
Artificial Intelligence
Að búa til tungumálalíkan í GPT-stíl fyrir eina spurningu

Vísindamenn frá Kína hafa þróað hagkvæma aðferð til að búa til náttúruleg málvinnslukerfi í GPT-3-stíl en forðast sífellt ofboðslegri kostnað af tíma og peningum sem fylgja því að þjálfa upp mikið magn gagnasöfn - vaxandi tilhneiging sem annars hótar að á endanum falli þennan geira gervigreindar úr deild. til FAANG leikmanna og háttsettra fjárfesta.
Fyrirhugaður rammi heitir Verkefnadrifin tungumálalíkön (TLM). Í stað þess að þjálfa risastórt og flókið líkan á gríðarstórum hópi milljarða orða og þúsundir merkimiða og flokka, þjálfar TLM í staðinn mun minna líkan sem inniheldur í raun fyrirspurn beint inn í líkanið.

Til vinstri, dæmigerð hástærðaraðferð við tungumálalíkön í miklu magni; rétt, grannur aðferð TLM til að kanna stóran tungumálahóp eftir efni eða spurningu. Heimild: https://arxiv.org/pdf/2111.04130.pdf
Í raun er einstakt NLP reiknirit eða líkan framleitt til að svara einni spurningu, í stað þess að búa til gríðarstórt og ómeðfarið almennt mállíkan sem getur svarað fjölbreyttari spurningum.
Við prófun TLM komust rannsakendur að því að nýja nálgunin nær niðurstöðum sem eru svipaðar eða betri en forþjálfaðar tungumálalíkön eins og ROBERTA-Large, og NLP kerfi í háum skala eins og OpenAI's GPT-3, TRILLION Parameter Switch Transformer frá Google Gerð, Kóreu HyperClover, AI21 Labs' Jurassic 1, og Microsoft Megatron-Turing NLG 530B.
Í tilraunum með TLM yfir átta flokkunargagnasöfn á fjórum lénum komust höfundarnir að auki að því að kerfið dregur úr þjálfunar-FLOPs (flotpunktsaðgerðir á sekúndu) sem krafist er af tveimur stærðargráðum. Rannsakendur vona að TLM geti „lýðræðislegt“ geira sem er að verða sífellt úrvalsríkari, með NLP módel svo stór að ekki er raunhæft að setja þau upp á staðnum, og sitji þess í stað, í tilviki GPT-3, á bak við dýr og takmarkaðan aðgang API OpenAI og, núna, Microsoft Azure.
Höfundarnir fullyrða að það að skera þjálfunartíma um tvær stærðir lækki þjálfunarkostnað yfir 1,000 GPU í einn dag í aðeins 8 GPU á 48 klst.
Nýji tilkynna er titill NLP frá grunni án stórfelldrar forþjálfunar: Einfaldur og skilvirkur rammi, og kemur frá þremur fræðimönnum við Tsinghua háskólann í Peking, og fræðimanni frá kínverska gervigreindarþróunarfyrirtækinu Recurrent AI, Inc.
Óviðráðanleg svör
The kostnaður þjálfun árangursríkra, alhliða tungumálalíkönum er sífellt að verða einkennt sem hugsanleg „hitamörk“ á því að hve miklu leyti árangursríkt og nákvæmt NLP getur raunverulega dreifst í menningu.
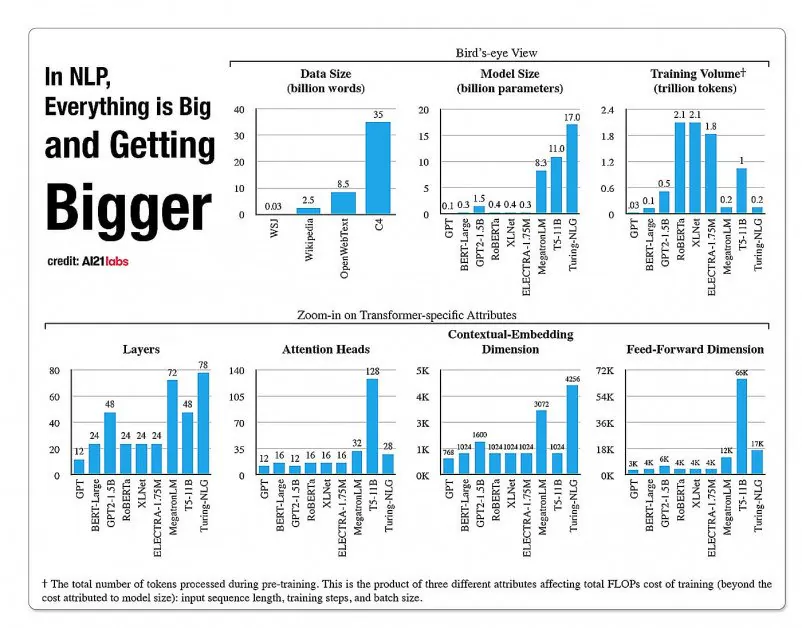
Tölfræði um vöxt hliðar í NLP líkanarkitektúr, úr 2020 skýrslu frá A121 Labs. Heimild: https://arxiv.org/pdf/2004.08900.pdf
Árið 2019 rannsakandi reiknað að það kostar $61,440 USD að þjálfa XLNet gerð (Tilkynnt var á sínum tíma að sigra BERT í NLP verkefnum) yfir 2.5 daga á 512 kjarna í 64 tækjum, en GPT-3 er áætlaður að hafa kostað 12 milljónir dollara að þjálfa - 200 sinnum kostnaðinn við að þjálfa forvera sinn, GPT-2 (þó að nýlegar endurmat haldi því fram að það gæti verið þjálfað núna fyrir aðeins 4,600,000 $ á lægsta verðlagða skýja-GPU).
Undirmengi gagna byggt á fyrirspurnarþörfum
Þess í stað leitast hin nýja fyrirhugaða arkitektúr að því að fá nákvæmar flokkanir, merkingar og alhæfingu með því að nota fyrirspurn sem eins konar síu til að skilgreina hlutmengi upplýsinga úr stórum tungumálagagnagrunni sem verður þjálfaður, ásamt fyrirspurninni, til að veita svör um afmarkað efni.
Höfundar segja:
„TLM er knúið áfram af tveimur lykilhugmyndum. Í fyrsta lagi ná menn tökum á verkefni með því að nota aðeins lítinn hluta heimsþekkingar (t.d. þurfa nemendur aðeins að rifja upp nokkra kafla, meðal allra bóka í heiminum, til að troða sér fyrir próf).
„Við gerum ráð fyrir að það sé mikil offramboð í stórum hópi fyrir tiltekið verkefni. Í öðru lagi er þjálfun á merktum gögnum undir eftirliti mun skilvirkari gögnum fyrir frammistöðu síðar en að hámarka tungumálalíkanamarkmiðið á ómerktum gögnum. Byggt á þessum hvötum, notar TLM verkefnagögnin sem fyrirspurnir til að sækja örlítið undirmengi af almennum hluta. Þessu er fylgt eftir með því að fínstilla í sameiningu verkefnismarkmið undir eftirliti og mállíkanamarkmið með því að nota bæði sótt gögn og verkefnisgögn.'
Auk þess að gera mjög árangursríka NLP líkanaþjálfun á viðráðanlegu verði, sjá höfundar ýmsa kosti við að nota verkefnisdrifin NLP líkan. Fyrir það fyrsta geta rannsakendur notið meiri sveigjanleika, með sérsniðnum aðferðum fyrir lengd raða, táknun, stillingu á ofbreytum og framsetningu gagna.
Rannsakendur sjá einnig fyrir þróun blendinga framtíðarkerfa sem skipta út takmarkaðri forþjálfun PLM (sem annars er ekki gert ráð fyrir í núverandi útfærslu) á móti meiri fjölhæfni og alhæfingu gegn þjálfunartíma. Þeir telja kerfið skref fram á við til framfara á alhæfingaraðferðum innan léns.
Prófanir og niðurstöður
TLM var prófað á flokkunaráskorunum í átta verkefnum á fjórum sviðum - lífeindafræði, fréttum, umsögnum og tölvunarfræði. Verkefnum var skipt í auðlindaríka og auðlindalitla flokka. Mikil auðlindaverkefni innihéldu yfir 5,000 verkefnisgögn, svo sem AGNews og RCT, meðal annarra; fjárvana verkefni innifalin ChemProt og ACL-ARC, Sem og HyperPartisan gagnagrunnsuppgötvun frétta.
Rannsakendur þróuðu tvö þjálfunarsett sem heita Corpus-BERT og Corpus-RoBERTa, hið síðarnefnda tífalt stærra en hið fyrra. Í tilraununum var borið saman almenn forþjálfuð tungumálalíkön BERT (frá Google) og RÓBERTA (frá Facebook) yfir í nýja arkitektúrinn.
Ritgerðin tekur fram að þó að TLM sé almenn aðferð og ætti að vera takmarkaðara að umfangi og notagildi en breiðari og háþróaðar gerðir, þá er hún fær um að framkvæma nærri lénsaðlagandi fínstillingaraðferðir.

Niðurstöður úr samanburði á frammistöðu TLM á móti BERT og RoBERTa byggðum. Niðurstöðurnar sýna meðaltal F1 stig yfir þrjá mismunandi þjálfunarkvarða og lista yfir fjölda stika, heildarþjálfunarreikning (FLOPs) og stærð þjálfunarheildar.
Höfundarnir komast að þeirri niðurstöðu að TLM sé fær um að ná sambærilegum eða betri árangri en PLM, með verulegri lækkun á FLOPs sem þörf er á, og þarfnast aðeins 1/16 hluta af þjálfunarheildinni. Á meðalstórum og stórum mælikvarða getur TLM greinilega bætt árangur um 0.59 og 0.24 stig að meðaltali, en minnkar þjálfunargagnastærð um tvær stærðargráður.
„Þessar niðurstöður staðfesta að TLM er mjög nákvæmt og mun skilvirkara en PLM. Þar að auki fær TLM fleiri kosti í skilvirkni á stærri skala. Þetta gefur til kynna að PLM í stærri stíl gæti hafa verið þjálfuð til að geyma almennari þekkingu sem er ekki gagnleg fyrir tiltekið verkefni.'















