
ဉာဏ်ရည်တု
အစစ်အမှန်ရုပ်ပုံများအစား ကျပန်းဆူညံသံများကို ကွန်ပြူတာအမြင်ပုံစံများကို လေ့ကျင့်ခြင်း။

MIT Computer Science & Artificial Intelligence Laboratory (CSAIL) မှ သုတေသီများသည် ကွန်ပြူတာအမြင် မော်ဒယ်များကို လေ့ကျင့်ရန် ကွန်ပျူတာအမြင် ဒေတာအတွဲများတွင် ကျပန်းဆူညံသံပုံများကို အသုံးပြုကာ အမှိုက်ထုတ်မည့်အစား နည်းလမ်းသည် အံ့အားသင့်ဖွယ် ထိရောက်ကြောင်း တွေ့ရှိခဲ့သည်။

စွမ်းဆောင်ရည်အလိုက် စီထားသော စမ်းသပ်မှုမှ မျိုးဆက်သစ်မော်ဒယ်များ။ အရင်းအမြစ်- https://openreview.net/pdf?id=RQUl8gZnN7O
လူကြိုက်များသော ကွန်ပျူတာအမြင်ဗိသုကာများအတွင်းသို့ ထင်သာမြင်သာရှိသော 'မြင်သာသောအမှိုက်' ကို ကျွေးမွေးခြင်းသည် ဤစွမ်းဆောင်ရည်မျိုး မဖြစ်စေသင့်ပါ။ အထက်ပုံ၏ညာဘက်အစွန်တွင်၊ အနက်ရောင်ကော်လံများသည် တိကျမှုရမှတ်များကိုကိုယ်စားပြုသည် (ဖွင့်ထားသည်။ Imagenet-100) 'အစစ်အမှန်' ဒေတာအတွဲလေးခုအတွက်။ ၎င်း၏ရှေ့ရှိ 'ကျပန်းဆူညံသံ' ဒေတာအတွဲများ (အရောင်အမျိုးမျိုးဖြင့် ပြထားသည့် အညွှန်းအပေါ်-ဘယ်ဘက်တွင်ကြည့်ပါ) ၎င်းနှင့် ကိုက်ညီမှုမရှိသော်လည်း ၎င်းတို့အားလုံးနီးပါးသည် တိကျမှုအတွက် လေးစားဖွယ်ကောင်းသော အထက်နှင့်အောက် ဘောင်များ (အနီရောင် မျဉ်းကြောင်းများ) အတွင်းတွင် ရှိနေပါသည်။
ဤသဘောအရ 'တိကျမှု' သည် ရလဒ်တစ်ခုနှင့်တူသည်ဟု မဆိုလိုပါ။ မျက်နှာတစ်ဦး ဘုရားရှိခိုးကြောငျးတစ်ဦး ပီဇာသို့မဟုတ် သင်ဖန်တီးရန် စိတ်ဝင်စားနိုင်သည့် အခြားသော သီးခြားဒိုမိန်းတစ်ခု ရုပ်ပုံပေါင်းစပ်မှု Generative Adversarial Network၊ သို့မဟုတ် ကုဒ်ဒါ/ကုဒ်ဒါဘောင်ကဲ့သို့သော စနစ်။
ယင်းအစား၊ CSAIL မော်ဒယ်များသည် ရုပ်ပုံဒေတာမှ ကျယ်ပြန့်စွာ အသုံးချနိုင်သော ဗဟို 'အမှန်တရားများ' မှ ဆင်းသက်လာသောကြောင့် ၎င်းကို ထောက်ပံ့ပေးနိုင်စွမ်းမရှိစေရဟု ထင်သာမြင်သာဖြင့် ဖွဲ့စည်းတည်ဆောက်ထားခြင်း မရှိဟု ဆိုလိုသည်။
မတူကွဲပြားမှု Vs. သဘာဝတရား
ဤရလဒ်များကို လည်း မသတ်မှတ်နိုင်ပါ။ အလွန်လျောက်ပတ်စွာ: သွက်တယ်။ ဆွေးနွေးမှု Open Review မှ စာရေးဆရာများနှင့် သုံးသပ်သူများကြားတွင် အမြင်အာရုံကွဲပြားသော ဒေတာအတွဲများမှ မတူညီသောအကြောင်းအရာများ (ဥပမာ 'dead leaf'၊ 'fractals' နှင့် 'procedural noise' ကဲ့သို့ - အောက်ပုံတွင်ကြည့်ပါ) လေ့ကျင့်ရေးဒေတာအတွဲသို့ ရောစပ်ထားသည်ကို ဖော်ပြသည်။ တကယ်တော့ တိုးတက် ဟုတ်မှန်ရေး ဤစမ်းသပ်မှုများတွင်။
၎င်းသည် 'မတူကွဲပြားခြင်း' သည် 'သဘာဝဝါဒ' ကို လွှမ်းမိုးသည့် 'အံဝင်ခွင်ကျ' အမျိုးအစားသစ်တစ်မျိုးကို အကြံပြုထားသည်။
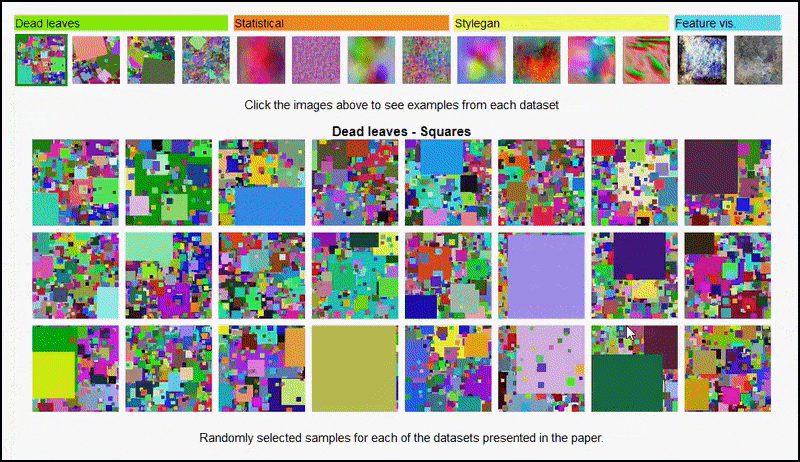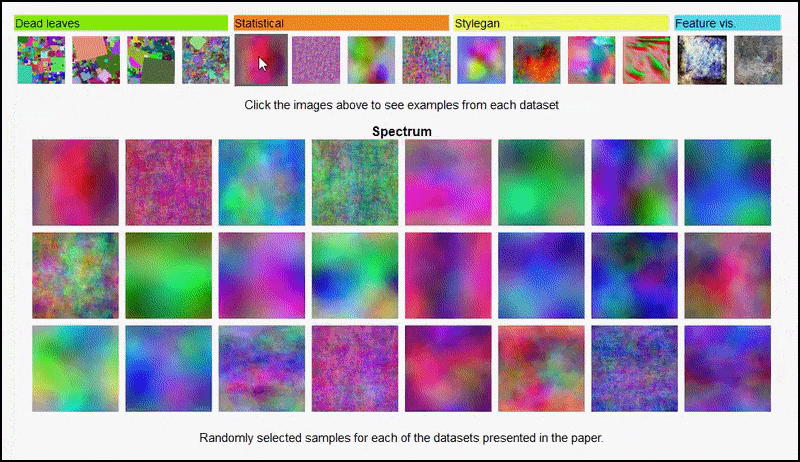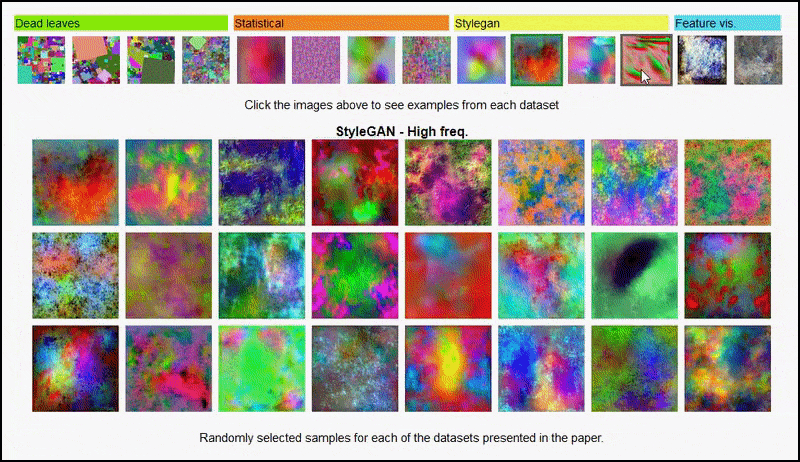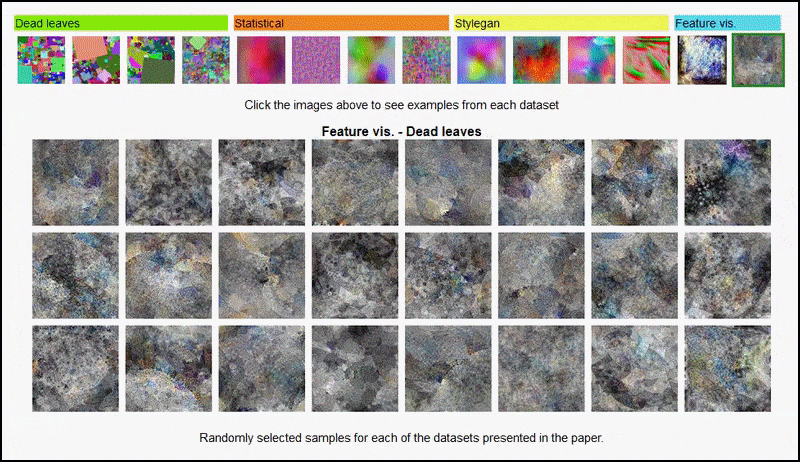
အဆိုပါ စီမံကိန်းစာမျက်နှာ ပဏာမခြေလှမ်းအတွက် စမ်းသပ်မှုတွင် အသုံးပြုသည့် ကျပန်းပုံဒေတာအတွဲများ၏ ကွဲပြားသော အမျိုးအစားများကို အပြန်အလှန်တုံ့ပြန်ကြည့်ရှုနိုင်စေပါသည်။ အရင်းအမြစ်- https://mbaradad.github.io/learning_with_noise/
သုတေသီများရရှိသော ရလဒ်များသည် ရုပ်ပုံအခြေခံသော အာရုံကြောကွန်ရက်များနှင့် ၎င်းတို့ကို ထိတ်လန့်ကြောက်ရွံ့ဖွယ်ရာ လွှင့်ပစ်သည့် 'ကမ္ဘာမြေ' ပုံရိပ်များကြား အခြေခံဆက်ဆံရေးကို မေးခွန်းထုတ်စရာဖြစ်လာသည်။ ပိုများသော volumes နှစ်စဉ်နှစ်တိုင်း ရယူရန်၊ ပြုပြင်ရန်နှင့် အခြားနည်းဖြင့် ငြင်းခုံရန် လိုအပ်သည်ဟု ဆိုလိုသည်။ hyperscale ပုံဒေတာအတွဲများ မလိုအပ်တော့တာတွေ ဖြစ်လာနိုင်ပါတယ်။ စာရေးသူက ဤသို့ဆိုသည်-
'လက်ရှိအမြင်အာရုံစနစ်များကို ကြီးမားသောဒေတာအတွဲများပေါ်တွင် လေ့ကျင့်သင်ကြားထားပြီး အဆိုပါဒေတာအတွဲများသည် ကုန်ကျစရိတ်များဖြင့် လာပါသည်- ပြုပြင်ရေးသည် စျေးကြီးသည်၊ ၎င်းတို့သည် လူသားတို့၏ ဘက်လိုက်မှုများကို အမွေဆက်ခံကာ၊ ကိုယ်ရေးကိုယ်တာနှင့် အသုံးပြုမှုအခွင့်အရေးများအပေါ် စိုးရိမ်မှုများရှိသည်။ ဤကုန်ကျစရိတ်များကို တန်ပြန်ရန်၊ အညွှန်းမပါသော ပုံများကဲ့သို့သော စျေးသက်သာသော ဒေတာရင်းမြစ်များမှ သင်ယူမှုကို စိတ်ဝင်စားမှု မြင့်တက်လာခဲ့သည်။
'ဤစာတမ်းတွင်၊ ကျွန်ုပ်တို့သည် အဆင့်တစ်ဆင့်တက်ပြီး လုပ်ထုံးလုပ်နည်း ဆူညံသံများကို သင်ယူခြင်းဖြင့် အမှန်တကယ် ရုပ်ပုံဒေတာအတွဲများကို လုံးလုံးလျားလျား ဖယ်ရှားနိုင်မလား။
လက်ရှိ machine learning Architecture ၏ ကောက်နှုတ်ချက်သည် ယခင်က ထင်ထားသည်ထက် ပို၍ အခြေခံကျသော (သို့မဟုတ် အနည်းဆုံး၊ မမျှော်လင့်ထားသော) ရုပ်ပုံများမှ တစ်စုံတစ်ရာကို ရည်ညွှန်းနေခြင်း ဖြစ်နိုင်ကြောင်း သုတေသီများက အကြံပြုထားပြီး အဆိုပါ 'အဓိပ္ပါယ်မဲ့' ပုံများသည် ဤအသိပညာကို ပိုမိုများပြားစွာ ပေးနိုင်သည် သင်တန်းအချိန်အတွင်း ကျပန်းပုံများကိုထုတ်ပေးသည့် dataset-generation architectures မှတဆင့် ad hoc synthetic data ကို စျေးပေါပေါဖြင့်၊
''လေ့ကျင့်ရေးအမြင်စနစ်များအတွက် ကောင်းမွန်သောပေါင်းစပ်အချက်အလက်များကိုရရှိစေသည့် အဓိကဂုဏ်သတ္တိနှစ်ခုကို ခွဲခြားသတ်မှတ်ထားသည်- 1) သဘာဝတရား၊ 2) ကွဲပြားမှု။ စိတ်ဝင်စားစရာမှာ သဘာဝဆန်သော အချက်အလက်အများစုသည် မတူကွဲပြားမှု၏ကုန်ကျစရိတ်ဖြင့် သဘာဝအလျောက်ရောက်လာနိုင်သောကြောင့် အမြဲတမ်းအကောင်းဆုံးမဟုတ်ပေ။
'သဘာဝဆန်သော ဒေတာအကူအညီသည် အံ့သြစရာမဟုတ်ပေ၊ အမှန်တကယ်တွင် ကြီးမားသော အချက်အလက်များသည် တန်ဖိုးရှိကြောင်း ညွှန်ပြနေပါသည်။ သို့သော်၊ အရေးကြီးသည်မှာ ဒေတာဖြစ်ရန် မဟုတ်ပါ။ စစ်မှန်သော ဒါပေမယ် သဘာဝဆန်သောဆိုလိုသည်မှာ အစစ်အမှန်ဒေတာ၏ အချို့သောဖွဲ့စည်းပုံဆိုင်ရာ ဂုဏ်သတ္တိများကို ဖမ်းယူရမည်ဖြစ်သည်။
'ဤဂုဏ်သတ္တိများစွာကို ရိုးရှင်းသော ဆူညံသံပုံစံများဖြင့် ဖမ်းယူနိုင်သည်။'

3rd နှင့် 5th (နောက်ဆုံး) convolutional အလွှာကို ဖုံးအုပ်ထားသည့် အမျိုးမျိုးသော 'ကျပန်းပုံ' ဒေတာအတွဲများမှ အချို့သော AlexNet မှရရှိသော ကုဒ်ကုဒ်ဒါမှ ရရှိလာသော အသွင်အပြင်များကို သရုပ်ဖော်ထားပါသည်။ ဤနေရာတွင် အသုံးပြုသည့် နည်းစနစ်မှာ အောက်ပါအတိုင်းဖြစ်သည်။ 2017 မှ Google AI သုတေသန.
အဆိုပါ စက္ကူဆစ်ဒနီတွင် 35th Conference on Neural Information Processing Systems (NeurIPS 2021) ခေါင်းစဉ်ဖြင့် တင်ပြထားသည်။ Noise ကို ကြည့်ခြင်းဖြင့် မြင်ရန် သင်ယူခြင်း။နှင့် CSAIL မှ သုတေသီခြောက်ဦးတို့မှ တူညီသောပံ့ပိုးကူညီမှုဖြင့် လာပါသည်။
အလုပ်ဖြစ်ခဲ့တယ်။ အကြံပြု NeurIPS 2021 တွင် အလေးပေးရွေးချယ်မှုတစ်ခုအတွက် တူညီသောမှတ်ချက်ပေးသူများသည် စာတမ်းအား 'သိပ္ပံဆိုင်ရာအောင်မြင်မှုများ' အဖြစ်သတ်မှတ်ပေးကာ 'လေ့လာမှု၏ကြီးမားသောနယ်ပယ်' ကိုဖွင့်ပေးသည့်အနေဖြင့် ၎င်းသည် အဖြေရှိသလောက်မေးခွန်းများစွာကို ပေါ်ပေါက်စေသည့်တိုင်၊
စာတမ်းတွင် စာရေးသူ ကောက်ချက်ချသည်-
'သဘာဝရုပ်ပုံစာရင်းအင်းဆိုင်ရာ ယခင်သုတေသနပြုချက်များမှ ရလဒ်များကို အသုံးပြု၍ ဒီဇိုင်းထုတ်သောအခါ၊ ဤဒေတာအတွဲများသည် အမြင်အာရုံကိုယ်စားပြုမှုများကို အောင်မြင်စွာ လေ့ကျင့်ပေးနိုင်ကြောင်း ကျွန်ုပ်တို့ပြသခဲ့သည်။ ဤစာတမ်းသည် မတူကွဲပြားသော အမြင်ဆိုင်ရာ လုပ်ငန်းဆောင်တာများတွင် အသုံးပြုသည့်အခါ ပိုမိုမြင့်မားသော စွမ်းဆောင်ရည်ကို ရရှိစေမည့် ဖွဲ့စည်းတည်ဆောက်ထားသော ဆူညံသံများကို ထုတ်လုပ်နိုင်စွမ်းရှိသော မျိုးဆက်သစ်မော်ဒယ်များကို လေ့လာရန် လှုံ့ဆော်ပေးမည်ဟု ကျွန်ုပ်တို့ မျှော်လင့်ပါသည်။
'ImageNet pretraining ဖြင့် ရရှိသော စွမ်းဆောင်ရည်နှင့် ကိုက်ညီနိုင်ပါမည်လား။ အလုပ်တစ်ခုအတွက် သီးခြားသတ်မှတ်ထားသော ကြီးမားသောလေ့ကျင့်မှုတစ်ခုမရှိလျှင် အကောင်းဆုံးကြိုတင်လေ့ကျင့်မှုသည် ImageNet ကဲ့သို့သော စံအမှန်တကယ်ဒေတာအစုံကို အသုံးပြုနေမည်မဟုတ်ပေ။'















