
Umjetna inteligencija
YOLOv7: Najnapredniji algoritam za otkrivanje objekata?

6. srpnja 2022. bit će označen kao prekretnica u povijesti umjetne inteligencije jer je na taj dan objavljen YOLOv7. Još od lansiranja, YOLOv7 je najvruća tema u zajednici programera računalnog vida, i to iz pravih razloga. YOLOv7 se već smatra prekretnicom u industriji otkrivanja objekata.
Nedugo poslije Objavljen je rad YOLOv7, pokazao se kao najbrži i najprecizniji model za otkrivanje prigovora u stvarnom vremenu. Ali kako YOLOv7 nadmašuje svoje prethodnike? Što YOLOv7 čini tako učinkovitim u obavljanju zadataka računalnog vida?
U ovom ćemo članku pokušati analizirati YOLOv7 model i pokušati pronaći odgovor zašto YOLOv7 sada postaje industrijski standard? Ali prije nego što možemo odgovoriti na to pitanje, morat ćemo pogledati kratku povijest otkrivanja objekata.
Što je otkrivanje objekata?
Detekcija objekata grana je računalnog vida koji identificira i locira objekte na slici ili videodatoteci. Detekcija objekata sastavni je dio brojnih aplikacija, uključujući samovozeće automobile, nadzirani nadzor, pa čak i robotiku.
Model detekcije objekta može se klasificirati u dvije različite kategorije, jednostruki detektori, i detektori s više hitaca.
Detekcija objekata u stvarnom vremenu
Da bismo doista razumjeli kako YOLOv7 funkcionira, bitno je da razumijemo glavni cilj YOLOv7, “Detekcija objekata u stvarnom vremenu”. Detekcija objekata u stvarnom vremenu ključna je komponenta modernog računalnog vida. Modeli za otkrivanje objekata u stvarnom vremenu pokušavaju identificirati i locirati objekte od interesa u stvarnom vremenu. Modeli detekcije objekata u stvarnom vremenu omogućili su razvojnim programerima stvarno učinkovito praćenje objekata od interesa u pokretnom okviru poput videa ili ulaza za nadzor uživo.

Modeli detekcije objekata u stvarnom vremenu su u biti korak ispred konvencionalnih modela detekcije slike. Dok se prvi koristi za praćenje objekata u video datotekama, drugi locira i identificira objekte unutar stacionarnog okvira poput slike.
Kao rezultat toga, modeli detekcije objekata u stvarnom vremenu stvarno su učinkoviti za video analitiku, autonomna vozila, brojanje objekata, praćenje više objekata i još mnogo toga.
Što je YOLO?
YOLO ili "Gledaš samo jednom” je obitelj modela detekcije objekata u stvarnom vremenu. Koncept YOLO prvi je predstavio 2016. godine Joseph Redmon i gotovo istog trena se počelo pričati o njemu jer je bio puno brži i točniji od postojećih algoritama za detekciju objekata. Nije prošlo dugo prije nego što je YOLO algoritam postao standard u industriji računalnog vida.

Temeljni koncept koji predlaže YOLO algoritam je korištenje end-to-end neuronske mreže pomoću graničnih okvira i vjerojatnosti klase za izradu predviđanja u stvarnom vremenu. YOLO se razlikovao od prethodnog modela otkrivanja objekata u smislu da je predlagao drugačiji pristup za izvođenje otkrivanja objekata mijenjanjem namjene klasifikatora.
Promjena u pristupu je uspjela jer je YOLO ubrzo postao industrijski standard jer je razlika u performansama između sebe i drugih algoritama za otkrivanje objekata u stvarnom vremenu bila značajna. Ali koji je bio razlog zašto je YOLO bio tako učinkovit?
U usporedbi s YOLO-om, tada su algoritmi za otkrivanje objekata koristili mreže prijedloga regija za otkrivanje mogućih područja od interesa. Proces prepoznavanja je zatim izveden za svaku regiju zasebno. Kao rezultat toga, ti su modeli često izvodili višestruke iteracije na istoj slici, a otuda nedostatak točnosti i duže vrijeme izvršenja. S druge strane, YOLO algoritam koristi jedan potpuno povezani sloj za izvođenje predviđanja odjednom.
Kako radi YOLO?
Postoje tri koraka koji objašnjavaju kako radi YOLO algoritam.
Reframing Object Detection kao problem pojedinačne regresije
Korištenje električnih romobila ističe YOLO algoritam pokušava preoblikovati otkrivanje objekta kao pojedinačni regresijski problem, uključujući piksele slike, do vjerojatnosti klase i koordinate graničnog okvira. Stoga algoritam mora pogledati sliku samo jednom kako bi predvidio i locirao ciljne objekte na slikama.
Globalno obrazlaže sliku
Nadalje, kada algoritam YOLO daje predviđanja, on sliku globalno obrazlaže. Razlikuje se od tehnika koje se temelje na prijedlogu regije i klizećih tehnika jer YOLO algoritam vidi cjelovitu sliku tijekom obuke i testiranja skupa podataka i može kodirati kontekstualne informacije o klasama i načinu na koji se pojavljuju.
Prije YOLO-a, Fast R-CNN bio je jedan od najpopularnijih algoritama za otkrivanje objekata koji nije mogao vidjeti širi kontekst na slici jer je pozadinske mrlje na slici znao zamijeniti za objekt. U usporedbi s Fast R-CNN algoritmom, YOLO je 50% precizniji kada je riječ o pozadinskim pogreškama.
Generalizira prikaz objekata
Konačno, algoritam YOLO također ima za cilj generalizirati prikaze objekata na slici. Kao rezultat toga, kada je YOLO algoritam pokrenut na skupu podataka s prirodnim slikama i testiran za rezultate, YOLO je znatno nadmašio postojeće R-CNN modele. To je zato što je YOLO vrlo generaliziran, šanse da se pokvari kada se implementira na neočekivanim unosima ili novim domenama bile su male.
YOLOv7: Što je novo?
Sada kada imamo osnovno razumijevanje o tome što su modeli detekcije objekata u stvarnom vremenu i što je YOLO algoritam, vrijeme je da razgovaramo o YOLOv7 algoritmu.
Optimiziranje procesa obuke
YOLOv7 algoritam ne samo da pokušava optimizirati arhitekturu modela, već također ima za cilj optimizirati proces obuke. Cilj mu je korištenje optimizacijskih modula i metoda za poboljšanje točnosti otkrivanja objekata, povećanje troškova obuke, uz zadržavanje troškova smetnji. Ovi optimizacijski moduli mogu se nazvati a trainable bag of freebies.
Grubo do fino olovno vođeno dodjeljivanje oznaka
Algoritam YOLOv7 planira koristiti novu dodjelu vođene oznake od grubog do finog olova umjesto konvencionalnog Dodjela dinamičke oznake. To je tako jer s dinamičkim dodjeljivanjem oznaka, obučavanje modela s više izlaznih slojeva uzrokuje neke probleme, a najčešći od njih je kako dodijeliti dinamičke ciljeve za različite grane i njihove izlaze.
Ponovna parametrizacija modela
Re-parametrizacija modela važan je koncept u detekciji objekata, a njegovu upotrebu općenito prate neki problemi tijekom obuke. YOLOv7 algoritam planira koristiti koncept put širenja gradijenta za analizu politike re-parametrizacije modela primjenjiv na različite slojeve u mreži.
Proširi i spoji skaliranje
YOLOv7 algoritam također predstavlja proširene i složene metode skaliranja koristiti i učinkovito koristiti parametre i proračune za otkrivanje objekata u stvarnom vremenu.

YOLOv7 : Srodni rad
Detekcija objekata u stvarnom vremenu
YOLO je trenutačno industrijski standard, a većina detektora objekata u stvarnom vremenu koristi YOLO algoritme i FCOS (potpuno konvolucijsko jednostupanjsko otkrivanje objekata). Najsuvremeniji detektor objekata u stvarnom vremenu obično ima sljedeće karakteristike
- Jača i brža mrežna arhitektura.
- Učinkovita metoda integracije značajki.
- Točna metoda otkrivanja objekata.
- Robusna funkcija gubitka.
- Učinkovita metoda dodjele oznaka.
- Učinkovita metoda treninga.
YOLOv7 algoritam ne koristi samonadzirane metode učenja i destilacije koje često zahtijevaju velike količine podataka. Suprotno tome, algoritam YOLOv7 koristi metodu vrećice besplatnih proizvoda koja se može obučiti.
Ponovna parametrizacija modela
Tehnike re-parametrizacije modela smatraju se tehnikama ansambla koje spajaju višestruke računalne module u fazi interferencije. Tehnika se dalje može podijeliti u dvije kategorije, ansambl na razini modela, i ansambl na razini modula.
Sada, za dobivanje konačnog modela interferencije, tehnika reparametrizacije na razini modela koristi dvije prakse. Prva praksa koristi različite podatke o obuci za obuku brojnih identičnih modela, a zatim izračunava prosjek težine obučenih modela. Alternativno, druga praksa izračunava prosjek težine modela tijekom različitih iteracija.
Re-parametrizacija na razini modula u posljednje vrijeme dobiva ogromnu popularnost jer dijeli modul na različite grane modula ili različite identične grane tijekom faze obuke, a zatim nastavlja s integracijom tih različitih grana u ekvivalentni modul tijekom interferencije.
Međutim, tehnike ponovne parametrizacije ne mogu se primijeniti na sve vrste arhitekture. To je razlog zašto je YOLOv7 algoritam koristi nove tehnike re-parametrizacije modela za dizajniranje povezanih strategija pogodan za različite arhitekture.
Skaliranje modela
Skaliranje modela je proces povećanja ili smanjenja postojećeg modela tako da odgovara različitim računalnim uređajima. Skaliranje modela općenito koristi različite čimbenike poput broja slojeva (dubina), veličina ulaznih slika (rezolucija), broj piramida značajki (faza), i broj kanala (širina). Ovi čimbenici igraju ključnu ulogu u osiguravanju uravnoteženog kompromisa za mrežne parametre, brzinu smetnji, izračunavanje i točnost modela.
Jedna od najčešće korištenih metoda skaliranja je NAS ili traženje mrežne arhitekture koji automatski traži odgovarajuće faktore skaliranja iz tražilica bez ikakvih kompliciranih pravila. Glavni nedostatak korištenja NAS-a je taj što je to skup pristup za traženje prikladnih faktora skaliranja.
Gotovo svaki model ponovne parametrizacije modela neovisno analizira pojedinačne i jedinstvene faktore skaliranja, i nadalje, čak neovisno optimizira te faktore. To je zato što NAS arhitektura radi s faktorima skaliranja koji nisu u korelaciji.
Vrijedno je napomenuti da modeli koji se temelje na ulančavanju poput VoVNet or DenseNet promijenite ulaznu širinu nekoliko slojeva kada se skalira dubina modela. YOLOv7 radi na predloženoj arhitekturi koja se temelji na ulančavanju i stoga koristi složenu metodu skaliranja.

Gore navedena slika uspoređuje proširene učinkovite mreže agregacije slojeva (E-ELAN) različitih modela. Predložena E-ELAN metoda održava gradijentni prijenosni put izvorne arhitekture, ali ima za cilj povećanje kardinalnosti dodanih značajki korištenjem grupne konvolucije. Proces može poboljšati značajke koje su naučile različite karte i dodatno može učiniti upotrebu izračuna i parametara učinkovitijom.
YOLOv7 Arhitektura
Model YOLOv7 koristi modele YOLOv4, YOLO-R i Scaled YOLOv4 kao svoju bazu. YOLOv7 rezultat je eksperimenata provedenih na ovim modelima kako bi se poboljšali rezultati i model učinio preciznijim.
Proširena učinkovita mreža agregacije slojeva ili E-ELAN
E-ELAN je temeljni građevni element modela YOLOv7, a izveden je iz već postojećih modela učinkovitosti mreže, uglavnom ELAN.
Glavna razmatranja pri projektiranju učinkovite arhitekture su broj parametara, gustoća računanja i količina izračuna. Drugi modeli također uzimaju u obzir čimbenike poput utjecaja omjera ulazno/izlaznih kanala, grana u arhitektonskoj mreži, brzine interferencije mreže, broja elemenata u tenzorima konvolucijske mreže i više.
Korištenje električnih romobila ističe CSPVoNet model ne samo da uzima u obzir gore navedene parametre, već također analizira putanju gradijenta kako bi saznao više različitih značajki omogućavajući težine različitih slojeva. Pristup omogućuje da smetnje budu puno brže i točnije. The ELAN Arhitektura ima za cilj dizajniranje učinkovite mreže za kontrolu najkraće najduže gradijentne staze tako da mreža može biti učinkovitija u učenju i konvergenciji.
ELAN je već dosegao stabilnu fazu bez obzira na broj slaganja računalnih blokova i duljinu puta gradijenta. Stabilno stanje može biti uništeno ako se računski blokovi neograničeno slažu, a stopa iskorištenja parametara će se smanjiti. The predložena E-ELAN arhitektura može riješiti problem jer koristi kardinalnost proširenja, miješanja i spajanja za kontinuirano poboljšanje mrežne sposobnosti učenja uz zadržavanje izvorne putanje gradijenta.
Nadalje, kada se uspoređuje arhitektura E-ELAN-a s ELAN-om, jedina razlika je u računskom bloku, dok je arhitektura prijelaznog sloja nepromijenjena.
E-ELAN predlaže proširenje kardinalnosti računskih blokova i proširenje kanala korištenjem skupna konvolucija. Karta značajki će se zatim izračunati i pomiješati u grupe prema parametru grupe, a zatim će se spojiti zajedno. Broj kanala u svakoj grupi ostat će isti kao u originalnoj arhitekturi. Na kraju, grupe karti značajki bit će dodane za izvođenje kardinalnosti.
Skaliranje modela za modele temeljene na ulančavanju
Skaliranje modela pomaže u podešavanje atributa modela koji pomaže u generiranju modela prema zahtjevima i različitih razmjera kako bi se zadovoljile različite brzine smetnji.

Slika govori o skaliranju modela za različite modele koji se temelje na ulančavanju. Kao što možete na slici (a) i (b), izlazna širina računskog bloka raste s povećanjem skaliranja dubine modela. Kao rezultat, ulazna širina prijenosnih slojeva je povećana. Ako su ove metode implementirane na arhitekturu koja se temelji na ulančavanju, proces skaliranja izvodi se dubinski, a prikazan je na slici (c).
Stoga se može zaključiti da nije moguće neovisno analizirati faktore skaliranja za modele koji se temelje na ulančavanju, već ih se mora razmatrati ili analizirati zajedno. Stoga, za model koji se temelji na ulančavanju, prikladno je koristiti odgovarajuću metodu skaliranja složenog modela. Dodatno, kada se faktor dubine skalira, mora se skalirati i izlazni kanal bloka.
Torba besplatnih poklona koja se može trenirati
Vreća besplatnih proizvoda izraz je koji programeri koriste za opisivanje skup metoda ili tehnika koje mogu promijeniti strategiju ili cijenu obuke u pokušaju povećanja točnosti modela. Dakle, koje su to vrećice besplatnih stvari koje se mogu trenirati u YOLOv7? Pogledajmo.
Planirana re-parametrizirana konvolucija
YOLOv7 algoritam koristi gradijentne staze širenja protoka za određivanje kako idealno kombinirati mrežu s re-parametriziranom konvolucijom. Ovaj pristup YOLov7 je pokušaj suprotstavljanja RepConv algoritam koji, iako je radio mirno na modelu VGG, ima loše rezultate kada se izravno primijeni na modele DenseNet i ResNet.
Da bi se identificirale veze u konvolucijskom sloju, RepConv algoritam kombinira 3×3 konvoluciju i 1×1 konvoluciju. Ako analiziramo algoritam, njegovu izvedbu i arhitekturu primijetit ćemo da RepConv uništava ulančavanje u DenseNet, a ostatak u ResNet.

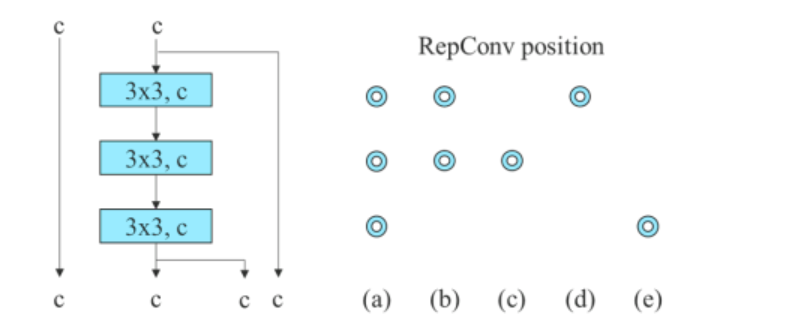
Gornja slika prikazuje planirani re-parametrizirani model. Može se vidjeti da je algoritam YOLov7 utvrdio da sloj u mreži s ulančanim ili rezidualnim vezama ne bi trebao imati vezu identiteta u algoritmu RepConv. Kao rezultat toga, prihvatljivo je prebacivanje s RepConvN bez povezivanja identiteta.
Grubo za pomoćno i fino za gubitak olova
Duboki nadzor je grana računalne znanosti koja se često koristi u procesu obuke dubokih mreža. Temeljno načelo dubokog nadzora je da ono dodaje dodatnu pomoćnu glavu u srednjim slojevima mreže zajedno s plitkim mrežnim težinama s pomoćnim gubitkom kao vodičem. YOLOv7 algoritam se odnosi na glavu koja je odgovorna za konačni rezultat kao vodeću glavu, a pomoćna glava je glava koja pomaže u obuci.
Idući dalje, YOLOv7 koristi drugu metodu za dodjelu oznaka. Konvencionalno, dodjela oznaka se koristi za generiranje oznaka pozivajući se izravno na temeljnu istinu i na temelju zadanog skupa pravila. Međutim, posljednjih godina distribucija i kvaliteta unosa predviđanja igraju važnu ulogu u stvaranju pouzdane oznake. YOLOv7 generira meku oznaku objekta korištenjem predviđanja graničnog okvira i temeljne istine.
Nadalje, nova metoda dodjele oznaka algoritma YOLOv7 koristi predviđanja glave elektrode za vođenje i elektrode i pomoćne glave. Metoda dodjele oznaka ima dvije predložene strategije.
Glavni vođeni dodjeljivač etiketa
Strategija izrađuje izračune na temelju rezultata predviđanja vodeće glave i temeljne istine, a zatim koristi optimizaciju za generiranje mekih oznaka. Te se meke oznake zatim koriste kao model za obuku i za glavnu glavu i za pomoćnu glavu.
Strategija radi na pretpostavci da, budući da vodeća glava ima veću sposobnost učenja, oznake koje generira trebaju biti reprezentativnije i korelirati između izvora i cilja.
Dodjeljivač naljepnica s vođenom glavom od grubo do fino
Ova strategija također vrši izračune na temelju rezultata predviđanja vodeće glave i temeljne istine, a zatim koristi optimizaciju za generiranje mekih oznaka. Međutim, postoji ključna razlika. U ovoj strategiji postoje dva skupa mekih oznaka, gruba razina, i fina oznaka.
Gruba oznaka se stvara popuštanjem ograničenja pozitivnog uzorka
proces dodjele koji više rešetki tretira kao pozitivne ciljeve. To je učinjeno kako bi se izbjegao rizik od gubitka informacija zbog slabije snage učenja pomoćne glave.

Gornja slika objašnjava upotrebu vrećice besplatnih proizvoda koja se može trenirati u algoritmu YOLOv7. Prikazuje grubo za pomoćnu glavu, a fino za olovnu glavu. Kada usporedimo model s pomoćnom glavom (b) s normalnim modelom (a), primijetit ćemo da shema u (b) ima pomoćnu glavu, dok je nema u (a).
Slika (c) prikazuje uobičajeni neovisni dodjeljivač oznaka dok slika (d) i slika (e) redom predstavljaju glavni vođeni dodjeljivač i glavni vođeni dodjeljivač od grubog do finog koji koristi YOLOv7.
Druga vrećica besplatnih poklona koja se može trenirati
Uz gore spomenute, YOLOv7 algoritam koristi dodatne vrećice besplatnih proizvoda, iako ih izvorno nisu predložili. Oni su
- Normalizacija serije u tehnologiji Conv-Bn-Activation: Ova se strategija koristi za izravno povezivanje konvolucijskog sloja sa slojem normalizacije serije.
- Implicitno znanje u YOLOR-u: YOLOv7 kombinira strategiju s mapom konvolucijskih značajki.
- EMA model: EMA model se koristi kao konačni referentni model u YOLOv7 iako se njegova primarna upotreba koristi u metodi srednjeg učitelja.
YOLOv7 : Eksperimenti
Eksperimentalno postavljanje
YOLOv7 algoritam koristi Skup podataka Microsoft COCO za obuku i provjeru valjanosti njihov model detekcije objekta, a ne koriste svi ovi eksperimenti unaprijed obučeni model. Programeri su upotrijebili skup podataka o vlaku iz 2017. za obuku, a za odabir hiperparametara upotrijebili su skup podataka za validaciju iz 2017. Konačno, izvedba rezultata detekcije objekata YOLOv7 uspoređuje se s najsuvremenijim algoritmima za detekciju objekata.
Programeri su dizajnirali osnovni model za edge GPU (YOLOv7-tiny), normalni GPU (YOLOv7) i cloud GPU (YOLOv7-W6). Nadalje, algoritam YOLOv7 također koristi osnovni model za skaliranje modela prema različitim zahtjevima usluge i dobiva različite modele. Za algoritam YOLOv7 skaliranje hrpe vrši se na vratu, a predloženi spojevi koriste se za povećanje dubine i širine modela.
Polazne crte
Algoritam YOLOv7 koristi prethodne modele YOLO i algoritam za otkrivanje objekata YOLOR kao osnovnu liniju.

Gornja slika uspoređuje osnovnu liniju modela YOLOv7 s drugim modelima detekcije objekata, a rezultati su prilično očiti. U usporedbi s YOLOv4 algoritam, YOLOv7 ne samo da koristi 75% manje parametara, već također koristi 15% manje računanja i ima 0.4% veću točnost.
Usporedba s najsuvremenijim modelima detektora objekata

Gornja slika prikazuje rezultate kada se YOLOv7 uspoređuje s najsuvremenijim modelima detekcije objekata za mobilne i opće GPU-ove. Može se uočiti da metoda koju predlaže algoritam YOLOv7 ima najbolji rezultat kompromisa između brzine i točnosti.
Studija ablacije: predložena metoda skaliranja spojeva

Gornja slika uspoređuje rezultate korištenja različitih strategija za povećanje modela. Strategija skaliranja u modelu YOLOv7 povećava dubinu računskog bloka za 1.5 puta, a širinu za 1.25 puta.
U usporedbi s modelom koji samo povećava dubinu, model YOLOv7 radi bolje za 0.5% uz korištenje manje parametara i računalne snage. S druge strane, u usporedbi s modelima koji povećavaju samo dubinu, točnost YOLOv7 je poboljšana za 0.2%, ali broj parametara treba skalirati za 2.9%, a izračunavanje za 1.2%.
Predloženi planirani re-parametrizirani model
Kako bi potvrdio općenitost svog predloženog re-parametriziranog modela, YOLOv7 algoritam koristi ga na modelima koji se temelje na ostatku i ulančavanju za provjeru. Za postupak verifikacije koristi se YOLOv7 algoritam 3-složni ELAN za model koji se temelji na ulančavanju i CSPDarknet za model koji se temelji na ostatku.
Za model koji se temelji na ulančavanju, algoritam zamjenjuje konvolucijske slojeve 3×3 u ELAN-u s 3 hrpe s RepConv. Slika u nastavku prikazuje detaljnu konfiguraciju Planned RepConv-a i 3-složnog ELAN-a.
Nadalje, kada se radi s modelom temeljenim na ostatku, algoritam YOLOv7 koristi obrnuti tamni blok jer izvorni tamni blok nema 3×3 blok konvolucije. Donja slika prikazuje arhitekturu obrnutog CSPDarkneta koji mijenja položaje 3×3 i 1×1 konvolucijskog sloja. 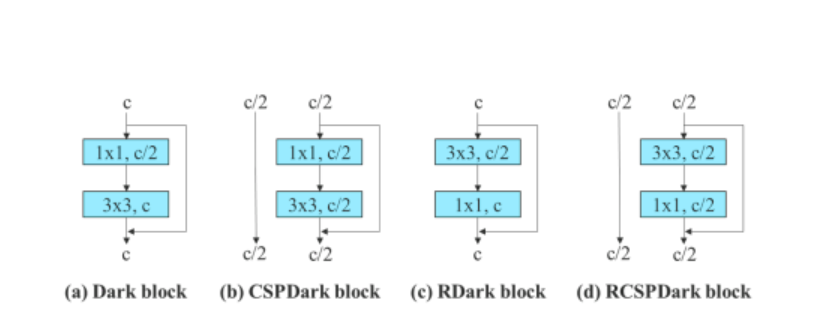
Predloženi gubitak pomoćnika za pomoćnog voditelja
Za pomoćni gubitak za pomoćnu glavu, model YOLOv7 uspoređuje nezavisnu dodjelu oznaka za metode pomoćne glave i vodeće glave.

Gornja slika sadrži rezultate studije o predloženoj pomoćnoj glavi. Može se vidjeti da se ukupna izvedba modela povećava s povećanjem pomoćnog gubitka. Nadalje, dodjela oznaka vođena voditeljem koju predlaže YOLOv7 model ima bolju izvedbu od neovisnih strategija dodjele voditelja.
YOLOv7 Rezultati
Na temelju gornjih eksperimenata, ovo je rezultat izvedbe YOLov7 u usporedbi s drugim algoritmima za otkrivanje objekata.

Gornja slika uspoređuje model YOLOv7 s drugim algoritmima za otkrivanje objekata i može se jasno uočiti da YOLOv7 nadmašuje druge modele za otkrivanje prigovora u smislu Prosječna preciznost (AP) v/s skupne smetnje.
Nadalje, donja slika uspoređuje performanse YOLOv7 u odnosu na druge algoritme za otkrivanje prigovora u stvarnom vremenu. Još jednom, YOLOv7 nasljeđuje druge modele u pogledu ukupnih performansi, točnosti i učinkovitosti.

Evo nekih dodatnih zapažanja iz rezultata i izvedbe YOLOv7.
- YOLOv7-Tiny je najmanji model u YOLO obitelji, s preko 6 milijuna parametara. YOLOv7-Tiny ima prosječnu preciznost od 35.2% i nadmašuje YOLOv4-Tiny modele s usporedivim parametrima.
- Model YOLOv7 ima preko 37 milijuna parametara i nadmašuje modele s višim parametrima poput YOLov4.
- Model YOLOv7 ima najveći mAP i FPS stopu u rasponu od 5 do 160 FPS.
Zaključak
YOLO ili You Only Look Once je najsuvremeniji model detekcije objekata u modernom računalnom vidu. YOLO algoritam je poznat po svojoj visokoj točnosti i učinkovitosti, i kao rezultat toga, nalazi široku primjenu u industriji detekcije objekata u stvarnom vremenu. Otkako je prvi YOLO algoritam predstavljen 2016. godine, eksperimenti su omogućili programerima da kontinuirano poboljšavaju model.
Model YOLOv7 najnoviji je dodatak u obitelji YOLO i najmoćniji je algoritam YOLo do danas. U ovom smo članku govorili o osnovama YOLOv7 i pokušali objasniti što YOLOv7 čini tako učinkovitim.















