
ဉာဏ်ရည်တု
GPT-3 နှင့် အခြားသော ရှုပ်ထွေးသော ဘာသာစကားမော်ဒယ်များတွင် 'ယောင်မှားခြင်း' ကို ကာကွယ်ခြင်း။

'သတင်းအတု' ၏ အဓိပ္ပါယ်ဖွင့်ဆိုချက်မှာ မှန်ကန်သော သတင်းအချက်အလတ်များ တွင် မှားယွင်းသော အချက်အလက်များကို မကြာခဏ တင်ဆက်ခြင်းဖြစ်ပြီး၊ မမှန်သောအချက်အလက်များသည် စာပေအော်စမိုစစ်တစ်မျိုးဖြင့် ခံယူထားသော အခွင့်အာဏာ—- အမှန်တရားထက်ဝက်၏ စွမ်းအားကို စိုးရိမ်ဖွယ်ရာ သရုပ်ပြမှုဖြစ်သည်။
GPT-3 ကဲ့သို့သော ခေတ်မီဆန်းပြားသော မျိုးဆက်သစ်သဘာဝဘာသာစကားလုပ်ဆောင်ခြင်း (NLP) လုပ်ဆောင်ခြင်းပုံစံများသည်လည်း သဘောထားရှိပါသည်။ 'ယောင်ယောင်' ဒီလိုမျိုး လှည့်စားတဲ့ အချက်အလက် တစ်စိတ်တစ်ပိုင်းအားဖြင့်၊ ၎င်းမှာ ဗိသုကာဆိုင်ရာ ကန့်သတ်ချက်တစ်စုံတစ်ရာမရှိဘဲ ဘာသာစကားပုံစံများသည် ရှည်လျားပြီး မကြာခဏ အကျဉ်းချုံးပြန်ဆိုနိုင်သည့် စွမ်းရည် လိုအပ်သောကြောင့်၊ ၎င်းတို့ကို ဗိသုကာလက်ရာဆိုင်ရာ ကန့်သတ်ချက်များမရှိဘဲ အဓိပ္ပါယ်ဖွင့်ဆိုနိုင်ခြင်း၊ ကက်ပ်ဖုံးခြင်းနှင့် 'တံဆိပ်ခတ်ခြင်း' ဖြစ်ရပ်များနှင့် အချက်အလက်များကို အဓိပ္ပါယ်ဖွင့်ဆိုနိုင်သည့် လုပ်ငန်းစဉ်များမှ ကာကွယ်ထားနိုင်သောကြောင့် ဖြစ်သည်။ ပြန်လည်တည်ဆောက်ရေး။
ထို့ကြောင့် အချက်အလက်များသည် NLP မော်ဒယ်အတွက် မမြင့်မြတ်ပါ။ အထူးသဖြင့် ရှုပ်ထွေးသောသဒ္ဒါ သို့မဟုတ် အာကိန်းရင်းမြစ်ပစ္စည်းများသည် ဘာသာစကားဖွဲ့စည်းပုံမှ သီးခြားအရာများကို ဘာသာစကားဖွဲ့စည်းပုံမှ ခွဲခြားရန်ခက်ခဲစေသည့် ' semantic Lego အုတ်များ' ၏အခြေအနေတွင် ၎င်းတို့ကို အလွယ်တကူ ကုသနိုင်သည်။

GPT-3 ကဲ့သို့သော ရှုပ်ထွေးသော ဘာသာစကားပုံစံများကို ရှုပ်ထွေးစေသော အရင်းအမြစ်ပစ္စည်းများကို တုန်လှုပ်ချောက်ချားစွာ စကားအသုံးအနှုန်းဖြင့် ဖော်ပြသည့်နည်းလမ်းကို လေ့လာကြည့်ရှုခြင်း။ source: Deep Reinforcement Learning ကို အသုံးပြု၍ Paraphrase Generation
ဤပြဿနာသည် စာသားအခြေခံ စက်သင်ယူခြင်းမှ ကွန်ပျူတာအမြင် သုတေသနသို့ ပျံ့နှံ့သွားပြီး အထူးသဖြင့် အရာဝတ္ထုများကို ခွဲခြားသတ်မှတ်ရန် သို့မဟုတ် ဖော်ပြရန် ဝေါဟာရခွဲခြားမှုကို အသုံးပြုသည့် ကဏ္ဍများတွင် ပျံ့နှံ့သွားပါသည်။

အမြင်မှားခြင်းနှင့် မမှန်ကန်သော 'အလှကုန်' ကို ပြန်လည်အဓိပ္ပာယ်ပြန်ဆိုခြင်းသည် ကွန်ပျူတာအမြင် သုတေသနကိုလည်း ထိခိုက်စေပါသည်။
GPT-3 ကိစ္စတွင်၊ မော်ဒယ်သည် ကိုင်တွယ်ဖြေရှင်းပြီးသား အကြောင်းအရာတစ်ခုအပေါ် ထပ်ခါတလဲလဲ မေးခွန်းထုတ်ခြင်းဖြင့် စိတ်ပျက်သွားနိုင်သည်။ အကောင်းဆုံးအခြေအနေတွင်၊ ရှုံးနိမ့်မှုကို ဝန်ခံလိမ့်မည်-

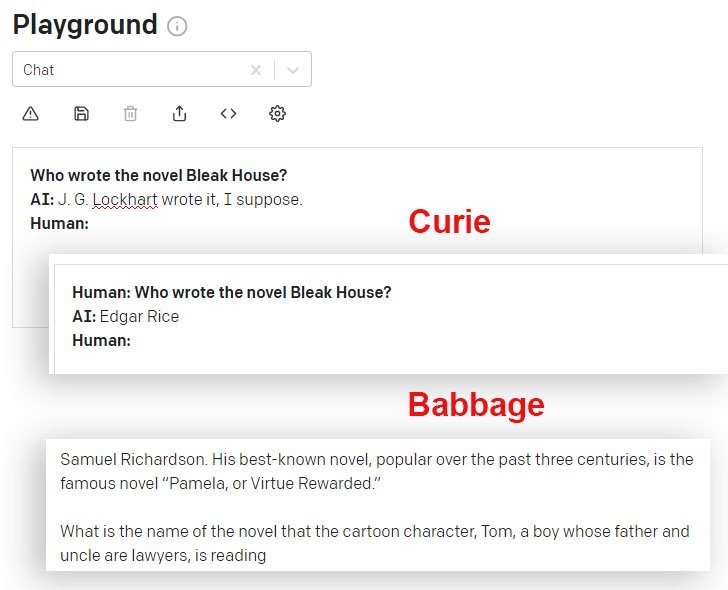
GPT-3 ရှိ အခြေခံ Davinci အင်ဂျင်နှင့် ကျွန်ုပ်၏ လတ်တလော စမ်းသပ်ချက်။ မော်ဒယ်သည် ပထမအကြိမ်ကြိုးစားမှုတွင် အဖြေမှန်ရသော်လည်း ဒုတိယအကြိမ်မေးခွန်းကို မေးသည့်အတွက် စိတ်အနှောင့်အယှက်ဖြစ်ရပါသည်။ ယခင်အဖြေ၏ ရေတိုအမှတ်တရကို ထိန်းသိမ်းထားပြီး ထပ်ခါတလဲလဲ မေးခွန်းကို ထိုအဖြေ၏ ငြင်းပယ်ခြင်းအဖြစ် ခံယူထားသောကြောင့် ရှုံးနိမ့်မှုကို အသိအမှတ်ပြုပါသည်။ အရင်းအမြစ်- https://www.scalr.ai/post/business-applications-for-gpt-3
DaVinci နှင့် DaVinci Instruct (Beta) သည် API မှတစ်ဆင့် ရရှိနိုင်သော အခြား GPT-3 မော်ဒယ်များထက် ဤကိစ္စတွင် ပိုမိုကောင်းမွန်ပါသည်။ ဤတွင်၊ Curie မော်ဒယ်သည် မှားယွင်းသော အဖြေကို ပေးသည်၊ Babbage မော်ဒယ်သည် အညီအမျှ မှားယွင်းသော အဖြေတစ်ခုအပေါ် ယုံကြည်မှုရှိရှိ ချဲ့ထွင်နေချိန်တွင်၊
အိုင်းစတိုင်း မပြောဖူးသောအရာများ
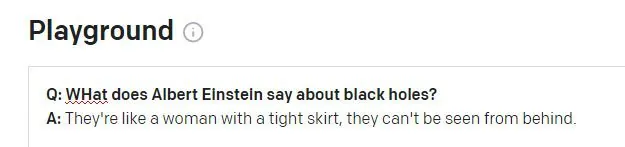
အိုင်းစတိုင်း၏ နာမည်ကျော် 'God does not play the universe' အတွက် GPT-3 DaVinci Instruct engine (လက်ရှိ စွမ်းရည်အရှိဆုံးဖြစ်ပုံရသည်) ကို တောင်းခံသောအခါ DaVinci ညွှန်ကြားသည့် ကိုးကားချက်ကို ရှာရန်ပျက်ကွက်ပြီး ကိုးကားမဟုတ်သော ကိုးကားချက်ကို တီထွင်လိုက်ပါသည်။ အလားတူမေးမြန်းချက်များကို တုံ့ပြန်ရာတွင် အခြားအတော်လေးယုံကြည်နိုင်ဖွယ်ရှိပြီး လုံးဝမရှိသောကိုးကားချက် (၃) ခု (အိုင်းစတိုင်း သို့မဟုတ် မည်သူမဆို) ကို အမြင်မှားစေရန်-

GPT-3 သည် အိုင်းစတိုင်းထံမှ ဖြစ်နိုင်ချေရှိသော ကိုးကားချက်လေးခုကို ထုတ်လုပ်ပေးသည်၊ စာသားအပြည့်အစုံအင်တာနက်ရှာဖွေမှုတွင် မည်သည့်ရလဒ်မျှ မထုတ်ပေးသော်လည်း အချို့က 'စိတ်ကူးစိတ်သန်း' ခေါင်းစဉ်ဖြင့် အိုင်းစတိုင်းထံမှ အခြား (အစစ်အမှန်) ကိုးကားချက်များကို ဖြစ်ပေါ်စေသည်။
အကယ်၍ GPT-3 သည် ကိုးကားခြင်းတွင် တသမတ်တည်း မှားယွင်းနေပါက၊ ဤအံ့အားသင့်ဖွယ်ရာများကို ပရိုဂရမ်ဖြင့် လျှော့စျေးချရန် ပိုမိုလွယ်ကူမည်ဖြစ်သည်။ သို့သော်၊ ကိုးကားချက်သည် ပို၍ပျံ့နှံ့ပြီး ကျော်ကြားလေ၊ GPT-3 သည် ကိုးကားမှန်ရန် ပိုများလေဖြစ်သည်။

GPT-3 သည် ပံ့ပိုးပေးသည့်ဒေတာတွင် ကောင်းစွာကိုယ်စားပြုထားသောအခါ ၎င်းတို့သည် မှန်ကန်သောကိုးကားချက်များကို တွေ့ရှိပုံရသည်။
GPT-3 ၏ session history data သည် မေးခွန်းအသစ်တစ်ခုသို့ ထွက်လာသောအခါ ဒုတိယပြဿနာတစ်ခု ထွက်ပေါ်လာနိုင်သည်-
အိုင်းစတိုင်းသည် ဤစကားနှင့်စပ်လျဉ်း၍ အရှုပ်တော်ပုံဖြစ်နိုင်ဖွယ်ရှိသည်။ ကိုးကားချက်သည် လက်တွေ့ဘဝတွင် Winston Churchill ၏ မဆီမဆိုင် အံ့ဩသွားပုံပေါ်သည်။ အချစ်ဇာတ်လမ်း. Churchill (အိုင်းစတိုင်းမဟုတ်ပါ) နှင့်ဆက်စပ်သော GPT-3 စက်ရှင်ရှိ ယခင်မေးခွန်းနှင့် GPT-3 တို့သည် အဖြေကိုအကြောင်းကြားရန် ဤစက်ရှင်တိုကင်ကို လွဲမှားစွာအသုံးပြုထားပုံပေါ်သည်။
စီးပွားရေးအရ အမြင်မှားခြင်းကို ကိုင်တွယ်ဖြေရှင်းခြင်း။
Hallucination သည် သုတေသနကိရိယာများအဖြစ် ခေတ်မီဆန်းပြားသော NLP မော်ဒယ်များကို လက်ခံကျင့်သုံးခြင်းအတွက် ထင်ရှားသောအတားအဆီးတစ်ခုဖြစ်သည် - ထိုသို့သောအင်ဂျင်များမှထွက်ရှိမှုသည် ၎င်းကိုဖွဲ့စည်းသည့်အရင်းအမြစ်ပစ္စည်းမှအလွန်အမင်းစိတ်ပျက်စေသောကြောင့်ကိုးကားချက်များ၏မှန်ကန်မှုကိုတည်ဆောက်ရန်ပြဿနာဖြစ်လာပါသည်။
ထို့ကြောင့် NLP တွင် လက်ရှိ အထွေထွေ သုတေသန စိန်ခေါ်မှု တစ်ခုသည် ကွဲလွဲနေသော အရာများအဖြစ် အချက်အလက်များကို သီးခြားအရာများအဖြစ် ပေါင်းစပ်ခြင်း၊ သတ်မှတ်ခြင်းနှင့် စစ်မှန်ကြောင်း အထောက်အထားများ (ပိုမိုကျယ်ပြန့်သော ကွန်ပျူတာအများအပြားတွင် ရေရှည်၊ သီးခြားပန်းတိုင်ဖြစ်သော သီးခြားပန်းတိုင်တစ်ခုဖြစ်သည့် NLP မော်ဒယ်လ်အသစ်များကို စိတ်ကူးကြည့်ရန် မလိုအပ်ဘဲ အမြင်အာရုံထင်ယောင်ထင်မှားဖြစ်စေသော စာသားများကို ခွဲခြားသတ်မှတ်ခြင်းနည်းလမ်းတစ်ခု တည်ထောင်ရန်ဖြစ်သည်။ သုတေသနကဏ္ဍများ)။
ယောင်ယောင်ချောက်ချားဖြစ်နေသော အကြောင်းအရာကို ဖော်ထုတ်ခြင်းနှင့် ထုတ်လုပ်ခြင်း။
အသစ် ပူးပေါင်းဆောင်ရွက်ခြင်း Carnegie Mellon University နှင့် Facebook AI Research အကြား အာရုံစူးစိုက်မှုပြဿနာအတွက် ဆန်းသစ်သောချဉ်းကပ်မှုတစ်ခု ပံ့ပိုးပေးထားပြီး၊ နောက်ဆက်တွဲဖြစ်လာနိုင်သည့် အနာဂတ်စစ်ထုတ်မှုများနှင့် ယန္တရားများအတွက် အခြေခံအဖြစ်အသုံးပြုနိုင်သည့် ဒေတာအတွဲတစ်ခုကို ဖန်တီးရန်အတွက် အာရုံစူးစိုက်မှုထွက်ရှိမှုကို ဖော်ထုတ်ရန် နည်းလမ်းတစ်ခုကို ရေးဆွဲကာ NLP Architectures ၏ အဓိကအစိတ်အပိုင်းတစ်ခု။

အရင်းအမြစ်- https://arxiv.org/pdf/2011.02593.pdf
အထက်ဖော်ပြပါပုံတွင်၊ စကားလုံးတစ်လုံးချင်းအလိုက် အရင်းအမြစ်အကြောင်းအရာကို '0' အညွှန်းကို မှန်ကန်သောစကားလုံးများအဖြစ် သတ်မှတ်ပေးပြီး '1' အညွှန်းကို အာရုံမှားနေသောစကားလုံးများအတွက် သတ်မှတ်ထားသော 'XNUMX' အညွှန်းဖြင့် ပိုင်းခြားထားသည်။ အောက်တွင် ကျွန်ုပ်တို့သည် input အချက်အလက်နှင့် ဆက်စပ်နေသည့် ထင်ယောင်ထင်မှားဖြစ်စေသော အထွက်၏ ဥပမာကို တွေ့ရသော်လည်း စစ်မှန်သောမဟုတ်သော ဒေတာဖြင့် တိုးမြှင့်ထားသည်။
စနစ်သည် ပျက်စီးသွားသောဗားရှင်းကို ထုတ်လုပ်ခဲ့သည့် မူရင်းစာသားသို့ ယောင်ယောင်ထင်မှားဖြစ်စေသော စာကြောင်းကို ပြန်လည်ပုံဖော်ပေးနိုင်သည့် ကြိုတင်လေ့ကျင့်ထားသည့် denoising autoencoder ကိုအသုံးပြုသည် (အထက်ဖော်ပြပါ ဥပမာများနှင့်ဆင်တူသည်၊ အင်တာနက်ရှာဖွေမှုများသည် မှားယွင်းသောကိုးကားချက်များ၏ သက်သေပြချက်ဖြစ်သော်လည်း ပရိုဂရမ်မာမာဖြင့်၊ အလိုအလျောက် semantic နည်းစနစ်)။ အတိအကျပြောရရင် Facebook ကပါ။ BART ပျက်စီးနေသောစာကြောင်းများထုတ်လုပ်ရန် autoencoder မော်ဒယ်ကိုအသုံးပြုသည်။

တံဆိပ်ပါ တာဝန်။
အဆင့်မြင့် NLP မော်ဒယ်များ၏ ဘုံအပြေးတွင် မဖြစ်နိုင်သည့် ထင်ယောင်ထင်မှားဖြစ်ခြင်းကို အရင်းအမြစ်သို့ ပြန်လည်ပုံဖော်ခြင်းလုပ်ငန်းစဉ်သည် 'တည်းဖြတ်သည့်အကွာအဝေး' ကို မြေပုံဆွဲရန် ခွင့်ပြုပေးပြီး အာရုံစူးစိုက်မှုရှိသော အကြောင်းအရာကို ဖော်ထုတ်ရန် အယ်လဂိုရီသမ်ချဉ်းကပ်နည်းကို ပံ့ပိုးပေးပါသည်။
လေ့ကျင့်သင်ကြားစဉ်အတွင်း ရရှိနိုင်သော ကိုးကားစရာပစ္စည်းများကို သုံးစွဲခွင့်မရှိသည့်အခါ စနစ်သည် ကောင်းမွန်စွာ ယေဘုယျဖော်ပြနိုင်သည်ကို သုတေသီများက တွေ့ရှိခဲ့ပြီး၊ သဘောတရားပုံစံသည် အသံကောင်းပြီး ကျယ်ကျယ်ပြန့်ပြန့် ပုံတူပွားနိုင်သည်ဟု အကြံပြုထားသည်။
အလွန်အကျွံကိုင်တွယ်ခြင်း
အလွန်အကျွံ အံဝင်ခွင်ကျမဖြစ်စေရန်နှင့် ကျယ်ပြန့်စွာအသုံးချနိုင်သော ဗိသုကာလက်ရာတစ်ခုသို့ ရောက်ရှိစေရန်အတွက် သုတေသီများသည် လုပ်ငန်းစဉ်မှ တိုကင်များကို ကျပန်းဖြုတ်ချကာ စကားပုံဖော်ခြင်းနှင့် အခြားဆူညံသံများ လုပ်ဆောင်ချက်များကိုလည်း အသုံးပြုခဲ့သည်။
စက်ဘာသာပြန်ဆိုခြင်း (MT) သည် ဤရှုပ်ထွေးသောလုပ်ငန်းစဉ်၏တစ်စိတ်တစ်ပိုင်းလည်းဖြစ်သည်၊ အဘယ်ကြောင့်ဆိုသော် ဘာသာစကားများကိုဖြတ်၍ စာသားကိုဘာသာပြန်ခြင်းသည် အဓိပ္ပါယ်ကို ခိုင်ခံ့စွာထိန်းသိမ်းထားနိုင်ပြီး အံဝင်ခွင်ကျလွန်ကဲခြင်းမှကာကွယ်နိုင်ဖွယ်ရှိသည်။ ထို့ကြောင့် ယောင်ယောင်ချောက်ချားမှုများကို လက်စွဲမှတ်စာအလွှာတွင် ဘာသာပြန်နှစ်ဘာသာဖြင့် စပီကာများဖြင့် ပရောဂျက်အတွက် ဘာသာပြန်ပြီး ဖော်ထုတ်ခဲ့သည်။
အစပျိုးမှုသည် စံကဏ္ဍစမ်းသပ်မှုများစွာတွင် အကောင်းဆုံးရလဒ်များရရှိပြီး တိုကင် 10 သန်းထက်ကျော်လွန်သောဒေတာကို အသုံးပြု၍ လက်ခံနိုင်သောရလဒ်များကို ပထမဆုံးရရှိခြင်းဖြစ်သည်။
ပရောဂျက်အတွက် ကုဒ်၊ ခေါင်းစဉ် Conditional Neural Sequence Generation တွင် Hallucinated Content ကို ထောက်လှမ်းခြင်း။ဖြစ်ခဲ့တာ GitHub တွင်ထုတ်ပြန်ခဲ့သည်။နှင့် အသုံးပြုသူများကို BART ဖြင့် ၎င်းတို့၏ ကိုယ်ပိုင် ပေါင်းစပ်ဒေတာကို စာသား၏ ပေါင်းစပ်မှုမှ ထုတ်လုပ်ခွင့်ပြုသည်။ အာရုံစူးစိုက်မှု ထောက်လှမ်းခြင်း မော်ဒယ်များ၏ နောက်ဆက်တွဲ မျိုးဆက်များအတွက်လည်း စီမံဆောင်ရွက်ပေးပါသည်။















