
Artificial Intelligence
セルフアテンション ガイダンス: 拡散モデルのサンプル品質の向上

ノイズ除去拡散モデルは、反復的なノイズ除去プロセスを通じてノイズから画像を合成する生成 AI フレームワークです。これらは、その卓越した画像生成機能と多様性で高く評価されており、これは主に、分類子ガイダンスや分類子なしガイダンスなどのテキストまたはクラス条件付きガイダンス方法に起因します。これらのモデルは、多様で高品質な画像の作成に特に成功しています。最近の研究では、クラスのキャプションやラベルなどのガイダンス技術が、これらのモデルが生成する画像の品質を向上させる上で重要な役割を果たしていることが示されています。
ただし、拡散モデルと誘導方法は、特定の外部条件の下では制限に直面します。ラベルドロップを使用する分類子なしガイダンス (CFG) メソッドでは、トレーニング プロセスがさらに複雑になりますが、分類子ガイダンス (CG) メソッドでは追加の分類子のトレーニングが必要です。どちらの方法も、苦労して獲得した外部条件に依存するため、ある程度の制約があり、その可能性が制限され、条件付きの設定に限定されます。
これらの制限に対処するために、開発者は、セルフ アテンション ガイダンス (SAG) として知られる、拡散ガイダンスに対するより一般的なアプローチを策定しました。この方法では、拡散モデルの中間サンプルからの情報を利用して画像を生成します。この記事では SAG について詳しく説明し、その仕組み、方法論、結果を現在の最先端のフレームワークやパイプラインと比較して説明します。
セルフアテンション ガイダンス : 拡散モデルのサンプル品質の向上
ノイズ除去拡散モデル (DDM) は、反復的なノイズ除去プロセスによってノイズから画像を作成できる機能で人気を集めています。これらのモデルの画像合成能力は主に、採用されている拡散誘導方法によるものです。普及モデルとガイダンスベースの手法は、その長所にもかかわらず、複雑さの増加や計算コストの増加などの課題に直面しています。
現在の制限を克服するために、開発者は、拡散ガイダンスからの外部情報に依存しない拡散ガイダンスのより一般的な定式化であるセルフアテンション ガイダンス手法を導入しました。これにより、ガイドに対する条件のない柔軟なアプローチが容易になります。 拡散フレームワーク。セルフ・アテンション・ガイダンスによって選択されたアプローチは、最終的には、外部要件の有無にかかわらず、従来の拡散ガイダンス手法の適用性を高めるのに役立ちます。
セルフ・アテンション・ガイダンスは、一般化された定式化という単純な原理に基づいており、中間サンプルに含まれる内部情報もガイダンスとして機能するという想定に基づいています。この原則に基づいて、SAG メソッドではまず、サンプル品質を向上させるためのシンプルで直接的なソリューションであるブラー ガイダンスを導入します。ブラー ガイダンスは、ガウスぼかしの良性の特性を利用して、ガウスぼかしの結果として削除された情報を使用して中間サンプルをガイドすることで、細かいスケールの詳細を自然に除去することを目的としています。 Blur ガイダンス法は中程度のガイダンス スケールでサンプルの品質を向上させますが、領域全体に構造的曖昧さが生じることが多いため、大きなガイダンス スケールでは結果を再現できません。その結果、ブラー ガイダンス方法では、元の入力を劣化した入力の予測と一致させることが困難になります。より大きなガイダンス スケールでブラー ガイダンス手法の安定性と有効性を強化するために、最新の拡散モデルにはすでにセルフ アテンション メカニズムがアーキテクチャ内に含まれているため、セルフ アテンション ガイダンスは拡散モデルのセルフ アテンション メカニズムを活用しようとします。
重要な情報を本質的に捉えるには自己注意が不可欠であるという前提のもと、自己注意ガイダンス手法では、拡散モデルの自己注意マップを使用して、顕著な情報を含む領域を敵対的にぼかし、その過程で、 拡散モデル 必要な残存情報が含まれています。この方法では、拡散モデルの逆プロセス中にアテンション マップを利用して画像の品質を向上させ、追加のトレーニングや外部情報を必要とせずにセルフコンディショニングを使用してアーティファクトを低減します。

要約すると、セルフ・アテンション・ガイダンスの方法
- 拡散フレームワークの内部セルフ アテンション マップを使用して、追加のトレーニングを必要としたり外部条件に依存したりすることなく、生成されたサンプル画像の品質を向上させる新しいアプローチです。
- SAG 手法は、条件付きガイダンス手法を、追加のリソースや外部条件を必要とせずにあらゆる拡散モデルと統合できる条件なし手法に一般化することを試み、これによりガイダンスベースのフレームワークの適用可能性を高めます。
- また、SAG メソッドは、既存の条件付きメソッドやフレームワークと直交する機能を実証しようとしています。これにより、他のメソッドやモデルとの柔軟な統合が容易になり、パフォーマンスの向上が促進されます。
さらに、セルフ アテンション ガイダンス メソッドは、ノイズ除去拡散モデル、サンプリング ガイダンス、生成 AI セルフ アテンション メソッド、拡散モデルの内部表現などの関連フレームワークの結果から学習します。ただし、本質的には、セルフ アテンション ガイダンス メソッドは、DDPM またはノイズ除去拡散確率モデル、分類子ガイダンス、分類子なしガイダンス、および拡散フレームワークのセルフ アテンションからの学習を実装します。次のセクションで詳しく説明します。
自己注意ガイダンス : 準備、方法論、アーキテクチャ
ノイズ除去拡散確率モデルまたは DDPM
DDPMまたは ノイズ除去拡散確率モデル は、反復ノイズ除去プロセスを使用してホワイト ノイズから画像を回復するモデルです。従来、DDPM モデルはタイム ステップで入力イメージと分散スケジュールを受け取り、マルコフ プロセスとして知られる順方向プロセスを使用してイメージを取得します。
GAN 実装による分類子および分類子なしのガイダンス
GAN (Generative Adversarial Networks) は忠実度を高めるための独自の取引多様性を備えており、GAN フレームワークのこの機能を拡散モデルにもたらすために、Self-Attendance Guide フレームワークは、追加の分類子を使用する分類子ガイダンス手法を使用することを提案しています。逆に、追加の分類子を使用せずに分類子を使用しないガイダンス方法を実装して、同じ結果を達成することもできます。このメソッドは望ましい結果を提供しますが、追加のラベルが必要であり、フレームワークがテキストやクラスなどの追加の条件と追加のトレーニングの詳細を必要とする条件付き拡散モデルに限定されているため、まだ計算的に実行可能ではありません。モデル。
普及指導の一般化
分類子および分類子を使用しないガイダンス手法は、望ましい結果を提供し、拡散モデルでの条件付き生成に役立ちますが、追加の入力に依存します。任意のタイムステップに対して、拡散モデルの入力は一般化された条件と、一般化された条件を持たない摂動サンプルで構成されます。さらに、一般化された状態には、摂動されたサンプル内の内部情報、外部状態、あるいはその両方が含まれます。結果として得られるガイダンスは、一般化された状態を予測できるという仮定の下、仮想回帰変数を利用して定式化されます。
セルフ アテンション マップを使用した画質の向上
一般化拡散ガイダンスは、摂動されたサンプルに含まれる一般化された条件で顕著な情報を抽出することによって、拡散モデルの逆のプロセスへのガイダンスを提供することが可能であることを意味します。これに基づいて、セルフ アテンション ガイダンス手法は、事前トレーニングされた拡散モデルの分布外の問題の結果として生じるリスクを制限しながら、逆プロセスの顕著な情報を効果的に取得します。
ブラーガイダンス
セルフ アテンション ガイダンスのブラー ガイダンスは、ガウス ブラー (入力信号をガウス フィルターで畳み込んで出力を生成する線形フィルター手法) に基づいています。標準偏差が増加すると、ガウスぼかしは入力信号内の細かいスケールの詳細を低減し、入力信号を定数に向かって平滑化することによって局所的に区別がつかなくなる結果になります。さらに、実験では、入力信号とガウスぼかし出力信号の間の情報の不均衡が示されており、出力信号にはより細かいスケールの情報が含まれています。
この学習に基づいて、セルフ アテンション ガイダンス フレームワークは、拡散プロセス中の中間再構成から情報を意図的に除外する技術であるブラー ガイダンスを導入し、代わりにこの情報を使用して、画像と画像の関連性を高める方向に予測を導きます。情報を入力します。ぼかしガイダンスは本質的に、元の予測をぼかした入力予測からさらに逸脱させます。さらに、ガウスぼかしの良性の特性により、出力信号が元の信号から大きく逸脱することがなくなり、適度な偏差が発生します。簡単に言うと、画像には自然にぼかしが発生するため、ガウスぼかしは、事前にトレーニングされた拡散モデルに適用するのにより適した方法となります。
Self-Attendance Guide パイプラインでは、入力信号は最初にガウス フィルターを使用してぼかされ、次に追加のノイズで拡散されて出力信号が生成されます。これにより、SAG パイプラインは、ガウス ノイズを低減する結果として生じるブラーの副作用を軽減し、ガイダンスがランダム ノイズに依存するのではなくコンテンツに依存するようにします。ブラー ガイダンスは、中程度のガイダンス スケールのフレームワークでは満足のいく結果をもたらしますが、次の図に示すように、ノイズの多い結果が生成される傾向があるため、大きなガイダンス スケールの既存のモデルでは結果を再現できません。

これらの結果は、グローバル ブラーによってフレームワークに導入された構造的曖昧さの結果である可能性があります。これにより、SAG パイプラインが元の入力の予測を劣化した入力と一致させることが困難になり、ノイズの多い出力が発生します。
自己注意のメカニズム
前述したように、拡散モデルには通常、セルフ アテンション コンポーネントが組み込まれており、これは拡散モデル フレームワークで最も重要なコンポーネントの 1 つです。セルフ アテンション メカニズムは拡散モデルの中核に実装されており、次の画像の上段に高周波マスクが示されているように、モデルが生成プロセス中に入力の顕著な部分に注意を払うことができるようになります。最終的に生成された画像の一番下の行にはセルフ アテンション マスクが表示されます。

提案されたセルフ アテンション ガイダンス方法は、同じ原理に基づいて構築されており、拡散モデルのセルフ アテンション マップの機能を活用しています。全体として、セルフ アテンション ガイダンス手法は、入力信号内のセルフ アテンション パッチをぼかします。つまり、簡単に言えば、拡散モデルが注目するパッチの情報を隠します。さらに、セルフ アテンション ガイダンスの出力信号には、入力信号のそのままの領域が含まれているため、入力の構造的な曖昧さが生じず、全体的なぼやけの問題が解決されます。次に、パイプラインは、GAP またはグローバル平均プーリングを実行してセルフ アテンション マップを次元に集約し、最近傍をアップサンプリングして入力信号の解像度に一致させることにより、集約されたセルフ アテンション マップを取得します。
自注意指導:実験と結果
パフォーマンスを評価するために、セルフ アテンション ガイダンス パイプラインは 8 個の Nvidia GeForce RTX 3090 GPU を使用してサンプリングされ、事前トレーニングされた IDDPM、ADM、および 安定した普及の枠組み.
セルフアテンションガイダンスによる無条件生成
無条件モデルでの SAG パイプラインの有効性を測定し、分類子ガイダンスと分類子フリー ガイダンス アプローチには備わっていない条件なしの特性を実証するために、SAG パイプラインは 50 サンプルの無条件で事前トレーニングされたフレームワークで実行されます。

ご覧のとおり、SAG パイプラインの実装により、無条件入力の FID、sFID、および IS メトリクスが向上し、同時に再現率が低下します。さらに、SAG パイプラインの実装の結果としての質的向上は、次の画像で明らかです。上部の画像は ADM および安定拡散フレームワークの結果であり、下部の画像は ADM および安定拡散フレームワークの結果です。 SAG パイプライン。


SAG による条件付き生成
既存のフレームワークに SAG パイプラインを統合すると、無条件生成で優れた結果が得られます。また、SAG パイプラインは条件非依存性があり、条件付き生成にも SAG パイプラインを実装できます。
セルフアテンションガイダンスによる安定普及
元の Stable Diffusion フレームワークは高品質の画像を生成しますが、Stable Diffusion フレームワークと Self-Attendance Guide パイプラインを統合すると、結果が大幅に向上します。その効果を評価するために、開発者は、画像ペアごとにランダム シードを使用して安定拡散の空のプロンプトを使用し、自己注意ガイダンスの有無にかかわらず、500 組の画像に対して人間による評価を使用します。結果を次の図に示します。

さらに、SAG の実装により、分類子フリー ガイダンスとセルフ アテンション ガイダンスを融合することで安定拡散モデルの範囲をテキストから画像への合成まで広げることができるため、安定拡散フレームワークの機能を強化できます。さらに、セルフ アテンション ガイダンスを使用した安定拡散モデルから生成された画像は、次の画像に示すように、SAG パイプラインの自己調整効果のおかげで、アーティファクトが少なく高品質です。

現在の制限
セルフ アテンション ガイダンス パイプラインを実装すると、生成される画像の品質が大幅に向上しますが、いくつかの制限があります。
主な制限の 1 つは、分類子ガイドと分類子なしガイダンスの直交性です。次の画像でわかるように、SAG の実装により FID スコアと予測スコアが向上しています。これは、SAG パイプラインに従来のガイダンス方法と同時に使用できる直交コンポーネントが含まれていることを意味します。

ただし、拡散モデルを特定の方法でトレーニングする必要があるため、計算コストだけでなく複雑さも増加します。
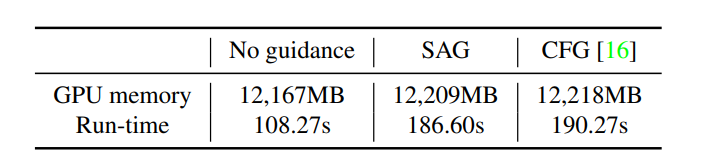
さらに、セルフ アテンション ガイダンスの実装によってメモリや時間の消費が増加することはありません。これは、SAG でのマスキングやぼかしなどの操作から生じるオーバーヘッドが無視できることを示しています。ただし、ガイダンスなしのアプローチと比較すると追加のステップが含まれるため、依然として計算コストが増加します。
最終的な考え
この記事では、自己注意ガイダンスについて説明しました。これは、高品質の画像を生成するために拡散モデル内で利用可能な内部情報を利用する、新規かつ一般的なガイダンス方法の定式化です。セルフ・アテンション・ガイダンスは、一般化された定式化という単純な原理に基づいており、中間サンプルに含まれる内部情報もガイダンスとして機能するという想定に基づいています。セルフ アテンション ガイダンス パイプラインは、条件やトレーニングを必要としないアプローチであり、さまざまな拡散モデルにわたって実装でき、セルフ コンディショニングを使用して生成された画像内のアーティファクトを軽減し、全体の品質を向上させます。















