
ხელოვნური ინტელექტი
RigNeRF: Deepfakes-ის ახალი მეთოდი, რომელიც იყენებს ნერვულ გამოსხივების ველებს

Adobe-ში შემუშავებული ახალი კვლევა გვთავაზობს პირველ სიცოცხლისუნარიან და ეფექტურ ღრმა ფეიქსის მეთოდს ნერვული გამოსხივების ველები (NeRF) – ალბათ პირველი რეალური ინოვაცია არქიტექტურაში ან მიდგომაში 2017 წელს ღრმა ფეიქების გაჩენის შემდეგ ხუთი წლის განმავლობაში.
მეთოდი, სახელწოდებით RigNeRF, იყენებს 3D მორფირებული სახის მოდელები (3DMM), როგორც ინსტრუმენტულობის ინტერსტიციული ფენა სასურველ შეყვანას (ანუ იდენტობას, რომელიც უნდა დაწესდეს NeRF რენდერში) და ნერვულ სივრცეს შორის, მეთოდი, რომელიც იყო ფართოდ მიღებული ბოლო წლებში Generative Adversarial Network (GAN) სახის სინთეზის მიდგომებით, რომელთაგან არცერთს ჯერ არ შეუქმნია ფუნქციური და გამოსადეგი სახის ჩანაცვლების ჩარჩოები ვიდეოსთვის.

ტრადიციული ღრმა ფაქიზი ვიდეოებისგან განსხვავებით, აქ გამოსახული აბსოლუტურად არცერთი მოძრავი კონტენტი არ არის „რეალური“, არამედ არის საკვლევი ნერვული სივრცე, რომელიც გაწვრთნილი იყო მოკლე კადრებზე. მარჯვნივ ჩვენ ვხედავთ 3D მორფირებადი სახის მოდელს (3DMM), რომელიც მოქმედებს როგორც ინტერფეისი სასურველ მანიპულაციებს შორის („ღიმილი“, „მარცხნივ გაიხედე“, „მაღლა ახედე“ და ა. ვიზუალიზაცია. ამ კლიპის მაღალი გარჩევადობის ვერსიისთვის, სხვა მაგალითებთან ერთად, იხილეთ პროექტის გვერდი, ან ჩაშენებული ვიდეოები ამ სტატიის ბოლოს. წყარო: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM ფაქტობრივად არის სახეების CGI მოდელები, რომელთა პარამეტრები შეიძლება ადაპტირდეს უფრო აბსტრაქტულ გამოსახულების სინთეზის სისტემებთან, როგორიცაა NeRF და GAN, რომელთა კონტროლი სხვაგვარად რთულია.
რასაც ხედავთ ზემოთ მოცემულ სურათზე (შუა გამოსახულება, კაცი ლურჯ პერანგში), ისევე როგორც სურათი პირდაპირ ქვემოთ (მარცხნივ სურათი, კაცი ლურჯ პერანგში), არ არის „რეალური“ ვიდეო, რომელშიც არის პატარა ნაწილი „ ყალბი სახე გადაფარებულია, მაგრამ მთლიანად სინთეზირებული სცენა, რომელიც არსებობს მხოლოდ მოცულობითი ნერვული რენდერის სახით - სხეულისა და ფონის ჩათვლით:

პირდაპირ ზემოთ მოცემულ მაგალითში, რეალური ვიდეო მარჯვნივ (ქალი წითელ კაბაში) გამოიყენება მარცხნივ დატყვევებული იდენტობის (მამაკაცი ცისფერ პერანგში) „მარიონეტისთვის“ RigNeRF-ის საშუალებით, რომელიც (ავტორები ამტკიცებენ) პირველია. NeRF-ზე დაფუძნებული სისტემა პოზისა და ექსპრესიის განცალკევების მისაღწევად, ხოლო ახალი ხედვის სინთეზების შესასრულებლად.
მამაკაცის ფიგურა მარცხნივ, ზემოთ მოცემულ სურათზე, „ამოღებულია“ სმარტფონის 70 წამიანი ვიდეოდან, ხოლო შეყვანის მონაცემები (მათ შორის მთელი სცენის ინფორმაცია) შემდგომში 4 V100 GPU-ზე ივარჯიშება სცენის მისაღებად.
ვინაიდან 3DMM სტილის პარამეტრული მოწყობილობები ასევე ხელმისაწვდომია როგორც მთელი სხეულის პარამეტრული CGI მარიონეტები (უბრალოდ სახის რგოლების ნაცვლად), RigNeRF პოტენციურად ხსნის მთელ სხეულზე ღრმა ფეიქების შესაძლებლობას, სადაც ადამიანის რეალური მოძრაობა, ტექსტურა და გამოხატულება გადაეცემა CGI-ზე დაფუძნებულ პარამეტრულ ფენას, რომელიც შემდეგ აქცევს მოქმედებას და გამოხატვას NeRF გარემოში და ვიდეოებში. .
რაც შეეხება RigNeRF – კვალიფიცირდება თუ არა ის ღრმა ფეიკის მეთოდად ამჟამინდელი გაგებით, რომ სათაურები ესმით ტერმინს? თუ ეს არის კიდევ ერთი ნახევრად ჩართული DeepFaceLab და სხვა შრომატევადი, 2017 ეპოქის ავტოინკოდერის ღრმა ყალბი სისტემები?
ახალი ნაშრომის მკვლევარები ამ საკითხში ცალსახა არიან:
"როგორც მეთოდი, რომელსაც შეუძლია სახეების რეანიმაცია, RigNeRF მიდრეკილია ცუდი მსახიობების მიერ ბოროტად გამოყენებისკენ ღრმა ფეიქების შესაქმნელად."
ახალი ქაღალდი სახელდება RigNeRF: სრულად კონტროლირებადი ნერვული 3D პორტრეტებიდა მოდის შაჰრუხ ათჰადან Stonybrook University-დან, Adobe-ში სტაჟიორი RigNeRF-ის განვითარების პერიოდში და ოთხი სხვა ავტორი Adobe Research-დან.
Autoencoder-ზე დაფუძნებული Deepfakes-ის მიღმა
ვირუსული ღრმა ფეიქების უმეტესობა, რომლებიც ბოლო რამდენიმე წლის განმავლობაში სათაურებს იპყრობდა, წარმოებულია ავტომატური კოდირება-დაფუძნებული სისტემები, მიღებული კოდიდან, რომელიც გამოქვეყნდა სასწრაფოდ აკრძალულ r/deepfakes subreddit-ზე 2017 წელს – თუმცა არა მანამდე გადაწერა GitHub-ში, სადაც ის ამჟამად ჩანგალი იყო ათასჯერ მეტი, განსაკუთრებით პოპულარულში (თუ საკამათო) DeepFaceLab განაწილება და ასევე სახის გაცვლა პროექტი.
GAN-ისა და NeRF-ის გარდა, ავტომატური კოდირების ჩარჩოებმა ასევე ექსპერიმენტები ჩაატარეს 3DMM-ებით, როგორც „სახელმძღვანელოები“ სახის სინთეზის გაუმჯობესებული ჩარჩოებისთვის. ამის მაგალითია HifiFace პროექტი 2021 წლის ივლისიდან. თუმცა, როგორც ჩანს, ამ მიდგომიდან დღემდე არც ერთი გამოსადეგი ან პოპულარული ინიციატივა არ განვითარებულა.
RigNeRF სცენების მონაცემები მიიღება სმარტფონის მოკლე ვიდეოების გადაღებით. პროექტისთვის RigNeRF-ის მკვლევარებმა გამოიყენეს iPhone XR ან iPhone 12 ყველა ექსპერიმენტისთვის. გადაღების პირველი ნახევრის განმავლობაში, სუბიექტს სთხოვენ შეასრულოს სახის გამონათქვამებისა და მეტყველების ფართო დიაპაზონი, სანამ კამერა მოძრაობს მათ გარშემო.
გადაღების მეორე ნახევრის განმავლობაში, კამერა ინარჩუნებს ფიქსირებულ პოზიციას, ხოლო სუბიექტმა უნდა მოძრაობს თავი გარშემო და გამოხატავს გამოხატვის ფართო სპექტრს. შედეგად მიღებული 40-70 წამი კადრები (დაახლოებით 1200-2100 კადრი) წარმოადგენს მთელ მონაცემთა ბაზას, რომელიც გამოყენებული იქნება მოდელის მოსამზადებლად.
მონაცემთა შეგროვების შემცირება
ამის საპირისპიროდ, ავტომატური კოდირების სისტემები, როგორიცაა DeepFaceLab, მოითხოვს ათასობით მრავალფეროვანი ფოტოს შედარებით შრომატევად შეგროვებას და დამუშავებას, რომლებიც ხშირად გადაღებულია YouTube ვიდეოებიდან და სოციალური მედიის სხვა არხებიდან, ასევე ფილმებიდან (ცნობილთა ღრმა ფეიქების შემთხვევაში).
შედეგად მომზადებული ავტოინკოდერის მოდელები ხშირად განკუთვნილია სხვადასხვა სიტუაციებში გამოსაყენებლად. თუმცა, ყველაზე შრომატევადი „სელბრიტების“ ღრმა ფეიკერებს შეუძლიათ მთელი მოდელები ნულიდან მოამზადონ ერთი ვიდეოსთვის, მიუხედავად იმისა, რომ ვარჯიშს შეიძლება ერთი კვირა ან მეტი დასჭირდეს.
მიუხედავად ახალი ნაშრომის მკვლევარების გამაფრთხილებელი შენიშვნისა, "patchwork" და ფართოდ აწყობილი მონაცემთა ნაკრები, რომელიც აძლიერებს ხელოვნური ინტელექტის პორნოს, ისევე როგორც პოპულარული YouTube/TikTok "ღრმა ყალბი რეკასტინგები", როგორც ჩანს, ნაკლებად სავარაუდოა, რომ გამოიღოს მისაღები და თანმიმდევრული შედეგები ღრმა ყალბ სისტემაში, როგორიცაა RigNeRF. რომელსაც აქვს სცენის სპეციფიკური მეთოდოლოგია. ახალ ნამუშევარში ასახული მონაცემების აღრიცხვის შეზღუდვების გათვალისწინებით, ეს შეიძლება გარკვეულწილად დაამტკიცოს დამატებითი დაცვა მავნე ღრმა ფაკერების მიერ პირადობის შემთხვევითი მითვისებისგან.
NeRF-ის ადაპტაცია Deepfake ვიდეოზე
NeRF არის ფოტოგრამეტრიაზე დაფუძნებული მეთოდი, რომლის დროსაც სხვადასხვა კუთხიდან გადაღებული წყაროს სურათების მცირე რაოდენობა იკრიბება შესასწავლად 3D ნერვულ სივრცეში. ეს მიდგომა ცნობილი გახდა ამ წლის დასაწყისში, როდესაც NVIDIA-მ გამოაქვეყნა მისი მყისიერი NeRF სისტემა, რომელსაც შეუძლია შეამციროს ვარჯიშის გადაჭარბებული დრო NeRF-ისთვის წუთებამდე ან თუნდაც წამამდე:

მყისიერი NeRF. წყარო: https://www.youtube.com/watch?v=DJ2hcC1orc4
შედეგად მიღებული ნერვული გამოსხივების ველის სცენა არსებითად არის სტატიკური გარემო, რომლის შესწავლა შესაძლებელია, მაგრამ რაც არის რთული რედაქტირება. მკვლევარები აღნიშნავენ, რომ წინა NeRF-ზე დაფუძნებული ინიციატივა - HyperNeRF + E/P მდე NerFACE – დაარტყა სახის ვიდეოს სინთეზს და (როგორც ჩანს, სისრულისა და შრომისმოყვარეობის გამო) ტესტირების რაუნდში დააყენა RigNeRF ამ ორ ჩარჩოში:


თვისებრივი შედარება RigNeRF, HyperNeRF და NerFACE-ს შორის. იხილეთ მიბმული წყარო ვიდეოები და PDF უფრო მაღალი ხარისხის ვერსიებისთვის. სტატიკური გამოსახულების წყარო: https://arxiv.org/pdf/2012.03065.pdf
თუმცა, ამ შემთხვევაში, შედეგები, რომლებიც ხელს უწყობს RigNeRF-ს, საკმაოდ ანომალიურია, ორი მიზეზის გამო: პირველ რიგში, ავტორები აკვირდებიან, რომ „არ არსებობს ვაშლი-ვაშლის შედარების სამუშაო“; მეორეც, ამან მოითხოვა RigNeRF-ის შესაძლებლობების შეზღუდვა, რათა ნაწილობრივ მაინც შეესაბამებოდეს წინა სისტემების უფრო შეზღუდულ ფუნქციონირებას.
იმის გამო, რომ შედეგები არ არის წინა სამუშაოს დამატებითი გაუმჯობესება, არამედ წარმოადგენს "გარღვევას" NeRF რედაქტირებასა და სარგებლიანობაში, ჩვენ ტესტირების რაუნდს განზე დავტოვებთ და ამის ნაცვლად ვნახავთ რას აკეთებს RigNeRF განსხვავებულად მისი წინამორბედებისგან.
კომბინირებული ძლიერი მხარეები
NerFACE-ის პირველადი შეზღუდვა, რომელსაც შეუძლია შექმნას პოზების/გამოხატვის კონტროლი NeRF გარემოში, არის ის, რომ იგი ვარაუდობს, რომ წყაროს კადრები იქნება გადაღებული სტატიკური კამერით. ეს ფაქტობრივად ნიშნავს, რომ მას არ შეუძლია შექმნას ახალი შეხედულებები, რომლებიც სცილდება მის დაჭერის შეზღუდვებს. ეს აწარმოებს სისტემას, რომელსაც შეუძლია შექმნას „მოძრავი პორტრეტები“, მაგრამ რომელიც გამოუსადეგარია ღრმა ფეიკის სტილის ვიდეოებისთვის.
მეორე მხრივ, HyperNeRF-ს შეუძლია ახალი და ჰიპერ-რეალური ხედების გენერირება, მაგრამ არ აქვს ინსტრუმენტი, რომელიც საშუალებას აძლევს მას შეცვალოს თავის პოზები ან სახის გამონათქვამები, რაც კვლავ არ იწვევს რაიმე სახის კონკურენტს ავტოენკოდერზე დაფუძნებული ღრმა ფეიქებისთვის.
RigNeRF-ს შეუძლია დააკავშიროს ეს ორი იზოლირებული ფუნქციონალობა „კანონიკური სივრცის“ შექმნის გზით, ნაგულისხმევი საბაზისო ხაზი, საიდანაც გადახრები და დეფორმაციები შეიძლება განხორციელდეს 3DMM მოდულიდან შეყვანის გზით.
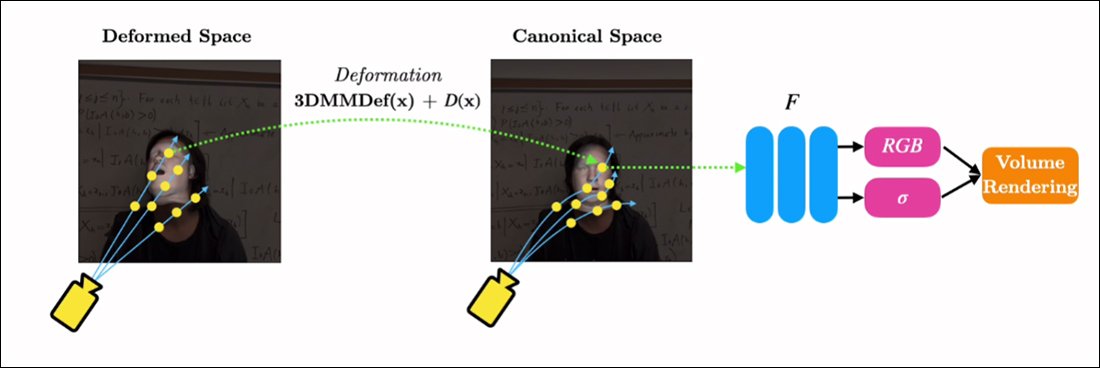
„კანონიკური სივრცის“ შექმნა (პოზის გარეშე, გამოხატვის გარეშე), რომელზედაც მოქმედებენ 3DMM-ის მეშვეობით წარმოქმნილი დეფორმაციები (ანუ პოზები და გამონათქვამები).
ვინაიდან 3DMM სისტემა ზუსტად არ ემთხვევა გადაღებულ საგანს, მნიშვნელოვანია ამის კომპენსირება პროცესში. RigNeRF ამას ახორციელებს დეფორმაციის ველით, რომელიც გამოითვლება a-დან მრავალშრიანი Perceptron (MLP) მიღებული წყაროს კადრებიდან.

დეფორმაციების გამოსათვლელად საჭირო კამერის პარამეტრები მიიღება მეშვეობით COLMAP, ხოლო გამოსახულებისა და ფორმის პარამეტრები თითოეული ჩარჩოსთვის მიღებულია რომ.
პოზიციონირება კიდევ უფრო ოპტიმიზირებულია საეტაპო მორგება და COLMAP-ის კამერის პარამეტრები და, გამოთვლითი რესურსების შეზღუდვის გამო, ვიდეო გამომავალი 256×256 გარჩევადობამდე მცირდება ვარჯიშისთვის (ტექნიკით შეზღუდული შემცირების პროცესი, რომელიც ასევე აწუხებს ავტოინკოდერის ღრმა გაყალბების სცენას).
ამის შემდეგ, დეფორმაციის ქსელი ივარჯიშება ოთხ V100-ზე - შესანიშნავი აპარატურა, რომელიც, სავარაუდოდ, შემთხვევითი ენთუზიასტებისთვის მიუწვდომელია (თუმცა, როდესაც საქმე ეხება მანქანათმცოდნეობის ტრენინგს, ხშირად შესაძლებელია წონის გადაცვლა დროზე და უბრალოდ მიიღოს ეს მოდელი. ტრენინგი იქნება დღეების ან თუნდაც კვირების საკითხი).
დასასრულს, მკვლევარები აცხადებენ:
სხვა მეთოდებისგან განსხვავებით, RigNeRF-ს, 3DMM-ით მართული დეფორმაციის მოდულის გამოყენების წყალობით, შეუძლია მაღალი სიზუსტით შექმნას თავის პოზა, სახის გამომეტყველება და სრული 3D პორტრეტის სცენა, რითაც უკეთეს რეკონსტრუქციას იძლევა მკვეთრი დეტალებით.
იხილეთ ჩაშენებული ვიდეოები ქვემოთ დამატებითი დეტალებისა და შედეგების კადრებისთვის.


პირველად გამოქვეყნდა 15 წლის 2022 ივნისს.















