
Artificial Intelligence
ニューラル ルミグラフ レンダリングによるリアルタイム AI 人間への挑戦

現在、神経放射フィールドへの関心が高まっているにもかかわらず (ナーフ)、AI によって生成された 3D 環境とオブジェクトを作成できるテクノロジーですが、画像合成テクノロジーへのこの新しいアプローチは依然として多大なトレーニング時間を必要とし、リアルタイムで応答性の高いインターフェイスを可能にする実装が不足しています。
しかし、産業界と学術界の著名な著名人によるコラボレーションは、この課題に対する新たなアプローチを提供します (一般に Novel View Synthesis (NVS) として知られています)。
リサーチ 紙、資格あり ニューラル ルミグラフ レンダリングは、最先端技術の約 2 桁の改善を主張しており、機械学習パイプラインを介したリアルタイム CG レンダリングに向けたいくつかのステップを表しています。

Neural Lumigraph レンダリング (右) は、以前の方法に比べてブレンディング アーティファクトの解像度が向上し、オクルージョンの処理が改善されました。 ソース.
この論文のクレジットではスタンフォード大学とホログラフィック ディスプレイ技術会社 Raxium (現在は ステルスモード)、貢献者には主な機械学習が含まれます。 建築家 Googleというコンピュータで 科学者 アドビでは、 CTO at ストーリーファイル (作ったのは 見出し 最近ではウィリアム・シャトナーの AI バージョンを使用しました)。
最近のシャトナーの宣伝大作戦に関して、StoryFile は、個々の人々の特徴と物語に基づいて、AI が生成するインタラクティブなエンティティを作成するための新しいプロセスに NLR を採用しているようです。

StoryFile は、博物館の展示、オンラインのインタラクティブな物語、ホログラフィック ディスプレイ、拡張現実 (AR)、遺産の記録でこのテクノロジーを使用することを想定しています。また、採用面接や仮想デート アプリケーションでの NLR の新しい応用の可能性にも注目しているようです。

StoryFile によるオンライン ビデオからの提案された使用法。 出典: https://www.youtube.com/watch?v=2K9J6q5DqRc
新しいビュー合成インターフェイスとビデオのためのボリュームキャプチャ
ボリュームキャプチャの原理は、その主題に関して蓄積されているさまざまな論文にわたって、主題の静止画像またはビデオを撮影し、機械学習を使用して元の論文ではカバーされていない視点を「埋める」というアイデアです。カメラの配列。
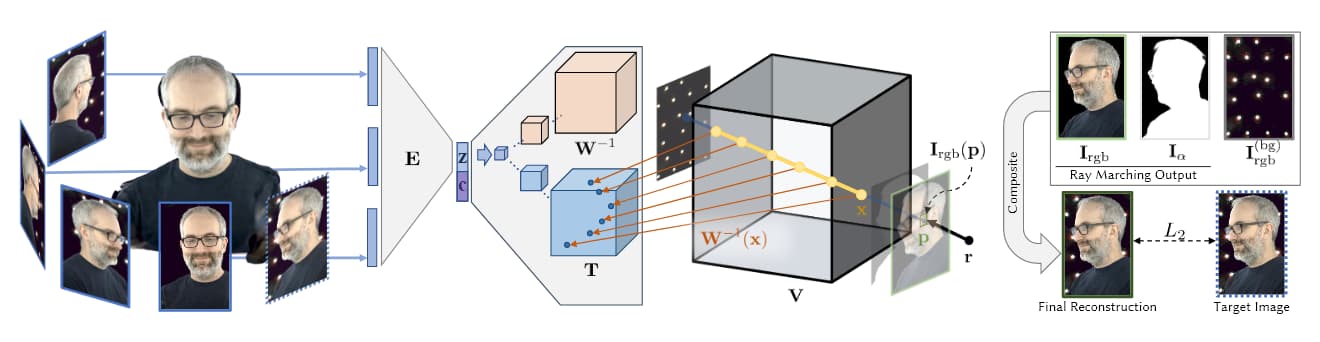
出典: https://research.fb.com/wp-content/uploads/2019/06/Neural- Volumes-Learning-Dynamic-Renderable- Volumes-from-Images.pdf
Facebook の AI 2019 AI 研究 (下記参照) から取得した上の画像では、ボリューム キャプチャの XNUMX つの段階がわかります。複数のカメラが画像/映像を取得します。 エンコーダ/デコーダ アーキテクチャ (または他のアーキテクチャ) は、ビューの相対性を計算して連結します。 レイマーチング アルゴリズムは、 ボクセル 体積空間内の各点の(または他の XYZ 空間幾何学単位)。 そして(最新の論文では)リアルタイムで操作できる完全なエンティティを合成するためにトレーニングが行われます。
この多くの場合、大規模でデータ量の多いトレーニング フェーズが、これまで新規ビューの合成をリアルタイムまたは高応答キャプチャの領域から遠ざけてきた原因です。
Novel View Synthesis が体積空間の完全な 3D マップを作成するという事実は、これらの点を従来のコンピューター生成メッシュにつなぎ合わせて、CGI 人間 (またはその他の比較的境界のあるオブジェクト) を効果的にキャプチャして表現することが比較的簡単であることを意味します。はえ。
NeRF を使用するアプローチは、点群と深度マップに依存して、キャプチャ デバイスのまばらな視点間の補間を生成します。

NeRF は、CG メッシュの生成ではなく、深度マップの計算を通じて体積深度を生成できます。 出典: https://www.youtube.com/watch?v=JuH79E8rdKc
NeRFですが、 できる メッシュの計算では、ほとんどの実装ではボリューム シーンの生成にこれを使用しません。
対照的に、暗黙的な微分可能レンダラー (IDR) アプローチ、 公表 ワイツマン科学研究所による 2020 年 3 月の研究は、キャプチャ アレイから自動的に生成された XNUMXD メッシュ情報の活用にかかっています。

インタラクティブな CGI メッシュに変換された IDR キャプチャの例。 出典: https://www.youtube.com/watch?v=C55y7RhJ1fE
NeRF には IDR の形状推定機能がありませんが、IDR は NeRF の画質に匹敵することができず、どちらもトレーニングと照合に多大なリソースを必要とします (ただし、NeRF の最近の技術革新は、 初め 〜へ これに対処する).

NLR のカスタム カメラ リグは、16 台の GoPro HERO7 カメラと 6 台の中央 Back-Bone H7PRO カメラを備えています。 「リアルタイム」レンダリングの場合、これらは最低 60fps で動作します。 出典:https://arxiv.org/pdf/2103.11571.pdf
代わりに、Neural Lumigraph レンダリングは サイレン (Sinusoidal Representation Networks) を使用して、各アプローチの長所を独自のフレームワークに組み込みます。これは、既存のリアルタイム グラフィックス パイプラインで直接使用できる出力を生成することを目的としています。
SIRENが活用されているのは、 同様の実装 過去 XNUMX 年間、そして現在は 一般的な API 呼び出し 画像合成コミュニティの愛好家 Colab 向け。 しかし、NLR のイノベーションは、SIREN を XNUMX 次元の多視点画像監視に適用することです。これには、SIREN が一般化された出力ではなく過剰適合した出力を生成する程度のため問題があります。
CG メッシュが配列イメージから抽出された後、メッシュは OpenGL を介してラスタライズされ、メッシュの頂点位置が適切なピクセルにマップされ、その後、さまざまな寄与マップのブレンドが計算されます。
結果として得られるメッシュは、NeRF よりも一般化され、代表的であり (以下の画像を参照)、必要な計算が少なく、メリットが得られない領域 (滑らかな顔の皮膚など) に過剰な詳細が適用されません。

出典:https://arxiv.org/pdf/2103.11571.pdf
マイナス面としては、NLR にはダイナミック ライティングや、 再点灯、出力はキャプチャ時に取得されたシャドウ マップおよびその他のライティングの考慮事項に制限されます。 研究者らは将来の研究でこの問題に対処する予定です。
さらに、この論文は、NLR によって生成された形状が、次のような代替アプローチほど正確ではないことを認めています。 非構造化マルチビュー ステレオのピクセル単位のビュー選択、または前述のワイツマン研究所の研究。
体積画像合成の台頭
ニューラル ネットワークを使用して限られた一連の写真から 3D エンティティを作成するというアイデアは NeRF よりも古く、先見の明のある論文は 2007 年かそれ以前に遡ります。 2019年にFacebookのAI研究部門は、独創的な研究論文を発表した。 ニューラル ボリューム: 画像から動的にレンダリング可能なボリュームを学習するこれにより、機械学習ベースのボリューム キャプチャによって生成された合成人間の応答性の高いインターフェイスが初めて有効になりました。

Facebook の 2019 年の研究により、体積測定を行う人向けの応答性の高いユーザー インターフェイスの作成が可能になりました。 出典: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/











