
Umelá inteligencia
LipSync3D od spoločnosti Google ponúka vylepšenú „hĺbkovú“ synchronizáciu pohybu úst

A spolupráce medzi výskumníkmi Google AI a Indian Institute of Technology Kharagpur ponúka nový rámec na syntetizovanie hovoriacich hláv zo zvukového obsahu. Cieľom projektu je vytvoriť optimalizované spôsoby s primeranými zdrojmi na vytváranie video obsahu „hovoriacej hlavy“ zo zvuku na účely synchronizácie pohybov pier s dabovaným alebo strojovo preloženým zvukom a na použitie v avataroch, v interaktívnych aplikáciách a iných prostrediach v reálnom čase.

Zdroj: https://www.youtube.com/watch?v=L1StbX9OznY
Modely strojového učenia trénované v tomto procese – nazývané LipSync3D – vyžadujú ako vstupné údaje iba jedno video identity cieľovej tváre. Potrubie na prípravu údajov oddeľuje extrakciu geometrie tváre od hodnotenia osvetlenia a iných aspektov vstupného videa, čo umožňuje ekonomickejší a cielenejší tréning.
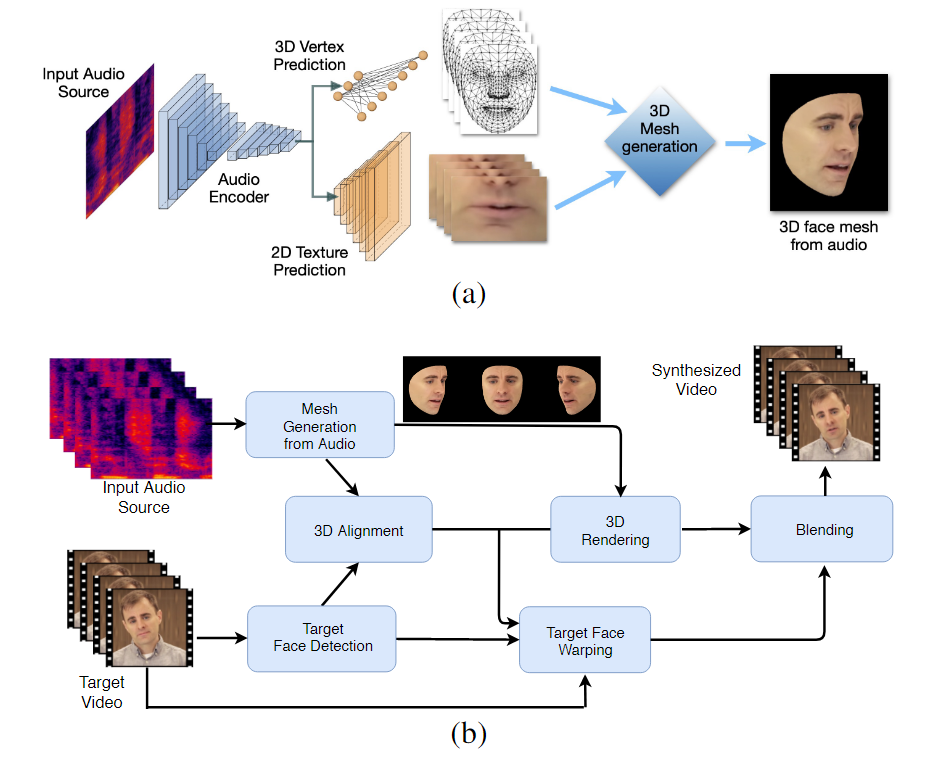
Dvojstupňový pracovný postup LipSync3D. Vyššie, generovanie dynamicky textúrovanej 3D tváre z „cieľového“ zvuku; nižšie, vloženie vygenerovanej siete do cieľového videa.
V skutočnosti môže byť najvýznamnejším príspevkom LipSync3D k výskumnému úsiliu v tejto oblasti jeho algoritmus normalizácie osvetlenia, ktorý oddeľuje tréning a inferenčné osvetlenie.

Oddelenie údajov o osvetlení od všeobecnej geometrie pomáha LipSync3D produkovať realistickejší výstup pohybu pier v náročných podmienkach. Iné prístupy posledných rokov sa obmedzili na „pevné“ svetelné podmienky, ktoré neprezrádzajú ich obmedzenejšiu kapacitu v tomto smere.
Počas predbežného spracovania vstupných dátových snímok musí systém identifikovať a odstrániť zrkadlové body, pretože tieto sú špecifické pre svetelné podmienky, za ktorých bolo video nasnímané, a inak budú interferovať s procesom opätovného osvetlenia.

LipSync3D, ako naznačuje jeho názov, nevykonáva iba pixelovú analýzu na tvárach, ktoré vyhodnocuje, ale aktívne využíva identifikované orientačné body tváre na generovanie pohyblivých sietí v štýle CGI spolu s „rozvinutými“ textúrami, ktoré sú okolo nich obalené v tradičnom CGI. potrubia.

Normalizácia pozície v LipSync3D. Vľavo sú vstupné rámce a zistené prvky; v strede normalizované vrcholy vyhodnotenia vygenerovanej siete; a napravo príslušný atlas textúr, ktorý poskytuje základnú pravdu pre predikciu textúr. Zdroj: https://arxiv.org/pdf/2106.04185.pdf
Vedci okrem novej metódy opätovného osvetlenia tvrdia, že LipSync3D ponúka tri hlavné inovácie predchádzajúcej práce: oddelenie geometrie, osvetlenia, pózy a textúry do diskrétnych dátových tokov v normalizovanom priestore; ľahko trénovateľný model automatickej regresnej predikcie textúr, ktorý vytvára časovo konzistentnú syntézu videa; a zvýšenú realistickosť hodnotenú ľudskými hodnoteniami a objektívnymi metrikami.

Rozdelenie rôznych aspektov obrazu tváre umožňuje väčšiu kontrolu pri syntéze videa.
LipSync3D dokáže odvodiť vhodný pohyb geometrie pier priamo zo zvuku analýzou fonémov a iných aspektov reči a ich prekladom do známych zodpovedajúcich svalových póz okolo oblasti úst.

Tento proces využíva kanál spoločnej predikcie, kde odvodená geometria a textúra majú vyhradené kódovače v nastavení automatického kódovania, ale zdieľajú kódovač zvuku s rečou, ktorá sa má vložiť do modelu:

Labilná pohybová syntéza LipSync3D je tiež určená na napájanie štylizovaných CGI avatarov, ktoré sú v skutočnosti len rovnakým druhom sieťových informácií a informácií o textúre ako obrazy v reálnom svete:
Štylizovaný 3D avatar má pohyby pier v reálnom čase poháňané videom zo zdrojového reproduktora. V takomto scenári by sa najlepšie výsledky dosiahli personalizovaným predtréningom.
Výskumníci tiež predpokladajú použitie avatarov s trochu realistickejším pocitom:
![]()
Vzorové tréningové časy pre videá sa pohybujú od 3-5 hodín pre 2-5-minútové video, v potrubí, ktoré používa TensorFlow, Python a C++ na GeForce GTX 1080. Školenia používali veľkosť dávky 128 snímok nad 500-1000 epoch, pričom každá epocha predstavuje kompletné vyhodnotenie videa.

Smerom k dynamickej re-synchronizácii pohybu pier
Oblasť opätovnej synchronizácie pier na prispôsobenie sa novej zvukovej stope si v posledných rokoch získala veľkú pozornosť vo výskume počítačového videnia (pozri nižšie), v neposlednom rade preto, že ide o vedľajší produkt kontroverznej technológia deepfake.
V roku 2017 University of Washington prezentovaný výskum schopný naučiť sa synchronizáciu pier zo zvuku a pomocou neho zmeniť pohyby pier vtedajšieho prezidenta Obamu. V roku 2018; viedol Inštitút Maxa Plancka pre informatiku ďalšia výskumná iniciatíva na umožnenie prenosu videa identity>identity so synchronizáciou pier a vedľajším produktom procesu; a v máji 2021 startup FlawlessAI s umelou inteligenciou odhalil svoju patentovanú technológiu synchronizácie pier TrueSync. obdržané v tlači ako prostriedok na zlepšenie dabingových technológií pre hlavné filmové vydania v rôznych jazykoch.
A, samozrejme, pokračujúci vývoj hlbokých otvorených zdrojových úložísk poskytuje ďalšie odvetvie aktívneho výskumu prispievajúceho používateľmi v tejto sfére syntézy obrázkov tváre.















