בינה מלאכותית
אימון מודלים של ראייה ממוחשבת על רעש אקראי במקום תמונות אמיתיות

חוקרים ממעבדת המחשב והבינה המלאכותית של MIT (CSAIL) ניסו להשתמש בתמונות רעש אקראי בנתונים של ראייה ממוחשבת כדי לאמן מודלים של ראייה ממוחשבת, וגילו שבמקום לייצר “זבל”, השיטה היא במפתיע מאוד יעילה:

Generative models from the experiment, sorted by performance. Source: https://openreview.net/pdf?id=RQUl8gZnN7O
הזנת ‘אשפה חזותית’ לארכיטקטורות ראייה ממוחשבת פופולריות לא אמורה להוביל לסוג כזה של ביצועים. בצד הימני של התמונה לעיל, העמודות השחורות מייצגות ציונים (ב Imagenet-100) עבור ארבעה ‘נתונים אמיתיים’. בעוד ש-‘נתוני רעש אקראי’ (המצוירים בצבעים שונים, ראו אינדקס בחלק השמאלי העליון) לא יכולים להשוות לזה, הם כמעט כולם בתוך גבולות נאותים עליונים ותחתונים (קווים מפוספסים אדומים) לדיוק.
במובן זה ‘דיוק’ לא אומר שתוצאה בהכרח נראית כמו פנים, כנסייה, פיצה, או כל תחום אחר שאתה עשוי להיות מעוניין ליצור מערכת סינתזת תמונות, כגון רשת יריבות גנרטיבית, או מסגרת מקודד / פוענח.
במקום זאת, זה אומר שמודלי CSAIL הפיקו ‘אמיתות’ מרכזיות רחבות שימוש מנתוני תמונה כל כך לא מובנים, שלא אמורים להיות מסוגלים לספק אותם.
גיוון Vs. טבעיות
תוצאות אלו לא יכולות להיות מיוחסות ל over-fitting: דיון חי בין המחברים והביקורתים ב-Open Review מראה כי ערבוב תוכן שונה מנתונים חזותיים מגוונים (כגון ‘עלים מתים’, ‘פרקטלים’ ו-‘רעש פרוצדורלי’ – ראו תמונה להלן) לנתוני אימון משפר את הדיוק בניסויים אלו.
זה מרמז (וזה מושג מהפכני מעט) על סוג חדש של ‘under-fitting’, שבו ‘גיוון’ גובר על ‘טבעיות’.
The project page for the initiative lets you interactively view the different types of random image datasets used in the experiment. Source: https://mbaradad.github.io/learning_with_noise/
התוצאות שהתקבלו על ידי החוקרים מעלות בספק את היחס הבסיסי בין רשתות נוירונים חזותיות ל’תמונות העולם האמיתי’ שנזרקות עליהן בכמויות הולכות וגדלות כל שנה, ומרמזות כי הצורך לרכוש, לנהל ולטפל ב נתוני תמונות בקנה מידה היפר עשוי להפוך למיותר. המחברים טוענים:
‘מערכות ראייה נוכחיות מאומנות על נתונים עצומים, ונתונים אלו באים עם עלויות: ניהול היא יקרה, הם יורשים הטיות אנושיות, וישנן דאגות בנוגע לפרטיות וזכויות שימוש. כדי להתמודד עם העלויות האלו, עלה העניין בלמידה ממקורות נתונים זולים יותר, כגון תמונות לא מסומנות.
‘במאמר זה, אנו הולכים צעד אחד רחוק יותר ושואלים אם ניתן לוותר על נתוני תמונות אמיתיים לחלוטין, על ידי למידה מתהליכי רעש פרוצדורליים.’
החוקרים מציעים כי הארכיטקטורות הנוכחיות של למידת מכונה עשויות להסיק משהו הרבה יותר יסודי (או, לפחות, בלתי צפוי) מתמונות מאשר שנחשב קודם, וכי ‘תמונות חסרות משמעות’ יכולות להעביר כמות גדולה של ידע זה, באופן זול יותר, אפילו עם השימוש האפשרי בנתונים סינתטיים אד הוק, דרך ארכיטקטורות יצירת נתונים שיוצרות תמונות אקראיות בזמן אימון:
‘אנו מזהים שני מאפיינים חשובים שהופכים נתונים סינתטיים לטובים לאימון מערכות ראייה: 1) טבעיות, 2) גיוון. באופן מעניין, הנתונים הטבעיים ביותר אינם תמיד הטובים ביותר, מכיוון שטבעיות יכולה לבוא על חשבון גיוון.
‘העובדה שנתונים טבעיים עוזרים אינה מפתיעה, והיא מרמזת כי אכן, נתונים אמיתיים בקנה מידה גדול הם בעלי ערך. אולם, אנו מוצאים כי מה שחשוב הוא לא שהנתונים יהיו אמיתיים אלא שהם יהיו טבעיים, כלומר, הם חייבים ללכוד מספר תכונות מבניות של נתונים אמיתיים.
‘רבות מתכונות אלו יכולות להילכד במודלים פשוטים של רעש.’

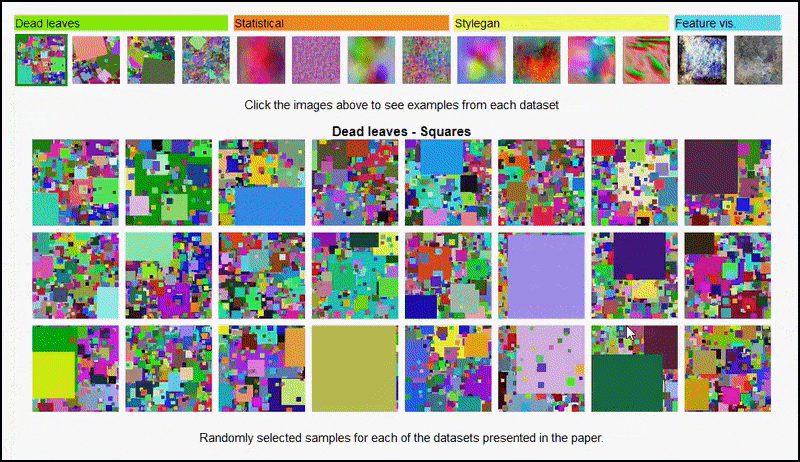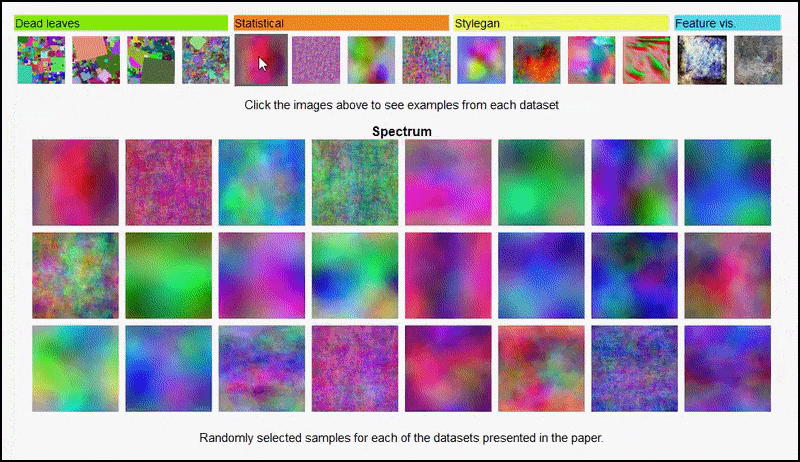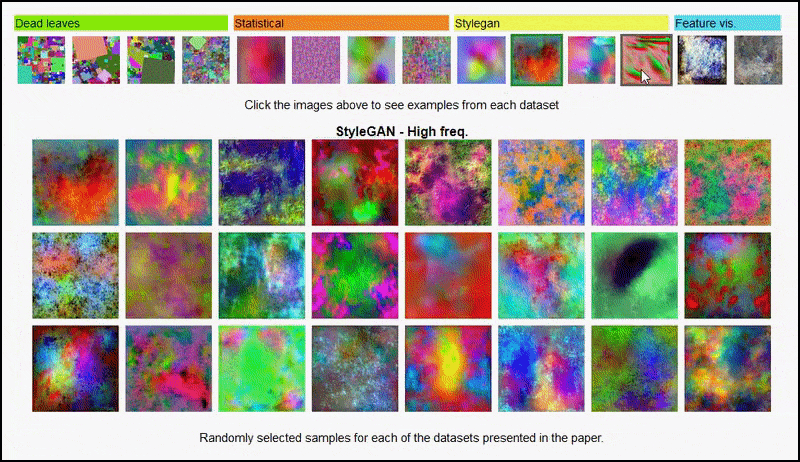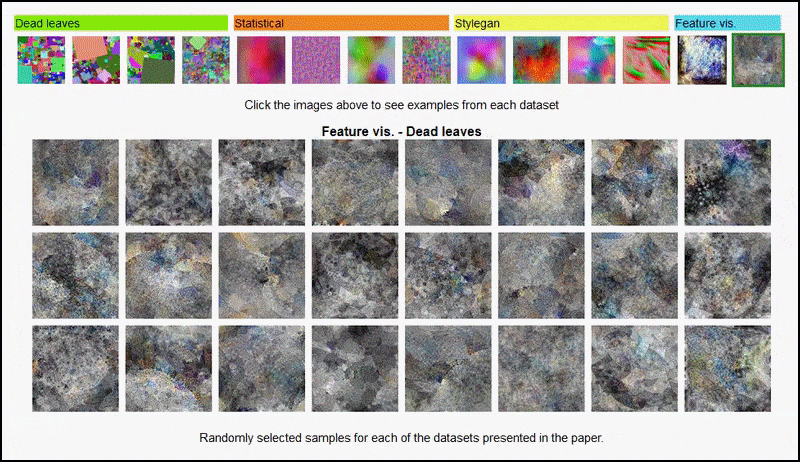
Feature visualizations resulting from an AlexNet-derived encoder on some of the various ‘random image’ datasets used by the authors, covering the 3rd and 5th (final) convolutional layer. The methodology used here follows that set out in Google AI research from 2017.
ה מאמר, שהוצג בכנס ה-35 על עיבוד מידע עצבי (NeurIPS 2021) בסידני, נקרא ללמוד לראות על ידי הסתכלות על רעש, ומגיע משישה חוקרים ב-CSAIL, עם תרומה שווה.
העבודה הומלצה על ידי קונצנזוס לבחירת ספוטלייט ב-NeurIPS 2021, עם פרשנים שאפיינו את המאמר כ’פריצת דרך מדעית’ שפותחת ‘תחום לימודי גדול’, אפילו אם היא מעלה כמה שאלות כמו שהיא עונה.
במאמר, המחברים מסכמים:
‘הראינו כי, כאשר מעוצבים באמצעות תוצאות ממחקר קודם על סטטיסטיקה של תמונות טבעיות, נתונים אלו יכולים לאמן בהצלחה ייצוגים חזותיים. אנו מקווים כי מאמר זה יעודד את לימודם של מודלים גנרטיביים חדשים המסוגלים לייצר רעש מובנה המשיג הישגים גבוהים יותר כאשר הם משמשים במגוון רחב של משימות חזותיות.
‘האם ניתן להשוות את הביצועים שהושגו עם אימון על ImageNet? אולי בהיעדר סט אימון גדול מיוחד למשימה מסוימת, האימון הטוב ביותר אינו בהכרח השימוש בנתונים אמיתיים סטנדרטיים כגון ImageNet.’












