
Umjetna inteligencija
Strojno učenje protiv dubokog učenja – ključne razlike
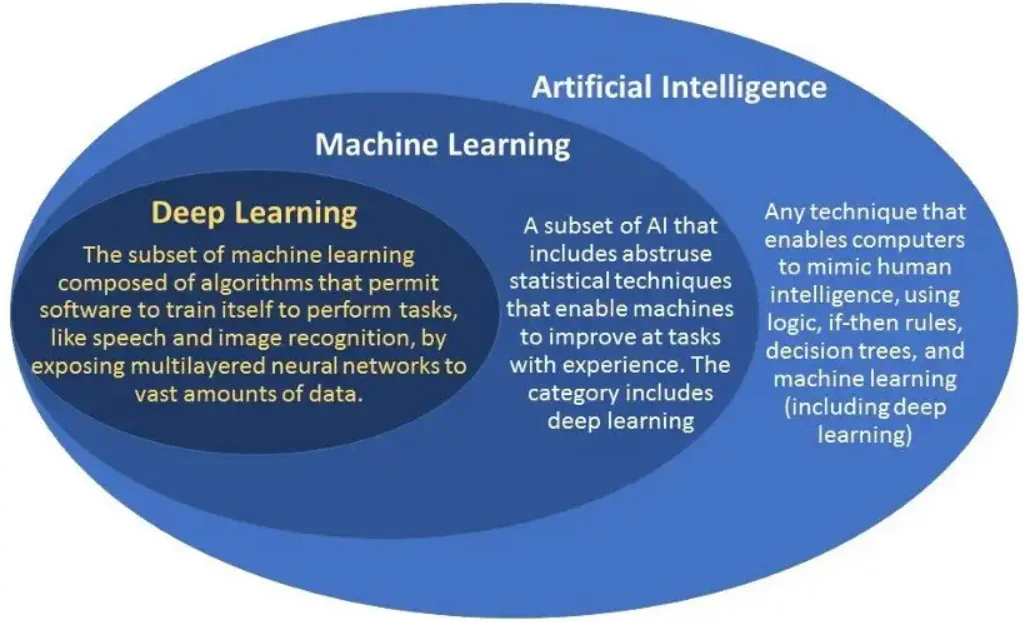
Terminologije kao što su Umjetna inteligencija (AI), Strojno učenje (ML) i Duboko učenje ovih su dana popularne. Ljudi, međutim, često koriste te pojmove naizmjenično. Iako su ovi izrazi u velikoj mjeri povezani jedni s drugima, oni također imaju različite značajke i specifične slučajeve upotrebe.
AI se bavi automatiziranim strojevima koji rješavaju probleme i donose odluke oponašajući ljudske kognitivne sposobnosti. Strojno učenje i dubinsko učenje poddomene su umjetne inteligencije. Strojno učenje je umjetna inteligencija koja može davati predviđanja uz minimalnu ljudsku intervenciju. Dok je duboko učenje podskup strojnog učenja koje koristi neuronske mreže za donošenje odluka oponašanjem neuronskih i kognitivnih procesa ljudskog uma.
Gornja slika ilustrira hijerarhiju. Nastavit ćemo s objašnjavanjem razlika između strojnog i dubokog učenja. Također će vam pomoći odabrati odgovarajuću metodologiju na temelju njezine primjene i područja fokusa. Raspravljajmo o tome detaljno.
Strojno učenje ukratko
Strojno učenje omogućuje stručnjacima da "treniraju" stroj tako što će ga tjerati da analizira ogromne skupove podataka. Što više podataka stroj analizira, točnije rezultate može proizvesti donošenjem odluka i predviđanja za neviđene događaje ili scenarije.
Modeli strojnog učenja trebaju strukturirane podatke za donošenje točnih predviđanja i odluka. Ako podaci nisu označeni i organizirani, modeli strojnog učenja ne uspijevaju ih točno shvatiti i oni postaju domena dubokog učenja.
Dostupnost golemih količina podataka u organizacijama učinila je strojno učenje sastavnom komponentom donošenja odluka. Motori za preporuke savršen su primjer modela strojnog učenja. OTT usluge poput Netflixa uče vaše postavke sadržaja i predlažu sličan sadržaj na temelju vaših navika pretraživanja i povijesti gledanja.
Razumjeti kako se obučavaju modeli strojnog učenja, prvo pogledajmo vrste ML-a.
Postoje četiri vrste metodologija u strojnom učenju.
- Nadzirano učenje – potrebni su označeni podaci kako bi se dobili točni rezultati. Često zahtijeva učenje više podataka i povremene prilagodbe kako bi se poboljšali rezultati.
- Polu-nadzirano – To je srednja razina između nadziranog i nenadziranog učenja koja pokazuje funkcionalnost obje domene. Može dati rezultate na djelomično označenim podacima i ne zahtijeva stalne prilagodbe da bi se dobili točni rezultati.
- Učenje bez nadzora – otkriva obrasce i uvide u skupovima podataka bez ljudske intervencije i daje točne rezultate. Grupiranje je najčešća primjena učenja bez nadzora.
- Učenje s potkrepljenjem – Model učenja s potkrepljenjem zahtijeva stalne povratne informacije ili potkrepljenje kako nove informacije dolaze kako bi dale točne rezultate. Također koristi "Funkciju nagrađivanja" koja omogućuje samoučenje nagrađivanjem željenih rezultata i kažnjavanjem pogrešnih.
Duboko učenje ukratko
Modeli strojnog učenja zahtijevaju ljudsku intervenciju kako bi se poboljšala točnost. Naprotiv, modeli dubokog učenja sami se poboljšavaju nakon svakog rezultata bez ljudskog nadzora. Ali često zahtijeva detaljnije i duže količine podataka.
Metodologija dubokog učenja dizajnira sofisticirani model učenja temeljen na neuronskim mrežama inspiriranim ljudskim umom. Ovi modeli imaju više slojeva algoritama koji se nazivaju neuroni. Oni se nastavljaju poboljšavati bez ljudske intervencije, poput kognitivnog uma koji se neprestano poboljšava i razvija s praksom, ponovnim posjetama i vremenom.
Modeli dubokog učenja uglavnom se koriste za klasifikaciju i izdvajanje značajki. Na primjer, duboki modeli se hrane skupom podataka u prepoznavanju lica. Model stvara višedimenzionalne matrice za pamćenje svake crte lica kao piksela. Kada ga zamolite da prepozna sliku osobe kojoj nije bio izložen, on je lako prepoznaje podudaranjem ograničenih crta lica.
- Konvolucijske neuronske mreže (CNN) – Konvolucija je proces dodjele težine različitim objektima slike. Na temelju ovih dodijeljenih težina, CNN model to prepoznaje. Rezultati se temelje na tome koliko su ti utezi blizu težini objekta koji se hrani kao vlak.
- Rekurentna neuronska mreža (RNN) – Za razliku od CNN-a, RNN model preispituje prethodne rezultate i podatkovne točke kako bi donio točnije odluke i predviđanja. To je stvarna replika ljudske kognitivne funkcije.
- Generativne kontradiktorne mreže (GAN) – dva klasifikatora u GAN-u, generator i diskriminator, pristupaju istim podacima. Generator proizvodi lažne podatke uključivanjem povratne informacije od diskriminatora. Diskriminator pokušava klasificirati jesu li dati podaci stvarni ili lažni.
Istaknute razlike
U nastavku su neke značajne razlike.
| Razlike | Strojno učenje | Duboko učenje |
| Ljudski nadzor | Strojno učenje zahtijeva više nadzora. | Modeli dubokog učenja ne zahtijevaju gotovo nikakav ljudski nadzor nakon razvoja. |
| Hardverski resursi | Izrađujete i pokrećete programe strojnog učenja na snažnom CPU-u. | Modeli dubokog učenja zahtijevaju snažniji hardver, poput namjenskih GPU-ova. |
| Vrijeme i trud | Vrijeme potrebno za postavljanje modela strojnog učenja manje je nego za duboko učenje, ali je njegova funkcionalnost ograničena. | Za razvoj i obuku podataka s dubokim učenjem potrebno je više vremena. Nakon što se stvori, s vremenom nastavlja poboljšavati svoju točnost. |
| Podaci (strukturirani/nestrukturirani) | Modeli strojnog učenja trebaju strukturirane podatke da bi dali rezultate (osim učenja bez nadzora) i zahtijevaju kontinuiranu ljudsku intervenciju za poboljšanje. | Modeli dubokog učenja mogu obraditi nestrukturirane i složene skupove podataka bez ugrožavanja točnosti. |
| Slučajevi upotrebe | Web-mjesta za e-trgovinu i usluge strujanja koje koriste mehanizme za preporuke. | Vrhunske aplikacije poput autopilota u zrakoplovima, samovozećih vozila, rovera na površini Marsa, prepoznavanja lica itd. |
Strojno učenje naspram dubokog učenja – koje je najbolje?
Izbor između strojnog učenja i dubinskog učenja uistinu se temelji na njihovim slučajevima upotrebe. Oba se koriste za izradu strojeva s inteligencijom gotovo ljudskom. Točnost oba modela ovisi o tome koristite li relevantne KPI-jeve i atribute podataka.
Strojno učenje i duboko učenje postat će rutinske poslovne komponente u svim industrijama. Bez sumnje, umjetna inteligencija će u skoroj budućnosti potpuno automatizirati industrijske aktivnosti poput zrakoplovstva, ratovanja i automobila.
Ako želite saznati više o umjetnoj inteligenciji io tome kako kontinuirano mijenja poslovne rezultate, pročitajte više članaka na ujediniti.ai.















