
Kënschtlech Intelligenz
Zero123++: Een eenzegt Bild zu konsequent Multi-View Diffusion Base Model

Déi lescht Joren hunn e séiere Fortschrëtt an der Leeschtung, Effizienz, a generativen Fäegkeete vum opkomende Roman Zeien. AI generativ Modeller déi extensiv Datesätz leeschten, an 2D Diffusiounsgeneratiounspraktiken. Haut sinn generativ AI Modeller extrem fäeg verschidde Forme vun 2D ze generéieren, an zu engem gewësse Mooss 3D Medieninhalt inklusiv Text, Biller, Videoen, GIFs, a méi.
An dësem Artikel schwätze mir iwwer den Zero123++ Kader, e bildbedingte Diffusiounsgenerativen AI Modell mam Zil fir 3D-konsistent Multiple-View Biller mat engem eenzege View Input ze generéieren. Fir de Virdeel ze maximéieren, dee vu virdru pretrained generativen Modeller gewonnen gouf, implementéiert den Zero123++ Kader vill Trainings- a Konditiounsschemaen fir d'Quantitéit un Effort ze minimiséieren, déi et brauch fir aus off-the-shelf Diffusiounsbildmodeller ze finanzéieren. Mir wäerten e méi déif Tauchen an d'Architektur, d'Aarbecht an d'Resultater vum Zero123++ Kader huelen, an analyséieren seng Fäegkeeten fir konsequent Multiple-View Biller vu héich Qualitéit aus engem eenzegen Bild ze generéieren. Also loosst eis ufänken.
Zero123 an Zero123++: Eng Aféierung
Den Zero123++ Kader ass e Bildbedingte Diffusiounsgenerativen AI Modell deen zielt fir 3D-konsistent Multiple-View Biller mat engem eenzegen Viewingang ze generéieren. Den Zero123++ Kader ass eng Fortsetzung vum Zero123 oder Zero-1-to-3 Kader, deen Null-Shot Roman View Bildsynthese Technik benotzt fir Pionéier Open-Source Single-Bild -zu-3D Konversiounen. Och wann den Zero123++ Kader villverspriechend Leeschtung liwwert, hunn d'Biller generéiert vum Kader siichtbar geometresch Inkonsistenz, an et ass den Haaptgrond firwat de Spalt tëscht 3D Szenen, a Multi-View Biller nach ëmmer existéiert.
Den Zero-1-zu-3 Kader déngt als Grondlag fir e puer aner Kaderen, dorënner SyncDreamer, One-2-3-45, Consistent123, a méi, déi extra Schichten zum Zero123 Kader bäidroen fir méi konsequent Resultater ze kréien wann Dir 3D Biller generéiert. Aner Kaderen wéi ProlificDreamer, DreamFusion, DreamGaussian, a méi verfollegen eng Optimiséierungsbaséiert Approche fir 3D Biller ze kréien andeems en 3D Bild vu verschiddene inkonsistente Modeller distilléiert gëtt. Och wann dës Techniken effektiv sinn, a si generéieren zefriddestellend 3D Biller, kënnen d'Resultater mat der Ëmsetzung vun engem Basisdiffusiounsmodell verbessert ginn, dee fäeg ass Multi-View Biller konsequent ze generéieren. Deementspriechend hëlt den Zero123 ++ Kader den Zero-1 op-3, a finjustéiert en neie Multi-View Basisdiffusiounsmodell vu Stable Diffusion.
Am Null-1-zu-3 Kader gëtt all Roman Vue onofhängeg generéiert, an dës Approche féiert zu Inkonsistenz tëscht de Meenungen generéiert wéi Diffusiounsmodeller eng Probenatur hunn. Fir dëst Thema unzegoen, adoptéiert den Zero123++ Kader eng Fliesen Layout Approche, mam Objet gëtt vu sechs Meenungen an en eenzegt Bild ëmginn, a garantéiert déi richteg Modelléierung fir d'gemeinsame Verdeelung vun de Multi-View Biller vun engem Objet.
Eng aner grouss Erausfuerderung vun den Entwéckler, déi um Zero-1-to-3 Kader schaffen, ass datt et d'Fähigkeiten ënnernotzt Stabil Diffusioun dat féiert schlussendlech zu Ineffizienz, an zousätzlech Käschten. Et ginn zwee Haaptgrënn firwat den Zero-1-zu-3-Framework d'Kapazitéite vun der Stable Diffusion net maximéieren kann
- Wann Dir mat Bildbedéngungen trainéiert, integréiert den Zero-1-to-3 Kader net lokal oder global Konditiounsmechanismen, déi vun der Stable Diffusion effektiv ugebuede ginn.
- Wärend der Ausbildung benotzt den Zero-1-zu-3 Kader reduzéiert Resolutioun, eng Approche an där d'Ausgangsresolutioun ënner der Trainingsresolutioun reduzéiert gëtt, déi d'Qualitéit vun der Bildgeneratioun fir Stable Diffusion Modeller reduzéiere kann.
Fir dës Themen unzegoen, implementéiert den Zero123++ Kader eng ganz Rëtsch vun Konditiounstechniken, déi d'Notzung vu Ressourcen maximéiert, déi vun der Stable Diffusion ugebuede ginn, an d'Qualitéit vun der Bildgeneratioun fir Stable Diffusion Modeller behalen.
Verbesserung vun Konditioun a Konsistenz
An engem Versuch d'Bildkonditioun ze verbesseren, a Multi-View Bildkonsistenz, huet den Zero123++ Kader verschidden Techniken implementéiert, mam primäre Zil ass d'Wiederbenotzen vun virdrun Techniken aus dem pretrained Stable Diffusion Modell.
Multi-View Generatioun
Déi onverzichtbar Qualitéit fir konsequent Multi-View Biller ze generéieren läit an der gemeinsamer Verdeelung vu verschidde Biller korrekt ze modelléieren. Am Zero-1-zu-3 Kader gëtt d'Korrelatioun tëscht Multi-View Biller ignoréiert well fir all Bild de Kader déi bedingt Marginalverdeelung onofhängeg a separat modelléiert. Wéi och ëmmer, am Zero123++ Kader hunn d'Entwéckler fir eng Fliesen Layout Approche entscheet, déi 6 Biller an engem eenzege Frame / Bild fir eng konsequent Multi-View Generatioun placéiert, an de Prozess gëtt am folgende Bild demonstréiert.
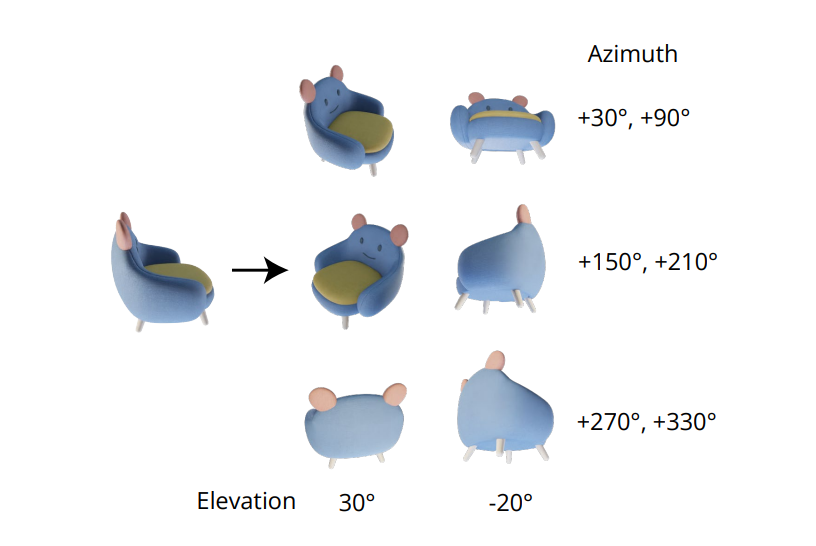
Ausserdeem gouf bemierkt datt d'Objetorientéierungen tendéieren ze disambiguéieren wann Dir de Modell op Kameraposen trainéiert, a fir dës Disambiguatioun ze vermeiden, trainéiert d'Zero-1-zu-3 Framework op Kamera poséiert mat Héichtwinkelen a relativen Azimut zum Input. Fir dës Approche ëmzesetzen, ass et néideg den Héichtwénkel vun der Vue vum Input ze kennen, deen dann benotzt gëtt fir d'relativ Pose tëscht neien Input Meenungen ze bestëmmen. An engem Versuch dësen Héichtwénkel ze kennen, addéiere Frameworks dacks en Héichtschätzungsmodul, an dës Approche kënnt dacks op d'Käschte vun zousätzleche Feeler an der Pipeline.
Kaméidi Zäitplang
Skaléiert-linear Zäitplang, den urspréngleche Geräischerplang fir Stabil Diffusioun konzentréiert sech haaptsächlech op lokal Detailer, awer wéi et an der folgender Bild gesi ka ginn, huet et ganz wéineg Schrëtt mat méi nidderegen SNR oder Signal zu Kaméidi Verhältnis.

Dës Schrëtt vum nidderegen Signal zu Kaméidi Verhältnis geschéien fréi während der denoising Etapp, eng Etapp entscheedend fir Bestëmmung vun der globaler niddereg-Frequenz Struktur. D'Reduktioun vun der Unzuel vun de Schrëtt während der Denoising Etapp, entweder während der Amëschung oder beim Training resultéiert dacks zu enger méi grousser strukturell Variatioun. Och wann dëse Setup ideal ass fir Single-Bild Generatioun limitéiert et d'Fäegkeet vum Kader fir eng global Konsistenz tëscht verschiddene Meenungen ze garantéieren. Fir dës Hürd ze iwwerwannen, finjustéiert den Zero123++ Kader e LoRA Modell am Stable Diffusion 2 V-Prediction Kader fir eng Spillsaach Aufgab auszeféieren, an d'Resultater ginn hei ënnen gewisen.

Mat dem scaléiert-lineare Geräischer Zäitplang iwwerdréit de LoRA Modell net, awer nëmmen d'Bild liicht wäiss. Ëmgekéiert, wann Dir mam lineare Geräischer Zäitplang schafft, generéiert de LoRA Framework en eidel Bild erfollegräich onofhängeg vun der Input Prompt, sou datt den Impakt vum Geräischerplang op d'Fäegkeet vum Kader fir nei Ufuerderunge weltwäit unzepassen.
Skaléiert Referenz Opmierksamkeet fir lokal Konditiounen
Déi eenzeg Vue-Input oder d'Konditiounsbiller am Zero-1-zu-3-Framework ass zesumme mat de lauter Inputen an der Feature-Dimensioun fir d'Bildkonditioun ze geraumen.
Dës Konkatenatioun féiert zu enger falscher pixelweiser raimlecher Korrespondenz tëscht dem Zilbild an dem Input. Fir e richtege lokalen Konditiounsinput ze liwweren, benotzt den Zero123++ Kader vun enger skaléierter Referenz Opmierksamkeet, eng Approche an där en denoising UNet Modell leeft op en extra Referenzbild bezeechent gëtt, gefollegt vun der Unhang vu Wäertmatrixen a SelbstOpmierksamkeetschlëssel vun der Referenz. Bild op déi jeeweileg Opmierksamkeet Schichten wann de Modell Input denoised ass, an et ass an der folgender Figur bewisen.

D'Referenz Opmierksamkeet Approche ass fäeg den Diffusiounsmodell ze guidéieren fir Biller ze generéieren déi ähnlech Textur mam Referenzbild deelen, a semanteschen Inhalt ouni Feintuning. Mat Feintuning liwwert d'Referenz Opgepasst Approche super Resultater mat der latenter Skala.

Global Conditioning: FlexDiffuse
An der ursprénglecher Stable Diffusion Approche sinn d'Text Embeddings déi eenzeg Quell fir global Embeddings, an d'Approche beschäftegt de CLIP Kader als Text Encoder fir Kräizuntersuchungen tëscht den Text Embeddings auszeféieren, an de Modelllatenten. Als Resultat sinn d'Entwéckler fräi d'Ausrichtung tëscht den Textraim ze benotzen, an déi resultéierend CLIP Biller fir se fir global Bildbedéngungen ze benotzen.
Den Zero123++ Kader proposéiert eng trainéierbar Variant vum linear Leedungsmechanismus ze benotzen fir déi global Bildbedéngung an de Kader mat minimalem Integréieren fein ofstëmmen néideg, an d'Resultater ginn am folgende Bild gewisen. Wéi et ka gesi ginn, ouni d'Präsenz vun enger globaler Bildkonditioun, ass d'Qualitéit vum Inhalt, deen vum Kader generéiert gëtt, zefriddestellend fir sichtbar Regiounen, déi dem Inputbild entspriechen. Wéi och ëmmer, d'Qualitéit vum Bild generéiert vum Kader fir onsichtbar Regiounen Zeien eng bedeitend Verschlechterung, déi haaptsächlech wéinst der Onméiglechkeet vum Modell ass fir d'global Semantik vum Objet ofzeschléissen.

Modell Architektur
Den Zero123++ Kader gëtt trainéiert mam Stable Diffusion 2v-Modell als Fondatioun mat de verschiddenen Approchen an Techniken, déi am Artikel ernimmt ginn. Den Zero123++ Kader ass viraus trainéiert op der Objaverse Dataset déi mat zoufälleger HDRI Beliichtung ofgeleet gëtt. De Kader adoptéiert och d'phaséiert Trainingsplang Approche, déi am Stabile Diffusion Image Variations Framework benotzt gëtt an engem Versuch, d'Quantitéit vun der erfuerderter Feintuning weider ze minimiséieren, a sou vill wéi méiglech an der fréierer Stable Diffusion ze erhaalen.
D'Aarbecht oder d'Architektur vum Zero123++ Kader kann weider a sequentiell Schrëtt oder Phasen opgedeelt ginn. Déi éischt Phas erzielt de Kader feinstemmt d'KV Matrizen vu Kräiz-Opmierksamkeet Schichten, an d'SelbstOpmierksamkeetsschichten vun der stabiler Diffusioun mat AdamW als säin Optimizer, 1000 Erwiermungsschrëtt an de Cosinus Léierrate Zäitplang maximal 7 × 10-5. An der zweeter Phase beschäftegt de Kader en héich konservativen konstante Léierrate mat 2000 Warm-Up-Sets, a beschäftegt d'Min-SNR Approche fir d'Effizienz während der Ausbildung ze maximéieren.
Zero123++: Resultater a Leeschtung Verglach
Qualitativ Leeschtung
Fir d'Performance vum Zero123++ Kader op Basis vu senger generéierter Qualitéit ze bewäerten, gëtt et verglach mat SyncDreamer, an Zero-1-zu-3-XL, zwee vun de schéinste modernste Kadere fir Inhaltsgeneratioun. D'Kadere gi géint véier Input Biller mat ënnerschiddlechen Ëmfang verglach. Dat éischt Bild ass eng elektresch Spillsaach Kaz, direkt aus dem Objaverse Dataset geholl, an et bitt mat enger grousser Onsécherheet um hënneschten Enn vum Objet. Zweetens ass d'Bild vun engem Feierläscher, an dat drëtt ass d'Bild vun engem Hond deen op enger Rakéit sëtzt, generéiert vum SDXL Modell. Dat lescht Bild ass eng anime Illustratioun. Déi erfuerderlech Héichtschrëtt fir d'Kadere ginn erreecht andeems d'Héichtestimatiounsmethod vum One-2-3-4-5 Kader benotzt gëtt, an d'Hannergrondentfernung gëtt mam SAM Kader erreecht. Wéi et ka gesi ginn, generéiert den Zero123++ Kader héichqualitativ Multi-View Biller konsequent, an ass fäeg ze generaliséieren op Out-of-Domain 2D Illustratioun, an AI-generéiert Biller gläich gutt.


Quantitative Analyse
Fir den Zero123++ Kader quantitativ géint de modernsten Zero-1-to-3 an Zero-1to-3 XL Kaderen ze vergläichen, evaluéieren d'Entwéckler de Learned Perceptual Image Patch Similarity (LPIPS) Score vun dëse Modeller op de Validatiounssplitdaten, e Subset. vun der Objaverse Dataset. Fir d'Performance vum Modell op der Multi-View Bildgeneratioun ze evaluéieren, zéien d'Entwéckler d'Buedem Wourecht Referenz Biller, respektiv 6 generéiert Biller, a berechnen dann de Learned Perceptual Image Patch Similarity (LPIPS) Score. D'Resultater ginn hei ënnen demonstréiert a wéi et kloer ka gesi ginn, erreecht den Zero123 ++ Kader déi bescht Leeschtung op der Validatioun Split Set.

Text zu Multi-View Evaluatioun
Fir d'Fäegkeet vum Zero123++ Kader an Text zu Multi-View Inhalt Generatioun ze evaluéieren, benotzen d'Entwéckler fir d'éischt den SDXL Kader mat Textprompts fir e Bild ze generéieren, a benotzen dann den Zero123++ Kader fir dat generéiert Bild. D'Resultater ginn am folgende Bild bewisen, a wéi et ka gesi ginn, am Verglach zum Zero-1-zu-3 Kader, deen net konsequent Multi-View Generatioun garantéieren kann, gëtt den Zero123++ Kader konsequent, realistesch an héich detailléiert Multi- Vue Biller vun Ëmsetzung vun der Text-zu-Bild-zu-Multi-View Approche oder Pipeline.

Zero123++ Déift KontrollNet
Zousätzlech zum Basis Zero123++ Kader, hunn d'Entwéckler och d'Depth ControlNet Zero123++ verëffentlecht, eng Déift-kontrolléiert Versioun vum urspréngleche Kader gebaut mat der ControlNet Architektur. Déi normaliséiert linear Biller ginn am Respekt mat de spéider RGB Biller gemaach, an e ControlNet Kader gëtt trainéiert fir d'Geometrie vum Zero123++ Kader ze kontrolléieren mat Hëllef vun Déift Perceptioun.

Konklusioun
An dësem Artikel hu mir iwwer Zero123++ geschwat, e bildbedingte Diffusiounsgenerativen AI Modell mam Zil 3D-konsistente Multiple-View Biller mat engem eenzegen Viewingang ze generéieren. Fir de Virdeel ze maximéieren, dee vu virdru pretrained generativen Modeller gewonnen gouf, implementéiert den Zero123++ Kader vill Trainings- a Konditiounsschemaen fir d'Quantitéit un Effort ze minimiséieren, déi et brauch fir aus off-the-shelf Diffusiounsbildmodeller ze finanzéieren. Mir hunn och déi verschidden Approchen an Verbesserungen diskutéiert, déi vum Zero123++ Kader ëmgesat ginn, deen et hëlleft Resultater ze erreechen, vergläichbar mat, a souguer iwwerschreiden déi, déi duerch den aktuellen Zoustand vun der Konscht Kaderen erreecht ginn.
Wéi och ëmmer, trotz senger Effizienz, a Fäegkeet fir qualitativ héichwäerteg Multi-View Biller konsequent ze generéieren, huet den Zero123++ Kader nach ëmmer e Raum fir Verbesserung, mat potenziellen Fuerschungsberäicher sinn eng
- Zwee-Etapp Refiner Modell dat kéint d'Onméiglechkeet vun Zero123++ léisen fir global Ufuerderunge fir Konsistenz z'erreechen.
- Zousätzlech Skala-Ups Zero123++ d'Fäegkeet fir Biller vun nach méi héijer Qualitéit ze generéieren.



