
Artificial Intelligence
AI によって生成された言語が科学文献を汚染し始めている

フランスとロシアの研究者らは、GPT-3などのAI主導の確率的テキスト生成ツールの使用が、「拷問言語」、存在しない文献の引用、場当たり的でクレジットのない画像の再利用を、以前は立派だったチャンネルに導入していることを示す研究を発表した。新しい科学文献の出版。
おそらく最も懸念されるのは、調査対象の論文には、客観的かつ体系的な研究の成果として提示された科学的に不正確または再現不可能な内容も含まれていることです。これは、生成言語モデルが論文著者の限られた英語スキルを強化するためだけでなく、しかし、実際にはそれに伴う大変な仕事をするためです(そして、いつもそれはひどい仕事です)。
レポート、題し 拷問されたフレーズ: 科学界に出現した疑わしい文体は、トゥールーズ大学コンピューターサイエンス学部の研究者と、現在テルアビブ大学に在籍するヤンデックス研究者アレクサンダー・マガジノフ氏によってまとめられた。
この研究は、エルゼビア・ジャーナルにおける、AIによって生成された無意味な科学出版物の成長に特に焦点を当てています。 マイクロプロセッサとマイクロシステム.
他の名前で
GPT-3 などの自己回帰言語モデルは、大量のデータでトレーニングされ、その寄与するデータを言い換え、要約、照合、解釈して、元の言語を保持しながら自然な音声と書き込みのパターンを再現できる、一貫した生成言語モデルを作成するように設計されています。トレーニングデータの意図。
このようなフレームワークは、元のデータを直接「吸収されない」逆流するため、モデルのトレーニング段階で頻繁に罰せられるため、確立されたフレーズであっても、必然的に同義語を求めます。
研究者らによって発掘された、明らかに AI によって作成/支援された科学的提出物には、機械学習分野の既知のフレーズに対する創造的な同義語の試みが異常に多く失敗していることが含まれています。
ディープ ニューラル ネットワーク: '深層神経組織」
人工ニューラルネットワークk: 「(偽物 | 偽造)神経組織」
モバイルネットワーク: '多目的な組織」
ネットワーク攻撃: '組織(待ち伏せ | 襲撃)」
ネットワーク接続: 「組織協会」
ビッグデータ: '(巨大な | 膨大な | 計り知れない | 莫大な) 情報」
データウェアハウス: 「情報(ストックルーム | 配送センター)」
人工知能 (AI): 「(偽物 | 人間が作った)意識」
ハイパフォーマンスコンピューティング: 「エリートフィギュア」
霧/ミスト/クラウド コンピューティング: 「もやの様子」
グラフィックス プロセッシング ユニット (GPU): 「デザイン準備ユニット」
中央処理装置 (CPU): 「焦点準備ユニット」
ワークフローエンジン: 「ワークプロセスモーター」
顔認識: 「顔認証」
音声認識: 「談話承認」
平均二乗誤差: 「平均二乗 (間違い | 失敗)」
平均絶対誤差: 「意地悪(あからさま | 最高)(間違い | 失敗)」
信号対ノイズ: '(動き | 旗 | 標識 | 標識 | 信号) から (喧騒 | 騒ぎ | 騒音)'
グローバルパラメータ: 「ワールドワイドパラメータ」
ランダムアクセス: 「(任意 | 不規則) への通行権を得る」
ランダムフォレスト: '(任意 | 不規則) (奥地 | 森林地帯 | 緑豊かな地域)'
ランダムな値: 「(恣意的 | 不規則な)尊重」
アリのコロニー: 「地下昆虫 (州 | 都道府県 | 地域 | 地域 | 集落)」
アリのコロニー: 「地下の不気味な這い回る (州 | 県 | 地域 | 地域 | 集落)」
残りのエネルギー: 「残った活力」
運動エネルギー: 「モーターバイタリティ」
素朴なベイズ: 「(信じやすい | 無実 | だまされやすい)ベイズ」
携帯情報端末 (PDA): 「個人のコンピュータ化された協力者」
2021年XNUMX月、研究者らは以下の質問を行った。 寸法 学術検索エンジンは、この種の混乱した自動化された言語を検索し、「膨大な情報」(これは有効な語句であり、「ビッグ データ」の失敗した同義語ではありません)などの正当な語句を慎重に除外します。 この時点で彼らは次のことを観察しました マイクロプロセッサとマイクロシステム 誤った言い換えの発生件数が最も多かった。
現時点ではまだ可能です 検索する (アーカイブスナップショット、15 年 07 月 2021 日) ナンセンスなフレーズ「深層神経組織」(つまり「ディープ ニューラル ネットワーク」) に関する多数の科学論文や、上記のリストにある他の論文も同様のヒットをもたらします。
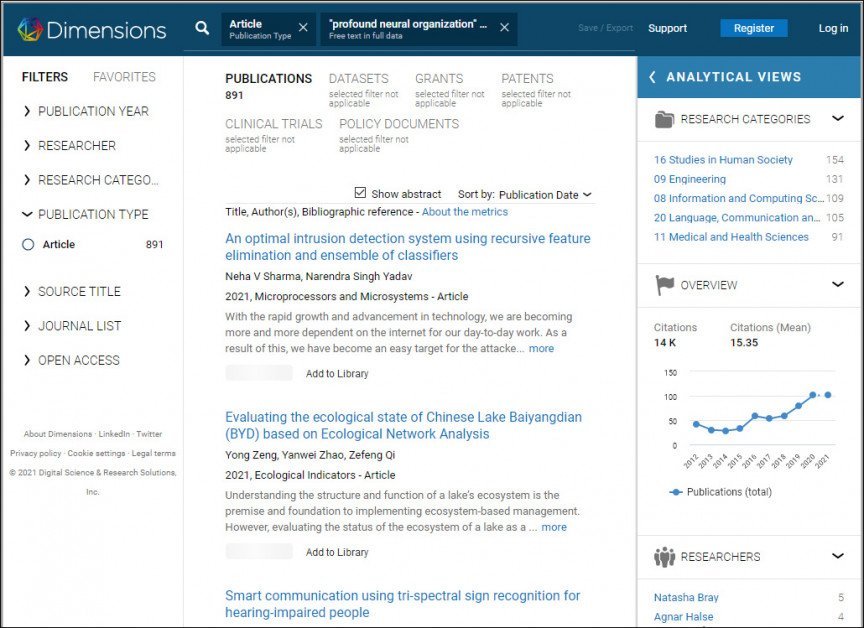
Dimensions での「深層ニューラル組織」 (「ディープ ニューラル ネットワーク」) の検索結果。 出典: https://app.dimensions.ai/
マイクロプロセッサー ジャーナルは 1976 年に創刊され、次のように改名されました。 マイクロプロセッサとマイクロシステム 二年後。
ナンセンスな言語の増加
研究者らは、2018 年 2021 月から 6 年 8 月までの期間を調査し、過去 XNUMX 年間、特に過去 XNUMX ~ XNUMX か月で投稿数が急激に増加していることを観察しました。
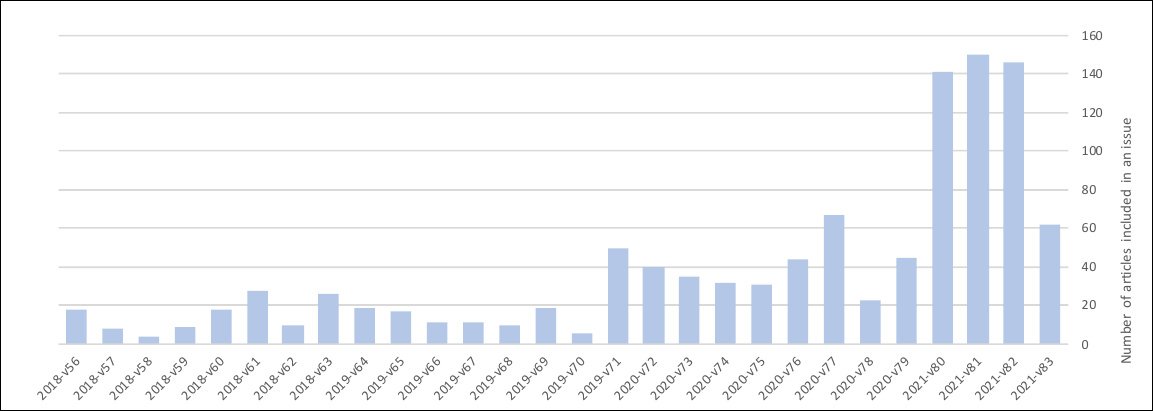
相関関係か因果関係か? Microprocessors and Microsystems ジャーナルへの投稿の増加は、一見立派な投稿における「ナンセンス」テキストや同義語の増加と一致しているようです。 出典:https://arxiv.org/pdf/2107.06751.pdf
共同研究者によって収集された最終的なデータセットには、トゥールーズ大学のエルゼビア サブスクリプションを通じて取得した 1,078 件の全長論文が含まれています。
中国の科学論文に対する編集監督の低下
この論文は、報告された投稿の編集評価に割り当てられる期間が 2021 年に大幅に短縮され、40 日を下回ると観察しています。 2021 年 XNUMX 月から明らかなように、査読の標準時間は XNUMX 分の XNUMX に減少しています。
フラグが立てられた論文の中で最も多いのは、中国本土に関係する著者によるもので、404 日以内に受理された 30 件の論文のうち、97.5% が中国関連です。 逆に、編集プロセスが 40 日を超えた場合 (615 件の論文)、中国関連の投稿はそのカテゴリの 9.5% にすぎず、不均衡は XNUMX 倍でした。
報告書は、警告された論文の侵入は編集プロセスの欠陥と、投稿数の増加に直面したリソース不足の可能性によるものだとしている。
研究者らは、GPT スタイルの生成モデルと同様のタイプの言語生成フレームワークが、フラグが立てられた論文のテキストの多くを生成するために使用されていると仮説を立てています。 ただし、生成モデルがソースを抽象化する方法により、これを証明することが困難になります。主な証拠は、貧弱で不必要な同義語の常識的な評価と、提出された論理的一貫性の綿密な検査にあります。
研究者らはさらに、このナンセンスの洪水に寄与していると考えられる生成言語モデルは、問題のあるテキストを作成するだけでなく、研究者自身が行ったのと同じ方法で、問題のあるテキストを認識し、体系的にフラグを立てることもできることを観察した。手動で。 この研究では、GPT-2 を使用したそのような実装について詳しく説明し、問題のある科学的提出物を特定するための将来のシステムのフレームワークを提供します。
「汚染された」投稿の発生率は、調査対象となった他のジャーナル (最大 72.1%) と比較して、エルゼビア ジャーナル (13.6%) ではるかに高かった。
セマンティクスだけではない
研究者らは、問題のジャーナルの多くは単に間違った言語を使用しているだけでなく、科学的に不正確な記述が含まれていることを強調しており、生成言語モデルは単に貢献する科学者の限られた言語スキルを向上させるために使用されているだけでなく、実際に使用されている可能性を示している。論文の中核となる定理とデータの少なくとも一部を定式化するために使用されます。
他のケースでは、研究者らは、学術研究文化の「出版か消滅か」の圧力に対抗するため、そしておそらくは世界的な事前研究の国家ランキングを向上させるために、抽象化された(そして優れた)先行研究の効果的な「再合成」または「紡ぎ出し」を主張している。膨大な量の AI 研究で著名です。

投稿された論文の無意味な内容。 この場合、研究者らは、テキストがその場限りの文書から派生したものであることを発見しました。 EDNの記事、そこから付属のイラストも出所不明で盗まれています。 元の内容の書き換えはあまりにも極端で、意味がなくなってしまいます。
提出されたエルゼビアの論文のいくつかを分析したところ、研究者らは意味を推測できなかった文章を発見した。 存在しない文献への参照。 実際にはサポート資料に現れていない数式内の変数や定理への参照 (言語ベースの抽象化を示唆するもの、または '幻覚' 明らかに事実に基づくデータ); 出典を明示せずに画像を再利用すること(研究者らはこれを著作権の観点からではなく、科学的厳密性が不十分であることの指標として批判している)。
引用の失敗
科学論文の議論を裏付けることを目的とした引用が、フラグが立てられた例の多くで「壊れているか、無関係な出版物につながっている」ことが判明しました。
さらに、「関連研究」への言及には、GPT スタイルのシステムによって「幻覚」を受けたと研究者が信じている著者が含まれていることが多いようです。
徘徊注意
GPT-3 のような最先端の言語モデルであっても、長い議論の間に集中力を失う傾向があるというもう XNUMX つの欠点があります。 研究者らは、フラグが立てられた論文は、論文の早い段階で、最初に準備メモなどで取り上げられた後は実際には決して戻らないトピックを取り上げていることが多いことを発見した。
彼らはまた、最悪の例のいくつかは、ソーステキストが一連の翻訳エンジンを複数回通過することによって発生し、そのたびに意味がさらに歪められると理論づけています。
出典と理由
この現象の背後にあるものを識別しようとして、論文の著者らは多くの可能性を示唆しています。 製紙工場 ソース素材として使用されているため、プロセスの非常に早い段階で不正確さが生じ、必然的にさらなる不正確さが生じることになります。 Spinbot などの記事スピニング ツールが盗作を隠すために使用されているということ。 そして、定期的に出版するという圧倒的なプレッシャーにより、リソースが不足している研究者が GPT-3 スタイルのシステムを使用して新しい学術論文を増強または完全に作成するようになっているということです。
研究者らは、明らかにそれ自身の主題である機械学習システムの餌食になることが判明している学術出版分野における監視の強化と基準の改善を求める行動喚起で締めくくっている。 彼らはまた、エルゼビアやその他の出版社に対し、より厳格な審査と審査手順を導入するよう勧告し、この点に関する現在の基準と慣行を広く批判し、次のように示唆している。合成テキストによる欺瞞は、科学文献の完全性を脅かします。」















