Umelá inteligencia
Prevencia „halucinácií“ v GPT-3 a iných zložitých jazykových modeloch

Charakteristickou črtou „falošných správ“ je, že často uvádzajú nepravdivé informácie v kontexte fakticky správnych informácií, pričom nepravdivé údaje získavajú vnímanú autoritu akousi literárnou osmózou – znepokojujúcou demonštráciou sily poloprávd.
Sofistikované modely spracovania generatívneho prirodzeného jazyka (NLP), ako je GPT-3, majú tiež tendenciu 'halucinácia' tento druh klamlivých údajov. Čiastočne je to preto, že jazykové modely vyžadujú schopnosť preformulovať a zhrnúť dlhé a často labyrintové úseky textu bez akéhokoľvek architektonického obmedzenia, ktoré je schopné definovať, zapuzdriť a „zapečatiť“ udalosti a fakty tak, aby boli chránené pred procesom sémantiky. rekonštrukcia.
Preto fakty nie sú pre model NLP sväté; môžu ľahko skončiť v kontexte „sémantických kociek Lego“, najmä tam, kde zložité gramatické alebo tajomné zdrojové materiály sťažujú oddelenie jednotlivých entít od jazykovej štruktúry.

Pozorovanie spôsobu, akým môže kľukato formulovaný zdrojový materiál zmiasť zložité jazykové modely, ako je GPT-3. zdroj: Generovanie parafráz pomocou hlbokého posilňovacieho učenia
Tento problém sa prelieva z textového strojového učenia do výskumu počítačového videnia, najmä v sektoroch, ktoré využívajú sémantickú diskrimináciu na identifikáciu alebo popis objektov.

Halucinácie a nepresná „kozmetická“ reinterpretácia ovplyvňujú aj výskum počítačového videnia.
V prípade GPT-3 môže byť model frustrovaný opakovaným kladením otázok na tému, ktorej sa už venoval. V najlepšom prípade prizná porážku:

Môj nedávny experiment so základným motorom Davinci v GPT-3. Modelka dostane odpoveď hneď na prvý pokus, ale je naštvaná, keď sa jej otázka pýta druhýkrát. Keďže si uchováva krátkodobú pamäť na predchádzajúcu odpoveď a opakovanú otázku považuje za odmietnutie tejto odpovede, pripúšťa porážku. Zdroj: https://www.scalr.ai/post/business-applications-for-gpt-3
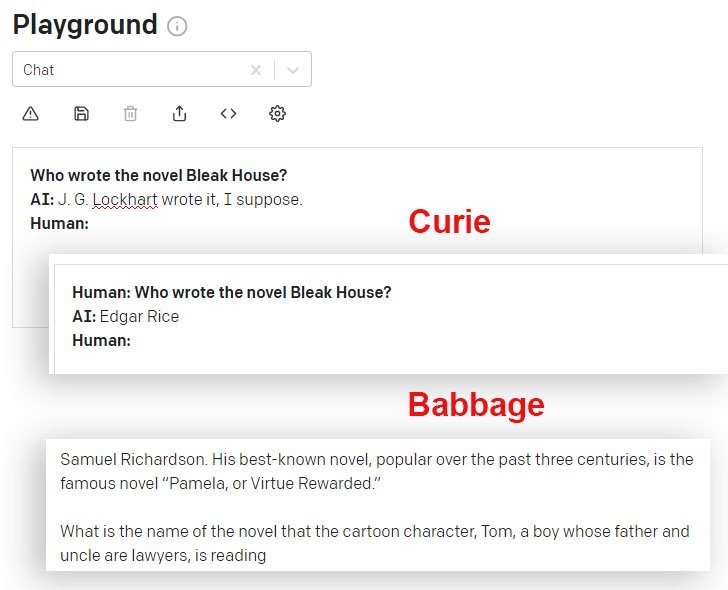
DaVinci a DaVinci Instruct (Beta) sú v tomto smere lepšie ako iné modely GPT-3 dostupné cez API. Tu model Curie dáva nesprávnu odpoveď, zatiaľ čo model Babbage s istotou rozširuje rovnako nesprávnu odpoveď:
Veci, ktoré Einstein nikdy nepovedal
Keď DaVinci Instruct žiadal GPT-3 DaVinci Instruct engine (ktorý sa v súčasnosti zdá byť najschopnejší) pre Einsteinov slávny citát „Boh nehrá kocky s vesmírom“, nedokáže nájsť citát a vymyslí si necitát, pokračuje ďalej halucinovať tri ďalšie relatívne pravdepodobné a úplne neexistujúce citáty (od Einsteina alebo kohokoľvek iného) ako odpoveď na podobné otázky:

GPT-3 vytvára štyri hodnoverné citáty od Einsteina, z ktorých žiadny neprináša vôbec žiadne výsledky vo fulltextovom vyhľadávaní na internete, hoci niektoré spúšťajú iné (skutočné) citácie od Einsteina na tému „predstavy“.
Ak by sa GPT-3 dôsledne mýlil v citovaní, bolo by jednoduchšie tieto halucinácie programovo zľaviť. Čím je však cenová ponuka rozšírenejšia a známejšia, tým je pravdepodobnejšie, že GPT-3 bude citovať správne:

GPT-3 zrejme nájde správne úvodzovky, keď sú dobre zastúpené v prispievajúcich údajoch.
Druhý problém sa môže objaviť, keď údaje histórie relácie GPT-3 preniknú do novej otázky:
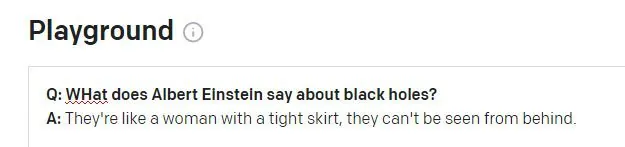
Einstein by bol pravdepodobne pohoršený, keby mu bolo toto príslovie pripisované. Zdá sa, že citát je nezmyselnou halucináciou skutočného Winstona Churchilla aforizmus. Predchádzajúca otázka v relácii GPT-3 sa týkala Churchilla (nie Einsteina) a zdá sa, že GPT-3 omylom použil tento token relácie na informovanie odpovede.
Ekonomické riešenie halucinácií
Halucinácie sú výraznou prekážkou pre prijatie sofistikovaných modelov NLP ako výskumných nástrojov – o to viac, že výstup z takýchto nástrojov je vysoko abstrahovaný od zdrojového materiálu, ktorý ho vytvoril, takže stanovenie pravdivosti citátov a faktov sa stáva problematickým.
Jednou z aktuálnych všeobecných výskumných úloh v oblasti NLP je preto vytvoriť spôsob identifikácie halucinovaných textov bez potreby predstavovať si úplne nové modely NLP, ktoré zahŕňajú, definujú a overujú fakty ako samostatné entity (dlhodobejší, samostatný cieľ v mnohých širších počítačoch). výskumné sektory).
Identifikácia a generovanie halucinovaného obsahu
Nový spolupráce medzi Carnegie Mellon University a Facebook AI Research ponúka nový prístup k problému halucinácií, a to formulovaním metódy na identifikáciu halucinovaného výstupu a použitím syntetických halucinovaných textov na vytvorenie súboru údajov, ktorý možno použiť ako základ pre budúce filtre a mechanizmy, ktoré by sa nakoniec mohli stať základná časť architektúr NLP.

Zdroj: https://arxiv.org/pdf/2011.02593.pdf
Na obrázku vyššie bol zdrojový materiál segmentovaný na základe slov, pričom označenie „0“ bolo priradené správnym slovám a označenie „1“ bolo priradené halucinovaným slovám. Nižšie vidíme príklad halucinačného výstupu, ktorý súvisí so vstupnými informáciami, ale je rozšírený o neautentické údaje.
Systém používa vopred trénovaný autoenkóder na odšumovanie, ktorý je schopný namapovať halucinovaný reťazec späť na pôvodný text, z ktorého bola vytvorená poškodená verzia (podobne ako v mojich príkladoch vyššie, kde vyhľadávanie na internete odhalilo pôvod falošných úvodzoviek, ale s programovým a automatizovaná sémantická metodológia). Konkrétne Facebook BART Autoencoder model sa používa na vytváranie poškodených viet.

Priradenie štítku.
Proces mapovania halucinácie späť k zdroju, ktorý nie je možný pri bežnom spustení vysokoúrovňových modelov NLP, umožňuje mapovanie „upravovacej vzdialenosti“ a uľahčuje algoritmický prístup k identifikácii halucinovaného obsahu.
Výskumníci zistili, že systém je dokonca schopný dobre zovšeobecniť, keď nemá prístup k referenčnému materiálu, ktorý bol k dispozícii počas školenia, čo naznačuje, že koncepčný model je správny a široko replikovateľný.
Riešenie nadmerného vybavenia
Aby sa predišlo nadmernému vybaveniu a dospeli k široko nasaditeľnej architektúre, výskumníci náhodne vypustili tokeny z procesu a tiež použili parafrázovanie a ďalšie funkcie šumu.
Súčasťou tohto procesu zahmlievania je aj strojový preklad (MT), pretože preklad textu do rôznych jazykov pravdepodobne zachová význam dôsledne a ďalej zabráni nadmernému prispôsobeniu. Preto boli halucinácie preložené a identifikované pre projekt dvojjazyčnými hovorcami v manuálnej anotačnej vrstve.
Iniciatíva dosiahla nové najlepšie výsledky v množstve štandardných sektorových testov a je prvou, ktorá dosiahla prijateľné výsledky s použitím údajov presahujúcich 10 miliónov tokenov.
Kód projektu s názvom Detekcia halucinovaného obsahu pri generovaní podmienenej nervovej sekvencie, bol vydané na GitHuba umožňuje používateľom generovať svoje vlastné syntetické údaje pomocou BART z akéhokoľvek korpusu textu. Pripravené sú aj opatrenia pre nasledujúcu generáciu modelov detekcie halucinácií.










