
Umelá inteligencia
Pred nami sú tri výzvy pre stabilnú difúziu

uvoľnite stability.ai's Stable Diffusion latentná difúzia model syntézy obrazu spred niekoľkých týždňov môže byť jedným z najvýznamnejších technologických odhalení od DeCSS v roku 1999; je to určite najväčšia udalosť v snímkach generovaných AI od roku 2017 deepfakes kód bol skopírovaný na GitHub a rozvetvený do toho, čo sa stane DeepFaceLab a Výmena tváre, ako aj deepfake softvér na streamovanie v reálnom čase DeepFaceLive.
naraz, frustrácia používateľov cez obmedzenia obsahu v DALL-E 2 API syntézy obrazu boli zmietnuté bokom, pretože sa ukázalo, že filter NSFW Stable Diffusion možno deaktivovať zmenou jediný riadok kódu. Porno-centrické Stable Diffusion Reddits vznikli takmer okamžite a boli rovnako rýchlo znížené, zatiaľ čo tábor vývojárov a používateľov sa na Discorde rozdelil na oficiálnu komunitu a komunitu NSFW a Twitter sa začal zapĺňať fantastickými výtvormi Stable Diffusion.
V súčasnosti sa zdá, že každý deň prináša nejakú úžasnú inováciu od vývojárov, ktorí si systém osvojili, s pluginmi a doplnkami tretích strán, ktoré sú narýchlo napísané pre Kriti, photoshop, Cinema4D, Mixéra mnoho ďalších aplikačných platforiem.

Do tej doby, promptcraft – v súčasnosti profesionálne umenie „AI whispering“, ktoré môže skončiť ako najkratšia kariérna možnosť od „Filofax binder“ – sa už stáva komerčne, zatiaľ čo skoré speňaženie Stable Diffusion prebieha v Úroveň Patreon, s istotou, že prídu sofistikovanejšie ponuky pre tých, ktorí nie sú ochotní navigovať Na báze Conda inštalácie zdrojového kódu alebo proskriptívne filtre NSFW webových implementácií.
Tempo vývoja a slobodný zmysel pre skúmanie zo strany používateľov postupuje takou závratnou rýchlosťou, že je ťažké vidieť veľmi ďaleko dopredu. V podstate ešte presne nevieme, s čím máme do činenia, ani aké sú všetky obmedzenia či možnosti.
Poďme sa však pozrieť na tri z najzaujímavejších a najnáročnejších prekážok, ktorým musí rýchlo vytvorená a rýchlo rastúca komunita Stable Diffusion čeliť a dúfajme, že ich prekonať.
1: Optimalizácia potrubí založených na dlaždiciach
Vzhľadom na obmedzené hardvérové zdroje a prísne obmedzenia rozlíšenia tréningových obrázkov sa zdá pravdepodobné, že vývojári nájdu riešenia na zlepšenie kvality aj rozlíšenia výstupu Stable Diffusion. Mnohé z týchto projektov sú nastavené tak, aby zahŕňali využívanie obmedzení systému, ako je jeho prirodzené rozlíšenie iba 512 × 512 pixelov.
Ako je to vždy v prípade iniciatív počítačového videnia a syntézy obrazu, stabilná difúzia bola trénovaná na obrázkoch so štvorcovým pomerom, v tomto prípade prevzorkovaných na 512 × 512, takže zdrojové obrázky mohli byť regulované a schopné prispôsobiť sa obmedzeniam GPU, ktoré trénoval model.
Stabilná difúzia preto „myslí“ (ak vôbec myslí) v pomeroch 512 × 512 a určite v štvorcových hodnotách. Mnohí používatelia, ktorí v súčasnosti skúmajú limity systému, hlásia, že stabilná difúzia poskytuje najspoľahlivejšie a najmenej chybné výsledky pri tomto pomerne obmedzenom pomere strán (pozri „riešenie končatín“ nižšie).
Aj keď rôzne implementácie obsahujú upscaling cez RealESRGAN (a dokáže opraviť zle vykreslené tváre cez GFPGAN) niekoľko používateľov v súčasnosti vyvíja metódy na rozdelenie obrázkov do sekcií s rozmermi 512 x 512 pixelov a ich spojenie do väčších zložených diel.

Toto vykreslenie s rozlíšením 1024 × 576, rozlíšenie, ktoré je zvyčajne nemožné v jednom vykreslení Stable Diffusion, bolo vytvorené skopírovaním a prilepením súboru attention.py Python zo súboru DoggettX vidlica Stable Diffusion (verzia, ktorá implementuje upscaling na báze dlaždíc) do inej vidlice. Zdroj: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Aj keď niektoré iniciatívy tohto druhu používajú pôvodný kód alebo iné knižnice, port txt2imghd GOBIG (režim v režime ProgRockDiffusion, ktorý je hladný po VRAM) je nastavený tak, aby túto funkciu čoskoro poskytol hlavnej vetve. Zatiaľ čo txt2imghd je vyhradený port GOBIG, ďalšie úsilie vývojárov komunity zahŕňa rôzne implementácie GOBIG.

Pohodlne abstraktný obrázok v pôvodnom vykreslení 512 x 512 pixelov (vľavo a druhý zľava); upscaled ESGRAN, ktorý je teraz viac-menej natívny vo všetkých distribúciách Stable Diffusion; a venovala sa im „zvláštna pozornosť“ prostredníctvom implementácie GOBIG, ktorá vytvára detaily, ktoré sa prinajmenšom v rámci obrazovej časti zdajú lepšie zväčšené. Szdroj: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Vyššie uvedený druh abstraktného príkladu má veľa „malých kráľovstiev“ detailov, ktoré vyhovujú tomuto solipsistickému prístupu k upscalingu, ale ktoré si môžu vyžadovať náročnejšie kódom riadené riešenia, aby sa vytvorilo neopakujúce sa, súdržné upscaling, ktoré vyzerať ako keby bol zostavený z mnohých častí. V neposlednom rade v prípade ľudských tvárí, kde sme nezvyčajne naladení na aberácie alebo „trhavé“ artefakty. Preto môžu tváre nakoniec potrebovať špeciálne riešenie.
Stabilná difúzia v súčasnosti nemá žiadny mechanizmus na zameranie pozornosti na tvár počas vykresľovania rovnakým spôsobom, akým ľudia uprednostňujú informácie o tvári. Hoci niektorí vývojári v komunitách Discord zvažujú metódy na implementáciu tohto druhu „vylepšenej pozornosti“, v súčasnosti je oveľa jednoduchšie manuálne (a prípadne automaticky) vylepšiť tvár po vykonaní počiatočného vykreslenia.
Ľudská tvár má vnútornú a úplnú sémantickú logiku, ktorá sa nenachádza v „dlaždici“ v dolnom rohu (napríklad) budovy, a preto je v súčasnosti možné veľmi efektívne „priblížiť“ a znova vykresliť „útržkovitá“ tvár vo výstupe stabilnej difúzie.

Vľavo, počiatočné úsilie Stable Diffusion s okamžitou „Celodĺžkovou farebnou fotkou Christiny Hendricksovej, ktorá vchádza na preplnené miesto, oblečená v pršiplášte; Canon50, očný kontakt, vysoký detail, vysoký detail tváre“. Vpravo, vylepšená tvár získaná vrátením rozmazanej a načrtnutej tváre z prvého vykreslenia späť do plnej pozornosti Stable Diffusion pomocou Img2Img (pozri animované obrázky nižšie).
V prípade absencie špeciálneho riešenia pre textovú inverziu (pozri nižšie) to bude fungovať len pre obrázky celebrít, kde je príslušná osoba už dobre zastúpená v podmnožinách údajov LAION, ktoré trénovali stabilnú difúziu. Preto bude fungovať na takých ako Tom Cruise, Brad Pitt, Jennifer Lawrence a obmedzenú škálu skutočných mediálnych svetiel, ktoré sú prítomné vo veľkom počte obrázkov v zdrojových údajoch.
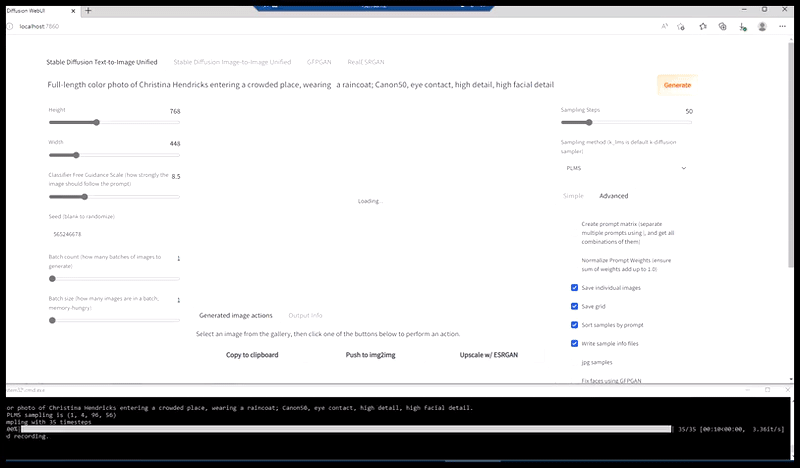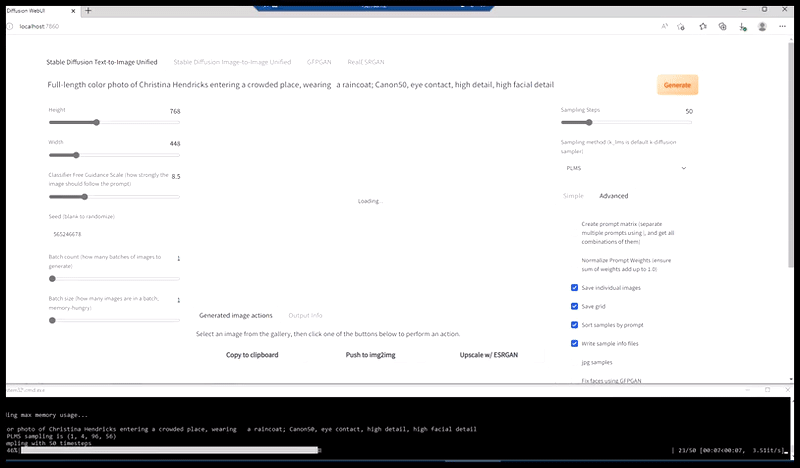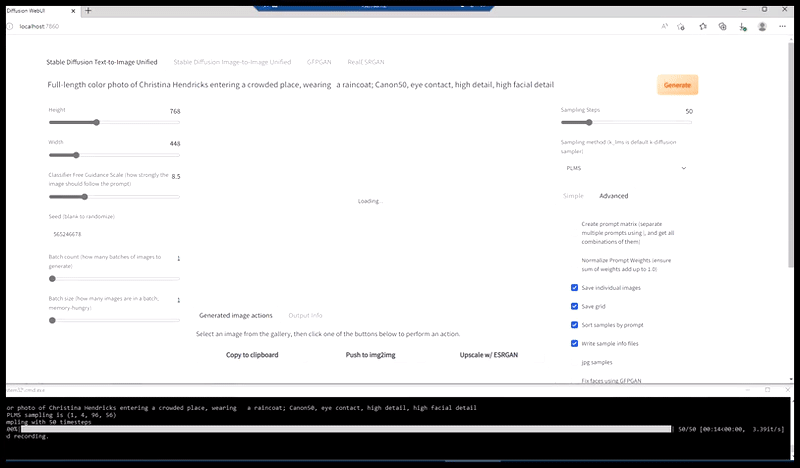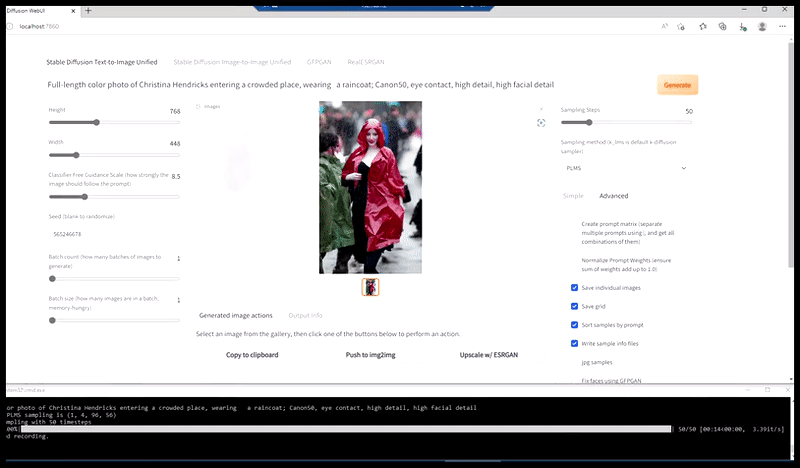
Generovanie vierohodného tlačového obrázku s výzvou „Celá farebná fotografia Christiny Hendricksovej, ktorá vchádza na preplnené miesto v pršiplášte; Canon50, očný kontakt, vysoký detail, vysoký detail tváre“.
U celebrít s dlhou a trvalou kariérou Stable Diffusion zvyčajne vygeneruje obraz osoby v nedávnom (teda staršom) veku a bude potrebné pridať promptné doplnky ako napr. 'mladý' or „v roku [YEAR]“ s cieľom vytvoriť mladšie vyzerajúce obrázky.

S prominentnou, veľa fotografovanou a konzistentnou kariérou trvajúcou takmer 40 rokov je herečka Jennifer Connelly jednou z hŕstky celebrít v LAION, ktoré umožňujú Stable Diffusion reprezentovať rôzne vekové kategórie. Zdroj: predbalenie Stable Diffusion, lokálny, kontrolný bod v1.4; výzvy súvisiace s vekom.
Je to z veľkej časti kvôli rozšíreniu digitálnej tlače (namiesto drahej, emulznej) tlačenej fotografie od polovice 2000. storočia a neskoršiemu nárastu objemu obrazového výstupu v dôsledku zvýšených širokopásmových rýchlostí.
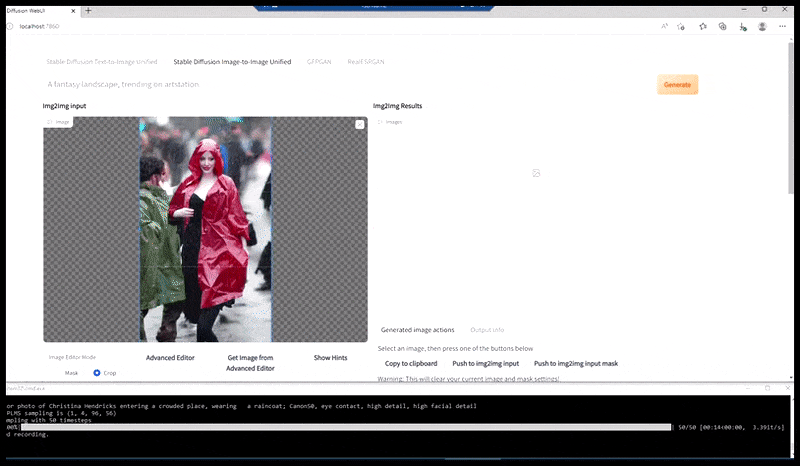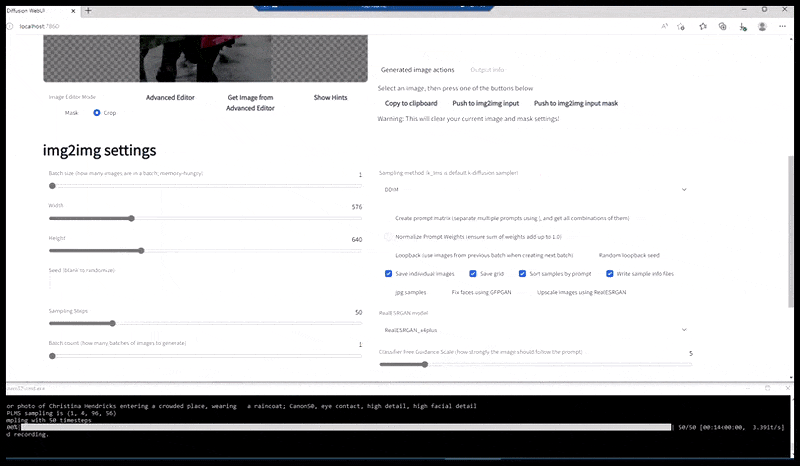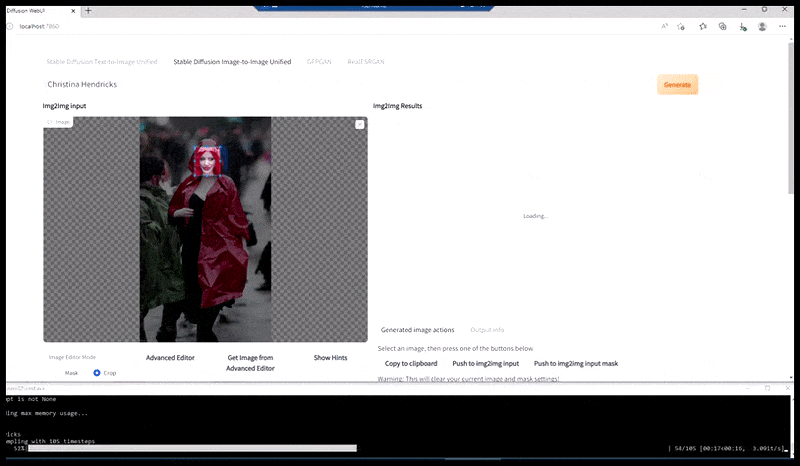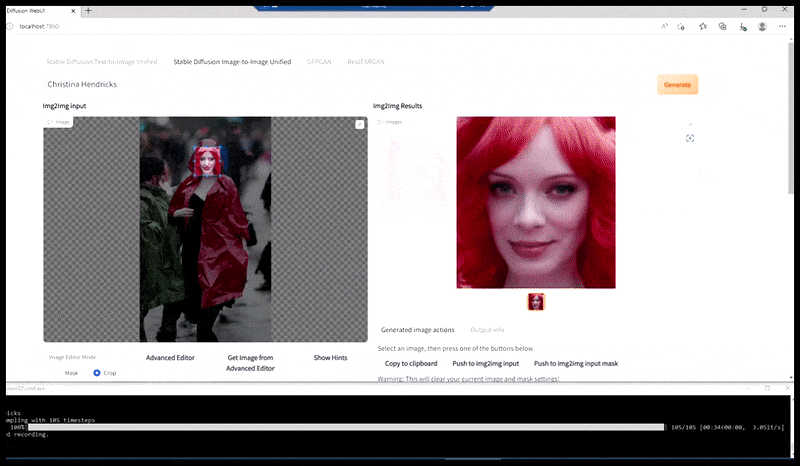
Vykreslený obrázok sa prenesie do Img2Img v Stable Diffusion, kde sa vyberie „oblasť zaostrenia“ a nový render s maximálnou veľkosťou sa vytvorí len z tejto oblasti, čo umožňuje Stable Diffusion sústrediť všetky dostupné zdroje na opätovné vytvorenie tváre.
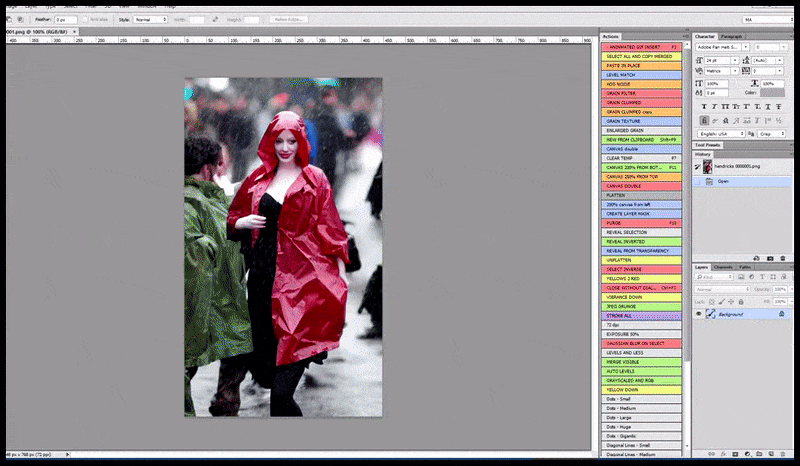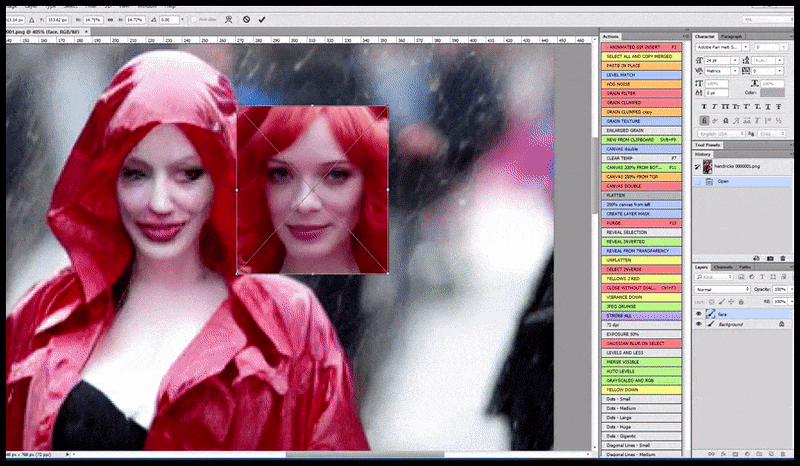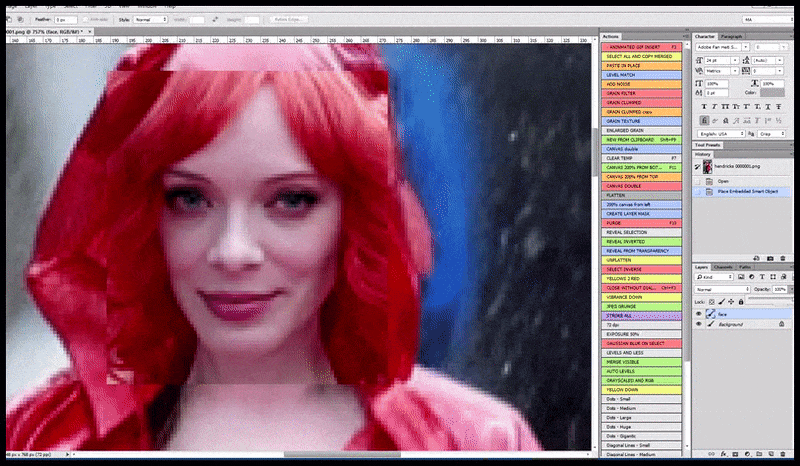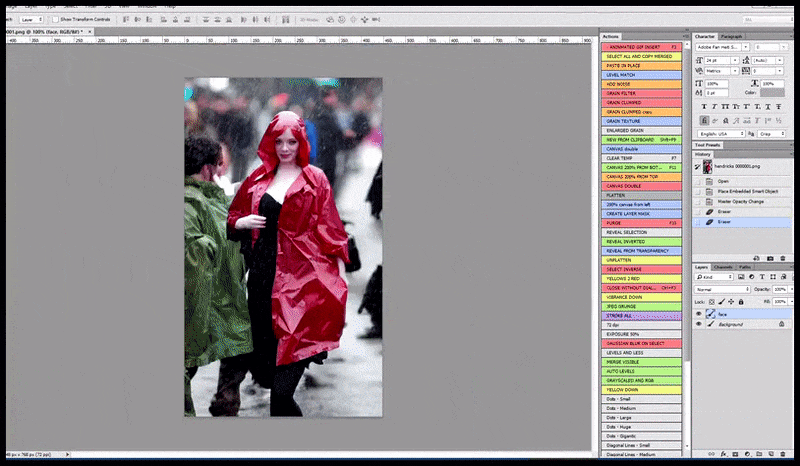
Kompozícia tváre s „vysokou pozornosťou“ späť do pôvodného renderu. Okrem tvárí bude tento proces fungovať iba s entitami, ktoré majú potenciálne známy, súdržný a integrálny vzhľad, ako je napríklad časť pôvodnej fotografie s odlišným objektom, ako sú hodinky alebo auto. Zväčšenie časti – napríklad – steny povedie k veľmi zvláštne vyzerajúcej premontovanej stene, pretože obklady dlaždíc nemali širší kontext pre tento „kus skladačky“, ako sa vykresľovalo.
Niektoré celebrity v databáze sú „pred zmrazené“ v čase, buď preto, že zomreli predčasne (ako napríklad Marilyn Monroe), alebo sa dostali do popredia len prchavého hlavného prúdu a vytvorili veľké množstvo obrázkov v obmedzenom časovom období. Polling Stable Diffusion pravdepodobne poskytuje akýsi „aktuálny“ index popularity pre moderné a staršie hviezdy. Pre niektoré staršie a súčasné celebrity nie je v zdrojových údajoch dostatok obrázkov na získanie veľmi dobrej podobizne, zatiaľ čo pretrvávajúca popularita konkrétnych dávno mŕtvych alebo inak vyblednutých hviezd zaisťuje, že ich primeranú podobizeň je možné získať zo systému.

Rendery Stable Diffusion rýchlo odhalia, ktoré známe tváre sú dobre zastúpené v tréningových údajoch. Napriek svojej obrovskej popularite ako staršia tínedžerka v čase písania, Millie Bobby Brown bola mladšia a menej známa, keď boli zdrojové súbory údajov LAION zoškrabané z webu, čím sa podobnosť s vysokou kvalitou so Stable Diffusion v súčasnosti stala problematickou.
Tam, kde sú údaje k dispozícii, riešenia s rozlíšením up-res založené na dlaždiciach v Stable Diffusion by mohli ísť ďalej, než len namieriť na tvár: mohli by potenciálne umožniť ešte presnejšie a detailnejšie tváre rozbitím čŕt tváre a otočením celej sily lokálneho GPU. zdroje na významných prvkoch individuálne, pred opätovným zložením – proces, ktorý je v súčasnosti opäť manuálny.

Neobmedzuje sa to na tváre, ale obmedzuje sa na časti objektov, ktoré sú prinajmenšom rovnako predvídateľne umiestnené v širšom kontexte hostiteľského objektu a ktoré sú v súlade s vysokoúrovňovými vloženiami, ktoré možno rozumne očakávať v hyperškále. súbor údajov.
Skutočným limitom je množstvo dostupných referenčných údajov v súbore údajov, pretože v konečnom dôsledku sa hlboko iterované detaily stanú úplne „halucinovanými“ (tj fiktívnymi) a menej autentickými.
Takéto granulárne zväčšenia na vysokej úrovni fungujú v prípade Jennifer Connelly, pretože je dobre zastúpená v rôznych vekových kategóriách LAION-estetika (primárna podskupina LAION 5B ktorý používa Stable Diffusion) a vo všeobecnosti naprieč LAION; v mnohých iných prípadoch by presnosť trpela nedostatkom údajov, čo by si vyžadovalo buď jemné doladenie (dodatočné školenie, pozri „Prispôsobenie“ nižšie) alebo textovú inverziu (pozri nižšie).
Dlaždice predstavujú výkonný a relatívne lacný spôsob, ako umožniť stabilnú difúziu produkovať výstup vo vysokom rozlíšení, ale algoritmické dlaždicové upscaling tohto druhu, ak mu chýba nejaký širší mechanizmus pozornosti na vyššej úrovni, môže zaostať za očakávaným pre štandardy pre celý rad typov obsahu.
2: Riešenie problémov s ľudskými končatinami
Stable Diffusion nezodpovedá svojmu názvu, keď zobrazuje zložitosť ľudských končatín. Ruky sa môžu náhodne množiť, prsty sa spájajú, tretie nohy sa zdajú byť nepozvané a existujúce končatiny zmiznú bez stopy. Na svoju obranu Stable Diffusion zdieľa problém so svojimi stajňovými kolegami a určite s DALL-E 2.

Neupravené výsledky z DALL-E 2 a stabilnej difúzie (1.4) na konci augusta 2022, obe vykazujú problémy s končatinami. Výzva je „Žena objímajúca muža“
Fanúšikovia Stable Diffusion, ktorí dúfajú, že nadchádzajúci kontrolný bod 1.5 (intenzívnejšie trénovaná verzia modelu s vylepšenými parametrami) vyrieši zmätok končatín, budú pravdepodobne sklamaní. Nový model, ktorý bude uvedený na trh v r asi dva týždne, má práve premiéru na komerčnom portáli stability.ai štúdio snov, ktorý štandardne používa 1.5 a kde používatelia môžu porovnať nový výstup s vykreslením z ich lokálnych alebo iných systémov 1.4:

Zdroj: Local 1.4 prepack a https://beta.dreamstudio.ai/

Zdroj: Local 1.4 prepack a https://beta.dreamstudio.ai/

Zdroj: Local 1.4 prepack a https://beta.dreamstudio.ai/
Ako sa často stáva, kvalita údajov môže byť hlavnou príčinou.
Databázy s otvoreným zdrojovým kódom, ktoré poháňajú systémy syntézy obrazu, ako sú Stable Diffusion a DALL-E 2, sú schopné poskytnúť mnoho označení pre individuálnych ľudí aj medziľudské akcie. Tieto štítky sa trénujú symbioticky so súvisiacimi obrázkami alebo segmentmi obrázkov.

Používatelia Stable Diffusion môžu preskúmať koncepty zaškolené do modelu dotazovaním sa na súbor údajov LAION-aesthetics, podmnožinu väčšieho súboru údajov LAION 5B, ktorý poháňa systém. Obrázky sú zoradené nie podľa ich abecedného označenia, ale podľa ich „estetického skóre“. Zdroj: https://rom1504.github.io/clip-retrieval/
A dobrá hierarchia jednotlivých štítkov a tried prispievajúcich k zobrazeniu ľudskej ruky by bolo niečo podobné telo>paže>ruka>prsty>[číslice + palec]> [segmenty číslic]>nechty.

Granulovaná sémantická segmentácia častí ruky. Dokonca aj táto nezvyčajne podrobná dekonštrukcia ponecháva každý „prst“ ako jedinú entitu, ktorá neberie do úvahy tri časti prsta a dve časti palca. Zdroj: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
V skutočnosti je nepravdepodobné, že by zdrojové obrázky boli tak konzistentne anotované v celom súbore údajov a algoritmy označovania bez dozoru sa pravdepodobne zastavia na vyššia úroveň – napríklad – „ruky“ a vnútorné pixely (ktoré technicky obsahujú informácie o „prste“) ponechajú ako neoznačenú masu pixelov, z ktorých sa budú ľubovoľne odvodzovať vlastnosti a ktoré sa môžu prejaviť v neskorších vykresleniach ako rušivý prvok.

Ako by to malo byť (vpravo hore, ak nie v hornom reze) a ako to zvykne byť (vpravo dole) v dôsledku obmedzených zdrojov na označovanie alebo architektonického využitia takýchto označení, ak v súbore údajov existujú.
Ak sa teda model latentnej difúzie dostane až k vykresleniu ramena, takmer určite sa aspoň pokúsi vykresliť ruku na konci ramena, pretože paže>ruka je minimálna požadovaná hierarchia, pomerne vysoko v tom, čo architektúra vie o „ľudskej anatómii“.
Potom môžu byť „prsty“ najmenším zoskupením, aj keď pri zobrazovaní ľudských rúk je potrebné zvážiť ďalších 14 podčastí prstov/palcov.
Ak táto teória platí, neexistuje žiadna skutočná náprava v dôsledku nedostatku rozpočtu v celom sektore na ručnú anotáciu a nedostatku adekvátne účinných algoritmov, ktoré by mohli automatizovať označovanie a zároveň produkovať nízku chybovosť. V skutočnosti sa model môže v súčasnosti spoliehať na ľudskú anatomickú konzistenciu, aby prekryl nedostatky súboru údajov, na ktorom bol trénovaný.
Jeden z možných dôvodov prečo áno nemôže spoliehaj sa na to, nedávno navrhovanej na Stable Diffusion Discord je, že model by mohol byť zmätený ohľadom správneho počtu prstov, ktoré by (realistická) ľudská ruka mala mať, pretože databáza odvodená od LAION, ktorá ju poháňa, obsahuje kreslené postavičky, ktoré môžu mať menej prstov (čo je samo o sebe skratka šetriaca prácu).

Dvaja z potenciálnych vinníkov syndrómu „chýbajúceho prsta“ v Stable Diffusion a podobných modeloch. Nižšie sú uvedené príklady kreslených ručičiek z LAION-estetického súboru údajov napájajúcich Stable Diffusion. Zdroj: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Ak je to pravda, potom jediným zjavným riešením je preškoliť model s vylúčením nerealistického obsahu založeného na ľuďoch, čím sa zabezpečí, že skutočné prípady vynechania (tj amputácie) budú vhodne označené ako výnimky. Už len z hľadiska spracovania údajov by to bola veľká výzva, najmä v prípade úsilia komunity s nedostatkom zdrojov.
Druhým prístupom by bolo použiť filtre, ktoré vylúčia takýto obsah (tj „ruka s tromi/piatimi prstami“) z prejavu v čase vykresľovania, podobne ako OpenAI do určitej miery, filtrovaný GPT-3 a DALL-E2, takže ich výkon bolo možné regulovať bez potreby preškoľovania zdrojových modelov.

V prípade Stable Diffusion môže byť sémantický rozdiel medzi číslicami a dokonca končatinami hrozne rozmazaný, čím si spomeniete na hororové filmy typu „body horror“ z 1980. rokov od takých ako David Cronenberg. Zdroj: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Opäť by si to však vyžadovalo štítky, ktoré nemusia existovať na všetkých dotknutých obrázkoch, čo nám dáva rovnakú logistickú a rozpočtovú výzvu.
Dalo by sa tvrdiť, že vpred sú ešte dve cesty: vrhnúť na problém viac údajov a použiť interpretačné systémy tretích strán, ktoré môžu zasiahnuť, keď sa koncovému používateľovi prezentujú fyzické chyby tu opísaného typu (prinajmenšom, ten by dal OpenAI metódu na poskytovanie náhrad za vykreslenie „body horror“, ak by bola spoločnosť motivovaná tak urobiť).
3: Prispôsobenie
Jednou z najzaujímavejších možností pre budúcnosť Stable Diffusion je perspektíva používateľov alebo organizácií vyvíjajúcich revidované systémy; modifikácie, ktoré umožňujú integráciu obsahu mimo predtrénovanej sféry LAION do systému – ideálne bez nekontrolovateľných nákladov na opätovné trénovanie celého modelu alebo bez rizika spojeného s trénovaním veľkého množstva nových obrázkov na existujúce, zrelé a schopné Model.
Analogicky: ak dvaja menej nadaní študenti vstúpia do triedy pokročilých tridsiatich študentov, buď sa asimilujú a dobehnú, alebo zlyhajú ako odľahlí; v oboch prípadoch to pravdepodobne neovplyvní priemerný výkon triedy. Ak sa však zapojí 15 menej nadaných študentov, krivka známok pre celú triedu pravdepodobne utrpí.
Podobne, synergická a pomerne jemná sieť vzťahov, ktoré sa vytvárajú počas trvalého a drahého školenia modelov, môže byť narušená, v niektorých prípadoch účinne zničená, nadmerným množstvom nových údajov, čím sa celkovo zníži kvalita výstupu pre model.
Dôvod, prečo to urobiť, je v prvom rade tam, kde váš záujem spočíva v úplnom ovládnutí koncepčného chápania vzťahov a vecí modelu a privlastnení si ho na exkluzívnu produkciu obsahu, ktorý je podobný dodatočnému materiálu, ktorý ste pridali.
Teda tréning 500,000 XNUMX Simpsons snímky do existujúceho kontrolného bodu stabilnej difúzie pravdepodobne nakoniec vylepšíte Simpsons simulátor, než aký mohla ponúknuť pôvodná zostava, za predpokladu, že tento proces prežije dostatočne široké sémantické vzťahy (tj Homer Simpson jedol hotdog, ktorá môže vyžadovať materiál o hot-dogoch, ktorý nebol vo vašom dodatočnom materiáli, ale už existoval v kontrolnom bode) a za predpokladu, že nechcete náhle prejsť z Simpsons obsahu na tvorbu báječná krajina od Grega Rutkowského – pretože váš model po vytrénovaní má masívne odvrátenú pozornosť a nebude taký dobrý robiť takéto veci ako predtým.
Jedným z pozoruhodných príkladov je waifu-difúzia, ktorá úspešne prebehla dodatočne vyškolených 56,000 XNUMX anime obrázkov do dokončeného a vyškoleného kontrolného bodu stabilnej difúzie. Pre nadšencov je to však ťažká perspektíva, pretože tento model vyžaduje oku lahodiacich minimálne 30 GB VRAM, čo je ďaleko za hranicou toho, čo bude pravdepodobne dostupné na úrovni spotrebiteľov v pripravovaných vydaniach série 40XX od NVIDIA.

Trénovanie vlastného obsahu do stabilnej difúzie prostredníctvom waifu-difúzie: model trval dva týždne následného školenia, aby vytvoril túto úroveň ilustrácie. Šesť obrázkov naľavo ukazuje pokrok modelu, ako tréning pokračoval, pri vytváraní koherentného výstupu pre subjekt na základe nových tréningových údajov. Zdroj: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Na takéto „rozvetvenia“ kontrolných bodov stabilnej difúzie by sa dalo vynaložiť veľké úsilie, ktoré by však zmaril technický dlh. Vývojári z oficiálneho Discordu už naznačili, že neskoršie vydania kontrolných bodov nemusia byť nevyhnutne spätne kompatibilné, dokonca ani s promptnou logikou, ktorá mohla fungovať s predchádzajúcou verziou, pretože ich primárnym záujmom je získať čo najlepší model, a nie podporovať staršie aplikácie a procesy.
Preto spoločnosť alebo jednotlivec, ktorý sa rozhodne efektívne rozvetviť kontrolný bod na komerčný produkt, nemá cestu späť; ich verzia modelu je v tomto bode „hard fork“ a nebude môcť čerpať výhody z neskorších vydaní zo stránky stability.ai – čo je dosť veľký záväzok.
Súčasná a väčšia nádej na prispôsobenie Stable Diffusion je Textová inverzia, kde používateľ trénuje v malej hŕstke CLIP- zarovnané obrázky.

Vďaka spolupráci medzi Tel Avivskou univerzitou a NVIDIA umožňuje textová inverzia trénovať diskrétne a nové entity bez toho, aby sa zničili možnosti zdrojového modelu. Zdroj: https://textual-inversion.github.io/
Primárnym zjavným obmedzením textovej inverzie je, že sa odporúča veľmi nízky počet obrázkov – len päť. To efektívne vytvára obmedzenú entitu, ktorá môže byť užitočnejšia pre úlohy prenosu štýlu ako vkladanie fotorealistických objektov.
Napriek tomu v súčasnosti prebiehajú experimenty v rámci rôznych Stable Diffusion Discords, ktoré využívajú oveľa vyšší počet tréningových obrázkov, a ešte len uvidíme, ako produktívna sa táto metóda môže ukázať. Táto technika opäť vyžaduje veľa VRAM, času a trpezlivosti.
Kvôli týmto obmedzujúcim faktorom si možno budeme musieť chvíľu počkať, kým uvidíme niektoré zo sofistikovanejších experimentov s textovou inverziou od nadšencov Stable Diffusion – a či vás tento prístup dokáže „uviesť do obrazu“ spôsobom, ktorý vyzerá lepšie ako Photoshop vystrihne a prilepí, pričom si zachová ohromujúcu funkčnosť oficiálnych kontrolných bodov.
Prvýkrát uverejnené 6. septembra 2022.















