
Արհեստական բանականություն
Ուղղակի նախապատվությունների օպտիմիզացում. ամբողջական ուղեցույց

Լեզուների մեծ մոդելները (LLM) մարդկային արժեքներին և նախասիրություններին համապատասխանեցնելը դժվար է: Ավանդական մեթոդներ, ինչպիսիք են Ուսուցման ամրապնդում մարդկային արձագանքից (RLHF), ճանապարհ են հարթել՝ ինտեգրելով մարդկային միջոցները՝ մոդելի արդյունքները կատարելագործելու համար: Այնուամենայնիվ, RLHF-ը կարող է լինել բարդ և ռեսուրսների ինտենսիվ, որը պահանջում է զգալի հաշվողական հզորություն և տվյալների մշակում: Ուղղակի նախապատվությունների օպտիմիզացում (DPO) ի հայտ է գալիս որպես նոր և ավելի պարզեցված մոտեցում, որն առաջարկում է արդյունավետ այլընտրանք այս ավանդական մեթոդներին: Օպտիմալացման գործընթացի պարզեցմամբ՝ DPO-ն ոչ միայն նվազեցնում է հաշվողական բեռը, այլև մեծացնում է մոդելի՝ մարդու նախասիրություններին արագ հարմարվելու ունակությունը:
Այս ուղեցույցում մենք կխորանանք DPO-ի մեջ՝ ուսումնասիրելով դրա հիմքերը, իրականացումը և գործնական կիրառությունները:
Նախապատվությունների հավասարեցման անհրաժեշտությունը
DPO-ն հասկանալու համար կարևոր է հասկանալ, թե ինչու է LLM-ների համապատասխանեցումը մարդկային նախասիրություններին այդքան կարևոր: Չնայած իրենց տպավորիչ հնարավորություններին, LLM-ները, որոնք վերապատրաստվել են տվյալների հսկայական հավաքածուների վրա, երբեմն կարող են արտադրել արդյունքներ, որոնք չեն համապատասխանում, կողմնակալ են կամ չեն համապատասխանում մարդկային արժեքներին: Այս անհամապատասխանությունը կարող է դրսևորվել տարբեր ձևերով.
- Վտանգավոր կամ վնասակար բովանդակության ստեղծում
- Անճշտ կամ ապակողմնորոշող տեղեկատվության տրամադրում
- Ուսուցման տվյալների մեջ առկա կողմնակալության դրսևորում
Այս խնդիրները լուծելու համար հետազոտողները մշակել են LLM-ների ճշգրտման մեթոդներ՝ օգտագործելով մարդկային արձագանքը: Այս մոտեցումներից ամենաակնառուը RLHF-ն է:
Հասկանալով RLHF. DPO-ի նախադրյալը
Մարդկային հետադարձ կապից ուժեղացված ուսուցումը (RLHF) եղել է LLM-ների մարդկային նախասիրություններին համապատասխանեցնելու հիմնական մեթոդը: Եկեք քանդենք RLHF գործընթացը՝ հասկանալու դրա բարդությունները.
a) Վերահսկվող ճշգրտում (SFT)Գործընթացը սկսվում է նախապես վերապատրաստված LLM-ի ճշգրտմամբ՝ բարձրորակ պատասխանների տվյալների բազայի վրա: Այս քայլն օգնում է մոդելին ավելի համապատասխան և համահունչ արդյունքներ ստեղծել նպատակային առաջադրանքի համար:
b) Պարգևատրման մոդելավորումԱռանձին պարգևատրման մոդելը պատրաստված է մարդկանց նախասիրությունները կանխատեսելու համար: Սա ներառում է.
- Տրված հուշումների համար պատասխանների զույգերի ստեղծում
- Ունենալով մարդիկ գնահատում են, թե որ արձագանքն են նրանք նախընտրում
- Այս նախապատվությունները կանխատեսելու մոդելի ուսուցում
c) Ամրապնդման ուսուցումՄանրագործված LLM-ն այնուհետև օպտիմիզացվում է ուժեղացման ուսուցման միջոցով: Պարգևատրման մոդելը տրամադրում է հետադարձ կապ՝ ուղղորդելով LLM-ին ստեղծել պատասխաններ, որոնք համահունչ են մարդու նախասիրություններին:
Ահա Python-ի պարզեցված կեղծ կոդ՝ RLHF գործընթացը ցույց տալու համար.
Չնայած արդյունավետությանը, RLHF-ն ունի մի քանի թերություններ.
- Այն պահանջում է ուսուցում և պահպանում բազմաթիվ մոդելներ (SFT, պարգևատրման մոդել և RL-օպտիմիզացված մոդել)
- RL գործընթացը կարող է լինել անկայուն և զգայուն հիպերպարամետրերի նկատմամբ
- Այն հաշվողականորեն թանկ է, պահանջում է բազմաթիվ առաջ և հետընթաց անցումներ մոդելների միջով
Այս սահմանափակումները դրդել են ավելի պարզ, արդյունավետ այլընտրանքների որոնմանը, ինչը հանգեցնում է DPO-ի զարգացմանը:
Ուղղակի նախապատվությունների օպտիմիզացում. հիմնական հասկացություններ

Ուղղակի նախապատվությունների օպտիմիզացում https://arxiv.org/abs/2305.18290
Այս պատկերը հակադրում է LLM-ի արդյունքները մարդկային նախասիրություններին համապատասխանեցնելու երկու հստակ մոտեցումներ՝ ամրապնդման ուսուցում մարդու հետադարձ կապից (RLHF) և ուղղակի նախապատվությունների օպտիմալացում (DPO): RLHF-ն հենվում է պարգևատրման մոդելի վրա՝ լեզվի մոդելի քաղաքականությունն ուղղորդելու համար կրկնվող հետադարձ կապերի միջոցով, մինչդեռ DPO-ն ուղղակիորեն օպտիմիզացնում է մոդելի ելքերը՝ մարդկանց նախընտրած պատասխաններին համապատասխանելու համար՝ օգտագործելով նախապատվության տվյալները: Այս համեմատությունը ընդգծում է յուրաքանչյուր մեթոդի ուժեղ կողմերն ու պոտենցիալ կիրառությունները՝ տրամադրելով պատկերացումներ այն մասին, թե ինչպես կարող են վերապատրաստվել ապագա LLM-ները՝ ավելի լավ համապատասխանեցնելու մարդկային ակնկալիքներին:
DPO-ի հիմքում ընկած հիմնական գաղափարները.
a) Անուղղակի պարգևատրման մոդելավորումDPO-ն վերացնում է առանձին պարգևատրման մոդելի անհրաժեշտությունը՝ լեզվի մոդելը դիտարկելով որպես անուղղակի պարգևատրման գործառույթ:
b) Քաղաքականության վրա հիմնված ձևակերպումՊարգևատրման գործառույթը օպտիմալացնելու փոխարեն, DPO-ն ուղղակիորեն օպտիմիզացնում է քաղաքականությունը (լեզու մոդելը)՝ առավելագույնի հասցնելու նախընտրելի պատասխանների հավանականությունը:
c) Փակ ձևի լուծումDPO-ն օգտագործում է մաթեմատիկական պատկերացում, որը թույլ է տալիս փակ ձևով լուծում տալ օպտիմալ քաղաքականությանը՝ խուսափելով RL-ի կրկնվող թարմացումների անհրաժեշտությունից:
DPO-ի իրականացում. Գործնական օրենսգրքի ուսումնասիրություն
Ստորև բերված պատկերը ցույց է տալիս մի կոդի հատված, որն իրականացնում է DPO կորստի ֆունկցիան՝ օգտագործելով PyTorch-ը: Այս գործառույթը վճռորոշ դեր է խաղում այն բանում, թե ինչպես են լեզվական մոդելները առաջնահերթություն տալիս արդյունքներին՝ հիմնված մարդկային նախասիրությունների վրա: Ահա հիմնական բաղադրիչների բաշխումը.
- Գործառույթի ստորագրությունՄանրամասն
dpo_lossֆունկցիան ընդունում է մի քանի պարամետր, ներառյալ քաղաքականության մատյան հավանականությունները (pi_logps), տեղեկատու մոդելի մատյան հավանականությունները (ref_logps), և նախընտրելի և չնախընտրելի լրացումները ներկայացնող ինդեքսներ (yw_idxs,yl_idxs) Բացի այդ, աbetaպարամետրը վերահսկում է KL տուգանքի ուժը: - Մատյան հավանականության արդյունահանումԾածկագիրը քաղում է նախընտրելի և ոչ նախընտրելի լրացումների գրանցամատյանների հավանականությունները և՛ քաղաքականության, և՛ տեղեկատու մոդելներից:
- Մատյան հարաբերակցության հաշվարկՆախընտրելի և չնախընտրելի լրացումների գրանցամատյանների հավանականությունների միջև տարբերությունը հաշվարկվում է ինչպես քաղաքականության, այնպես էլ հղման մոդելների համար: Այս հարաբերակցությունը կարևոր է օպտիմալացման ուղղությունը և մեծությունը որոշելու համար:
- Կորուստների և պարգևների հաշվարկԿորուստը հաշվարկվում է օգտագործելով
logsigmoidգործառույթը, մինչդեռ պարգևները որոշվում են քաղաքականության և հղման տեղեկամատյանների հավանականությունների միջև տարբերությունը չափավորելովbeta.

DPO կորստի գործառույթ՝ օգտագործելով PyTorch
Եկեք սուզվենք DPO-ի հիմքում ընկած մաթեմատիկայի մեջ՝ հասկանալու համար, թե ինչպես է այն հասնում այս նպատակներին:
DPO-ի մաթեմատիկա
DPO-ն նախընտրելի ուսուցման խնդրի խելացի վերաձեւակերպումն է: Ահա քայլ առ քայլ դասակարգում.
ա) Մեկնարկային կետ. KL- Սահմանափակված պարգևների առավելագույնի հասցում
RLHF-ի սկզբնական նպատակը կարող է արտահայտվել հետևյալ կերպ.
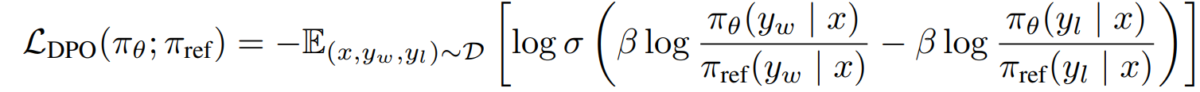
- πθ այն քաղաքականությունն է (լեզվի մոդել), որը մենք օպտիմալացնում ենք
- r(x,y)-ը պարգևատրման ֆունկցիան է
- πref-ը հղման քաղաքականություն է (սովորաբար նախնական SFT մոդելը)
- β-ն վերահսկում է KL դիվերգենցիայի սահմանափակման ուժը
b) Օպտիմալ քաղաքականության ձև. Կարելի է ցույց տալ, որ այս նպատակի համար օպտիմալ քաղաքականությունը ունի հետևյալ ձևը.
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Որտեղ Z(x)-ը նորմալացման հաստատուն է:
c) Պարգևատրում-Քաղաքականություն երկակիություն. DPO-ի հիմնական գաղափարը պարգևատրման գործառույթն օպտիմալ քաղաքականության առումով արտահայտելն է.
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))դ) Նախապատվության մոդել Ենթադրելով, որ նախապատվությունները հետևում են Բրեդլի-Թերի մոդելին, մենք կարող ենք արտահայտել y1-ը y2-ից նախընտրելու հավանականությունը հետևյալ կերպ.
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Որտեղ σ լոգիստիկ ֆունկցիան է:
e) DPO-ի նպատակը Փոխարինելով մեր պարգևատրման-քաղաքականության երկակիությունը նախապատվության մոդելով, մենք հասնում ենք DPO-ի նպատակին.
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Այս նպատակը կարող է օպտիմիզացվել՝ օգտագործելով գրադիենտ վայրէջքի ստանդարտ տեխնիկան՝ առանց RL ալգորիթմների անհրաժեշտության:
DPO-ի իրականացում
Այժմ, երբ մենք հասկանում ենք DPO-ի հիմքում ընկած տեսությունը, եկեք նայենք, թե ինչպես դա իրականացնել գործնականում: Մենք կօգտագործենք Python և PyTorch- ը այս օրինակի համար.
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Մարտահրավերներ և ապագա ուղղություններ
Թեև DPO-ն զգալի առավելություններ է առաջարկում ավանդական RLHF մոտեցումների նկատմամբ, դեռևս կան մարտահրավերներ և ոլորտներ հետագա հետազոտությունների համար.
ա) Ընդարձակություն դեպի ավելի մեծ մոդելներ.
Քանի որ լեզվական մոդելները շարունակում են աճել չափերով, DPO-ի արդյունավետ կիրառումը հարյուր միլիարդավոր պարամետրերով մոդելների վրա մնում է բաց մարտահրավեր: Հետազոտողները ուսումնասիրում են այնպիսի մեթոդներ, ինչպիսիք են.
- Արդյունավետ ճշգրտման մեթոդներ (օրինակ, LoRA, նախածանցային թյունինգ)
- Բաշխված վերապատրաստման օպտիմալացումներ
- Գրադիենտային անցակետ և խառը ճշգրիտ ուսուցում
DPO-ի հետ LoRA-ի օգտագործման օրինակ.
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
բ) Բազմաֆունկցիոնալ և մի քանի կրակոցների հարմարեցում.
Հետազոտության ակտիվ ոլորտ է DPO տեխնիկայի մշակումը, որոնք կարող են արդյունավետ կերպով հարմարվել նոր առաջադրանքներին կամ տիրույթներին սահմանափակ նախապատվությունների տվյալների հետ: Հետազոտվող մոտեցումները ներառում են.
- Մետա-ուսուցման շրջանակներ արագ հարմարվողականության համար
- DPO-ի արագ կարգավորումների վրա հիմնված
- Ուսուցումը ընդհանուր նախապատվության մոդելներից տեղափոխել կոնկրետ տիրույթներ
գ) Ոչ միանշանակ կամ հակասական նախապատվությունների կառավարում.
Իրական աշխարհի նախապատվությունների տվյալները հաճախ պարունակում են անորոշություններ կամ հակասություններ: Նման տվյալների նկատմամբ DPO-ի կայունության բարելավումը շատ կարևոր է: Հնարավոր լուծումները ներառում են.
- Հավանական նախապատվության մոդելավորում
- Անորոշությունները լուծելու ակտիվ ուսուցում
- Բազմագործակալների նախապատվությունների համախմբում
Հավանական նախապատվության մոդելավորման օրինակ.
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
դ) DPO-ի համադրում այլ հավասարեցման տեխնիկայի հետ.
DPO-ի ինտեգրումը հավասարեցման այլ մոտեցումների հետ կարող է հանգեցնել ավելի ամուր և ընդունակ համակարգերի.
- Սահմանադրական AI սկզբունքները հստակ սահմանափակումների բավարարման համար
- Բանավեճ և ռեկուրսիվ պարգևատրման մոդելավորում բարդ նախապատվությունների առաջացման համար
- Հակադարձ ամրապնդման ուսուցում՝ հիմքում ընկած պարգևատրման գործառույթները պարզելու համար
DPO-ն սահմանադրական AI-ի հետ համատեղելու օրինակ.
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Գործնական նկատառումներ և լավագույն պրակտիկա
Իրական աշխարհի հավելվածների համար DPO-ն կիրառելիս հաշվի առեք հետևյալ խորհուրդները.
a) Տվյալների որակըՁեր նախընտրած տվյալների որակը շատ կարևոր է: Համոզվեք, որ ձեր տվյալների բազան՝
- Ընդգրկում է մուտքերի և ցանկալի վարքագծի բազմազան շրջանակ
- Ունի հետևողական և հուսալի նախապատվությունների ծանոթագրություններ
- Հավասարակշռում է տարբեր տեսակի նախապատվություններ (օրինակ՝ փաստացիություն, անվտանգություն, ոճ)
b) Hyperparameter TuningԹեև DPO-ն ունի ավելի քիչ հիպերպարամետրեր, քան RLHF-ը, թյունինգը դեռ կարևոր է.
- β (բետա). Վերահսկում է նախապատվության բավարարման և հղման մոդելից տարբերվելու փոխզիջումը: Սկսեք արժեքներից 0.1-0.5.
- Ուսուցման արագություն. օգտագործեք ավելի ցածր ուսուցման արագություն, քան ստանդարտ ճշգրտումը, սովորաբար տիրույթում 1e-6-ից 1e-5.
- Խմբաքանակի չափը՝ ավելի մեծ խմբաքանակի չափսեր (32-128) հաճախ լավ են աշխատում նախընտրելի ուսուցման համար:
c) Կրկնվող ճշգրտումDPO-ն կարող է կիրառվել կրկնվող՝
- Վերապատրաստեք նախնական մոդելը՝ օգտագործելով DPO
- Ստեղծեք նոր պատասխաններ՝ օգտագործելով վերապատրաստված մոդելը
- Հավաքեք նոր նախապատվությունների տվյալներ այս պատասխանների վերաբերյալ
- Վերապատրաստվել՝ օգտագործելով ընդլայնված տվյալների բազան

Ուղղակի նախապատվությունների օպտիմիզացման կատարողականություն
Այս պատկերը ցույց է տալիս GPT-4-ի նման LLM-ների կատարողականությունը՝ համեմատած մարդկային դատողությունների հետ տարբեր ուսուցման մեթոդների, ներառյալ ուղղակի նախապատվությունների օպտիմիզացում (DPO), վերահսկվող նուրբ կարգավորում (SFT) և մոտակա քաղաքականության օպտիմալացում (PPO): Աղյուսակը ցույց է տալիս, որ GPT-4-ի արդյունքներն ավելի ու ավելի են համընկնում մարդու նախասիրությունների հետ, հատկապես ամփոփման առաջադրանքներում: GPT-4-ի և մարդկանց վերանայողների միջև համաձայնության մակարդակը ցույց է տալիս մոդելի կարողությունը՝ ստեղծելու այնպիսի բովանդակություն, որը ռեզոնանսվում է մարդկային գնահատողների հետ, գրեթե նույնքան սերտորեն, որքան մարդու կողմից ստեղծված բովանդակությունը:
Case Studies and Applications
DPO-ի արդյունավետությունը ցույց տալու համար եկեք դիտարկենք իրական աշխարհի որոշ հավելվածներ և դրա որոշ տարբերակներ.
- Կրկնվող DPOՄշակված Snorkel-ի կողմից (2023), այս տարբերակը համատեղում է մերժման նմուշառումը DPO-ի հետ՝ հնարավորություն տալով ավելի կատարելագործված ընտրության գործընթաց վերապատրաստման տվյալների համար: Նախապատվությունների նմուշառման մի քանի փուլերի վրա կրկնելով՝ մոդելն ավելի լավ է կարողանում ընդհանրացնել և խուսափել աղմկոտ կամ կողմնակալ նախապատվություններին գերհամապատասխանելուց:
- IPO (Կրկնվող նախապատվությունների օպտիմիզացում)Ներկայացրեց Ազարը և ուրիշներ։ (2023 թ.), IPO-ն ավելացնում է կանոնավորացման տերմին՝ կանխարգելելու գերհարմարեցումը, ինչը սովորական խնդիր է նախապատվությունների վրա հիմնված օպտիմալացման մեջ: Այս ընդլայնումը թույլ է տալիս մոդելներին հավասարակշռություն պահպանել նախապատվություններին հետևելու և ընդհանրացման հնարավորությունների պահպանման միջև:
- KTO (Գիտելիքների փոխանցման օպտիմիզացում)Էթայարաջի և այլոց ավելի նոր տարբերակ: (2023), KTO-ն ընդհանրապես հրաժարվում է երկուական նախապատվություններից: Փոխարենը, այն կենտրոնանում է հղման մոդելից դեպի քաղաքականության մոդել գիտելիքի փոխանցման վրա՝ օպտիմալացնելով մարդկային արժեքների հետ ավելի հարթ և հետևողական համապատասխանեցումը:
- Multi-Modal DPO Cross-Domain Learning-ի համար Xu et al. (2024)Մոտեցում, որտեղ DPO-ն կիրառվում է տարբեր եղանակներով՝ տեքստ, պատկեր և աուդիո, ցույց տալով իր բազմակողմանիությունը՝ մոդելները մարդկային նախասիրություններին համապատասխանեցնելու տարբեր տեսակի տվյալների: Այս հետազոտությունը ընդգծում է DPO-ի ներուժը ավելի համապարփակ AI համակարգեր ստեղծելու համար, որոնք կարող են լուծել բարդ, բազմամոդալ առաջադրանքներ:











