
ხელოვნური ინტელექტი
"ჰალუცინაციის" პრევენცია GPT-3 და სხვა რთულ ენობრივ მოდელებში

„ყალბი ამბების“ განმსაზღვრელი მახასიათებელია ის, რომ ის ხშირად წარმოადგენს ცრუ ინფორმაციას ფაქტობრივად სწორი ინფორმაციის კონტექსტში, ხოლო მცდარი მონაცემები აღქმულ ავტორიტეტს იძენს ერთგვარი ლიტერატურული ოსმოსით - ნახევრად სიმართლის ძალის შემაშფოთებელი დემონსტრირება.
დახვეწილი გენერაციული ბუნებრივი ენის დამუშავების (NLP) დამუშავების მოდელებს, როგორიცაა GPT-3, ასევე აქვთ ტენდენცია. "ჰალუცინაცია" ასეთი მატყუარა მონაცემები. ნაწილობრივ, ეს იმიტომ ხდება, რომ ენობრივ მოდელებს სჭირდებათ ტექსტის გრძელი და ხშირად ლაბირინთული ტრაქტატების ხელახალი ფორმულირება და შეჯამება, ყოველგვარი არქიტექტურული შეზღუდვის გარეშე, რომელსაც შეუძლია მოვლენებისა და ფაქტების განსაზღვრა, დალუქვა და „დალუქვა“ ისე, რომ ისინი დაცული იყოს სემანტიკური პროცესისგან. რეკონსტრუქცია.
ამიტომ ფაქტები არ არის წმინდა NLP მოდელისთვის; ისინი ადვილად შეიძლება განიხილებოდეს „ლეგოს სემანტიკური კუბიკების“ კონტექსტში, განსაკუთრებით მაშინ, როდესაც რთული გრამატიკა ან საიდუმლო წყაროს მასალა ართულებს დისკრეტული ერთეულების გამოყოფას ენის სტრუქტურისგან.

დაკვირვება იმაზე, თუ როგორ შეუძლია აურზაურით ფრაზებირებულ წყაროს მასალა აერიოს რთული ენობრივი მოდელები, როგორიცაა GPT-3. წყარო: პარაფრაზი თაობა ღრმა განმტკიცების სწავლის გამოყენებით
ეს პრობლემა გადადის ტექსტზე დაფუძნებული მანქანური სწავლებიდან კომპიუტერული ხედვის კვლევაში, განსაკუთრებით იმ სექტორებში, რომლებიც იყენებენ სემანტიკურ დისკრიმინაციას ობიექტების იდენტიფიცირებისთვის ან აღწერისთვის.

ჰალუცინაცია და არაზუსტი "კოსმეტიკური" რეინტერპრეტაცია ასევე გავლენას ახდენს კომპიუტერული ხედვის კვლევაზე.
GPT-3-ის შემთხვევაში, მოდელი შეიძლება იმედგაცრუებული იყოს განმეორებით დაკითხვით იმ თემაზე, რომელიც მან უკვე განიხილა, ისევე როგორც მას შეუძლია. საუკეთესო შემთხვევაში, ის აღიარებს დამარცხებას:

ჩემი ბოლო ექსპერიმენტი ძირითადი Davinci ძრავით GPT-3-ში. მოდელი პასუხს პირველივე მცდელობისას იღებს, მაგრამ შეშფოთებულია კითხვაზე მეორედ დასმით. ვინაიდან ის ინარჩუნებს წინა პასუხის მოკლევადიან მეხსიერებას და განმეორებით კითხვას განიხილავს, როგორც ამ პასუხის უარყოფას, ის აღიარებს დამარცხებას. წყარო: https://www.scalr.ai/post/business-applications-for-gpt-3
DaVinci და DaVinci Instruct (ბეტა) უკეთესად აკეთებენ ამ მხრივ, ვიდრე სხვა GPT-3 მოდელები, რომლებიც ხელმისაწვდომია API-ით. აქ კიურის მოდელი იძლევა არასწორ პასუხს, ხოლო ბაბიჯის მოდელი თავდაჯერებულად აფართოებს თანაბრად არასწორ პასუხს:
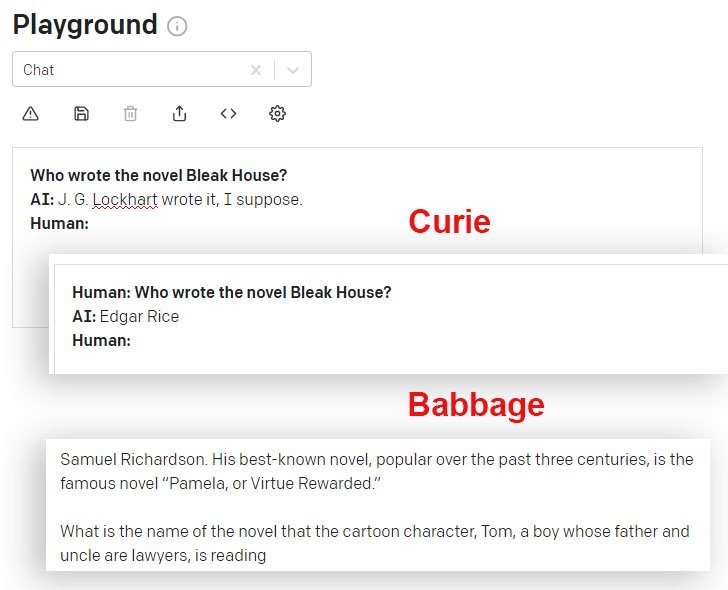
ის, რაც აინშტაინს არასოდეს უთქვამს
როდესაც ითხოვს GPT-3 DaVinci Instruct ძრავას (რომელიც ამჟამად ყველაზე ქმედუნარიანია) აინშტაინის ცნობილი ციტატისთვის "ღმერთი არ თამაშობს კამათელს სამყაროსთან", დავინჩის ინსტრუქტაჟი ვერ პოულობს ციტატას და იგონებს არაციტატას, გრძელდება. ჰალუცინაცია მოახდინოს სამი სხვა შედარებით დამაჯერებელი და სრულიად არარსებული ციტატა (აინშტაინის ან ვინმეს მიერ) მსგავსი კითხვების საპასუხოდ:

GPT-3 აწარმოებს აინშტაინის ოთხ სარწმუნო ციტატას, რომელთაგან არცერთი არ იძლევა რაიმე შედეგს ინტერნეტის სრული ტექსტის ძიებაში, თუმცა ზოგიერთი იწვევს აინშტაინის სხვა (რეალურ) ციტატებს "წარმოსახვის" თემაზე.
თუ GPT-3 მუდმივად ცდებოდა ციტირებისას, უფრო ადვილი იქნებოდა ამ ჰალუცინაციების პროგრამულად გამორიცხვა. თუმცა, რაც უფრო გავრცელებული და ცნობილი ციტატაა, მით უფრო სავარაუდოა, რომ GPT-3 ციტატას სწორად მიიღებს:

GPT-3 აშკარად პოულობს სწორ ციტატებს, როდესაც ისინი კარგად არის წარმოდგენილი ხელშემწყობ მონაცემებში.
მეორე პრობლემა შეიძლება წარმოიშვას, როდესაც GPT-3-ის სესიის ისტორიის მონაცემები ახალ კითხვაში გადადის:
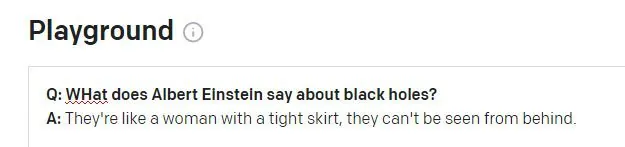
აინშტაინი, სავარაუდოდ, სკანდალიზებული იქნებოდა, თუ მას ეს გამონათქვამი მიეწერებოდა. ციტატა, როგორც ჩანს, რეალური უინსტონ ჩერჩილის უაზრო ჰალუცინაციაა აფორიზმი. GPT-3 სესიის წინა კითხვა ეხებოდა ჩერჩილს (არა აინშტაინს) და GPT-3, როგორც ჩანს, შეცდომით გამოიყენა ეს სესიის ჟეტონი პასუხის გასაგებად.
ჰალუცინაციების ეკონომიურად დაძლევა
ჰალუცინაცია მნიშვნელოვანი დაბრკოლებაა დახვეწილი NLP მოდელების, როგორც კვლევის ინსტრუმენტების მიღებაში - მით უმეტეს, რომ ასეთი ძრავებიდან მიღებული გამომავალი ძალზე აბსტრაქტულია მისი შემქმნელი საწყისი მასალისგან, ასე რომ ციტატებისა და ფაქტების სისწორის დადგენა პრობლემატური ხდება.
ამიტომ, NLP-ში არსებული ზოგადი კვლევის გამოწვევაა ჰალუცინირებული ტექსტების იდენტიფიცირების საშუალებების დადგენა სრულიად ახალი NLP მოდელების წარმოდგენის საჭიროების გარეშე, რომლებიც აერთიანებენ, განსაზღვრავენ და ამოწმებენ ფაქტებს, როგორც დისკრეტულ ერთეულებს (გრძელვადიანი, ცალკე მიზანი მრავალ ფართო კომპიუტერში. კვლევითი სექტორები).
ჰალუცინირებული შინაარსის იდენტიფიცირება და გენერირება
ახალი თანამშრომლობა კარნეგი მელონის უნივერსიტეტსა და Facebook AI Research-ს შორის გვთავაზობს ახალ მიდგომას ჰალუცინაციების პრობლემისადმი, ჰალუცინირებული გამოსავლის იდენტიფიცირების მეთოდის ფორმულირებით და სინთეზური ჰალუცინირებული ტექსტების გამოყენებით მონაცემთა ნაკრების შესაქმნელად, რომელიც შეიძლება გამოყენებულ იქნას, როგორც საბაზისო საფუძველი მომავალი ფილტრებისა და მექანიზმებისთვის, რომლებიც შეიძლება საბოლოოდ გახდეს. NLP არქიტექტურის ძირითადი ნაწილი.

წყარო: https://arxiv.org/pdf/2011.02593.pdf
ზემოთ მოცემულ სურათზე, საწყისი მასალა დაყოფილია თითო სიტყვის მიხედვით, „0“ ეტიკეტი მინიჭებულია სწორ სიტყვებზე და „1“ ეტიკეტი მინიჭებული ჰალუცინაციურ სიტყვებზე. ქვემოთ ჩვენ ვხედავთ ჰალუცინირებული გამომავალი მაგალითს, რომელიც დაკავშირებულია შეყვანის ინფორმაციასთან, მაგრამ დამატებულია არაავთენტური მონაცემებით.
სისტემა იყენებს წინასწარ გაწვრთნილ დენოიზირების ავტოინკოდერს, რომელსაც შეუძლია ჰალუცინირებული სტრიქონი დააბრუნოს თავდაპირველ ტექსტზე, საიდანაც შეიქმნა დაზიანებული ვერსია (მსგავსი ჩემი ზემოთ მოყვანილი მაგალითების მსგავსად, სადაც ინტერნეტის ძიებამ გამოავლინა ყალბი ციტატების წარმოშობა, მაგრამ პროგრამული და ავტომატური სემანტიკური მეთოდოლოგია). კონკრეტულად ფეისბუქის ბარტ ავტოინკოდერის მოდელი გამოიყენება დაზიანებული წინადადებების შესაქმნელად.

ლეიბლის დავალება.
ჰალუცინაციის წყაროსთან დაბრუნების პროცესი, რაც არ არის შესაძლებელი მაღალი დონის NLP მოდელების ჩვეულ პერსპექტივაში, იძლევა „რედაქტირების მანძილის“ დახატვას და ხელს უწყობს ჰალუცინირებული შინაარსის იდენტიფიცირების ალგორითმულ მიდგომას.
მკვლევარებმა დაადგინეს, რომ სისტემას კარგად განზოგადებაც კი შეუძლია, როდესაც მას არ აქვს წვდომა საცნობარო მასალაზე, რომელიც ხელმისაწვდომი იყო ტრენინგის დროს, რაც ვარაუდობს, რომ კონცეპტუალური მოდელი არის სწორი და ფართოდ გამეორებადი.
გადაჭარბებული მორგების დაძლევა
იმისათვის, რომ თავიდან აიცილონ გადაჭარბება და მიაღწიონ ფართოდ განლაგებულ არქიტექტურას, მკვლევარებმა შემთხვევით ამოიღეს ტოკენები პროცესიდან და ასევე გამოიყენეს პერიფრაზირება და სხვა ხმაურის ფუნქციები.
მანქანური თარგმანი (MT) ასევე არის ამ ბუნდოვანი პროცესის ნაწილი, რადგან ტექსტის თარგმნა ენებზე, სავარაუდოდ, მტკიცედ შეინარჩუნებს მნიშვნელობას და შემდგომში თავიდან აიცილებს ზედმეტად მორგებას. ამიტომ ჰალუცინაციები ითარგმნა და იდენტიფიცირდა პროექტისთვის ორენოვანი მომხსენებლების მიერ სახელმძღვანელო ანოტაციის ფენაში.
ინიციატივამ მიაღწია ახალ საუკეთესო შედეგებს რიგი სტანდარტული სექტორის ტესტებში და პირველია, ვინც მიაღწია მისაღებ შედეგებს 10 მილიონ ტოკენზე მეტი მონაცემების გამოყენებით.
პროექტის კოდი, სახელწოდებით ჰალუცინირებული შინაარსის გამოვლენა პირობითი ნერვული მიმდევრობის გენერაციაში, უკვე გამოვიდა GitHub-ზედა საშუალებას აძლევს მომხმარებლებს შექმნან საკუთარი სინთეტიკური მონაცემები BART-ით ნებისმიერი ტექსტის კორპუსიდან. ასევე გათვალისწინებულია ჰალუცინაციების გამოვლენის მოდელების შემდგომი თაობა.















