Modèles et plateformes d’IA
Non, ils n’étaient pas en train de limiter Claude – C’était encore pire

Très bien, discutons de ce qui s’est passé avec Claude, car si vous l’avez utilisé au cours du dernier mois, vous avez probablement remarqué que quelque chose n’allait pas.
Pendant six semaines, les utilisateurs de Claude ont perdu la tête. Début août, des plaintes ont commencé à inonder Reddit, X et les forums de développeurs. Les problèmes étaient partout :
- Le code qui fonctionnait parfaitement était soudainement cassé
- Claude prétendait avoir apporté des modifications à des fichiers alors qu’il ne l’avait pas fait
- Des caractères thaïs ou chinois apparaissaient aléatoirement dans les réponses en anglais
- Les instructions étaient complètement ignorées
- La même invite donnait des réponses de qualité très différentes
- Les utilisateurs de Claude Code disaient qu’il se sentait “lobotomisé” par rapport à avant
Les plaintes sont devenues si graves que fin août, les gens étaient convaincus qu’Anthropic limitait secrètement Claude pour économiser de l’argent. Les théories du complot étaient partout – peut-être qu’ils réduisaient la qualité pendant les heures de pointe, peut-être qu’ils avaient discrètement remplacé le modèle par un moins cher, peut-être que cette dégradation intentionnelle était destinée à gérer les coûts du serveur.
Les utilisateurs payaient pour Claude Pro et obtenaient ce qui ressemblait à Claude Lite. Les développeurs qui avaient construit des flux de travail autour de Claude voyaient soudainement leur productivité chuter. Cependant, certains utilisateurs n’ont rencontré aucun problème, ce qui rendait tout plus confus.
Anthropic Admet Enfin : Oui, Nous Avions Des Problèmes
Après des semaines de plaintes d’utilisateurs et de frustration croissante, Anthropic vient de publier un rapport post-mortem technique massif qui dit essentiellement : “Vous aviez raison. Claude était cassé. Voici ce qui s’est passé.”
Et la réponse est intéressante.
Il s’est avéré que ce n’était pas un problème. C’étaient trois bogues d’infrastructure complètement séparés, tous se produisant en même temps, créant une tempête parfaite de dégradation de l’IA. Ils ne limitaient pas. Ils ne faisaient pas d’角es. Ils avaient simplement trois choses cassées simultanément de manière à ce qu’il leur fallait six semaines pour les comprendre et les réparer.
Laissez-moi détailler exactement ce qui s’est passé, car c’est vraiment un regard utile sur la façon dont ces systèmes d’IA peuvent échouer de manière inattendue.
La Triple-Bogue : Une Chronologie Du Chaos
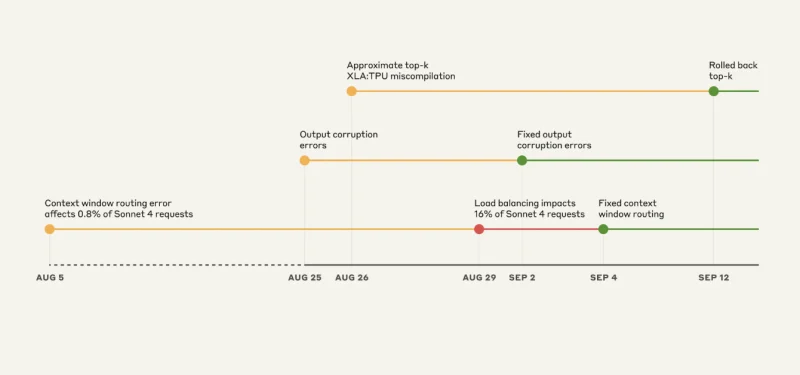
Source : Anthropic
Bogue #1 : Le Problème De Serveur
C’est presque drôle si vous n’étiez pas celui qui l’a vécu. Claude Sonnet 4 était conçu pour gérer 200 000 contextes de jetons. Mais à partir du 5 août, certaines requêtes étaient acheminées vers des serveurs configurés pour 1 million de contextes de jetons.
Initialement, seuls 0,8 % des requêtes étaient affectées. Pas de problème, n’est-ce pas ? Faux.
Le 29 août, une mise à jour de routine du load balancer a transformé ce problème mineur en un problème majeur. Soudain, à son apogée, 16 % des requêtes Sonnet 4 étaient acheminées vers les mauvais serveurs. Et l’acheminement était “collant”. Une fois que vous étiez mal acheminé, vous restiez mal acheminé.
L’impact :
- Environ 30 % des utilisateurs de Claude Code qui étaient actifs pendant la période avaient au moins une requête mal acheminée
- Les temps de réponse ont chuté pour les utilisateurs affectés
- Le même utilisateur a connu le problème à plusieurs reprises tandis que d’autres n’ont eu aucun problème
Bogue #2 : Le Générateur De Caractères Aléatoires
Le 25 août, Anthropic a déployé une mauvaise configuration sur ses serveurs TPU. Le résultat était que Claude insérait aléatoirement des caractères thaïs et chinois dans les réponses en anglais.
Imaginez demander à Claude de déboguer votre code Python et obtenir ceci :
def calculate_total(items) :
total = 0
for item in items :
總計 += item.price # <- Qu'est-ce que c'est ?
return ผลรวม
Cela a affecté :
- Opus 4.1 et Opus 4 : 25-28 août
- Sonnet 4 : 25 août – 2 septembre
La cause technique était une erreur de génération de jetons qui attribuait une probabilité élevée à des caractères qui n’avaient pas lieu d’être là. Cela a littéralement cassé le mécanisme fondamental de la façon dont Claude sélectionne le mot suivant à dire.
Bogue #3 : Le Bogue De Compilateur Invisible
C’est le plus effrayant du point de vue de l’ingénierie. Il y avait un bogue latent dans le compilateur XLA de Google qui était resté dormant. Lorsqu’Anthropic a déployé du code pour améliorer la sélection de jetons le 25 août, ils ont accidentellement déclenché ce bogue.
Ce que ce bogue faisait était vraiment bizarre – il faisait en sorte que Claude exclue involontairement le jeton le plus probable lors de la génération de texte. Claude connaissait la bonne réponse, mais était physiquement empêché de la dire.
La partie vraiment dérangée ? Ils avaient déjà contourné ce bogue en décembre 2024 sans s’en rendre compte. Lorsqu’ils ont “réparé” ce qu’ils pensaient être la cause profonde en août, ils ont supprimé le contournement et déclenché le véritable problème.
Pourquoi Il A Fallu Six Semaines Pour Réparer
Vous vous demandez peut-être : comment une entreprise comme Anthropic, avec des ingénieurs de classe mondiale, peut mettre six semaines pour résoudre ce problème ?
La réponse révèle à quel point ces systèmes sont vraiment complexes :
1. Les Contrôles De Confidentialité Bloquaient Le Débogage
“Nos contrôles internes de confidentialité et de sécurité limitent la façon dont et quand les ingénieurs peuvent accéder aux interactions des utilisateurs avec Claude, en particulier lorsque ces interactions ne sont pas signalées à nous comme des commentaires.”
Ils ne pouvaient littéralement pas voir ce qui se cassait à moins que les utilisateurs ne le signalent explicitement avec des commentaires. C’est bien pour la confidentialité, mais terrible pour le débogage.
2. Les Bogues Se Cachaient
Claude récupérait souvent de ses erreurs individuelles, faisant que la dégradation ressemblait à une variance normale plutôt qu’à une défaillance systématique. Leurs benchmarks et évaluations ne détectaient pas cela, car le modèle se corrigeait suffisamment pour passer les tests.
3. Chaos Multi-Plateformes
Claude s’exécute sur AWS Trainium, NVIDIA GPUs et Google TPUs – trois plateformes matérielles complètement différentes. Chaque bogue se manifestait différemment sur chaque plateforme :
- AWS Bedrock : 0,18 % des requêtes Sonnet 4 affectées à l’apogée
- Google Vertex AI : en dessous de 0,0004 % affectées
- API directe : jusqu’à 16 % affectées
Cela faisait apparaître plusieurs problèmes sans rapport les uns avec les autres plutôt que trois bogues spécifiques.
4. Symptômes Chevauchants
Avec trois bogues actifs simultanément, les symptômes étaient partout. Un utilisateur pouvait obtenir des caractères thaïs, un autre pouvait obtenir des réponses dégradées, un troisième pouvait voir des performances parfaites. Il n’y avait pas de modèle clair à suivre.
Ce Que Cela Signifie Vraiment Pour La Fiabilité De L’IA
Cette histoire révèle quelque chose d’essentiel sur l’état actuel des systèmes d’IA : ils sont beaucoup plus fragiles qu’ils ne le semblent.
Nous ne parlons pas seulement du modèle d’IA lui-même. Nous parlons de :
- L’infrastructure de routage qui peut envoyer des requêtes à la mauvaise place
- Les implémentations matérielles spécifiques qui se comportent différemment
- Les bogues de compilateur qui peuvent rester dormants pendant des mois
- Les équilibreurs de charge qui peuvent amplifier les problèmes mineurs en pannes majeures
Une mauvaise configuration, un bogue de compilateur, une erreur de routage – et soudain, votre assistant d’IA oublie comment coder ou commence à parler des langues qu’il ne devrait pas.
Est-Ce Vraiment Réparé ?
Anthropic dit qu’ils ont résolu les trois problèmes le 16 septembre. Ils ont :
- Réparé la logique de routage
- Rétabli les configurations problématiques
- Passé des opérations top-k approximatives à des opérations top-k exactes (en prenant un coup de performance pour la précision)
- Ajouté une surveillance continue en production
Mais les utilisateurs signalent toujours des problèmes. Certains développeurs prétendent que Claude Code se sent encore dégradé par rapport à ses performances antérieures. Que ce soit :
- Des effets résiduels des bogues
- De nouveaux problèmes qui n’ont pas été identifiés
- Un biais psychologique après des semaines de problèmes
- Ou une dégradation réelle continue
… nous ne le savons pas encore.
Le Fond De L’Affaire
Cette situation est un cas d’étude parfait sur la façon dont les systèmes d’IA complexes peuvent échouer de manière complètement inattendue. Trois bogues distincts, tous déclenchés dans les semaines qui suivent, ont créé une perception de dégradation massive de la qualité qui a pris six semaines pour être diagnostiquée et réparée.
Nous pouvons donner du crédit à Anthropic pour la transparence. Publier un rapport post-mortem technique détaillé est plus que ce que la plupart des entreprises feraient. Mais cela montre également à quel point les choses peuvent mal tourner sous le capot de ces systèmes sur lesquels nous comptons de plus en plus.
Pour quiconque construit sur Claude ou tout LLM : vous avez besoin de redondance, de validation et de plans de secours. Parce que, comme nous venons de le voir, même les meilleurs systèmes d’IA peuvent avoir trois problèmes simultanément, et il peut falloir des semaines avant que quelqu’un découvre ce qui se passe réellement.
L’infrastructure qui soutient ces modèles d’IA est tout aussi importante que les modèles eux-mêmes. Et en ce moment, cette infrastructure montre des douleurs de croissance sérieuses.












