
Best of
10 Algorîtmayên Fêrbûna Makîneyê ya çêtirîn
Her çend em di dema fêrbûna makîneya bilezkirî ya GPU de di demek nûbûnek awarte de dijîn, kaxezên lêkolînê yên herî paşîn bi gelemperî (û berbiçav) algorîtmayên ku bi dehsalan in, di hin rewşan de 70 sal in vedihewînin.
Dibe ku hin kes îdia bikin ku gelek ji van rêbazên kevintir di şûna fêrbûna makîneyê de dikevin kampa 'analîzên îstatîstîkî', û tercîh dikin ku dîroka hatina sektorê tenê ji sala 1957-an ve paşde vegerînin. dahênana Perceptron.
Ji ber asta ku van algorîtmayên kevin piştgirî dikin û di nav meylên herî paşîn û pêşkeftinên sernivîsê de di fêrbûna makîneyê de ne, ew helwestek dijber e. Ji ber vê yekê em ê li hin blokên avahîsaziyê yên 'klasîk' ên ku nûbûnên herî paşîn vedihewînin, û her weha hin navnîşên nû yên ku ji bo salona navdar a AI-ê pêşnumayek zû dikin, binihêrin.
1: Transformers
Di sala 2017-an de Lêkolîna Google-ê hevkariyek lêkolînê kir ku di encamê de bi dawî bû kaxez Baldarî Hemî Te Need e. Di xebatê de mîmariya romanê ya ku pêş xistibû destnîşan kir mekanîzmayên balê ji 'boriyê' di şîfreker/dekoder û modelên torê yên dûbare de heya teknolojiyek veguherîna navendî bi serê xwe.
Nêzîkatî hate dublajkirin Transformer, û ji wê demê ve di Pêvajoya Zimanê Xwezayî (NLP) de bûye rêbazek şoreşgerî, di nav gelek mînakên din de, modela zimanê xweser û AI-a posterê-zarok GPT-3 hêzdar dike.
![]()
Transformers bi elegant pirsgirêka çareser kir veguherîna rêzê, jê re 'veguhertin' jî tê gotin, ku bi hilberandina rêzikên têketinê di rêzikên derketinê de mijûl e. Transformer di heman demê de daneyan bi rengekî domdar distîne û bi rê ve dibe, ji dêvla komikên rêzdar, rê dide 'berdewamiya bîranînê' ku mîmarên RNN ji bo bidestxistina wê ne hatine sêwirandin. Ji bo nêrînek berfirehtir a veguherîneran, lê binêre gotara referansa me.
Berevajî Torên Neuralî yên Recurrent (RNN) ku di serdema CUDA de dest bi serdestiya lêkolîna ML kiribû, mîmariya Transformer jî dikare bi hêsanî be. paralel kirin, rê vedike ku bi hilberînerî li ser berhevokek daneya ji RNN-ê pir mezintir çareser bike.
Bikaranîna populer
Transformers di sala 2020-an de bi serbestberdana GPT-3-ya OpenAI-yê, ya ku wê gavê rekorek şikestî pesnê xwe dide, xeyala gel girt. 175 milyar parametre. Ev destkeftiya berbiçav di dawiyê de ji hêla projeyên paşerojê ve, wekî sala 2021-an, hate dorpêç kirin. berdan Megatron-Turing NLG 530B ya Microsoft-ê, ku (wek ku nav diyar dike) zêdetirî 530 mîlyar parametre vedihewîne.

Demjimêrek projeyên hyperscale Transformer NLP. Kanî: microsoft
Mîmariya veguherîner jî ji NLP derbasî vîzyona komputerê bûye, hêz a nifşê nû çarçoveyên senteza wêneyê yên wekî OpenAI's KLIPP û SLAB, ku ji bo ku wêneyên netemam biqedîne û wêneyên nûjen ji domên perwerdekirî, di nav hejmareke zêde ya serîlêdanên têkildar de hevdeng bike, nivîsar> nexşeya domaina wêneyê bikar tîne.

DALL-E hewl dide ku wêneyek qismî ya bustek Platon temam bike. Çavkanî: https://openai.com/blog/dall-e/
2: Torên Dijbera Generative (GAN)
Her çend transformer bi berdan û pejirandina GPT-3 ve navgînek medyayê ya awarte bi dest xistine Tora Adversarial Generated (GAN) bi serê xwe bûye marqeyek naskirî, û dibe ku di dawiyê de beşdar bibe kûr wek lêker.
Pêşî pêşniyar kirin li 2014 û di serî de ji bo senteza wêneyê, Tora Dijbera Generative tê bikar anîn avakarî ji pêkhatiye Jenerator û a Cudakar. Generator di nav bi hezaran wêneyan de di nav daneyekê de digere, bi dûbare hewl dide ku wan ji nû ve ava bike. Ji bo her hewildanê, Cudakar karê Generatorê dinirxîne, û Generatorê vedigerîne da ku çêtir bike, lê bêyî ku têgihîştinek li ser awayê ku nûavakirina berê xelet bû.

Çavkanî: https://developers.google.com/machine-learning/gan/gan_structure
Ev zorê dide Generatorê ku gelek rêyan keşif bike, li şûna ku bişopîne rêçên kor ên potansiyel ên ku dê encam bigirta heke Cudakar jê re bigota ew li ku derê xelet diçû (li jêr #8 binêre). Wexta ku perwerde qediya, Generator nexşeyek hûrgulî û berfireh a têkiliyên di navbera xalên di databasê de heye.

Ji kaxezê Bi Bilindkirina Hişyariya Cihanî ve hevsengiya GAN-ê çêtir dike: çarçoveyek romanê di nav cîhê nepenî yê carinan-nepenî yê GAN de derbas dibe, ji bo mîmariya senteza wêneyê amûrek bersivdar peyda dike. Çavkanî: https://genforce.github.io/eqgan/
Bi analogî, ev ferqa di navbera fêrbûna rêwîtiyek yekane ya humdrum-ê berbi navenda London-ê, an bidestxistina bi êş e. The Knowledge.
Encam di cîhê dereng ên modela perwerdekirî de berhevokek asta bilind a taybetmendiyan e. Nîşana semantîkî ya taybetmendiyek asta bilind dikare 'kes' be, di heman demê de daketinek bi taybetmendiya bi taybetmendiyê re têkildar dibe ku taybetmendiyên din ên hînbûyî, wekî 'nêr' û 'jin' derxe holê. Di astên jêrîn de, jêr-taybetmendî dikarin wekî 'blonde', 'Qafqasî', û hwd.
Tevlihevî ye pirsgirêkek berbiçav di qada nepenî ya GAN û çarçoveyên şîfreker/dekoder de: kenê li ser rûyê jinê yê ku GAN-ê hatî hilberandin taybetmendiyek tevlihev a 'nasnameya wê ya di cîhê veşartî de ye, an ew şaxek paralel e?

Rûyên ku ji hêla GAN-ê ve hatî çêkirin ji vî kesî re tune. Çavkanî: https://this-person-does-not-exist.com/en
Van du salên çûyî di vî warî de jimarek zêde destpêşxeriyên lêkolînê yên nû derxistiye holê, dibe ku rê li ber verastkirina asta taybetmendiyê, şêwaza Photoshop-ê ji bo cîhê nepenî yê GAN-ê veke, lê heya niha, gelek veguhertin bi bandor in. pakêtên hemî an tiştek. Nemaze, serbestberdana EditGAN-a NVIDIA ya dawiya 2021-an bi dest dixe asta bilind ya şirovekirinê di qada veşartî de bi karanîna maskên dabeşkirina semantîk.
Bikaranîna populer
Ji xeynî tevlêbûna wan (bi rastî pir kêm) di vîdyoyên kûr-fake yên populer de, GAN-ên wêne/vîdyo-navendî di van çar salên dawî de zêde bûne, lêkolîner û gel bi heman rengî dilkêş dike. Xwedîderketina bi rêjeya gêjbûn û berbelavbûna berdanên nû dijwariyek e, her çend depoya GitHub Serlêdanên GAN-ê yên ecêb armanc dike ku navnîşek berfireh peyda bike.
Torên Dijberê yên Generator di teoriyê de dikarin taybetmendiyan ji her domainek baş-çarçovedar derxînin, di nav de nivîs.
3: SVM
Destpêk kirin li 1963, Piştgiriya Vector Machine (SVM) algorîtmayek bingehîn e ku di lêkolînên nû de pir caran çêdibe. Di binê SVM-ê de, vektor nexşeya pêveberiya têkildar a nuqteyên daneyê di nav daneyekê de, dema ku alîkarî vektor sînorên di navbera kom, taybetmendî an taybetmendiyên cihêreng de diyar dikin.
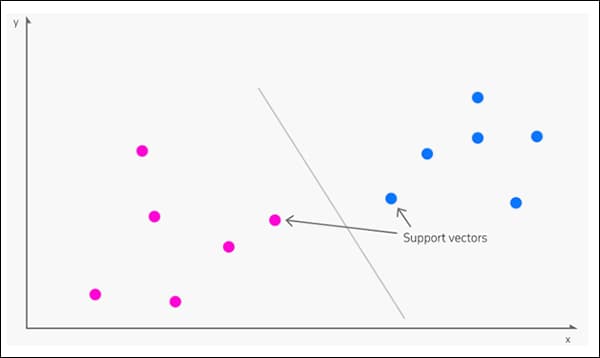
Vektorên piştevaniyê sînorên di navbera koman de diyar dikin. Çavkanî: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Ji sînorê derhatî re tê gotin a hîperplane.
Di astên taybetmendiya nizm de, SVM e du-alî (wêneya li jor), lê li ku derê jimareyek naskirî ya kom an celebek mezintir hebe, ew dibe sê-dimîn.

Komek kûrtir ji xal û koman SVM-ya sê-alî hewce dike. Çavkanî: https://cml.rhul.ac.uk/svm.html
Bikaranîna populer
Ji ber ku Piştgiriya Makîneyên Vector dikare bi bandor û agnostîk daneyên pir-dimensîyonel ên ji gelek celeban çareser bike, ew bi berfirehî li cûrbecûr sektorên fêrbûna makîneyê, di nav de tespîtkirina kûr, tesnîfkirina wêneyê, tesnîfkirina axaftina nefretê, Analîziya DNA û pêşbîniya avahiya nifûsê, di nav gelekên din.
4: K-Means Clustering
Clustering bi giştî an fêrbûna bêpergal nêzîkatiya ku hewl dide ku kategorîzekirina xalên daneyê bi rê ve texmîna density, çêkirina nexşeya belavkirina daneyên ku têne lêkolîn kirin.

K-Wateya komkirina beşan, kom û civakan di daneyan de ye. Çavkanî: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Means Clustering bûye pêkanîna herî populer a vê nêzîkatiyê, şivantiya xalên daneyê di nav "K-Komên" de vedihewîne, ku dibe ku sektorên demografîk, civakên serhêl, an kombûnek veşartî ya gengaz a din a ku li bendê ne ku di daneyên statîstîkî yên xav de were kifş kirin nîşan bide.

Kom di analîza K-Means de çêdibin. Çavkanî: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Nirxa K bixwe faktora diyarker e di karanîna pêvajoyê de, û di damezrandina nirxek çêtirîn ji bo komekê. Di destpêkê de, nirxa K bi korfelaqî tê destnîşan kirin, û taybetmendî û taybetmendiyên vektorê li gorî cîranên xwe têne berhev kirin. Ew cîranên ku herî zêde dişibin nuqteya daneyê ya bi nirxa ku bi korfelaqî ve hatî veqetandin, bi rengek dubare li koma wê têne tayîn kirin heya ku dane hemî komên ku pêvajo destûr dide peyda bike.
Pîvana ji bo xeletiya çargoşe, an 'mesrefa' nirxên cihêreng ên di nav koman de dê nîşan bide xala milê ji bo daneyan:

Di grafikek komê de 'xala elbikê'. Çavkanî: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Xala kulmê di têgînê de dişibihe awayê ku winda di dawiya danişînek perwerdehiyê de ji bo databasê kêm dibe. Ew nuqteya ku tê de çu cûdahiyên din di navbera koman de xuya nabin temsîl dike, dema ku meriv derbasî qonaxên paşîn ên di lûleya daneyê de bibe, an wekî din raporkirina dîtinan destnîşan dike.
Bikaranîna populer
K-Means Clustering, ji ber sedemên diyar, teknolojiyek bingehîn e di analîza xerîdar de, ji ber ku ew metodolojîyek zelal û raveker pêşkêşî dike da ku hejmarek mezin ji tomarên bazirganî wergerîne têgihîştinên demografîk û 'rêber'.
Li derveyî vê serîlêdanê, K-Means Clustering jî ji bo xebitandin pêşbîniya erdhejê, dabeşkirina wêneya bijîşkî, senteza wêneyê bi GANan, tesnîfkirina belgeyê, û plansaziya bajêr, di nav gelek karanîna potansiyel û rastîn ên din de.
5: Daristana Random
Daristana Random an e fêrbûna ensembleyê rêbaza ku navînî encama ji array ji darên biryarê da ku pêşbîniyek giştî ji bo encamê saz bikin.

Çavkanî: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Ger we bi qasî temaşekirina wê jî lêkolîn kiriye Back to the Future trîlojî, dara biryarê bi xwe têgihîştinek pir hêsan e: hejmarek rê li ber we ne, û her rêyek berbi encamek nû ve diçe, ku di encamê de rêyên gengaz ên din jî vedihewîne.
In hînbûna hînkirinê, dibe ku hûn ji rêyek vekişin û dîsa ji helwestek berê dest pê bikin, lê darên biryarê bi rêwîtiyên xwe ve girêdayî ne.
Ji ber vê yekê algorîtmaya Daristana Random bi bingehîn ji bo biryaran betal e. Ji ber ku algorîtmayê çêdike jê re 'random' tê gotin ad hoc hilbijartin û çavdêriyên ji bo têgihîştina median berhevoka encamên ji rêza dara biryarê.
Ji ber ku ew gelek faktoran dihesibîne, nêzîkatiyek Daristana Random dikare ji dara biryarê veguhertina grafikên watedar dijwartir be, lê dibe ku bi taybetî hilbertir be.
Darên biryarê bi zêdebarkirinê ve girêdayî ne, li cihê ku encamên ku têne wergirtin dane-taybetî ne û ne gengaz e ku gelemperî bibin. Hilbijartina keyfî ya xalên daneyê ji hêla Random Forest ve li dijî vê meylê şer dike, di nav daneyan de berbi meylên nûnerê watedar û bikêr ve diçe.

Vegerandina dara biryarê. Çavkanî: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Bikaranîna populer
Mîna gelek algorîtmayên di vê navnîşê de, Random Forest bi gelemperî wekî dabeşkerek 'destpêkê' û parzûnek daneyê tevdigere, û wekî wusa bi domdarî di kaxezên lêkolînê yên nû de derdikeve. Hin mînakên karanîna Daristana Random hene Senteza Wêne Rezonansê Magnetic, Pêşbîniya bihayê Bitcoin, dabeşkirina serjimartinê, tesnîfkirina nivîsê û tespîtkirina sextekariya qerta krediyê.
Ji ber ku Daristana Rasthatî di mîmarên fêrbûna makîneyê de algorîtmayek nizm e, ew dikare di performansa rêbazên din ên asta nizm de, û her weha algorîtmayên dîtbarîkirinê, tevî Clustering Inductive, Veguherandinên taybetmendiyê, dabeşkirina belgeyên nivîsê bikaranîna taybetmendiyên sparse, û nîşankirina Pipelines.
6: Naive Bayes
Bi texmîna dendikê ve girêdayî ye (binêre 4, jor), a naive Bayes Klasifker algorîtmayek bi hêz lê nisbeten sivik e ku karibe îhtîmalan li ser bingeha taybetmendiyên hesabkirî yên daneyan texmîn bike.

Têkiliyên taybetmendiyê di dabeşkerek Bayes a naîf de. Çavkanî: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Peyva 'naîf' tê wateya têgihîştina di nav de Teorema Bayes ku taybetiyên negirêdayî ne, tê zanîn serxwebûna şert. Ger hûn vê helwestê bipejirînin, rêveçûn û axaftina mîna ordek têrê nake ku em bi ordek re têkildar in, û tu texmînên 'eşkere' ji zû de nayên pejirandin.
Ev asta hişkiya akademîk û lêpirsînê dê li cîhê ku 'aqilê hevpar' heye pir zêde be, lê gava ku meriv li gelek nezelalî û têkiliyên potansiyel ên negirêdayî yên ku dibe ku di danehevek fêrbûna makîneyê de hebin, standardek hêja ye.
Di torgilokek Bayesian ya orîjînal de, taybetmendî di bin çavan de ne fonksiyonên tomarkirinê, di nav de dirêjahiya danasîna hindiktirîn û Gola Bayesian, ku dikare di warê girêdanên texmînkirî yên ku di navbera xalên daneyê de têne dîtin, û rêgezên ku van pêwendiyan tê de diherikin de, sînorkirina daneyan ferz bike.
Berevajî vê, dabeşkerek Bayes a naîf, bi texmîna ku taybetmendiyên tiştek diyarkirî serbixwe ne tevdigere, di dûv re teorema Bayes bikar tîne da ku îhtîmala tiştekê diyarkirî, li gorî taybetmendiyên wê, hesab bike.
Bikaranîna populer
Parzûnên Naive Bayes di nav de baş têne temsîl kirin pêşbîniya nexweşiyê û kategorîzekirina belgeyê, Parzûna spam, dabeşkirina hest, sîstemên pêşniyarker, û tespîtkirina xapandinê, di nav serîlêdanên din de.
7: K- Cîranên herî nêzîk (KNN)
Yekem ji hêla Dibistana Dermanê Avhewayê ya Hêza Hewayî ya Dewletên Yekbûyî ve hatî pêşniyar kirin li 1951, û pêdivî ye ku xwe li gorî zencîreya nûjen a nîvê sedsala 20-an a komputerê bicîh bîne, K-Nêziktirîn Cîran (KNN) algorîtmayek bêhêz e ku hîn jî di nav kaxezên akademîk û însiyatîfa lêkolîna fêrbûna makîneyê ya sektora taybet de bi giranî xuya dike.
KNN jê re 'xwendekarê tembel' tê binavkirin, ji ber ku ew bi berfirehî danezanek dişoxilîne da ku têkiliyên di navbera xalên daneyê de binirxîne, li şûna ku pêdivî bi perwerdehiya modelek fêrbûna makîneya bêkêmasî hebe.

Komek KNN. Kanî: https://scikit-learn.org/stable/modules/neighbors.html
Her çend KNN ji hêla mîmarî ve zirav e, lê nêzîkatiya wê ya sîstematîk daxwazek berbiçav li ser operasyonên xwendin/nivîsandinê pêk tîne, û karanîna wê di danehevên pir mezin de bêyî teknolojiyên pêvek ên wekî Analîzkirina Parçeya Sereke (PCA), ku dikare danehevên tevlihev û qebareya bilind biguhezîne pirsgirêk dibe. li komên nûneran ku KNN dikare bi hewldanek kêmtir derbas bibe.
A lêkolîneke dawî karîgerî û aborîya çend algorîtmayên ku ji bo pêşbînîkirina ka karmendek dê ji pargîdaniyek derkeve nirxand, dît ku KNN-ya septuagenarian di warê rastbûn û bandorkeriya pêşdîtinê de ji pêşbazên nûjentir ma.
Bikaranîna populer
Digel hemî sadebûna xwe ya populer a têgîn û darvekirinê, KNN di salên 1950-an de asê nebûye - ew di nav de hatî adapte kirin. nêzîkatiyek bêtir li ser DNN-ê di pêşnûmeya 2018-an de ji hêla Zanîngeha Dewleta Pennsylvania ve, û di gelek çarçoveyên fêrbûna makîneyê de pir tevlihevtir pêvajoyek qonaxa destpêkê ya navendî (an amûrek analîtîk a paş-pêvajoyê) dimîne.
Di veavakirinên cihêreng de, KNN an ji bo hatî bikar anîn verastkirina îmzeya serhêl, tesnîfkirina wêneyê, nivîsandina madenê, pêşbîniya çandiniyê, û pejirandina rûyê, ji bilî serîlêdan û pargîdaniyên din.

Di perwerdehiyê de pergalek nasîna rûyê KNN-ê. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Pêvajoya Biryara Markov (MDP)
Çarçoveyek matematîkî ku ji hêla matematîkzanê Amerîkî Richard Bellman ve hatî destnîşan kirin li 1957, Pêvajoya Biryara Markov (MDP) yek ji blokên herî bingehîn e hînbûna hînkirinê mîmarî. Algorîtmayek têgihîştî bi serê xwe, ew di hejmareke mezin a algorîtmayên din de hatî adapte kirin, û di berhema heyî ya lêkolîna AI/ML de pir caran dubare dibe.
MDP bi karanîna nirxandina rewşa xwe ya heyî (ango 'ku' ew di daneyê de ye) hawîrdorek daneyê vedikole da ku biryarê bide ka kîjan girêka daneyê dê paşê keşif bike.

Çavkanî: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Pêvajoyek Biryara Markov a bingehîn dê berjewendiya nêzîk-demê li ser armancên dirêj-demdirêj ên bêtir xwestî bide pêş. Ji ber vê yekê, ew bi gelemperî di nav çarçoweya mîmariya polîtîkaya berfirehtir de di fêrbûna xurtkirinê de tête bicîh kirin, û bi gelemperî ji faktorên sînordar ên wekî xelata erzankirî, û guhêrbarên hawîrdorê yên din ên guhezker ên ku dê pêşî lê bigirin ku ew berbi armancek tavilê venegere bêyî berçavgirtina encamên berfireh ên xwestî.
Bikaranîna populer
Têgîna asta nizm a MDP hem di lêkolînê de û hem jî di bicîhkirina çalak a fêrbûna makîneyê de berbelav e. Ew ji bo pêşniyar kirin Sîstemên parastina ewlehiya IoT, berhevkirina masiyan, û pêşbîniya bazarê.
Ji bilî wê sepandin eşkere ji bo şetrenc û lîstikên din ên hişk ên rêzdar, MDP di heman demê de ji bo lîstikan jî hevrikek xwezayî ye perwerdehiya pêvajoyê ya pergalên robotîkê, wekî em dikarin di vîdyoya jêrîn de bibînin.

9: Term Frequency-Inverse Document Frequency
Frequency Term (TF) hejmara carên ku peyvek di belgeyekê de xuya dibe bi hejmara giştî ya peyvên di wê belgeyê de dabeş dike. Bi vî awayî peyva seal di gotara hezar peyvan de carek xuya dibe xwedî frekansa termê 0.001 e. Ji xwe, TF bi giranî wekî nîşanek girîngiya termê bêkêr e, ji ber vê yekê ku gotarên bêwate (wek mînak a, û, ew, û it) serdest in.
Ji bo bidestxistina nirxek watedar ji bo termekê, Frekansa Belgeya Berevajî (IDF) TF-ya peyvekê li ser gelek belgeyên di danehevekê de dihejmêre, nirxa kêm ji frekansa pir bilind re destnîşan dike. stopwords, wek gotar. Vektorên taybetmendiyê yên encam bi tevahî nirxan têne normalîze kirin, bi her peyvê re giraniyek guncan tê destnîşan kirin.

TF-IDF eleqedariya peyvan li ser bingeha frekansa di nav hejmarek belgeyan de giran dike, digel bûyera hindiktir nîşanek girîngiyê. Çavkanî: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Her çend ev nêzîkatî rê nade ku peyvên girîng ên semantîkî wekî wenda bibin ji derve, berevajîkirina giraniya frekansê bixweber nayê wê wateyê ku termek frekansa kêm e ne ji derve, ji ber ku hin tişt kêm in û bêqîmet. Ji ber vê yekê têgînek bi frekansa nizm dê hewce bike ku nirxa xwe di çarçoveyek mîmarî ya berfireh de îspat bike bi taybetmendîkirina (tewra bi frekansek hindik ji bo her belgeyek) di hejmarek belgeyên di databasê de.
Tevî wê kalbûn, TF-IDF rêbazek hêzdar û populer e ji bo parzûnên destpêkê yên di çarçoveyên Pêvajoya Zimanê Xwezayî de.
Bikaranîna populer
Ji ber ku TF-IDF di van bîst salên dawî de bi kêmanî beşek di pêşkeftina algorîtmaya PageRank ya Google ya pir nepenî de lîstiye, ew bûye pir berfireh hate pejirandin wekî taktîkek SEO ya manipulatîf, tevî John Mueller 2019 redkirin girîngiya wê ya encamên lêgerînê.
Ji ber nepeniya li dora PageRank, delîlek zelal tune ku TF-IDF ye ne niha taktîkek bi bandor ji bo rabûna di rêzên Google de. Incendiary nîqaş di nav pisporên IT-ê de van demên dawî têgihiştinek populer destnîşan dike, rast an na, ku destdirêjiya termê hîn jî dibe ku bibe sedema çêtirkirina cîhê SEO (her çend zêde tawanbarkirina binpêkirina yekdestdariyê û reklama zêde sînorên vê teoriyê ronî bikin).
10: Descent Gradient Stochastic
Descent Gradient Stochastic (SGD) rêbazek her ku diçe populer e ji bo xweşbînkirina perwerdehiya modelên fêrbûna makîneyê.
Daketina Gradient bi xwe rêbazek xweşbînkirin û dûv re jimartina başbûna ku modelek di dema perwerdehiyê de çêdike ye.
Di vê wateyê de, 'gradient' ber bi xwarê ve nîşan dide (ji dêvla rengvedanek bingehîn, li wêneya jêrîn binêre), ku xala herî bilind a 'gir', li milê çepê, destpêka pêvajoya perwerdehiyê temsîl dike. Di vê qonaxê de, modelê hîn yek carî jî tevahî daneyan nedîtiye, û têra têkiliyên di navbera daneyan de fêr nebûye ku veguherînên bi bandor çêbike.

Li ser danişîna perwerdehiyê ya FaceSwap daketinek gradient. Em dikarin bibînin ku perwerde di nîvê duyemîn de ji bo demek dirêj bûye, lê di dawiyê de rêça xwe berbi pileyê berbi hevbûnek pejirandî vegerandiye.
Xala herî jêrîn, li milê rastê, hevgirtinê temsîl dike (xala ku tê de model bi qasî ku ew ê di bin sînor û mîhengên ferzkirî de biçe bi bandor e).
Pîvan wekî tomar û pêşbînkerê cudahiya di navbera rêjeya xeletiyê de (modelê niha çiqas rast nexşeya têkiliyên daneyê xêz kiriye) û giranan (mîhengên ku bandorê li awayê fêrbûna modelê dikin) dike.
Ev qeyda pêşketinê dikare ji bo agahdarkirina a bernameya rêjeya fêrbûnê, pêvajoyek otomatîkî ya ku ji mîmariyê re dibêje ku ew hûrgulî û rasttir bibe ji ber ku hûrguliyên nezelal ên destpêkê vediguherin têkilî û nexşeyên zelal. Di rastiyê de, windabûna gradient nexşeyek tam---dem-ê peyda dike ku divê perwerde li ku derê biçe, û ew çawa divê bidome.
Nûbûniya Stochastic Gradient Descent ev e ku ew li ser her mînakek perwerdehiyê her dubarekirinê pîvanên modelê nûve dike, ku bi gelemperî rêwîtiya berbi hevgirtinê lez dike. Ji ber hatina berhevokên daneyên hîperscale di van salên dawî de, SGD di van demên dawî de wekî rêbazek mimkun e ku ji bo çareserkirina pirsgirêkên lojîstîkî yên paşîn populerbûna xwe zêde kiriye.
Li aliyê din, SGD heye bandorên neyînî ji bo pîvandina taybetmendiyê, û dibe ku ji bo bidestxistina heman encamê bêtir dubareyan hewce bike, li gorî Daketina Gradientê ya birêkûpêk pêdivî bi plansazkirina zêde û pîvanên zêde heye.
Bikaranîna populer
Ji ber veavakirina wê, û tevî kêmasiyên xwe, SGD bûye algorîtmaya xweşbîniyê ya herî populer ji bo bicîhkirina torên neuralî. Yek veavakirina SGD-yê ku di kaxezên lêkolînê yên nû yên AI/ML de serdest dibe, bijartina Texmîna Momenta Adaptive (ADAM, hatî destnîşan kirin) ye li 2015) optimizer.
ADAM rêjeya fêrbûnê ji bo her parametreyê bi dînamîk ('rêjeya fêrbûna adaptîf') adapte dike, û hem jî encamên ji nûvekirinên berê di veavakirina paşîn de ('momentum') vedigire. Wekî din, ew dikare were mîheng kirin da ku nûbûnên paşîn bikar bîne, wek mînak Nesterov Momentum.
Lêbelê, hin kes diparêzin ku karanîna momentumê di heman demê de dikare ADAM (û algorîtmayên mîna) bi a Encama bin-optimal. Mîna ku piraniya deşta xwînê ya sektora lêkolîna fêrbûna makîneyê, SGD xebatek li pêş e.
Yekem di 10-ê Sibata 2022-an de hate weşandin. 10-ê Sibatê 20.05 EET hate guherandin - formatkirin.















