
Artificial Intelligence
機械学習とディープラーニング – 主な違い
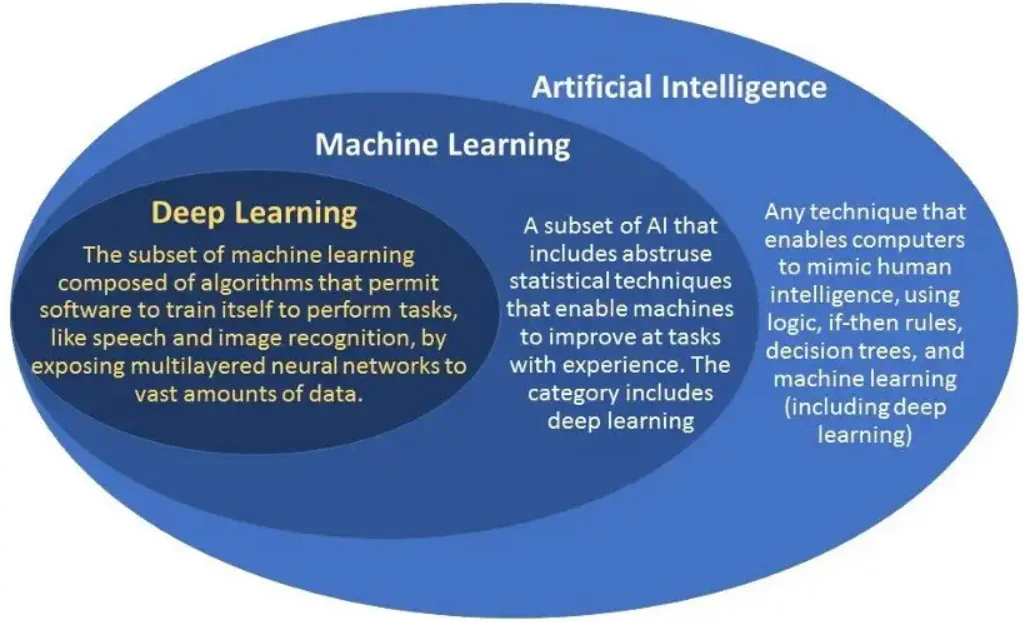
最近では、人工知能 (AI)、機械学習 (ML)、深層学習などの用語が誇大広告になっています。ただし、人々はこれらの用語を同じ意味で使用することがよくあります。これらの用語は相互に高度に相関していますが、独特の特徴と特定の使用例もあります。
AI は、人間の認知能力を模倣して問題を解決し、意思決定を行う自動化されたマシンを扱います。 機械学習と深層学習は AI のサブドメインです。 機械学習は、人間の介入を最小限に抑えて予測を行うことができる AI です。 一方、ディープ ラーニングは、ニューラル ネットワークを使用して人間の心の神経および認知プロセスを模倣して意思決定を行う機械学習のサブセットです。
上の図は階層を示しています。 引き続き、機械学習とディープラーニングの違いについて解説していきます。 また、アプリケーションと重点分野に基づいて適切な方法論を選択するのにも役立ちます。 これについて詳しく説明しましょう。
機械学習の概要
機械学習を使用すると、専門家は大規模なデータセットを分析させることで機械を「トレーニング」できます。 マシンが分析するデータが増えるほど、目に見えないイベントやシナリオに対する意思決定や予測を行って、より正確な結果を生み出すことができます。
機械学習モデルには、正確な予測と意思決定を行うために構造化データが必要です。 データがラベル付けされて整理されていない場合、機械学習モデルはデータを正確に理解できず、ディープラーニングの領域になります。
組織内で膨大な量のデータが利用できるようになったことで、機械学習が意思決定に不可欠な要素となっています。 レコメンデーション エンジンは、機械学習モデルの好例です。 Netflix などの OTT サービスは、ユーザーのコンテンツの好みを学習し、検索習慣や視聴履歴に基づいて類似のコンテンツを提案します。
理解する 機械学習モデルがどのようにトレーニングされるか, まずはMLの種類を見てみましょう。
機械学習には XNUMX 種類の方法論があります。
- 教師あり学習 – 正確な結果を得るには、ラベル付きデータが必要です。 多くの場合、結果を改善するには、より多くのデータを学習し、定期的に調整する必要があります。
- 半教師あり – 教師あり学習と教師なし学習の中間層であり、両方のドメインの機能を示します。部分的にラベル付けされたデータで結果を得ることができ、正確な結果を得るために継続的な調整を必要としません。
- 教師なし学習 – 人間の介入なしにデータセット内のパターンと洞察を発見し、正確な結果を提供します。 クラスタリングは、教師なし学習の最も一般的なアプリケーションです。
- 強化学習 – 強化学習モデルでは、新しい情報が得られると正確な結果が得られるため、継続的なフィードバックまたは強化が必要です。 また、望ましい結果に報酬を与え、間違った結果にペナルティを与えることで自己学習を可能にする「報酬機能」も使用します。
ディープラーニングの概要
機械学習モデルの精度を向上させるには人間の介入が必要です。 それどころか、深層学習モデルは、人間の監視なしで結果が得られるたびに自ら改善します。 ただし、多くの場合、より詳細で長い量のデータが必要になります。
ディープ ラーニング手法は、人間の心にヒントを得たニューラル ネットワークに基づいて洗練された学習モデルを設計します。 これらのモデルには、ニューロンと呼ばれるアルゴリズムの複数の層があります。 実践、再訪、そして時間とともに改善し進化し続ける認知的精神と同じように、それらは人間の介入なしで改善し続けます。
深層学習モデルは主に分類と特徴抽出に使用されます。 たとえば、ディープ モデルは顔認識のデータセットをフィードします。 モデルは多次元マトリックスを作成して、顔の各特徴をピクセルとして記憶します。 公開されていない人物の写真を認識するよう依頼すると、限られた顔の特徴を照合することで簡単に認識します。
- 畳み込みニューラル ネットワーク (CNN) – 畳み込みは、画像のさまざまなオブジェクトに重みを割り当てるプロセスです。 これらの割り当てられた重みに基づいて、CNN モデルはそれを認識します。 結果は、これらの重みが列車セットとして供給されるオブジェクトの重さにどれだけ近いかに基づいています。
- リカレント ニューラル ネットワーク (RNN) – CNN とは異なり、RNN モデルは以前の結果とデータ ポイントを再検討して、より正確な意思決定と予測を行います。これは人間の認知機能を実際に再現したものです。
- Generative Adversarial Networks (GAN) – GAN の XNUMX つの分類子、ジェネレーターとディスクリミネーターは同じデータにアクセスします。 ジェネレーターは、ディスクリミネーターからのフィードバックを組み込んで偽のデータを生成します。 ディスクリミネーターは、指定されたデータが本物か偽物かを分類しようとします。
顕著な違い
以下にいくつかの顕著な違いを示します。
| 違い | 機械学習 | 深層学習 |
| 人間による監督 | 機械学習にはより多くの監視が必要です。 | ディープラーニングモデルは、開発後に人間による監督をほとんど必要としません。 |
| ハードウェアリソース | 強力な CPU 上で機械学習プログラムを構築して実行します。 | ディープ ラーニング モデルには、専用 GPU などのより強力なハードウェアが必要です。 |
| 時間と労力 | 機械学習モデルのセットアップに必要な時間はディープ ラーニングよりも短くなりますが、その機能は制限されています。 | ディープラーニングを使用してデータを開発およびトレーニングするには、より多くの時間が必要です。 一度作成されると、時間の経過とともに精度が向上し続けます。 |
| データ (構造化/非構造化) | 機械学習モデルは結果を得るために構造化データを必要とし (教師なし学習を除く)、改善のためには継続的な人間の介入が必要です。 | 深層学習モデルは、精度を損なうことなく、構造化されていない複雑なデータセットを処理できます。 |
| ユースケース | レコメンデーション エンジンを使用する e コマース Web サイトおよびストリーミング サービス。 | 飛行機のオートパイロット、自動運転車、火星表面の探査機、顔認識などのハイエンド アプリケーション。 |
機械学習とディープラーニング – どちらが最適ですか?
機械学習とディープラーニングのどちらを選択するかは、まさにそのユースケースに基づいています。 どちらも人間に近い知能を備えた機械を作るために使用されます。 両方のモデルの精度は、関連する KPI とデータ属性を使用しているかどうかによって異なります。
機械学習と深層学習は、あらゆる業界で日常的なビジネス コンポーネントになるでしょう。 近い将来、AI によって航空、戦争、自動車などの産業活動が完全に自動化されることは間違いありません。
AI と、AI がどのようにビジネスの成果を継続的に変革するかについて詳しく知りたい場合は、次の記事を参照してください。 ユナイトアイ.















