
ხელოვნური ინტელექტი
GPT-ის სტილის ენის მოდელის შექმნა ერთი შეკითხვისთვის

მკვლევარებმა ჩინეთიდან შეიმუშავეს ეკონომიური მეთოდი GPT-3-ის სტილის ბუნებრივი ენის დამუშავების სისტემების შესაქმნელად, იმავდროულად, თავიდან აიცილონ დროისა და ფულის მზარდი ხარჯები, რომლებიც დაკავშირებულია მონაცემთა დიდი მოცულობის მომზადებაში - მზარდი ტენდენცია, რომელიც სხვაგვარად ემუქრება AI-ს ამ სექტორის საბოლოოდ დაქვეითებას. FAANG-ის მოთამაშეებს და მაღალი დონის ინვესტორებს.
შემოთავაზებული ჩარჩო ე.წ ამოცანებზე ორიენტირებული ენის მოდელირება (TLM). იმის ნაცვლად, რომ მოამზადოს უზარმაზარი და რთული მოდელი მილიარდობით სიტყვის უზარმაზარ კორპუსზე და ათასობით ეტიკეტსა და კლასზე, TLM ავარჯიშებს ბევრად უფრო მცირე მოდელს, რომელიც რეალურად აერთიანებს მოთხოვნას უშუალოდ მოდელის შიგნით.

მარცხენა, ტიპიური ჰიპერმასშტაბიანი მიდგომა მაღალი მოცულობის ენობრივი მოდელებისადმი; მართალია, TLM-ის თხელი მეთოდი, რათა გამოიკვლიოს დიდი ენობრივი კორპუსი თითო თემის ან კითხვის საფუძველზე. წყარო: https://arxiv.org/pdf/2111.04130.pdf
ფაქტობრივად, უნიკალური NLP ალგორითმი ან მოდელი იქმნება ერთ კითხვაზე პასუხის გასაცემად, იმის ნაცვლად, რომ შეიქმნას უზარმაზარი და მოუხერხებელი ზოგადი ენობრივი მოდელი, რომელსაც შეუძლია უპასუხოს კითხვებზე ფართო სპექტრს.
TLM ტესტირებისას მკვლევარებმა აღმოაჩინეს, რომ ახალი მიდგომა აღწევს შედეგებს, რომლებიც მსგავსია ან უკეთესია, ვიდრე წინასწარ მომზადებული ენის მოდელები, როგორიცაა რობერტა-დიდიდა ჰიპერმასშტაბიანი NLP სისტემები, როგორიცაა OpenAI-ს GPT-3, Google-ის TRILLION პარამეტრის გადამრთველი ტრანსფორმატორი მოდელი, კორეის ჰიპერკლოვერი, AI21 Labs' იურული 1და Microsoft-ის Megatron-Turing NLG 530B.
TLM-ის რვა კლასიფიკაციის მონაცემთა ნაკრების ცდებში ოთხ დომენზე, ავტორებმა დამატებით დაადგინეს, რომ სისტემა ამცირებს სასწავლო FLOP-ებს (მცურავი წერტილის ოპერაციები წამში) საჭიროა სიდიდის ორი რიგით. მკვლევარები იმედოვნებენ, რომ TLM-ს შეუძლია „დემოკრატიზებული“ სექტორი, რომელიც სულ უფრო ელიტური ხდება, NLP მოდელებით იმდენად დიდი, რომ მათი რეალურად დაინსტალირება შეუძლებელია ადგილობრივად და ამის ნაცვლად, GPT-3-ის შემთხვევაში, უკან იჯდება. ძვირი და OpenAI-ის შეზღუდული წვდომის API და, ახლა, Microsoft Azure.
ავტორები აცხადებენ, რომ ტრენინგის დროის შემცირება ორი რიგით მასშტაბით ამცირებს ტრენინგის ღირებულებას 1,000 GPU-ზე მეტი ერთი დღის განმავლობაში მხოლოდ 8 GPU-მდე 48 საათის განმავლობაში.
ახალი მოხსენება სახელდება NLP ნულიდან ფართომასშტაბიანი წინასწარი მომზადების გარეშე: მარტივი და ეფექტური ჩარჩო, და მოდის პეკინის ცინგხუას უნივერსიტეტის სამი მკვლევარისგან და ჩინეთში დაფუძნებული AI განვითარების კომპანიის Recurrent AI, Inc.
მიუწვდომელი პასუხები
ის დაჯდა ტრენინგის ეფექტური, ყველა დანიშნულების ენობრივი მოდელები სულ უფრო და უფრო ხასიათდება, როგორც პოტენციური „თერმული ლიმიტი“ იმის შესახებ, თუ რამდენად ეფექტური და ზუსტი NLP შეიძლება მართლაც გავრცელდეს კულტურაში.
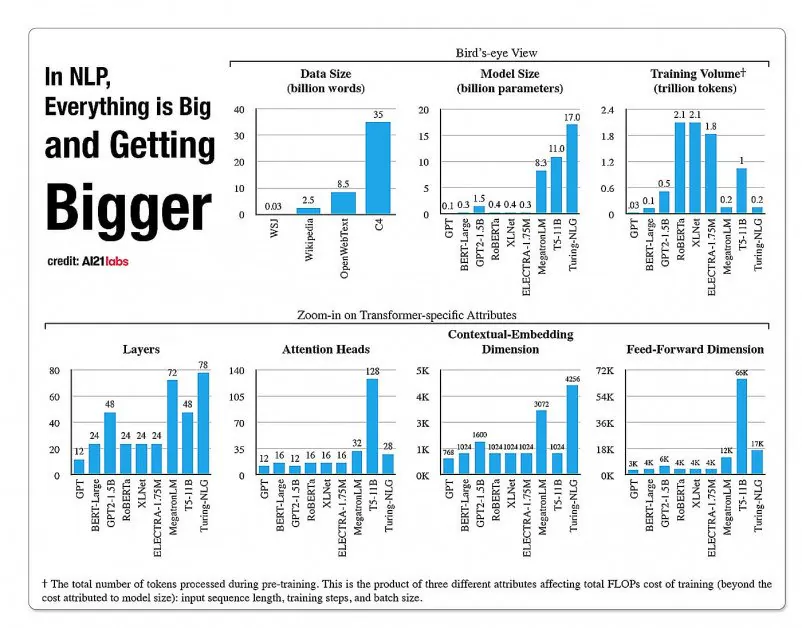
სტატისტიკა NLP მოდელის არქიტექტურაში ასპექტების ზრდის შესახებ, A2020 Labs-ის 121 წლის ანგარიშიდან. წყარო: https://arxiv.org/pdf/2004.08900.pdf
2019 წელს მკვლევარი გათვლილი რომ ტრენინგი ღირს $61,440 აშშ დოლარი XLNet მოდელი (იმ დროს მოხსენებული იყო BERT-ის დამარცხება NLP ამოცანებში) 2.5 დღის განმავლობაში 512 ბირთვზე 64 მოწყობილობაზე, ხოლო GPT-3 არის სავარაუდო 12 მილიონი დოლარი დაჯდა ტრენინგი - 200-ჯერ მეტი, ვიდრე მისი წინამორბედის, GPT-2-ის სწავლების ხარჯი (თუმცა ბოლოდროინდელი ხელახალი შეფასებები ამტკიცებს, რომ ის ახლა შეიძლება ივარჯიშოს. მხოლოდ $ 4,600,000 ყველაზე დაბალ ფასად ღრუბლოვან GPU-ებზე).
შეკითხვის საჭიროებებზე დაფუძნებული მონაცემთა ქვეჯგუფები
ამის ნაცვლად, ახალი შემოთავაზებული არქიტექტურა ცდილობს გამოიტანოს ზუსტი კლასიფიკაციები, ეტიკეტები და განზოგადება შეკითხვის, როგორც ერთგვარი ფილტრის გამოყენებით, რათა განისაზღვროს ინფორმაციის ქვეჯგუფი დიდი ენობრივი მონაცემთა ბაზიდან, რომელიც გაწვრთნილი იქნება, შეკითხვასთან ერთად, პასუხის გასაცემად. შეზღუდულ თემაზე.
ავტორები აცხადებენ:
“TLM მოტივირებულია ორი ძირითადი იდეით. პირველი, ადამიანები ეუფლებიან დავალებას მსოფლიო ცოდნის მხოლოდ მცირე ნაწილის გამოყენებით (მაგ., სტუდენტებს მხოლოდ რამდენიმე თავის გადახედვა სჭირდებათ, მსოფლიოს ყველა წიგნს შორის, გამოცდისთვის).
„ჩვენ ვარაუდობთ, რომ დიდ კორპუსში არის ბევრი ზედმეტი კონკრეტული ამოცანის შესასრულებლად. მეორეც, ტრეინინგი ზედამხედველობის ეტიკეტირებულ მონაცემებზე ბევრად უფრო ეფექტურია მონაცემების ქვემოთ მუშაობისთვის, ვიდრე ენის მოდელირების მიზნის ოპტიმიზაცია არალეიბლიან მონაცემებზე. ამ მოტივაციის საფუძველზე, TLM იყენებს ამოცანის მონაცემებს, როგორც მოთხოვნებს ზოგადი კორპუსის მცირე ქვეჯგუფის მოსაპოვებლად. ამას მოჰყვება ზედამხედველობის ქვეშ მყოფი ამოცანის მიზნისა და ენის მოდელირების მიზნის ერთობლივი ოპტიმიზაცია, როგორც მოძიებული, ასევე ამოცანის მონაცემების გამოყენებით.'
გარდა იმისა, რომ ძალიან ეფექტური NLP მოდელის ტრენინგი ხელმისაწვდომია, ავტორები ხედავენ უამრავ უპირატესობას ამოცანებზე ორიენტირებული NLP მოდელების გამოყენებისას. ერთის მხრივ, მკვლევარებს შეუძლიათ ისარგებლონ უფრო დიდი მოქნილობით, თანმიმდევრობის სიგრძის, ტოკენიზაციის, ჰიპერპარამეტრების რეგულირებისა და მონაცემთა წარმოდგენის მორგებული სტრატეგიებით.
მკვლევარები ასევე განჭვრეტენ ჰიბრიდული სამომავლო სისტემების განვითარებას, რომლებიც ცვლის PLM-ის შეზღუდულ წინასწარ მომზადებას (რაც სხვაგვარად არ არის მოსალოდნელი ამჟამინდელი დანერგვით) მეტი მრავალფეროვნებისა და განზოგადების წინააღმდეგ ტრენინგის დროს. ისინი სისტემას თვლიან წინ გადადგმულ ნაბიჯად დომენში ნულოვანი განზოგადების მეთოდების წინსვლისთვის.
ტესტირება და შედეგები
TLM ტესტირება ჩატარდა კლასიფიკაციის გამოწვევებზე რვა ამოცანაში ოთხ დომენში - ბიოსამედიცინო მეცნიერება, ახალი ამბები, მიმოხილვები და კომპიუტერული მეცნიერება. ამოცანები დაყოფილი იყო მაღალი რესურსების და დაბალი რესურსების კატეგორიებად. მაღალი რესურსის ამოცანები მოიცავდა 5,000-ზე მეტ ამოცანის მონაცემს, მაგ AGNews მდე RCT, სხვებს შორის; შედის დაბალი რესურსის ამოცანები ChemProt მდე ACL-ARC, ასევე ჰიპერპარტიზანი ახალი ამბების ამოცნობის მონაცემთა ნაკრები.
მკვლევარებმა შექმნეს ორი სასწავლო ნაკრები სახელწოდებით Corpus-BERT და Corpus-RoBERTa, ეს უკანასკნელი ათჯერ აღემატება პირველს. ექსპერიმენტებმა შეადარეს ზოგადი წინასწარ მომზადებული ენის მოდელები ბერტი (გუგლისგან) და რობერტა (ფეისბუქიდან) ახალ არქიტექტურამდე.
ნაშრომი აღნიშნავს, რომ მიუხედავად იმისა, რომ TLM არის ზოგადი მეთოდი და უნდა იყოს უფრო შეზღუდული მასშტაბითა და გამოყენებადობით, ვიდრე უფრო ფართო და მაღალი მოცულობის თანამედროვე მოდელები, მას შეუძლია შეასრულოს დომენის ადაპტირებადი დახვეწის დარეგულირების მეთოდები.

შედეგები TLM-ის შესრულების შედარებიდან BERT-სა და RoBERTa-ზე დაფუძნებულ კომპლექტებთან. შედეგებში ჩამოთვლილია საშუალო F1 ქულა სამ სხვადასხვა სავარჯიშო სკალაზე და ჩამოთვლილია პარამეტრების რაოდენობა, მთლიანი სავარჯიშო გამოთვლა (FLOPs) და სასწავლო კორპუსის ზომა.
ავტორები ასკვნიან, რომ TLM-ს შეუძლია მიაღწიოს შედეგებს, რომლებიც შესადარებელი ან უკეთესია, ვიდრე PLM-ები, საჭირო FLOP-ების მნიშვნელოვანი შემცირებით და მოითხოვს სასწავლო კორპუსის მხოლოდ 1/16-ს. საშუალო და დიდი მასშტაბებით, TLM-ს, როგორც ჩანს, შეუძლია გააუმჯობესოს შესრულება საშუალოდ 0.59 და 0.24 ქულით, ხოლო ტრენინგის მონაცემების ზომას ორი რიგით სიდიდის შემცირება.
”ეს შედეგები ადასტურებს, რომ TLM არის ძალიან ზუსტი და ბევრად უფრო ეფექტური, ვიდრე PLM. უფრო მეტიც, TLM იძენს უფრო მეტ უპირატესობას ეფექტურობაში უფრო ფართო მასშტაბით. ეს მიუთითებს იმაზე, რომ უფრო ფართომასშტაბიანი PLM-ები შესაძლოა გაწვრთნილი იყვნენ უფრო ზოგადი ცოდნის შესანახად, რომელიც არ არის სასარგებლო კონკრეტული ამოცანისთვის.'















