
Umelá inteligencia
YOLOv7: Najpokročilejší algoritmus detekcie objektov?

6. júl 2022 sa zapíše ako medzník v histórii AI, pretože práve v tento deň bol vydaný YOLOv7. Od svojho uvedenia na trh je YOLOv7 najhorúcejšou témou v komunite vývojárov Computer Vision, a to zo správnych dôvodov. YOLOv7 je už považovaný za míľnik v odvetví detekcie objektov.
Krátko po Bol uverejnený papier YOLOv7, ukázal sa ako najrýchlejší a najpresnejší model detekcie námietok v reálnom čase. Ako však YOLOv7 konkuruje svojim predchodcom? Prečo je YOLOv7 taký efektívny pri vykonávaní úloh počítačového videnia?
V tomto článku sa pokúsime analyzovať model YOLOv7 a pokúsime sa nájsť odpoveď na otázku, prečo sa YOLOv7 teraz stáva priemyselným štandardom? Ale skôr ako na to odpovieme, budeme sa musieť pozrieť na stručnú históriu detekcie objektov.
Čo je to detekcia objektov?
Detekcia objektov je odvetvím počítačového videnia ktorý identifikuje a lokalizuje objekty na obrázku alebo video súbore. Detekcia objektov je stavebným kameňom mnohých aplikácií vrátane samoriadiacich áut, monitorovaného dohľadu a dokonca aj robotiky.
Model detekcie objektov možno rozdeliť do dvoch rôznych kategórií, jednorazové detektory, a viacranové detektory.
Detekcia objektov v reálnom čase
Aby sme skutočne pochopili, ako YOLOv7 funguje, je nevyhnutné, aby sme pochopili hlavný cieľ YOLOv7, “Detekcia objektov v reálnom čase”. Detekcia objektov v reálnom čase je kľúčovou súčasťou moderného počítačového videnia. Modely detekcie objektov v reálnom čase sa snažia identifikovať a lokalizovať objekty záujmu v reálnom čase. Modely detekcie objektov v reálnom čase umožnili vývojárom skutočne efektívne sledovať objekty záujmu v pohybujúcom sa rámčeku, ako je video alebo živý sledovací vstup.

Modely detekcie objektov v reálnom čase sú v podstate o krok vpred od konvenčných modelov detekcie obrazu. Zatiaľ čo prvý sa používa na sledovanie objektov vo video súboroch, druhý vyhľadáva a identifikuje objekty v rámci stacionárneho rámca ako obrázok.
Výsledkom je, že modely detekcie objektov v reálnom čase sú skutočne efektívne pre analýzu videa, autonómne vozidlá, počítanie objektov, sledovanie viacerých objektov a oveľa viac.
Čo je YOLO?
YOLO alebo “Pozrieš sa len raz“ je rodina modelov detekcie objektov v reálnom čase. Koncept YOLO bol prvýkrát predstavený v roku 2016 Josephom Redmonom a mesto sa o ňom začalo hovoriť takmer okamžite, pretože bolo oveľa rýchlejšie a oveľa presnejšie ako existujúce algoritmy detekcie objektov. Netrvalo dlho a algoritmus YOLO sa stal štandardom v priemysle počítačového videnia.

Základným konceptom, ktorý navrhuje algoritmus YOLO, je použitie end-to-end neurónovej siete pomocou ohraničujúcich boxov a pravdepodobností tried na vytváranie predpovedí v reálnom čase. YOLO sa líšil od predchádzajúceho modelu detekcie objektov v tom zmysle, že navrhol iný prístup k vykonávaniu detekcie objektov prehodnotením klasifikátorov.
Zmena v prístupe zafungovala, pretože YOLO sa čoskoro stalo priemyselným štandardom, pretože medzi ním a inými algoritmami detekcie objektov v reálnom čase boli významné rozdiely. Ale aký bol dôvod, prečo bol YOLO taký efektívny?
V porovnaní s YOLO, algoritmy detekcie objektov v tom čase používali siete návrhov regiónov na detekciu možných oblastí záujmu. Proces rozpoznávania sa potom uskutočnil pre každú oblasť samostatne. Výsledkom bolo, že tieto modely často vykonávali viacero iterácií na rovnakom obrázku, a preto im chýba presnosť a dlhší čas vykonávania. Na druhej strane, algoritmus YOLO používa jednu plne prepojenú vrstvu na vykonanie predikcie naraz.
Ako YOLO funguje?
Existujú tri kroky, ktoré vysvetľujú, ako funguje algoritmus YOLO.
Prerámcovanie detekcie objektov ako jednoduchého regresného problému
Algoritmus YOLO sa pokúša prerámcovať detekciu objektov ako jeden regresný problém, vrátane obrazových pixelov, pravdepodobnosti tried a súradníc ohraničujúceho rámčeka. Algoritmus sa teda musí pozrieť na obrázok iba raz, aby predpovedal a lokalizoval cieľové objekty v obrázkoch.
Zdôvodňuje obraz globálne
Okrem toho, keď algoritmus YOLO robí predpovede, zdôvodňuje obraz globálne. Je to odlišné od techník založených na návrhu regiónu a posuvných techník, pretože algoritmus YOLO vidí úplný obraz počas školenia a testovania na súbore údajov a je schopný zakódovať kontextové informácie o triedach a o tom, ako sa zobrazujú.
Pred YOLO bol Fast R-CNN jedným z najpopulárnejších algoritmov na detekciu objektov, ktorý nedokázal vidieť väčší kontext v obrázku, pretože si mýlil záplaty pozadia v obrázku s objektom. V porovnaní s rýchlym algoritmom R-CNN je YOLO o 50 % presnejší pokiaľ ide o chyby na pozadí.
Zovšeobecňuje reprezentáciu objektov
Nakoniec, algoritmus YOLO sa tiež zameriava na zovšeobecnenie reprezentácií objektov na obrázku. Výsledkom bolo, že keď bol algoritmus YOLO spustený na súbore údajov s prirodzenými obrázkami a testovaný na výsledky, YOLO výrazne prekonalo existujúce modely R-CNN. Je to preto, že YOLO je vysoko zovšeobecniteľné, šanca, že sa pokazí pri implementácii na neočakávané vstupy alebo nové domény, bola malá.
YOLOv7: Čo je nové?
Teraz, keď máme základné znalosti o tom, čo sú modely detekcie objektov v reálnom čase a čo je algoritmus YOLO, je čas diskutovať o algoritme YOLOv7.
Optimalizácia tréningového procesu
Algoritmus YOLOv7 sa snaží nielen optimalizovať architektúru modelu, ale zameriava sa aj na optimalizáciu tréningového procesu. Zameriava sa na použitie optimalizačných modulov a metód na zlepšenie presnosti detekcie objektov, zvýšenie nákladov na školenie pri zachovaní nákladov na rušenie. Tieto optimalizačné moduly možno označiť ako a trénovateľná taška zadarmo.
Priradenie štítkov so sprievodcom od hrubého po jemné
Algoritmus YOLOv7 plánuje namiesto konvenčného priradenia štítkov používať nové priradenie značenia od hrubého k jemnému Dynamické priradenie štítkov. Je to tak preto, že pri dynamickom priraďovaní štítkov spôsobuje trénovanie modelu s viacerými výstupnými vrstvami určité problémy, z ktorých najbežnejší je spôsob priraďovania dynamických cieľov pre rôzne vetvy a ich výstupy.
Reparametrizácia modelu
Reparametrizácia modelu je dôležitým konceptom pri zisťovaní objektov a jeho použitie sa vo všeobecnosti sleduje s určitými problémami počas školenia. Algoritmus YOLOv7 plánuje použiť koncept cestu šírenia gradientu na analýzu politík reparametrizácie modelu použiteľné na rôzne vrstvy v sieti.
Rozšírenie a zložené škálovanie
Algoritmus YOLOv7 tiež zavádza rozšírené a zložené metódy škálovania využívať a efektívne využívať parametre a výpočty na detekciu objektov v reálnom čase.

YOLOv7: Súvisiace práce
Detekcia objektov v reálnom čase
YOLO je v súčasnosti priemyselným štandardom a väčšina detektorov objektov v reálnom čase využíva algoritmy YOLO a FCOS (plne konvolučná jednostupňová detekcia objektov). Najmodernejší detektor objektov v reálnom čase má zvyčajne nasledujúce charakteristiky
- Silnejšia a rýchlejšia sieťová architektúra.
- Efektívna metóda integrácie funkcií.
- Presná metóda detekcie objektov.
- Robustná funkcia straty.
- Efektívna metóda prideľovania štítkov.
- Efektívna tréningová metóda.
Algoritmus YOLOv7 nepoužíva metódy učenia a destilácie s vlastným dohľadom, ktoré často vyžadujú veľké množstvo údajov. Algoritmus YOLOv7 naopak používa trénovateľnú metódu sáčok zadarmo.
Reparametrizácia modelu
Techniky reparametrizácie modelu sa považujú za techniku súboru, ktorá spája viacero výpočtových modulov v interferenčnom štádiu. Techniku možno ďalej rozdeliť do dvoch kategórií, súbor na úrovni modelu, a súbor na úrovni modulov.
Teraz, aby sa získal konečný interferenčný model, technika reparametrizácie na úrovni modelu používa dve praktiky. Prvý tréning používa rôzne tréningové dáta na tréning mnohých identických modelov a potom spriemeruje hmotnosti trénovaných modelov. Alternatívne, iná prax spriemeruje váhy modelov počas rôznych iterácií.
Reparametrizácia na úrovni modulov si v poslednej dobe získava obrovskú popularitu, pretože rozdeľuje modul na rôzne vetvy modulov alebo rôzne identické vetvy počas tréningovej fázy a potom pokračuje v integrácii týchto rôznych vetiev do ekvivalentného modulu, pričom dochádza k interferencii.
Techniky reparametrizácie však nemožno aplikovať na všetky druhy architektúry. To je dôvod, prečo Algoritmus YOLOv7 využíva nové techniky reparametrizácie modelu na navrhovanie súvisiacich stratégií vhodné pre rôzne architektúry.
Škálovanie modelu
Škálovanie modelu je proces zväčšovania alebo zmenšovania existujúceho modelu tak, aby vyhovoval rôznym výpočtovým zariadeniam. Škálovanie modelu vo všeobecnosti používa rôzne faktory, ako je počet vrstiev (hĺbka), veľkosť vstupných obrázkov (riešenie), počet pyramíd prvkov(stupeň) a počet kanálov (šírka). Tieto faktory zohrávajú kľúčovú úlohu pri zabezpečovaní vyváženého kompromisu pre parametre siete, rýchlosť rušenia, výpočty a presnosť modelu.
Jednou z najčastejšie používaných metód škálovania je NAS alebo Network Architecture Search ktorý automaticky hľadá vhodné škálovacie faktory z vyhľadávačov bez zložitých pravidiel. Hlavnou nevýhodou používania NAS je to, že je to drahý prístup na vyhľadávanie vhodných faktorov škálovania.
Takmer každý model reparametrizácie modelu analyzuje individuálne a jedinečné škálovacie faktory nezávisle a navyše tieto faktory nezávisle optimalizuje. Je to preto, že architektúra NAS pracuje s nekorelovanými faktormi škálovania.
Stojí za zmienku, že modely založené na zreťazení ako VoVNet or DenseNet zmeniť vstupnú šírku niekoľkých vrstiev, keď sa hĺbka modelov zmení. YOLOv7 pracuje na navrhovanej architektúre založenej na zreťazení, a preto používa metódu zloženého škálovania.

Vyššie uvedený obrázok porovnáva rozšírené efektívne siete na agregáciu vrstiev (E-ELAN) rôznych modelov. Navrhovaná metóda E-ELAN zachováva gradientovú prenosovú cestu pôvodnej architektúry, ale zameriava sa na zvýšenie mohutnosti pridaných funkcií pomocou skupinovej konvolúcie. Proces môže vylepšiť vlastnosti naučené rôznymi mapami a môže ďalej zefektívniť používanie výpočtov a parametrov.
Architektúra YOLOv7
Model YOLOv7 využíva ako základ modely YOLOv4, YOLO-R a Scaled YOLOv4. YOLOv7 je výsledkom experimentov vykonaných na týchto modeloch s cieľom zlepšiť výsledky a spresniť model.
Extended Efficient Layer Aggregation Network alebo E-ELAN
E-ELAN je základným stavebným kameňom modelu YOLOv7 a je odvodený z už existujúcich modelov efektívnosti siete, najmä ELAN.
Hlavnými faktormi pri navrhovaní efektívnej architektúry sú počet parametrov, výpočtová hustota a množstvo výpočtov. Iné modely tiež berú do úvahy faktory ako vplyv pomeru vstupných/výstupných kanálov, vetvy v sieti architektúry, rýchlosť sieťového rušenia, počet prvkov v tenzoroch konvolučnej siete a ďalšie.
CSPVoNet model nielen berie do úvahy vyššie uvedené parametre, ale tiež analyzuje dráhu gradientu, aby sa naučil viac rôznorodých funkcií povolením váh rôznych vrstiev. Tento prístup umožňuje, aby boli interferencie oveľa rýchlejšie a presné. The ELAN architektúra sa zameriava na navrhovanie efektívnej siete na riadenie najkratšej najdlhšej dráhy gradientu, aby sieť mohla byť efektívnejšia pri učení a zbližovaní.
ELAN už dosiahol stabilnú fázu bez ohľadu na počet výpočtových blokov a dĺžku dráhy prechodu. Stabilný stav môže byť zničený, ak sú výpočtové bloky naskladané neobmedzene, a miera využitia parametrov sa zníži. The navrhovaná architektúra E-ELAN môže vyriešiť problém, pretože využíva expanziu, miešanie a zlučovanie mohutnosti neustále zvyšovať schopnosť učenia sa siete pri zachovaní pôvodnej dráhy gradientu.
Okrem toho, pri porovnaní architektúry E-ELAN s ELAN, jediný rozdiel je vo výpočtovom bloku, zatiaľ čo architektúra prechodovej vrstvy je nezmenená.
E-ELAN navrhuje rozšírenie mohutnosti výpočtových blokov a rozšírenie kanála pomocou skupinová konvolúcia. Mapa prvkov sa potom vypočíta a zamieša do skupín podľa parametra skupiny a potom sa spojí. Počet kanálov v každej skupine zostane rovnaký ako v pôvodnej architektúre. Nakoniec sa pridajú skupiny máp objektov, aby sa dosiahla mohutnosť.
Škálovanie modelov pre modely založené na zreťazení
Pomáha pri tom škálovanie modelu úprava atribútov modelov čo pomáha pri vytváraní modelov podľa požiadaviek a rôznych mierok, aby vyhovovali rôznym rýchlostiam rušenia.

Obrázok hovorí o škálovaní modelu pre rôzne modely založené na zreťazení. Ako vidíte na obrázku (a) a (b), výstupná šírka výpočtového bloku sa zvyšuje so zvyšujúcou sa mierou hĺbky modelov. V dôsledku toho sa zväčší vstupná šírka prenosových vrstiev. Ak sú tieto metódy implementované na architektúre založenej na zreťazení, proces škálovania sa vykonáva do hĺbky a je znázornený na obrázku (c).
Dá sa teda dospieť k záveru, že nie je možné analyzovať škálovacie faktory nezávisle pre modely založené na zreťazení a skôr ich treba posudzovať alebo analyzovať spoločne. Preto pre model založený na zreťazení je vhodné použiť zodpovedajúcu metódu škálovania zloženého modelu. Okrem toho, keď je hĺbkový faktor škálovaný, výstupný kanál bloku musí byť tiež škálovaný.
Trénovateľná taška zadarmo
Taška zadarmo je termín, ktorý vývojári používajú na opis súbor metód alebo techník, ktoré môžu zmeniť stratégiu školenia alebo náklady v snahe zvýšiť presnosť modelu. Aké sú teda tieto trénovateľné vrecia zadarmo v YOLOv7? Pozrime sa na to.
Plánovaná reparametrizovaná konvolúcia
Algoritmus YOLOv7 používa na určenie dráhy šírenia gradientu toku ako ideálne skombinovať sieť s preparametrizovanou konvolúciou. Tento prístup YOLov7 je pokusom čeliť Algoritmus RepConv že aj keď fungoval pokojne na modeli VGG, funguje zle, keď sa aplikuje priamo na modely DenseNet a ResNet.
Na identifikáciu spojení v konvolučnej vrstve Algoritmus RepConv kombinuje konvolúciu 3×3 a konvolúciu 1×1. Ak analyzujeme algoritmus, jeho výkon a architektúru, zistíme, že RepConv ničí zreťazenie v DenseNet a zvyšok v ResNet.

Obrázok vyššie zobrazuje plánovaný reparametrizovaný model. Je možné vidieť, že algoritmus YOLov7 zistil, že vrstva v sieti s zreťazením alebo reziduálnymi pripojeniami by nemala mať v algoritme RepConv spojenie identity. V dôsledku toho je prijateľné prepínať s RepConvN bez pripojenia identity.
Hrubé pre pomocné a jemné pre stratu olova
Hlboký dohľad je odvetvie informatiky, ktoré často nachádza svoje využitie v tréningovom procese hlbokých sietí. Základným princípom hlbokého dohľadu je, že áno pridáva ďalšiu pomocnú hlavu v stredných vrstvách siete spolu s plytkými sieťovými váhami so stratou asistenta ako sprievodcom. Algoritmus YOLOv7 označuje hlavu, ktorá je zodpovedná za konečný výstup, ako vedúcu hlavu a pomocná hlava je hlava, ktorá pomáha pri tréningu.
YOLOv7 používa inú metódu priraďovania štítkov. Bežne sa priraďovanie štítkov používa na generovanie štítkov priamym odkazom na základnú pravdu a na základe daného súboru pravidiel. V posledných rokoch však distribúcia a kvalita predikčných vstupov zohráva dôležitú úlohu pri vytváraní spoľahlivého označenia. YOLOv7 vygeneruje mäkký štítok objektu pomocou predpovedí ohraničujúceho boxu a základnej pravdy.
Okrem toho nová metóda priraďovania štítkov algoritmu YOLOv7 využíva predpovede vedúcej hlavy na vedenie elektródy aj pomocnej hlavy. Metóda prideľovania štítkov má dve navrhnuté stratégie.
Vedúci priraďovač štítkov s vedením
Stratégia robí výpočty na základe výsledkov predikcie vedúcej hlavy a základnej pravdy a potom používa optimalizáciu na generovanie mäkkých štítkov. Tieto mäkké štítky sa potom používajú ako tréningový model pre vodiacu hlavu aj pomocnú hlavu.
Stratégia funguje na predpoklade, že keďže vedúci vedúci má väčšiu schopnosť učiť sa, značky, ktoré vytvára, by mali byť reprezentatívnejšie a mali by korelovať medzi zdrojom a cieľom.
Priraďovač štítkov vedených hlavou s hrubým až jemným vedením
Táto stratégia tiež robí výpočty na základe výsledkov predikcie vedúcej hlavy a základnej pravdy a potom používa optimalizáciu na generovanie mäkkých štítkov. Je tu však zásadný rozdiel. V tejto stratégii existujú dve sady mäkkých štítkov, hrubá úroveň, a jemný štítok.
Hrubé označenie sa vytvorí uvoľnením obmedzení pozitívnej vzorky
proces priraďovania, ktorý považuje viac sietí za pozitívne ciele. Robí sa to preto, aby sa predišlo riziku straty informácií v dôsledku slabšej sily učenia pomocnej hlavy.

Vyššie uvedený obrázok vysvetľuje použitie trénovateľného vrecka s darčekmi v algoritme YOLOv7. Zobrazuje hrubé pre pomocnú hlavu a jemné pre olovenú hlavu. Keď porovnáme model s pomocnou hlavou (b) s normálnym modelom (a), zistíme, že schéma v (b) má pomocnú hlavu, zatiaľ čo v (a) nie je.
Obrázok (c) znázorňuje spoločného nezávislého priraďovača štítkov, zatiaľ čo obrázok (d) a obrázok (e) predstavujú vedúceho priraďovača a priraďovač od hrubého po jemné, ktorý používa YOLOv7.
Ďalšie trénovateľné vrece zadarmo
Okrem vyššie uvedených, algoritmus YOLOv7 používa ďalšie vrecia s darčekmi, hoci pôvodne neboli navrhnuté. Oni sú
- Dávková normalizácia v technológii Conv-Bn-Activation: Táto stratégia sa používa na pripojenie konvolučnej vrstvy priamo k vrstve normalizácie dávky.
- Implicitné znalosti v YOLOR: YOLOv7 kombinuje stratégiu s konvolučnou mapou funkcií.
- Model EMA: Model EMA sa používa ako konečný referenčný model v YOLOv7, hoci jeho primárne použitie sa má použiť v metóde stredného učiteľa.
YOLOv7 : Experimenty
Experimentálne nastavenie
Algoritmus YOLOv7 používa Dátový súbor Microsoft COCO na školenie a overenie ich model detekcie objektov a nie všetky tieto experimenty používajú vopred vyškolený model. Vývojári použili na školenie súbor údajov o vlaku z roku 2017 a na výber hyperparametrov použili súbor údajov z roku 2017. Nakoniec je výkonnosť výsledkov detekcie objektov YOLOv7 porovnaná s najmodernejšími algoritmami na detekciu objektov.
Vývojári navrhli základný model pre edge GPU (YOLOv7-tiny), normálny GPU (YOLOv7) a cloud GPU (YOLOv7-W6). Okrem toho algoritmus YOLOv7 tiež používa základný model na škálovanie modelu podľa rôznych požiadaviek na služby a získava rôzne modely. Pre algoritmus YOLOv7 sa škálovanie zásobníka vykonáva na krku a navrhované zlúčeniny sa používajú na zväčšenie hĺbky a šírky modelu.
Základné línie
Algoritmus YOLOv7 využíva predchádzajúce modely YOLO a algoritmus detekcie objektov YOLOR ako základnú líniu.

Vyššie uvedený obrázok porovnáva základnú líniu modelu YOLOv7 s inými modelmi detekcie objektov a výsledky sú celkom zrejmé. Pri porovnaní s Algoritmus YOLOv4, YOLOv7 nielenže používa o 75 % menej parametrov, ale využíva aj o 15 % menej výpočtov a má o 0.4 % vyššiu presnosť.
Porovnanie s najmodernejšími modelmi detektorov objektov

Vyššie uvedený obrázok ukazuje výsledky pri porovnaní YOLOv7 s najmodernejšími modelmi detekcie objektov pre mobilné a všeobecné GPU. Dá sa pozorovať, že metóda navrhovaná algoritmom YOLOv7 má najlepšie kompromisné skóre medzi rýchlosťou a presnosťou.
Ablačná štúdia: Navrhovaná metóda škálovania zlúčeniny

Vyššie uvedený obrázok porovnáva výsledky použitia rôznych stratégií na zväčšenie modelu. Stratégia škálovania v modeli YOLOv7 zväčšuje hĺbku výpočtového bloku 1.5-krát a šírku 1.25-krát.
V porovnaní s modelom, ktorý iba zväčšuje hĺbku, model YOLOv7 funguje lepšie o 0.5 % pri menšom počte parametrov a výpočtovom výkone. Na druhej strane, v porovnaní s modelmi, ktoré len zväčšujú hĺbku, sa presnosť YOLOv7 zlepšila o 0.2 %, ale počet parametrov je potrebné upraviť o 2.9 % a výpočet o 1.2 %.
Navrhovaný plánovaný reparametrizovaný model
Aby sa overila všeobecnosť jej navrhovaného reparametrizovaného modelu, Algoritmus YOLOv7 ho na overenie používa na modeloch založených na reziduálnych a zreťazených modeloch. Pre proces overovania používa algoritmus YOLOv7 3-skladaný ELAN pre model založený na zreťazení a CSPDarknet pre model založený na zvyškovom stave.
Pre model založený na zreťazení algoritmus nahrádza 3×3 konvolučné vrstvy v 3-skladanom ELAN s RepConv. Obrázok nižšie ukazuje detailnú konfiguráciu Planned RepConv a 3-stack ELAN.
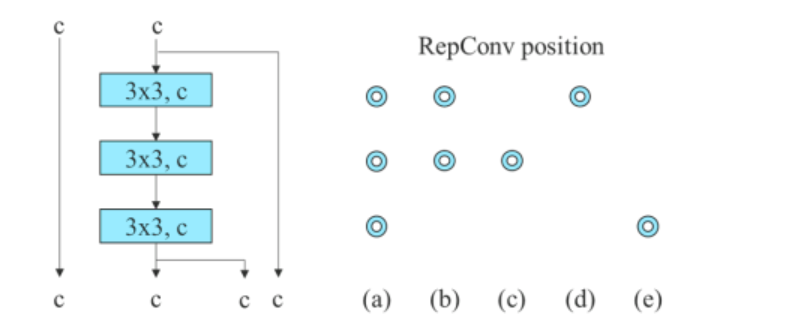
Okrem toho, keď sa zaoberáme modelom založeným na zvyškovom stave, algoritmus YOLOv7 používa obrátený tmavý blok, pretože pôvodný tmavý blok nemá konvolučný blok 3×3. Nižšie uvedený obrázok ukazuje architektúru Reversed CSPDarknet, ktorá obráti pozície konvolučnej vrstvy 3×3 a 1×1. 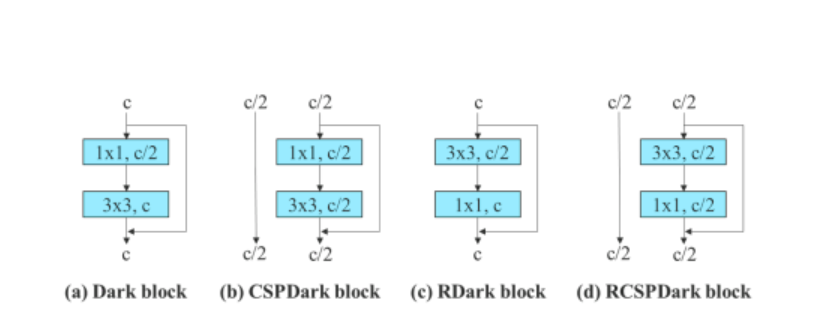
Navrhovaná strata asistenta pre pomocnú hlavu
Pre stratu asistenta pre pomocnú hlavicu model YOLOv7 porovnáva nezávislé priradenie štítkov pre metódy pomocnej hlavice a hlavice elektródy.

Vyššie uvedený obrázok obsahuje výsledky štúdie o navrhovanej pomocnej hlave. Je vidieť, že celkový výkon modelu stúpa so zvyšujúcou sa stratou asistenta. Okrem toho, priradenie označenia vedúceho zákazníka navrhnuté modelom YOLOv7 funguje lepšie ako nezávislé stratégie prideľovania potenciálnych zákazníkov.
Výsledky YOLOv7
Na základe vyššie uvedených experimentov je tu výsledok výkonu YOLov7 v porovnaní s inými algoritmami detekcie objektov.

Vyššie uvedený obrázok porovnáva model YOLOv7 s inými algoritmami detekcie objektov a možno jasne pozorovať, že YOLOv7 prevyšuje ostatné modely detekcie objektov z hľadiska Priemerná presnosť (AP) v/s dávkové rušenie.
Ďalej uvedený obrázok porovnáva výkon YOLOv7 v/s iných algoritmov detekcie námietok v reálnom čase. YOLOv7 opäť nahrádza ostatné modely z hľadiska celkového výkonu, presnosti a efektívnosti.

Tu je niekoľko ďalších postrehov z výsledkov a výkonov YOLOv7.
- YOLOv7-Tiny je najmenší model z rodiny YOLO s viac ako 6 miliónmi parametrov. YOLOv7-Tiny má priemernú presnosť 35.2% a s porovnateľnými parametrami prekonáva modely YOLOv4-Tiny.
- Model YOLOv7 má viac ako 37 miliónov parametrov a prekonáva modely s vyššími parametrami ako YOLov4.
- Model YOLOv7 má najvyššiu rýchlosť mAP a FPS v rozsahu 5 až 160 FPS.
záver
YOLO alebo You Only Look Once je najmodernejší model detekcie objektov v modernom počítačovom videní. Algoritmus YOLO je známy svojou vysokou presnosťou a účinnosťou, a preto nachádza rozsiahle uplatnenie v priemysle detekcie objektov v reálnom čase. Odkedy bol v roku 2016 predstavený prvý algoritmus YOLO, experimenty umožnili vývojárom neustále zlepšovať model.
Model YOLOv7 je najnovším prírastkom v rodine YOLO a je to doteraz najvýkonnejší algoritmus YOLO. V tomto článku sme hovorili o základoch YOLOv7 a pokúsili sme sa vysvetliť, prečo je YOLOv7 taký efektívny.















