人工知能
アンドリュー・エンが機械学習における過剰適合の文化を批判
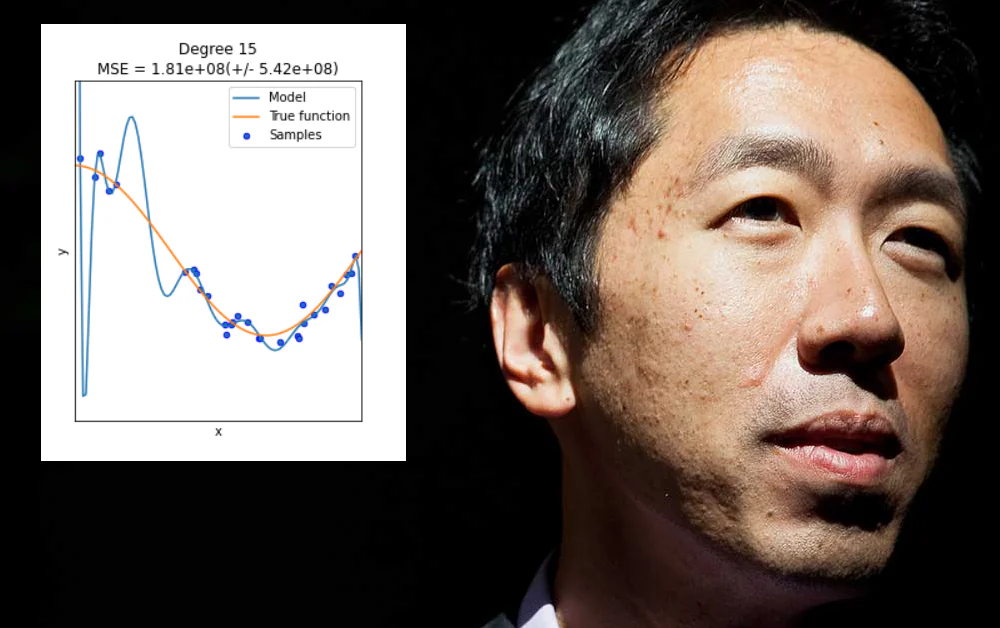
アンドリュー・エンは、過去10年間で最も影響力のある機械学習の声の一人であり、現在、モデルアーキテクチャーの革新よりもデーターに重点を置く業界のあり方について懸念を表明している。特に、過剰適合した結果が一般化された解決策や進歩として描かれることを許す業界の文化について批判的である。
これは、機械学習の文化に対する包括的な批判であり、最高の権威の一人から発せられたものであり、AI開発におけるビジネス信頼の3回目の崩壊への懸念がある業界への信頼に影響を及ぼす。
スタンフォード大学の教授であり、deeplearning.aiの創設者の一人であるエンは、3月に組織のサイトにメッセージを公開し、最近のスピーチを2つの核心的な勧告に凝縮した。
第一に、研究コミュニティーは、データクリーニングが機械学習の課題の80%を占めることを嘆くのをやめ、頑健なMLOpsメソッドと実践の開発に取り組むべきである。
第二に、機械学習モデルをデーターに過剰適合させて、モデルではうまく機能するが、一般化したり、広く展開可能なモデルを生成することができないようにする「簡単な勝利」から離れるべきである。
データアーキテクチャーとキュレーションの挑戦を受け入れる
エンは次のように書いている。
「私の見解は、データ準備が私たちの仕事の80%を占めるのであれば、データの品質を確保することが機械学習チームの重要な仕事である」と。
彼は続けた。
「エンジニアが偶然にデータセットを改善する方法を見つけるのを待つよりも、AIシステムを構築すること、包括して高品質のデータセットを構築することをより反復可能で体系的なものにするためのMLOpsツールを開発できることを希望する。」
「MLOpsは新しい分野であり、異なる人々がそれを異なる方法で定義している。しかし、MLOpsチームとツールの最も重要な原則は、プロジェクトのすべての段階で一貫して高品質のデータの流れを確保することである。そうすることで、多くのプロジェクトがよりスムーズに進むことになる。」
4月末に、ZoomでライブストリーミングされたQ&Aセッションで、エンは放射線学における機械学習分析システムの適用不足について話した。
「スタンフォード病院からデータを収集し、同じ病院でトレーニングとテストを行うと、実際に人間の放射線技師と同等の特定の状態を検出する能力を示す論文を発表できる。」
「…同じモデル、同じAIシステムを、街の中にある古い病院に持って行き、古い機械を使い、技術者が少し異なる画像化プロトコルを使うと、データのドリフトが起こってAIシステムの性能が大幅に低下する。対照的に、人間の放射線技師は、街の中にある古い病院に歩いて行って、問題なく仕事ができる。」
下位仕様は解決策ではない
過剰適合は、機械学習モデルが特定のデータセット(またはデータの形式)の特異性に合わせて設計されたときに発生する。これには、たとえば、特定のデータセットから良い結果を生み出す重みを指定することが含まれるが、他のデータセットでは「一般化」されない。
多くの場合、パラメータは、トレーニングセットの「非データ」側面、たとえば収集された情報の特定の解像度やその他の特異性に基づいて定義されるが、これらは他の後のデータセットで再発生することが保証されていない。
過剰適合は、データアーキテクチャーまたはモデル設計の範囲や柔軟性を盲目的に広げることで解決できる問題ではない。実際に必要なのは、幅広いデータ環境でうまく機能する、広く適用可能で、高い関連性のある特徴であるが、これはより困難な課題である。
一般に、この種の「下位仕様」は、エンが最近説明したのと同じ問題につながる。つまり、機械学習モデルが見られないデータで失敗する。ただし、この場合は、モデルが過剰適合されたオリジナルのトレーニングセットとは異なるデータまたはデータ形式であるということではなく、モデルが柔軟すぎるということである。
2020年末に、論文 Underspecification Presents Challenges for Credibility in Modern Machine Learning が、この実践に対して強い批判を加え、GoogleやMITを含む機関の40人以上の機械学習研究者や科学者の名前が記載されていた。
この論文は「ショートカット学習」を批判し、未仕様のモデルがトレーニングを開始するランダムなシードポイントに基づいて、狂った方向に飛び出す方法を観察する。寄稿者は次のように述べている。
「私たちは、実用的機械学習パイプライン全体で未仕様が普遍的であることを発見した。実際、未仕様のおかげで、決定の重要な側面は、パラメータ初期化に使用されるランダムなシードなどの任意の選択によって決定される。」
文化の変化の経済的影響
学術的な資格を持つエンは、空気の読めない学者ではなく、Google BrainやCourseraの共同創設者、BaiduのビッグデーターとAIの元チーフサイエンティスト、Landing AIの創設者 として、深い業界の経験を持っている。Landing AIは、セクターの新しいスタートアップに1億7500万ドルを管理している。
「AI全体、ヘルスケアに限らず、Proof-of-Concept-to-Productionギャップがある」という彼の言葉は、現在の水準のハイプと点在した歴史により、ますます不確実な長期的なビジネス投資として特徴付けられるセクターに警鐘を鳴らす意図である。
しかし、特定の環境でうまく機能するが、他の環境では失敗する、独自の機械学習システムは、業界への投資が報われるような市場を表す。過剰適合問題を職業上の危険性として提示することは、オープンソース研究への企業投資を商品化する方法であり、競合他社が複製することは可能だが問題があるような、実質的に独自のシステムを生成する方法である。
このアプローチが長期的には機能するかどうかは、機械学習の実際のブレークスルーが、ますます大きな投資を必要とするかどうかに依存し、すべての生産的なイニシアチブが、ホスティングと運用に必要な巨大なリソースのため、ある程度FAANGに移行するかどうかに依存する。












