
Artificial Intelligence
EfficientViT: 高解像度コンピューター ビジョン用のメモリ効率の高いビジョン トランスフォーマー

Vision Transformer モデルはモデル能力が高いため、最近大きな成功を収めています。 そのパフォーマンスにもかかわらず、ビジョン トランスフォーマー モデルには大きな欠陥が XNUMX つあります。その驚くべき計算能力には高い計算コストがかかり、それがビジョン トランスフォーマーがリアルタイム アプリケーションの最初の選択肢ではない理由です。 この問題に取り組むために、開発者のグループは、高速ビジョン トランスフォーマーのファミリーである EfficientViT を立ち上げました。
EfficientViT に取り組んでいるとき、開発者は、変流器モデルの速度が非効率的なメモリ操作、特に MHSA またはマルチヘッド セルフ アテンション ネットワークにおける要素ごとの関数とテンソルの再形成によって制限されることが多いことに気づきました。 これらの非効率なメモリ操作に取り組むために、EfficientViT 開発者は、サンドイッチ レイアウトを使用した新しいビルディング ブロックに取り組みました。つまり、EfficientViT モデルは、メモリ効率の向上に役立つ、効率的な FFN 層間の単一のメモリにバインドされたマルチヘッド セルフ アテンション ネットワークを利用します。また、チャネル全体のコミュニケーションも強化されます。 さらに、このモデルは、アテンション マップがヘッド間で高い類似性を持っていることが多く、それが計算の冗長性につながることも発見しました。 冗長性の問題に取り組むために、EfficientViT モデルは、全機能のさまざまな分割をアテンション ヘッドに供給するカスケード グループ アテンション モジュールを提供します。 この方法は、計算コストの節約に役立つだけでなく、モデルの注意の多様性も向上します。
さまざまなシナリオにわたって EfficientViT モデルに対して実行された包括的な実験では、EfficientViT が既存の効率的なモデルよりも優れたパフォーマンスを発揮することが示されています。 コンピュータビジョン 精度と速度の間で適切なトレードオフを実現します。 それでは、さらに深く掘り下げて、EfficientViT モデルをもう少し詳しく見てみましょう。
ビジョントランスフォーマーとEfficientViTの紹介
Vision Transformers は、優れたパフォーマンスと高い計算能力を提供するため、依然としてコンピューター ビジョン業界で最も人気のあるフレームワークの 2 つです。ただし、ビジョン トランスフォーマー モデルの精度とパフォーマンスが常に向上するにつれて、運用コストと計算オーバーヘッドも増加します。たとえば、SwinV3 や V-MoE などの ImageNet データセットで最先端のパフォーマンスを提供することが知られている現在のモデルは、それぞれ 14.7B と XNUMXB のパラメーターを使用します。これらのモデルは、計算コストと要件に加えてサイズが非常に大きいため、リアルタイム デバイスやアプリケーションには実質的に適していません。
EfficientNet モデルは、パフォーマンスを向上させる方法を探ることを目的としています。 ビジョントランスフォーマーモデル、効率的かつ効果的なトランスベースのフレームワーク アーキテクチャの設計の背後にある原則を見つけます。 EfficientViT モデルは、Swim や DeiT などの既存のビジョン トランスフォーマー フレームワークに基づいており、計算の冗長性、メモリ アクセス、パラメーターの使用量など、モデルの干渉速度に影響を与える XNUMX つの重要な要素を分析します。 さらに、このモデルは、ビジョン トランスフォーマー モデルの速度がメモリに依存していることを観察しています。これは、CPU/GPU の計算能力の完全な利用がメモリ アクセス遅延によって禁止または制限されていることを意味し、トランスフォーマーの実行速度に悪影響を及ぼします。 。 MHSA またはマルチヘッド セルフ アテンション ネットワークでの要素ごとの関数とテンソルの再形成は、最もメモリ効率の悪い操作です。 このモデルではさらに、FFN (フィード フォワード ネットワーク) と MHSA の比率を最適に調整すると、パフォーマンスに影響を与えることなくメモリ アクセス時間を大幅に短縮できることがわかりました。 ただし、このモデルでは、注意ヘッドが同様の線形投影を学習する傾向があるため、注意マップにある程度の冗長性も観察されます。
このモデルは、EfficientViT の研究作業中に得られた結果を最終的に発展させたものです。 このモデルは、フィード フォワード ネットワークまたは FFN レイヤーの間に単一のメモリ バインド MHSA レイヤーを適用するサンドイッチ レイアウトを備えた新しいブラックを特徴としています。 このアプローチは、MHSA でメモリに依存する操作の実行にかかる時間を短縮するだけでなく、より多くの FFN レイヤが異なるチャネル間の通信を容易にすることで、プロセス全体のメモリ効率も向上します。 このモデルは、新しい CGA またはカスケード グループ アテンション モジュールも利用しています。このモジュールは、アテンション ヘッドの計算の冗長性を削減するだけでなく、ネットワークの深さを増加させることで、計算をより効率的にすることを目的としており、結果としてモデルの容量が向上します。 最後に、モデルは、値の投影を含む重要なネットワーク コンポーネントのチャネル幅を拡張する一方で、フィードフォワード ネットワークの隠れ次元などの値の低いネットワーク コンポーネントを縮小して、フレームワーク内のパラメーターを再分配します。

上の画像からわかるように、EfficientViT フレームワークは、精度と速度の両方の点で、現在の最先端の CNN モデルや ViT モデルよりも優れたパフォーマンスを発揮します。 しかし、EfficientViT フレームワークはどのようにして現在の最先端のフレームワークの一部を上回るパフォーマンスを達成できたのでしょうか? それを調べてみましょう。
EfficientViT: ビジョントランスフォーマーの効率の向上
EfficientViT モデルは、XNUMX つの観点を使用して既存のビジョン トランスフォーマー モデルの効率を向上させることを目的としています。
- 計算の冗長性。
- メモリアクセス。
- パラメータの使用法。
このモデルは、上記のパラメーターがビジョン トランスフォーマー モデルの効率にどのような影響を与えるか、およびそれらを解決してより良い結果を効率的に達成する方法を見つけることを目的としています。 それらについてもう少し詳しく話しましょう。
メモリアクセスと効率
モデルの速度に影響を与える重要な要素の XNUMX つは、 メモリアクセスのオーバーヘッド マオとか。 以下の画像でわかるように、要素ごとの加算、正規化、頻繁な再形成などのトランスフォーマーのいくつかの演算子は、異なるメモリ ユニットにアクセスする必要があり、時間のかかるプロセスであるため、メモリ効率の悪い演算です。
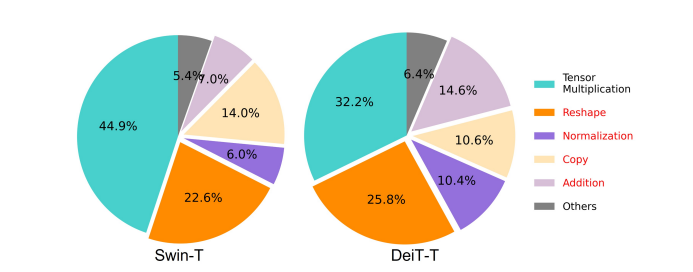
低ランク近似やスパース アテンションなど、標準的なソフトマックス セルフ アテンションの計算を簡素化できる既存の方法はいくつかありますが、多くの場合、高速化が限定的であり、精度が低下します。
一方、EfficientViT フレームワークは、フレームワーク内のメモリ効率の悪い層の量を減らすことでメモリ アクセス コストを削減することを目的としています。 このモデルは、DeiT-T と Swin-T を、1.25 倍と 1.5 倍の高い干渉スループットを備えた小さなサブネットワークにスケールダウンし、これらのサブネットワークのパフォーマンスを MHSA レイヤーの割合と比較します。 以下の画像でわかるように、このアプローチを実装すると、MHSA レイヤーの精度が約 20 ~ 40% 向上します。

計算効率
MHSA レイヤーは、入力シーケンスを複数のサブスペースまたはヘッドに埋め込む傾向があり、アテンション マップを個別に計算します。これは、パフォーマンスを向上させることが知られているアプローチです。 ただし、アテンション マップは計算コストが安いわけではないため、計算コストを調査するために、EfficientViT モデルは、より小規模な ViT モデルで冗長なアテンションを削減する方法を調査します。 このモデルは、幅をダウンスケールした DeiT-T モデルと Swim-T モデルを 1.25 倍の推論速度でトレーニングすることにより、各ブロック内の各ヘッドと残りのヘッドの最大コサイン類似性を測定します。 以下の画像でわかるように、アテンション ヘッド間には非常に多くの類似点があり、多数のヘッドが正確な完全な特徴の同様の投影を学習する傾向があるため、モデルに計算の冗長性が生じていることが示唆されます。

ヘッドがさまざまなパターンを学習できるようにするために、このモデルは、各ヘッドに全機能の一部のみが供給されるという直感的なソリューションを明示的に適用しています。これは、グループ畳み込みの考え方に似た手法です。 このモデルは、変更された MHSA レイヤーを特徴とするダウンスケール モデルのさまざまな側面をトレーニングします。
パラメータ効率
平均的な ViT モデルは、投影に同等の幅を使用すること、FFN での拡張率を 4 に設定すること、NLP トランスフォーマーからステージ上のヘッドを増やすことなどの設計戦略を継承しています。 これらのコンポーネントの構成は、軽量モジュール用に慎重に再設計する必要があります。 EfficientViT モデルは、テイラー構造化枝刈りを展開して Swim-T 層および DeiT-T 層の必須コンポーネントを自動的に見つけ、基礎となるパラメーター割り当て原則をさらに調査します。 特定のリソース制約の下では、プルーニング手法により重要でないチャネルが削除され、重要なチャネルは保持されるため、可能な限り最高の精度が保証されます。 以下の図は、Swin-T フレームワークでのプルーニング前後の入力エンベディングに対するチャネルの比率を比較しています。 次のことが観察されました。 ベースライン精度: 79.1%。 剪定精度: 76.5%。

上の画像は、フレームワークの最初の XNUMX つのステージではより多くの次元が保持されるのに対し、最後の XNUMX つのステージでははるかに少ない次元が保持されることを示しています。 これは、ステージごとにチャネルを XNUMX 倍にするか、すべてのブロックに同等のチャネルを使用する一般的なチャネル構成により、最後の数ブロックに大幅な冗長性が生じる可能性があることを意味している可能性があります。
効率的なビジョントランスフォーマー : アーキテクチャ
上記の分析で得られた学習に基づいて、開発者は、高速な干渉速度を提供する新しい階層モデルの作成に取り組みました。 効率的なビタミン モデル。 EfficientViT フレームワークの構造を詳しく見てみましょう。 以下の図は、EfficientViT フレームワークの一般的な概念を示しています。
EfficientViT フレームワークの構成要素
より効率的なビジョン トランスフォーマー ネットワークの構成要素を次の図に示します。

このフレームワークは、カスケード グループ アテンション モジュール、メモリ効率の高いサンドイッチ レイアウト、およびパラメータ再割り当て戦略で構成されており、それぞれ計算、メモリ、パラメータの観点からモデルの効率を向上させることに重点を置いています。 それらについてさらに詳しく話しましょう。
サンドイッチのレイアウト
このモデルは、新しいサンドイッチ レイアウトを使用して、フレームワークのより効果的かつ効率的なメモリ ブロックを構築します。 サンドイッチ レイアウトでは、メモリに依存するセルフ アテンション レイヤーが少なくなり、チャネル通信によりメモリ効率の高いフィードフォワード ネットワークが使用されます。 より具体的には、このモデルは、FFN レイヤーの間に挟まれた空間ミキシング用の単一のセルフ アテンション レイヤーを適用します。 この設計は、セルフ アテンション層によりメモリ時間の消費を削減するだけでなく、FFN 層の使用によりネットワーク内の異なるチャネル間の効果的な通信も可能にします。 また、このモデルは、DWConv または Deceptive Convolution を使用して各フィードフォワード ネットワーク層の前に追加のインタラクション トークン層を適用し、ローカル構造情報の帰納的バイアスを導入することでモデルの能力を強化します。
カスケード グループ アテンション
MHSA レイヤーの主な問題の XNUMX つは、アテンション ヘッドの冗長性により計算が非効率になることです。 この問題を解決するために、このモデルは、効率的な CNN のグループ畳み込みからインスピレーションを得た新しいアテンション モジュールである、ビジョン トランスフォーマー用の CGA (カスケード グループ アテンション) を提案します。 このアプローチでは、モデルは完全な特徴の分割を個々のヘッドに供給するため、アテンションの計算をヘッド全体にわたって明示的に分解します。 完全な特徴を各ヘッドに供給するのではなく、特徴を分割することで計算が節約され、プロセスがより効率的になります。モデルは、レイヤーがより豊富な情報を持つ特徴の投影を学習することを奨励することで、精度とその能力をさらに向上させることに取り組み続けます。

パラメータの再割り当て
パラメーターの効率を向上させるために、モデルは、重要なモジュールのチャネル幅を拡張する一方で、それほど重要ではないモジュールのチャネル幅を縮小することにより、ネットワーク内のパラメーターを再割り当てします。 テイラー解析に基づいて、モデルは各ステージで各ヘッドの投影に小さなチャネル寸法を設定するか、投影が入力と同じ寸法を持つことを許可します。 パラメータの冗長性を高めるために、フィードフォワード ネットワークの拡張率も 2 から 4 に引き下げられました。 EfficientViT フレームワークが実装する提案された再割り当て戦略は、重要なモジュールにより多くのチャネルを割り当て、モジュールが高次元空間での表現をより適切に学習できるようにし、特徴情報の損失を最小限に抑えます。 さらに、干渉プロセスを高速化し、モデルの効率をさらに高めるために、モデルは重要ではないモジュールの冗長パラメータを自動的に削除します。

EfficientViT フレームワークの概要は、上の図で説明されています。
- EfficientViT のアーキテクチャ、
- サンドイッチレイアウトブロック、
- カスケード グループ アテンション。
EfficientViT : ネットワーク アーキテクチャ

上の図は、EfficientViT フレームワークのネットワーク アーキテクチャを要約したものです。 このモデルは、20,80×16 のパッチを C16 次元トークンに埋め込むオーバーラップ パッチ埋め込み [1] を導入し、低レベルの視覚表現学習のパフォーマンスを向上させるモデルの能力を強化します。 モデルのアーキテクチャは 2 つのステージで構成され、各ステージでは EfficientViT フレームワークの提案された構成要素が積み重ねられ、各サブサンプリング層 (解像度の 4 倍のサブサンプリング) でのトークンの数が XNUMX 分の XNUMX に削減されます。 サブサンプリングをより効率的にするために、モデルは、サンプリング中の情報の損失を減らすために注目層を反転残差ブロックに置き換えることを除いて、提案されたサンドイッチ レイアウトを持つサブサンプル ブロックを提案します。 さらに、BN は先行する線形層または畳み込み層に折り畳むことができるため、従来の LayerNorm(LN) の代わりに BatchNorm(BN) が使用され、LN よりも実行時に利点が得られます。
EfficientViT モデルファミリー
EfficientViT モデルファミリーは、深さと幅のスケールが異なる 6 つのモデルで構成され、各ステージに設定された数のヘッドが割り当てられます。 モデルは、最終段階と比較して初期段階で使用するブロックが少なく、より大きな解像度での初期段階の処理プロセスには時間がかかるため、MobileNetV3 フレームワークで行われるプロセスと同様のプロセスになります。 幅は、後のステージでの冗長性を減らすために、小さな係数でステージごとに増加します。 以下に添付された表は、EfficientViT モデル ファミリのアーキテクチャの詳細を示しています。C、L、および H は、特定のステージの幅、深さ、およびヘッドの数を指します。

EfficientViT: モデルの実装と結果
EfficientViT モデルの合計バッチ サイズは 2,048 で、Timm と PyTorch で構築され、300 個の Nvidia V8 GPU を使用して 100 エポックにわたって最初からトレーニングされ、コサイン学習率スケジューラーと AdamW オプティマイザーを使用し、ImageNet で画像分類実験を実行します。 -1K。 入力画像はランダムにトリミングされ、224×224 の解像度にサイズ変更されます。 ダウンストリーム画像分類を含む実験では、EfficientViT フレームワークが 300 エポックのモデルを微調整し、バッチ サイズ 256 の AdamW オプティマイザーを使用します。モデルは COCO での物体検出に RetineNet を使用し、さらに 12 エポックのモデルのトレーニングを続けます。同じ設定のエポック。
ImageNet での結果
EfficientViT のパフォーマンスを分析するために、ImageNet データセット上の現在の ViT および CNN モデルと比較されます。 比較の結果を次の図に示します。 見てわかるように、EfficientViT モデル ファミリは、ほとんどの場合、現在のフレームワークよりも優れたパフォーマンスを示し、速度と精度の間の理想的なトレードオフを実現しています。

効率的な CNN および効率的な ViT との比較
このモデルはまず、EfficientNet などの効率的な CNN および MobileNet などの標準的な CNN フレームワークとパフォーマンスを比較します。 MobileNet フレームワークと比較すると、EfficientViT モデルは上位 1 位の精度スコアを獲得し、Intel CPU と V3.0 GPU ではそれぞれ 2.5 倍と 100 倍高速に実行されていることがわかります。
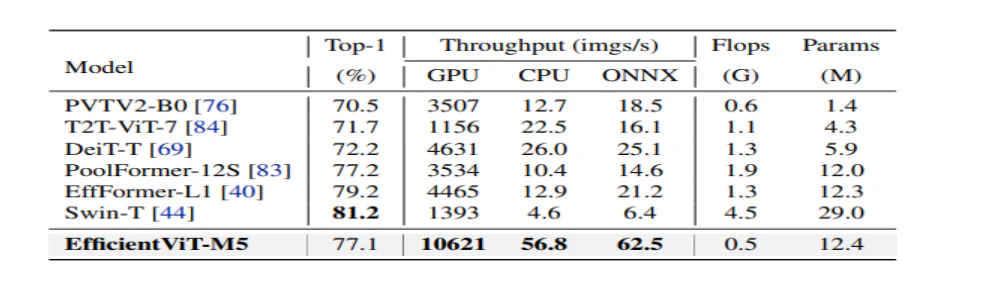
上の図は、EfficientViT モデルのパフォーマンスを、ImageNet-1K データセット上で実行される最先端の大規模 ViT モデルと比較しています。
ダウンストリーム画像分類
EfficientViT モデルは、モデルの転移学習能力を研究するためにさまざまな下流タスクに適用されます。以下の画像は、実験の結果を要約したものです。ご覧のとおり、EfficientViT-M5 モデルは、はるかに高いスループットを維持しながら、すべてのデータセットにわたってより良い、または同様の結果を達成しています。唯一の例外は Cars データセットで、EfficientViT モデルは正確な結果を提供できません。

オブジェクト検出
EfficientViT のオブジェクト検出機能を分析するために、COCO オブジェクト検出タスクの効率的なモデルと比較されます。以下の画像は、比較の結果を要約したものです。

最終的な考え
この記事では、カスケード グループ アテンションを使用し、メモリ効率の高い操作を提供する高速ビジョン トランスフォーマー モデルのファミリーである EfficientViT について説明しました。 EfficientViT のパフォーマンスを分析するために行われた広範な実験では、ほとんどの場合、EfficientViT モデルが現在の CNN およびビジョン トランスフォーマー モデルよりも優れたパフォーマンスを発揮するため、有望な結果が示されました。 また、ビジョントランスの干渉速度に影響を与える要因についての分析も試みました。















