
Umelá inteligencia
Zero123++: Jediný obrázok ku konzistentnému viacpohľadovému základnému modelu difúzie

V posledných rokoch sme boli svedkami rýchleho pokroku vo výkonnosti, efektívnosti a generatívnych schopnostiach vznikajúcich románov Generatívne modely AI ktoré využívajú rozsiahle súbory údajov a postupy generovania 2D difúzie. Dnes sú generatívne modely AI mimoriadne schopné generovať rôzne formy 2D a do určitej miery aj 3D mediálneho obsahu vrátane textu, obrázkov, videí, GIF a ďalších.
V tomto článku budeme hovoriť o rámci Zero123++, obrazom podmienenom difúznom generatívnom modeli AI s cieľom generovať 3D-konzistentné obrázky s viacerými zobrazeniami pomocou jediného vstupu zobrazenia. Aby sa maximalizovala výhoda získaná z predchádzajúcich predtrénovaných generatívnych modelov, rámec Zero123++ implementuje početné tréningové a kondičné schémy, aby sa minimalizovalo množstvo úsilia potrebného na jemné doladenie z bežne dostupných modelov difúznych obrazov. Ponoríme sa hlbšie do architektúry, práce a výsledkov rámca Zero123++ a analyzujeme jeho schopnosti na generovanie konzistentných obrázkov s viacerými zobrazeniami vysokej kvality z jedného obrázka. Tak poďme na to.
Zero123 a Zero123++: Úvod
Rámec Zero123++ je obrazom podmienený difúzny generatívny model AI, ktorého cieľom je generovať 3D konzistentné obrázky s viacerými zobrazeniami pomocou jediného vstupu zobrazenia. Rámec Zero123++ je pokračovaním rámca Zero123 alebo Zero-1-to-3, ktorý využíva novú techniku syntézy obrazu s nulovým záberom, aby sa stal priekopníkom konverzií jedného obrazu na 3D s otvoreným zdrojom. Aj keď rámec Zero123++ poskytuje sľubný výkon, obrázky generované rámcom majú viditeľné geometrické nezrovnalosti, a to je hlavný dôvod, prečo stále existuje priepasť medzi 3D scénami a obrázkami s viacerými zobrazeniami.
Rámec Zero-1-to-3 slúži ako základ pre niekoľko ďalších rámcov vrátane SyncDreamer, One-2-3-45, Consistent123 a ďalších, ktoré do rámca Zero123 pridávajú ďalšie vrstvy na získanie konzistentnejších výsledkov pri generovaní 3D obrázkov. Iné rámce ako ProlificDreamer, DreamFusion, DreamGaussian a ďalšie sledujú prístup založený na optimalizácii na získanie 3D obrázkov destiláciou 3D obrazu z rôznych nekonzistentných modelov. Hoci sú tieto techniky účinné a vytvárajú uspokojivé 3D obrazy, výsledky by sa mohli zlepšiť implementáciou základného difúzneho modelu schopného konzistentne generovať viacpohľadové obrazy. V súlade s tým rámec Zero123++ preberá Zero-1 až-3 a dolaďuje nový viacpohľadový základný difúzny model od Stable Diffusion.
V rámci nula-1-to-3 sa každý nový pohľad generuje nezávisle a tento prístup vedie k nezrovnalostiam medzi pohľadmi generovanými, keďže modely difúzie majú charakter vzorkovania. Na vyriešenie tohto problému používa rámec Zero123++ prístup rozloženia dlaždíc, pričom objekt je obklopený šiestimi pohľadmi do jedného obrázka a zabezpečuje správne modelovanie pre spoločnú distribúciu viacpohľadových obrázkov objektu.
Ďalšou veľkou výzvou, ktorej čelia vývojári pracujúci na rámci Zero-1-to-3, je to, že nedostatočne využíva možnosti, ktoré ponúka Stabilná difúzia čo v konečnom dôsledku vedie k neefektívnosti a zvýšeným nákladom. Existujú dva hlavné dôvody, prečo rámec Zero-1-to-3 nemôže maximalizovať možnosti, ktoré ponúka Stable Diffusion
- Pri tréningu s obrazovými podmienkami rámec Zero-1-to-3 efektívne nezahŕňa lokálne alebo globálne mechanizmy kondicionovania, ktoré ponúka Stable Diffusion.
- Počas tréningu používa rámec Zero-1-to-3 znížené rozlíšenie, prístup, v ktorom je výstupné rozlíšenie znížené pod rozlíšenie tréningu, čo môže znížiť kvalitu generovania obrazu pre modely Stable Diffusion.
Na vyriešenie týchto problémov implementuje rámec Zero123++ celý rad kondicionačných techník, ktoré maximalizujú využitie zdrojov, ktoré ponúka Stable Diffusion, a zachováva kvalitu generovania obrazu pre modely Stable Diffusion.
Zlepšenie kondicionovania a konzistencie
V snahe zlepšiť úpravu obrazu a konzistenciu obrazu z viacerých pohľadov, rámec Zero123++ implementoval rôzne techniky, pričom primárnym cieľom bolo opätovné použitie predchádzajúcich techník pochádzajúcich z vopred pripraveného modelu stabilnej difúzie.
Generácia viacerých zobrazení
Nepostrádateľná kvalita generovania konzistentných viacpohľadových obrázkov spočíva v správnom modelovaní spoločnej distribúcie viacerých obrázkov. V rámci Zero-1-to-3 sa korelácia medzi obrázkami s viacerými zobrazeniami ignoruje, pretože pre každý obrázok rámec modeluje podmienenú okrajovú distribúciu nezávisle a oddelene. V rámci Zero123++ sa však vývojári rozhodli pre prístup rozloženia dlaždíc, ktorý usporiada 6 obrázkov do jedného rámca/obrázku pre konzistentné generovanie viacerých zobrazení a proces je demonštrovaný na nasledujúcom obrázku.
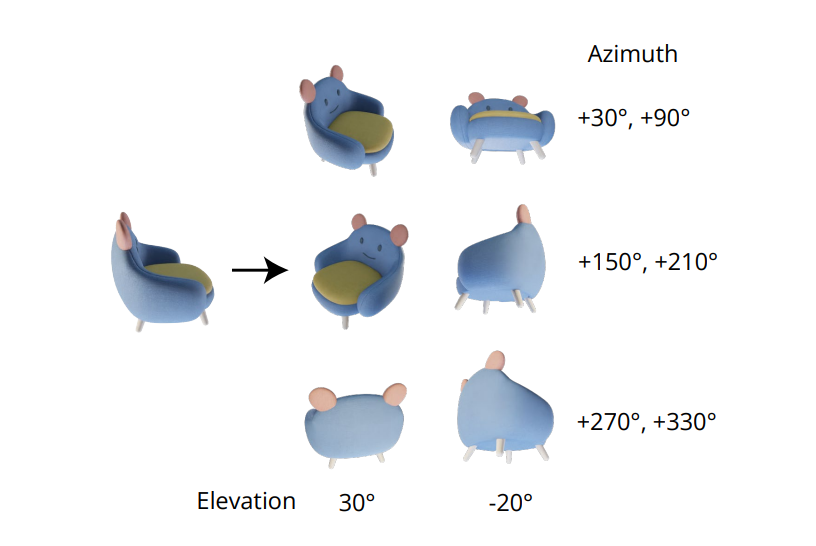
Okrem toho sa zistilo, že orientácie objektu majú tendenciu sa pri trénovaní modelu na pozíciách kamery rozmazávať, a aby sa predišlo tejto jednoznačnosti, rámec Zero-1-to-3 trénuje na pozíciách kamery s elevačnými uhlami a relatívnym azimutom k vstupu. Na implementáciu tohto prístupu je potrebné poznať elevačný uhol pohľadu na vstup, ktorý sa potom používa na určenie relatívnej polohy medzi novými vstupnými zobrazeniami. V snahe poznať tento výškový uhol rámce často pridávajú modul odhadu nadmorskej výšky a tento prístup často prichádza za cenu dodatočných chýb v potrubí.
Plán hluku
Škálovaný lineárny rozvrh, pôvodný rozvrh šumu pre Stable Diffusion sa zameriava predovšetkým na miestne detaily, ale ako je vidieť na nasledujúcom obrázku, má veľmi málo krokov s nižším SNR alebo pomerom signálu k šumu.

Tieto kroky nízkeho pomeru signálu k šumu sa vyskytujú skoro počas fázy odšumovania, čo je fáza rozhodujúca pre určenie globálnej nízkofrekvenčnej štruktúry. Zníženie počtu krokov počas fázy odšumovania, či už počas rušenia alebo tréningu, často vedie k väčšej štrukturálnej variácii. Aj keď je toto nastavenie ideálne na generovanie jedného obrázka, obmedzuje schopnosť rámca zabezpečiť globálnu konzistentnosť medzi rôznymi zobrazeniami. Aby sa táto prekážka prekonala, framework Zero123++ dolaďuje model LoRA na frameworku Stable Diffusion 2 v-prediction tak, aby plnil úlohu hračiek a výsledky sú uvedené nižšie.

Pri škálovanom lineárnom šume model LoRA neprepadá, ale iba mierne vybieli obraz. Naopak, pri práci s rozvrhom lineárneho šumu rámec LoRA úspešne generuje prázdny obrázok bez ohľadu na výzvu na zadanie, čo znamená vplyv rozvrhu hluku na schopnosť rámca globálne sa prispôsobiť novým požiadavkám.
Škálovaná referenčná pozornosť pre miestne podmienky
Vstup s jedným pohľadom alebo upravujúce obrazy v rámci Zero-1-to-3 sú spojené so zašumenými vstupmi v dimenzii funkcie, ktoré majú byť zašumované na úpravu obrazu.
Toto zreťazenie vedie k nesprávnej priestorovej korešpondencii medzi cieľovým obrázkom a vstupom v pixeloch. Aby sa zabezpečil správny vstup lokálnej úpravy, rámec Zero123++ využíva škálovanú referenčnú pozornosť, prístup, v ktorom sa spustenie odšumovacieho modelu UNet odkazuje na ďalší referenčný obrázok, po ktorom nasleduje pripojenie hodnotových matíc a kľúča vlastnej pozornosti z referenčného súboru. obrázok do príslušných vrstiev pozornosti, keď je vstup modelu odšumovaný, a je to znázornené na nasledujúcom obrázku.

Prístup Reference Attention je schopný viesť difúzny model na generovanie obrázkov zdieľajúcich textúru s referenčným obrázkom a sémantický obsah bez akéhokoľvek dolaďovania. Vďaka jemnému doladeniu poskytuje prístup Reference Attention vynikajúce výsledky so škálovaním latentného okrytia.

Globálna úprava: FlexDiffuse
V pôvodnom prístupe Stable Diffusion sú vloženie textu jediným zdrojom pre globálne vloženie a tento prístup využíva rámec CLIP ako kódovač textu na vykonávanie krížových vyšetrení medzi vloženými textami a latentnými modelmi. V dôsledku toho môžu vývojári voľne použiť zarovnanie medzi textovými priestormi a výsledné obrázky CLIP na použitie na globálne úpravy obrázkov.
Rámec Zero123++ navrhuje využiť trénovateľný variant mechanizmu lineárneho navádzania na začlenenie globálnej úpravy obrazu do rámca s minimálnymi dolaďovanie a výsledky sú znázornené na nasledujúcom obrázku. Ako je možné vidieť, bez prítomnosti globálnej úpravy obrazu je kvalita obsahu generovaného rámcom uspokojivá pre viditeľné oblasti, ktoré zodpovedajú vstupnému obrazu. Avšak kvalita obrazu generovaného rámcom pre neviditeľné oblasti je svedkom výrazného zhoršenia, ktoré je spôsobené najmä neschopnosťou modelu odvodiť globálnu sémantiku objektu.

Architektúra modelov
Rámec Zero123++ je trénovaný s modelom Stable Diffusion 2v ako základom pomocou rôznych prístupov a techník uvedených v článku. Rámec Zero123++ je vopred natrénovaný na súbore údajov Objaverse, ktorý je vykreslený náhodným osvetlením HDRI. Rámec tiež využíva prístup fázovaného tréningového plánu, ktorý sa používa v rámci Stable Diffusion Image Variations v snahe ďalej minimalizovať množstvo požadovaného jemného doladenia a zachovať čo najviac v predchádzajúcom Stable Diffusion.
Fungovanie alebo architektúru frameworku Zero123++ možno ďalej rozdeliť na postupné kroky alebo fázy. Prvá fáza je svedkom jemného doladenia rámca KV matíc vrstiev krížovej pozornosti a vrstiev sebapozorovania stabilnej difúzie s AdamW ako jeho optimalizátorom, 1000 zahrievacími krokmi a rozvrhom kosínusového učenia maximalizujúcim 7×10.-5. V druhej fáze rámec využíva vysoko konzervatívnu konštantnú rýchlosť učenia s 2000 zahrievacími sériami a využíva prístup Min-SNR na maximalizáciu efektivity počas tréningu.
Zero123++ : Výsledky a porovnanie výkonu
Kvalitatívny výkon
Na posúdenie výkonu rámca Zero123++ na základe jeho vygenerovanej kvality sa porovnáva so SyncDreamer a Zero-1-to-3-XL, dvoma z najlepších rámcov na vytváranie obsahu. Rámce sa porovnávajú so štyrmi vstupnými obrázkami s rôznym rozsahom. Prvý obrázok je elektrická mačka, prevzatá priamo z dátového súboru Objaverse a môže sa pochváliť veľkou neistotou na zadnej strane objektu. Druhý je obraz hasiaceho prístroja a tretí je obraz psa sediaceho na rakete, vytvorený modelom SDXL. Posledný obrázok je anime ilustrácia. Požadované výškové kroky pre rámce sa dosiahnu použitím metódy odhadu výšky rámca One-2-3-4-5 a odstránenie pozadia sa dosiahne pomocou rámca SAM. Ako je možné vidieť, rámec Zero123++ generuje konzistentne vysoko kvalitné obrázky s viacerými zobrazeniami a je schopný rovnako dobre zovšeobecniť 2D ilustrácie mimo domény a obrázky generované AI.


Kvantitatívna analýza
Na kvantitatívne porovnanie rámca Zero123++ s najmodernejšími rámcami Zero-1-to-3 a Zero-1to-3 XL vývojári hodnotia skóre podobnosti náplastí naučeného vnímania obrazu (LPIPS) týchto modelov na údajoch o rozdelení validácie, čo je podmnožina súboru údajov Objaverse. Na vyhodnotenie výkonu modelu pri vytváraní obrázkov z viacerých pohľadov vývojári usporiadajú referenčné obrázky základnej pravdy a 6 vygenerovaných obrázkov a potom vypočítajú skóre podobnosti náplastí naučeného vnímania obrazu (LPIPS). Výsledky sú demonštrované nižšie a ako je jasne vidieť, framework Zero123++ dosahuje najlepší výkon na validačnej delenej sade.

Hodnotenie textu na viacero zobrazení
Na vyhodnotenie schopnosti rámca Zero123++ pri generovaní obsahu z textu do viacerých zobrazení vývojári najprv použijú rámec SDXL s textovými výzvami na vygenerovanie obrázka a potom použijú rámec Zero123++ na vygenerovaný obrázok. Výsledky sú demonštrované na nasledujúcom obrázku, a ako je možné vidieť, v porovnaní s rámcom Zero-1-to-3, ktorý nemôže zaručiť konzistentné generovanie viacerých pohľadov, rámec Zero123++ vracia konzistentné, realistické a vysoko podrobné multi- zobraziť obrázky implementáciou text-to-image-to-multi-view prístup alebo potrubie.

Zero123++ Depth ControlNet
Okrem základného rámca Zero123++ vývojári vydali aj Depth ControlNet Zero123++, hĺbkovo riadenú verziu pôvodného rámca vybudovaného pomocou architektúry ControlNet. Normalizované lineárne obrázky sa vykreslia s ohľadom na následné obrázky RGB a rámec ControlNet je vyškolený na ovládanie geometrie rámca Zero123++ pomocou vnímania hĺbky.

záver
V tomto článku sme hovorili o Zero123++, obraze podmienenom difúznom generatívnom modeli AI s cieľom generovať 3D konzistentné obrázky s viacerými zobrazeniami pomocou jediného vstupu zobrazenia. Aby sa maximalizovala výhoda získaná z predchádzajúcich predtrénovaných generatívnych modelov, rámec Zero123++ implementuje početné tréningové a kondičné schémy, aby sa minimalizovalo množstvo úsilia potrebného na jemné doladenie z bežne dostupných modelov difúznych obrazov. Diskutovali sme aj o rôznych prístupoch a vylepšeniach implementovaných rámcom Zero123++, ktoré mu pomáhajú dosahovať výsledky porovnateľné s tými, ktoré dosahujú súčasné moderné rámce, a dokonca ich prevyšujú.
Napriek svojej efektívnosti a schopnosti konzistentne generovať vysokokvalitné obrázky s viacerými zobrazeniami má však rámec Zero123++ stále priestor na zlepšenie, pričom potenciálne oblasti výskumu sú
- Dvojstupňový model rafinácie to by mohlo vyriešiť neschopnosť Zero123++ splniť globálne požiadavky na konzistenciu.
- Ďalšie zväčšenia na ďalšie zlepšenie schopnosti Zero123++ vytvárať obrázky ešte vyššej kvality.



