
ປັນຍາປະດິດ
RigNeRF: ວິທີການ Deepfakes ໃໝ່ ທີ່ໃຊ້ Neural Radiance Fields

ການຄົ້ນຄວ້າໃຫມ່ທີ່ພັດທະນາຢູ່ Adobe ກໍາລັງສະເຫນີວິທີການ Deepfakes ທໍາອິດທີ່ມີປະສິດທິພາບແລະມີປະສິດທິພາບໂດຍອີງໃສ່ Neural Radiance Fields (NeRF) - ບາງທີການປະດິດສ້າງທີ່ແທ້ຈິງຄັ້ງທໍາອິດໃນຖາປັດຕະຍະຫຼືວິທີການໃນຫ້າປີນັບຕັ້ງແຕ່ການປະກົດຕົວຂອງ deepfakes ໃນປີ 2017.
ວິທີການ, ຫົວຂໍ້ RigNeRF, ການ ນຳ ໃຊ້ ແບບຈໍາລອງໃບຫນ້າ 3D morphable (3DMMs) ເປັນ layer interstitial ຂອງເຄື່ອງມືລະຫວ່າງ input ທີ່ຕ້ອງການ (ເຊັ່ນ: ຕົວຕົນທີ່ຈະ imposed ເຂົ້າໄປໃນ render NeRF) ແລະ neural space, ວິທີການທີ່ໄດ້ຮັບການ. ໄດ້ຮັບຮອງເອົາຢ່າງກວ້າງຂວາງໃນຊຸມປີມໍ່ໆມານີ້ ໂດຍ Generative Adversarial Network (GAN) ວິທີການສັງເຄາະປະເຊີນຫນ້າ, ບໍ່ມີອັນໃດທີ່ຍັງຜະລິດກອບການທົດແທນໃບຫນ້າທີ່ເປັນປະໂຫຍດແລະເປັນປະໂຫຍດສໍາລັບວິດີໂອ.

ບໍ່ເຫມືອນກັບວິດີໂອທີ່ປອມແປງແບບດັ້ງເດີມ, ແນ່ນອນວ່າບໍ່ມີເນື້ອຫາເຄື່ອນທີ່ທີ່ສະແດງຢູ່ນີ້ແມ່ນ 'ຈິງ', ແຕ່ແທນທີ່ຈະເປັນພື້ນທີ່ neural ທີ່ສາມາດສຳຫຼວດໄດ້ ເຊິ່ງໄດ້ຮັບການຝຶກອົບຮົມຈາກວິດີໂອສັ້ນໆ. ທາງດ້ານຂວາພວກເຮົາເຫັນຮູບແບບໃບຫນ້າແບບ 3D morphable (3DMM) ເຮັດຫນ້າທີ່ເປັນການໂຕ້ຕອບລະຫວ່າງການຫມູນໃຊ້ທີ່ຕ້ອງການ ('ຍິ້ມ', 'ເບິ່ງຊ້າຍ', 'ເບິ່ງຂຶ້ນ', ແລະອື່ນໆ) ແລະຕົວກໍານົດການປົກກະຕິ intractable ຂອງ Neural Radiance Field. ການເບິ່ງເຫັນ. ສໍາລັບສະບັບທີ່ມີຄວາມລະອຽດສູງຂອງຄລິບນີ້, ພ້ອມກັບຕົວຢ່າງອື່ນໆ, ເບິ່ງ ຫນ້າໂຄງການ, ຫຼືວິດີໂອຝັງຢູ່ໃນຕອນທ້າຍຂອງບົດຄວາມນີ້. ທີ່ມາ: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMMs ແມ່ນຕົວແບບ CGI ຂອງໃບຫນ້າທີ່ມີປະສິດຕິຜົນ, ຕົວກໍານົດການທີ່ສາມາດປັບຕົວເຂົ້າກັບລະບົບການສັງເຄາະຮູບພາບທີ່ບໍ່ມີຕົວຕົນຫຼາຍ, ເຊັ່ນ NeRF ແລະ GAN, ຖ້າບໍ່ດັ່ງນັ້ນຍາກທີ່ຈະຄວບຄຸມ.
ສິ່ງທີ່ທ່ານເຫັນໃນຮູບຂ້າງເທິງ (ຮູບກາງ, ຜູ້ຊາຍໃສ່ເສື້ອສີຟ້າ), ເຊັ່ນດຽວກັນກັບຮູບໂດຍກົງຂ້າງລຸ່ມນີ້ (ຮູບຊ້າຍ, ຜູ້ຊາຍໃນເສື້ອສີຟ້າ), ບໍ່ແມ່ນວິດີໂອ 'ທີ່ແທ້ຈິງ' ທີ່ເປັນ patch ຂະຫນາດນ້ອຍຂອງ ' ໃບໜ້າຂອງປອມໄດ້ຖືກນຳມາທັບຊ້ອນ, ແຕ່ເປັນສາກທີ່ສັງເຄາະທັງໝົດທີ່ມີພຽງການສະແດງອອກທາງປະສາດທາງປະສາດຂະໜາດເທົ່າ – ລວມທັງຮ່າງກາຍ ແລະ ພື້ນຫຼັງ:

ໃນຕົວຢ່າງໂດຍກົງຂ້າງເທິງ, ວິດີໂອຊີວິດຈິງເບື້ອງຂວາ (ແມ່ຍິງໃນຊຸດສີແດງ) ຖືກນໍາໃຊ້ເພື່ອ 'puppet' ຕົວຕົນທີ່ຖືກຈັບ (ຜູ້ຊາຍໃນເສື້ອສີຟ້າ) ຢູ່ເບື້ອງຊ້າຍໂດຍຜ່ານ RigNeRF, ເຊິ່ງ (ຜູ້ຂຽນອ້າງ) ແມ່ນຄັ້ງທໍາອິດ. ລະບົບທີ່ອີງໃສ່ NeRF ເພື່ອບັນລຸການແຍກລັກສະນະແລະການສະແດງອອກໃນຂະນະທີ່ສາມາດປະຕິບັດການສັງເຄາະມຸມເບິ່ງໃຫມ່.
ຮູບຜູ້ຊາຍຢູ່ເບື້ອງຊ້າຍໃນຮູບຂ້າງເທິງນີ້ແມ່ນ 'ຈັບໄດ້' ຈາກວິດີໂອໂທລະສັບສະຫຼາດ 70 ວິນາທີ, ແລະຂໍ້ມູນການປ້ອນຂໍ້ມູນ (ລວມທັງຂໍ້ມູນ scene ທັງຫມົດ) ຕໍ່ມາການຝຶກອົບຮົມໃນທົ່ວ 4 V100 GPUs ເພື່ອໃຫ້ໄດ້ຮັບ scene ໄດ້.
ເນື່ອງຈາກວ່າ rigs parametric ແບບ 3DMM ຍັງມີຢູ່ໃນ ຕົວແທນ CGI parametric ທັງຮ່າງກາຍ (ແທນທີ່ຈະພຽງແຕ່ປະເຊີນຫນ້າ), RigNeRF ອາດຈະເປີດຄວາມເປັນໄປໄດ້ຂອງ deep-body ເຕັມທີ່ບ່ອນທີ່ການເຄື່ອນໄຫວ, ໂຄງສ້າງແລະການສະແດງອອກຂອງມະນຸດທີ່ແທ້ຈິງຖືກສົ່ງໄປຫາຊັ້ນ parametric ທີ່ອີງໃສ່ CGI, ເຊິ່ງຫຼັງຈາກນັ້ນຈະແປການປະຕິບັດແລະການສະແດງອອກເຂົ້າໄປໃນສະພາບແວດລ້ອມແລະວິດີໂອ NeRF. .
ສໍາລັບ RigNeRF - ມັນມີຄຸນສົມບັດເປັນວິທີການປອມແປງໃນຄວາມຮູ້ສຶກໃນປະຈຸບັນທີ່ຫົວຂໍ້ຂ່າວເຂົ້າໃຈຄໍາສັບບໍ? ຫຼືວ່າມັນເປັນພຽງເຄິ່ງ hobbled ອື່ນທີ່ແລ່ນໄປຫາ DeepFaceLab ແລະລະບົບອື່ນໆທີ່ໃຊ້ແຮງງານຫຼາຍ, ຍຸກ 2017 autoencoder deepfake?
ນັກຄົ້ນຄ້ວາຂອງເອກະສານໃຫມ່ແມ່ນບໍ່ແນ່ນອນກ່ຽວກັບຈຸດນີ້:
'ເປັນວິທີການທີ່ສາມາດ reanimating ໃບຫນ້າ, RigNeRF ມັກຈະໃຊ້ໃນທາງທີ່ຜິດໂດຍນັກສະແດງທີ່ບໍ່ດີເພື່ອສ້າງການປອມແປງເລິກ.'
ໃຫມ່ ເຈ້ຍ ແມ່ນຫົວຂໍ້ RigNeRF: ຮູບ 3D Neural ທີ່ຄວບຄຸມໄດ້ຢ່າງເຕັມສ່ວນ, ແລະມາຈາກ ShahRukh Atha ຂອງມະຫາວິທະຍາໄລ Stonybrook, ນັກຝຶກງານຢູ່ Adobe ໃນລະຫວ່າງການພັດທະນາຂອງ RigNeRF, ແລະນັກຂຽນອີກສີ່ຄົນຈາກ Adobe Research.
ນອກເຫນືອຈາກ Autoencoder-Based Deepfakes
ສ່ວນໃຫຍ່ຂອງການປອມແປງໄວຣັສທີ່ຈັບໄດ້ໃນສອງສາມປີຜ່ານມາແມ່ນຜະລິດໂດຍ ການເຂົ້າລະຫັດອັດຕະໂນມັດລະບົບ -based, ໄດ້ມາຈາກລະຫັດທີ່ຖືກຈັດພີມມາຢູ່ໃນ r / deepfakes subreddit ທີ່ຖືກຫ້າມທັນທີໃນປີ 2017 - ເຖິງແມ່ນວ່າບໍ່ແມ່ນກ່ອນທີ່ຈະເປັນ. ສຳເນົາແລ້ວ ກັບ GitHub, ບ່ອນທີ່ມັນໄດ້ຖືກ forked ໃນປັດຈຸບັນ ຫຼາຍກວ່າພັນເທື່ອ, ຢ່າງຫນ້ອຍເຂົ້າໄປໃນທີ່ນິຍົມ (ຖ້າ controversial) DeepFaceLab ການແຜ່ກະຈາຍ, ແລະຍັງ ແລກປ່ຽນໃບ ໜ້າ ໂຄງການ.
ນອກຈາກ GAN ແລະ NeRF, ກອບການເຂົ້າລະຫັດອັດຕະໂນມັດຍັງໄດ້ທົດລອງກັບ 3DMMs ເປັນ 'ຄໍາແນະນໍາ' ສໍາລັບການປັບປຸງກອບການສັງເຄາະໃບຫນ້າ. ຕົວຢ່າງຂອງເລື່ອງນີ້ແມ່ນ ໂຄງການ HifiFace ຕັ້ງແຕ່ເດືອນກໍລະກົດຂອງປີ 2021. ແນວໃດກໍ່ຕາມ, ບໍ່ມີຂໍ້ລິເລີ່ມທີ່ສາມາດໃຊ້ໄດ້ ຫຼືເປັນທີ່ນິຍົມໄດ້ພັດທະນາຈາກວິທີການນີ້ຈົນເຖິງປັດຈຸບັນ.
ຂໍ້ມູນສໍາລັບ scenes RigNeRF ແມ່ນໄດ້ຮັບໂດຍການຈັບວິດີໂອໂທລະສັບສະຫຼາດສັ້ນ. ສໍາລັບໂຄງການ, ນັກຄົ້ນຄວ້າຂອງ RigNeRF ໄດ້ໃຊ້ iPhone XR ຫຼື iPhone 12 ສໍາລັບການທົດລອງທັງຫມົດ. ສໍາລັບເຄິ່ງທໍາອິດຂອງການຈັບພາບ, ຫົວຂໍ້ໄດ້ຖືກຂໍໃຫ້ປະຕິບັດການສະແດງອອກທາງຫນ້າແລະການປາກເວົ້າຢ່າງກວ້າງຂວາງໃນຂະນະທີ່ຮັກສາຫົວຂອງພວກເຂົາໄວ້ໃນຂະນະທີ່ກ້ອງຖ່າຍຮູບຖືກເຄື່ອນໄປອ້ອມຮອບພວກເຂົາ.
ສໍາລັບເຄິ່ງທີ່ສອງຂອງການຈັບພາບ, ກ້ອງຖ່າຍຮູບຮັກສາຕໍາແຫນ່ງຄົງທີ່ໃນຂະນະທີ່ຫົວຂໍ້ຕ້ອງຍ້າຍຫົວຂອງພວກເຂົາໄປໃນຂະນະທີ່ຫລີກລ້ຽງການສະແດງອອກຢ່າງກວ້າງຂວາງ. ຜົນໄດ້ຮັບ 40-70 ວິນາທີຂອງ footage (ປະມານ 1200-2100 ເຟຣມ) ເປັນຕົວແທນຂອງຊຸດຂໍ້ມູນທັງຫມົດທີ່ຈະໃຊ້ໃນການຝຶກອົບຮົມຕົວແບບ.
ການຫຼຸດຜ່ອນການເກັບກໍາຂໍ້ມູນ
ໃນທາງກົງກັນຂ້າມ, ລະບົບ autoencoder ເຊັ່ນ DeepFaceLab ຮຽກຮ້ອງໃຫ້ມີການລວບລວມແລະການຮັກສາທີ່ຂ້ອນຂ້າງຫຼາຍຂອງຮູບທີ່ຫຼາກຫຼາຍຊະນິດ, ມັກຈະເອົາມາຈາກວິດີໂອ YouTube ແລະຊ່ອງທາງສື່ສັງຄົມອື່ນໆ, ເຊັ່ນດຽວກັນກັບຮູບເງົາ (ໃນກໍລະນີຂອງການປອມແປງທີ່ມີຊື່ສຽງ).
ແບບຈໍາລອງການເຂົ້າລະຫັດອັດຕະໂນມັດທີ່ໄດ້ຮັບການຝຶກອົບຮົມທີ່ໄດ້ຮັບຜົນມັກຈະມີຈຸດປະສົງເພື່ອໃຊ້ໃນຫຼາຍໆສະຖານະການ. ແນວໃດກໍ່ຕາມ, ນັກເລິກ 'ຄົນດັງ' ທີ່ໄວທີ່ສຸດອາດຈະຝຶກອົບຮົມແບບຈໍາລອງທັງຫມົດຈາກຈຸດເລີ່ມຕົ້ນສໍາລັບວິດີໂອດຽວ, ເຖິງແມ່ນວ່າການຝຶກອົບຮົມສາມາດໃຊ້ເວລາຫນຶ່ງອາທິດຫຼືຫຼາຍກວ່ານັ້ນ.
ເຖິງວ່າຈະມີບັນທຶກການເຕືອນໄພຈາກນັກຄົ້ນຄວ້າຂອງເອກະສານໃຫມ່, 'patchwork' ແລະຊຸດຂໍ້ມູນທີ່ປະກອບຢ່າງກວ້າງຂວາງທີ່ມີອໍານາດ AI porn ເຊັ່ນດຽວກັນກັບ YouTube / TikTok ທີ່ນິຍົມ 'deepfake recastings' ເບິ່ງຄືວ່າຈະບໍ່ສ້າງຜົນໄດ້ຮັບທີ່ຍອມຮັບແລະສອດຄ່ອງໃນລະບົບ deepfake ເຊັ່ນ RigNeRF, ທີ່ມີວິທີການສະເພາະ scene. ເນື່ອງຈາກຂໍ້ຈໍາກັດກ່ຽວກັບການເກັບຂໍ້ມູນທີ່ລະບຸໄວ້ໃນວຽກໃຫມ່, ນີ້ສາມາດພິສູດໄດ້, ໃນບາງຂອບເຂດ, ການປົກປ້ອງເພີ່ມເຕີມຕໍ່ກັບການລັກລອບຕົວຕົນໂດຍຜູ້ປອມແປງທີ່ເປັນອັນຕະລາຍ.
ການປັບຕົວ NeRF ກັບວິດີໂອ Deepfake
NeRF ແມ່ນວິທີການທີ່ອີງໃສ່ photogrammetry ເຊິ່ງຈໍານວນເລັກນ້ອຍຂອງຮູບພາບທີ່ມາຈາກມຸມເບິ່ງຕ່າງໆໄດ້ຖືກປະກອບເຂົ້າໄປໃນພື້ນທີ່ neural 3D ທີ່ສາມາດຄົ້ນຫາໄດ້. ວິທີການນີ້ໄດ້ມີຊື່ສຽງໃນຕົ້ນປີນີ້ເມື່ອ NVIDIA ເປີດຕົວ ທັນທີ NeRF ລະບົບ, ສາມາດຕັດເວລາການຝຶກອົບຮົມຫຼາຍເກີນໄປສໍາລັບ NeRF ລົງເປັນນາທີ, ຫຼືແມ້ກະທັ້ງວິນາທີ:

ທັນທີ NeRF. ທີ່ມາ: https://www.youtube.com/watch?v=DJ2hcC1orc4
ເຫດການ Neural Radiance Field ທີ່ເປັນຜົນມາຈາກສະພາບແວດລ້ອມຄົງທີ່ທີ່ສາມາດຄົ້ນຫາໄດ້, ແຕ່ວ່າອັນໃດຄື. ຍາກທີ່ຈະແກ້ໄຂ. ນັກຄົ້ນຄວ້າສັງເກດເຫັນວ່າສອງຂໍ້ລິເລີ່ມທີ່ອີງໃສ່ NeRF ກ່ອນຫນ້ານີ້ - HyperNeRF + E/P ແລະ NerFACE – ໄດ້ຮັບການແທງໃນການສັງເຄາະວິດີໂອໃບຫນ້າ, ແລະ (ປາກົດຂື້ນສໍາລັບຄວາມສົມບູນແລະຄວາມພາກພຽນ) ໄດ້ກໍານົດ RigNeRF ຕ້ານສອງໂຄງການນີ້ໃນຮອບການທົດສອບ:


ການປຽບທຽບດ້ານຄຸນນະພາບລະຫວ່າງ RigNeRF, HyperNeRF, ແລະ NerFACE. ເບິ່ງວິດີໂອແຫຼ່ງເຊື່ອມຕໍ່ ແລະ PDF ສໍາລັບສະບັບທີ່ມີຄຸນນະພາບສູງກວ່າ. ແຫຼ່ງຮູບພາບຄົງທີ່: https://arxiv.org/pdf/2012.03065.pdf
ຢ່າງໃດກໍຕາມ, ໃນກໍລະນີນີ້, ຜົນໄດ້ຮັບ, ເຊິ່ງເຮັດໃຫ້ RigNeRF ມີຄວາມຜິດປົກກະຕິຫຼາຍ, ສໍາລັບສອງເຫດຜົນ: ທໍາອິດ, ຜູ້ຂຽນສັງເກດເຫັນວ່າ 'ບໍ່ມີການເຮັດວຽກທີ່ມີຢູ່ແລ້ວສໍາລັບການປຽບທຽບຫມາກໂປມກັບຫມາກໂປມ'; ອັນທີສອງ, ນີ້ໄດ້ມີຄວາມຈໍາເປັນຈໍາກັດຄວາມສາມາດຂອງ RigNeRF ຢ່າງຫນ້ອຍບາງສ່ວນທີ່ກົງກັບຫນ້າທີ່ຈໍາກັດຫຼາຍຂອງລະບົບກ່ອນ.
ເນື່ອງຈາກຜົນໄດ້ຮັບບໍ່ແມ່ນການປັບປຸງທີ່ເພີ່ມຂຶ້ນໃນການເຮັດວຽກກ່ອນ, ແຕ່ແທນທີ່ຈະເປັນ 'ຄວາມກ້າວຫນ້າ' ໃນການແກ້ໄຂແລະຜົນປະໂຫຍດ NeRF, ພວກເຮົາຈະອອກຈາກຮອບທົດສອບ, ແລະແທນທີ່ຈະເບິ່ງສິ່ງທີ່ RigNeRF ກໍາລັງເຮັດແຕກຕ່າງຈາກລຸ້ນກ່ອນ.
ຄວາມເຂັ້ມແຂງລວມ
ຂໍ້ຈໍາກັດຕົ້ນຕໍຂອງ NerFACE, ເຊິ່ງສາມາດສ້າງການຄວບຄຸມການສະແດງ / ການສະແດງອອກໃນສະພາບແວດລ້ອມ NeRF, ແມ່ນວ່າມັນສົມມຸດວ່າ footage ແຫຼ່ງຈະຖືກຈັບດ້ວຍກ້ອງຖ່າຍຮູບຄົງທີ່. ນີ້ຫມາຍຄວາມວ່າມັນບໍ່ສາມາດສ້າງທັດສະນະໃຫມ່ທີ່ຂະຫຍາຍເກີນຂອບເຂດຈໍາກັດການຈັບພາບຂອງມັນ. ອັນນີ້ສ້າງລະບົບທີ່ສາມາດສ້າງ 'ຮູບຄົນເຄື່ອນທີ່', ແຕ່ມັນບໍ່ເໝາະສົມກັບວິດີໂອແບບເລິກລັບ.
ໃນທາງກົງກັນຂ້າມ, HyperNeRF, ໃນຂະນະທີ່ສາມາດສ້າງວິວໃຫມ່ແລະ hyper-real views, ບໍ່ມີເຄື່ອງມືທີ່ອະນຸຍາດໃຫ້ມັນປ່ຽນທ່າທາງຫົວຫຼືການສະແດງອອກທາງຫນ້າ, ເຊິ່ງອີກເທື່ອຫນຶ່ງບໍ່ໄດ້ສົ່ງຜົນໃຫ້ຄູ່ແຂ່ງໃດໆສໍາລັບ deepfakes autoencoder.
RigNeRF ສາມາດສົມທົບສອງຫນ້າທີ່ໂດດດ່ຽວເຫຼົ່ານີ້ໂດຍການສ້າງ 'ຊ່ອງ canonical', ພື້ນຖານມາດຕະຖານທີ່ deviations ແລະ deformations ສາມາດໄດ້ຮັບການ enacted ໂດຍຜ່ານການປ້ອນຂໍ້ມູນຈາກໂມດູນ 3DMM.
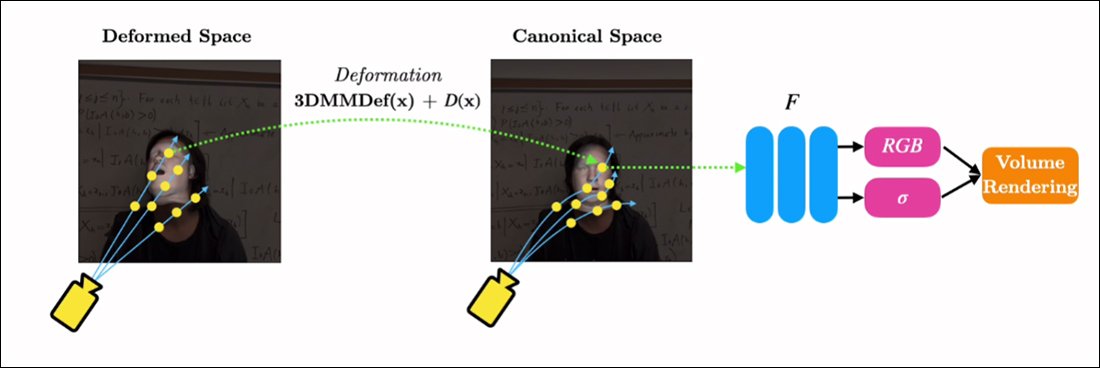
ການສ້າງ 'ຊ່ອງ canonical' (ບໍ່ມີ pose, ບໍ່ມີການສະແດງອອກ), ທີ່ deformations (ie poses ແລະການສະແດງອອກ) ທີ່ຜະລິດໂດຍຜ່ານ 3DMM ສາມາດປະຕິບັດ.
ເນື່ອງຈາກລະບົບ 3DMM ຈະບໍ່ກົງກັນກັບຫົວຂໍ້ທີ່ຈັບໄດ້, ມັນເປັນສິ່ງສໍາຄັນທີ່ຈະຊົດເຊີຍສໍາລັບການນີ້ໃນຂະບວນການ. RigNeRF ສໍາເລັດນີ້ກັບພາກສະຫນາມ deformation ກ່ອນທີ່ຈະຄິດໄລ່ຈາກ a Multiplayer Perceptron (MLP) ໄດ້ມາຈາກ footage ແຫຼ່ງ.

ຕົວກໍານົດການກ້ອງຖ່າຍຮູບທີ່ຈໍາເປັນເພື່ອຄິດໄລ່ການຜິດປົກກະຕິແມ່ນໄດ້ຮັບໂດຍຜ່ານ COLMAP, ໃນຂະນະທີ່ຕົວກໍານົດການສະແດງອອກແລະຮູບຮ່າງສໍາລັບແຕ່ລະກອບແມ່ນໄດ້ມາຈາກ DECA.
ການຈັດຕໍາແຫນ່ງແມ່ນ optimized ຕື່ມອີກໂດຍຜ່ານ ການປັບຈຸດຫມາຍ ແລະຕົວກໍານົດການກ້ອງຖ່າຍຮູບຂອງ COLMAP, ແລະ, ເນື່ອງຈາກຂໍ້ຈໍາກັດຂອງຊັບພະຍາກອນຂອງຄອມພິວເຕີ້, ຜົນຜະລິດວິດີໂອໄດ້ຖືກຫຼຸດລົງເປັນຄວາມລະອຽດ 256 × 256 ສໍາລັບການຝຶກອົບຮົມ (ຂະບວນການຫົດຕົວທີ່ມີຂໍ້ຈໍາກັດຂອງຮາດແວທີ່ຍັງ plagues scene deepfaking autoencoder).
ຫຼັງຈາກນັ້ນ, ເຄືອຂ່າຍ deformation ໄດ້ຖືກຝຶກອົບຮົມຢູ່ໃນສີ່ V100s - ຮາດແວທີ່ເປັນຕາຢ້ານທີ່ບໍ່ມີແນວໂນ້ມທີ່ຈະຢູ່ໃນຂອບເຂດຂອງຜູ້ທີ່ມັກຄວາມກະຕືລືລົ້ນ (ຢ່າງໃດກໍ່ຕາມ, ບ່ອນທີ່ການຝຶກອົບຮົມການຮຽນຮູ້ເຄື່ອງຈັກມີຄວາມກັງວົນ, ມັນມັກຈະເປັນໄປໄດ້ໃນການຊື້ຂາຍຫຼາຍສໍາລັບເວລາ, ແລະພຽງແຕ່ຍອມຮັບຕົວແບບນັ້ນ. ການຝຶກອົບຮົມຈະເປັນມື້ຫຼືແມ້ກະທັ້ງອາທິດ).
ສະຫຼຸບ, ນັກຄົ້ນຄວ້າກ່າວວ່າ:
'ໃນທາງກົງກັນຂ້າມກັບວິທີການອື່ນໆ, RigNeRF, ຍ້ອນການໃຊ້ໂມດູນການປ່ຽນຮູບຊົງແບບ 3DMM, ສາມາດສ້າງແບບຈໍາລອງຫົວ, ການສະແດງອອກທາງຫນ້າແລະ scene portrait 3D ເຕັມທີ່ດ້ວຍຄວາມຊື່ສັດສູງ, ດັ່ງນັ້ນຈຶ່ງເຮັດໃຫ້ການກໍ່ສ້າງທີ່ດີຂຶ້ນດ້ວຍລາຍລະອຽດແຫຼມ.'
ເບິ່ງວິດີໂອທີ່ຝັງໄວ້ຂ້າງລຸ່ມນີ້ສໍາລັບລາຍລະອຽດເພີ່ມເຕີມແລະວິດີໂອຜົນໄດ້ຮັບ.


ພິມຄັ້ງທຳອິດໃນວັນທີ 15 ມິຖຸນາ 2022.















