Intelligence Artificielle
Optimisation des préférences directes : un guide complet

Aligner les grands modèles linguistiques (LLM) avec les valeurs et préférences humaines est un défi. Les méthodes traditionnelles, telles que Apprentissage par renforcement à partir de la rétroaction humaine (RLHF), ont ouvert la voie en intégrant les apports humains pour affiner les résultats du modèle. Cependant, le RLHF peut être complexe et gourmand en ressources, nécessitant une puissance de calcul et un traitement de données importants. Optimisation des préférences directes L'approche DPO (Digital Progressive Processing) apparaît comme une approche innovante et rationalisée, offrant une alternative efficace aux méthodes traditionnelles. En simplifiant le processus d'optimisation, l'approche DPO réduit non seulement la charge de calcul, mais améliore également la capacité du modèle à s'adapter rapidement aux préférences humaines.
Dans ce guide, nous allons approfondir le sujet du DPO, en explorant ses fondements, sa mise en œuvre et ses applications pratiques.
La nécessité d’un alignement des préférences
Pour comprendre le DPO, il est essentiel de comprendre l'importance d'aligner les LLM sur les préférences humaines. Malgré leurs capacités impressionnantes, les LLM formés sur de vastes ensembles de données peuvent parfois produire des résultats incohérents, biaisés ou non conformes aux valeurs humaines. Ce décalage peut se manifester de différentes manières :
- Générer du contenu dangereux ou nuisible
- Fournir des informations inexactes ou trompeuses
- Présenter des biais présents dans les données d'entraînement
Pour résoudre ces problèmes, les chercheurs ont développé des techniques permettant d’affiner les LLM à l’aide de la rétroaction humaine. La plus importante de ces approches est la RLHF.
Comprendre le RLHF : le précurseur du DPO
L'apprentissage par renforcement à partir du feedback humain (RLHF) est la méthode de référence pour aligner les LLM sur les préférences humaines. Analysons le processus RLHF pour en comprendre la complexité :
a) Réglage fin supervisé (SFT): Le processus commence par affiner un LLM pré-entraîné sur un ensemble de données de réponses de haute qualité. Cette étape aide le modèle à générer des résultats plus pertinents et cohérents pour la tâche cible.
b) Modélisation de récompense: Un modèle de récompense distinct est formé pour prédire les préférences humaines. Cela implique :
- Générer des paires de réponses pour des invites données
- Demander aux humains d'évaluer la réponse qu'ils préfèrent
- Entraîner un modèle pour prédire ces préférences
c) Apprentissage par renforcement: Le LLM affiné est ensuite optimisé davantage à l'aide de l'apprentissage par renforcement. Le modèle de récompense fournit des commentaires, guidant le LLM pour générer des réponses qui correspondent aux préférences humaines.
Voici un pseudo-code Python simplifié pour illustrer le processus RLHF :
Bien qu’efficace, le RLHF présente plusieurs inconvénients :
- Cela nécessite la formation et la maintenance de plusieurs modèles (SFT, modèle de récompense et modèle optimisé pour RL)
- Le processus RL peut être instable et sensible aux hyperparamètres
- C'est coûteux en termes de calcul, car cela nécessite de nombreux passages en avant et en arrière dans les modèles.
Ces limites ont motivé la recherche d’alternatives plus simples et plus efficaces, conduisant au développement du DPO.
Optimisation des préférences directes : concepts de base

Optimisation des préférences directes https://arxiv.org/abs/2305.18290
Cette image met en contraste deux approches distinctes pour aligner les résultats des LLM sur les préférences humaines : l'apprentissage par renforcement à partir du feedback humain (RLHF) et l'optimisation directe des préférences (DPO). Le RLHF s'appuie sur un modèle de récompense pour guider la politique du modèle linguistique via des boucles de rétroaction itératives, tandis que l'DPO optimise directement les résultats du modèle pour qu'ils correspondent aux réponses préférées des humains à l'aide de données de préférences. Cette comparaison met en évidence les points forts et les applications potentielles de chaque méthode, offrant un aperçu de la manière dont les futurs LLM pourraient être formés pour mieux s'adapter aux attentes humaines.
Les idées clés derrière le DPO :
a) Modélisation implicite des récompenses: DPO élimine le besoin d'un modèle de récompense distinct en traitant le modèle de langage lui-même comme une fonction de récompense implicite.
b) Formulation basée sur des politiques: Au lieu d'optimiser une fonction de récompense, DPO optimise directement la politique (modèle linguistique) pour maximiser la probabilité de réponses préférées.
c) Solution de forme fermée: DPO exploite une vision mathématique qui permet d'élaborer une solution fermée pour la politique optimale, évitant ainsi le besoin de mises à jour itératives du RL.
Implémentation du DPO : une présentation pratique du code
L'image ci-dessous présente un extrait de code implémentant la fonction de perte DPO avec PyTorch. Cette fonction joue un rôle crucial dans l'amélioration de la façon dont les modèles de langage priorisent les sorties en fonction des préférences humaines. Voici une description de ses principaux composants :
- Signature de fonction: Les
dpo_lossla fonction prend en compte plusieurs paramètres, notamment les probabilités du journal de stratégie (pi_logps), probabilités du journal du modèle de référence (ref_logps), et des indices représentant les achèvements préférés et défavorisés (yw_idxs,yl_idxs). De plus, unbetaLe paramètre contrôle la force de la pénalité KL. - Extraction de probabilité de journal: Le code extrait les probabilités de journal pour les achèvements préférés et non préférés des modèles de politique et de référence.
- Calcul du rapport logarithmique: La différence entre les probabilités logarithmiques des achèvements préférés et dépréciés est calculée à la fois pour les modèles de politique et de référence. Ce ratio est essentiel pour déterminer la direction et l’ampleur de l’optimisation.
- Calcul des pertes et des récompenses: La perte est calculée à l'aide du
logsigmoidfonction, tandis que les récompenses sont déterminées en mettant à l'échelle la différence entre les probabilités de la politique et du journal de référence parbeta.

Fonction de perte DPO à l'aide de PyTorch
Plongeons dans les mathématiques derrière DPO pour comprendre comment il atteint ces objectifs.
Les mathématiques du DPO
Le DPO est une reformulation astucieuse du problème d'apprentissage des préférences. Voici une description détaillée :
a) Point de départ : maximisation des récompenses sous contrainte KL
L’objectif initial du RLHF peut être exprimé comme suit :
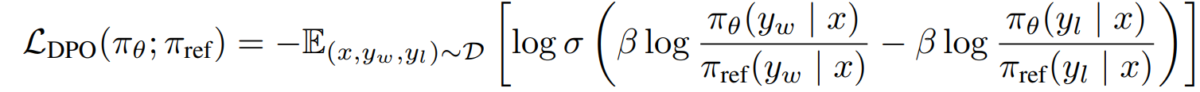
- πθ est la politique (modèle de langage) que nous optimisons
- r(x,y) est la fonction de récompense
- πref est une politique de référence (généralement le modèle SFT initial)
- β contrôle la force de la contrainte de divergence KL
b) Forme de politique optimale : On peut montrer que la politique optimale pour cet objectif prend la forme :
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Où Z(x) est une constante de normalisation.
c) Dualité récompense-politique : L’idée clé du DPO est d’exprimer la fonction de récompense en termes de politique optimale :
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Modèle de préférence En supposant que les préférences suivent le modèle Bradley-Terry, nous pouvons exprimer la probabilité de préférer y1 à y2 comme suit :
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Où σ est la fonction logistique.
e) Objectif du DPO En substituant notre dualité récompense-politique dans le modèle de préférence, nous arrivons à l’objectif DPO :
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Cet objectif peut être optimisé à l’aide de techniques standard de descente de gradient, sans avoir besoin d’algorithmes RL.
Implémentation du DPO
Maintenant que nous avons compris la théorie du DPO, voyons comment le mettre en pratique. Nous utiliserons Python PyTorch pour cet exemple:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Défis et orientations futures
Bien que le DPO offre des avantages significatifs par rapport aux approches RLHF traditionnelles, il existe encore des défis et des domaines nécessitant des recherches plus approfondies :
a) Évolutivité vers des modèles plus grands :
Alors que la taille des modèles de langage continue de croître, l’application efficace de DPO à des modèles comportant des centaines de milliards de paramètres reste un défi ouvert. Les chercheurs explorent des techniques telles que :
- Méthodes de réglage efficaces (par exemple, LoRA, réglage des préfixes)
- Optimisations de la formation distribuée
- Points de contrôle de gradient et entraînement à précision mixte
Exemple d'utilisation de LoRA avec DPO :
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adaptation multi-tâches et à quelques prises de vue :
Le développement de techniques DPO capables de s'adapter efficacement à de nouvelles tâches ou domaines avec des données de préférence limitées est un domaine de recherche actif. Les approches explorées comprennent :
- Cadres de méta-apprentissage pour une adaptation rapide
- Réglage fin basé sur des invites pour DPO
- Transférer l'apprentissage des modèles de préférences générales vers des domaines spécifiques
c) Gestion des préférences ambiguës ou contradictoires :
Les données de préférences réelles comportent souvent des ambiguïtés ou des conflits. Il est crucial d'améliorer la fiabilité des données du DPO. Parmi les solutions possibles, on peut citer :
- Modélisation probabiliste des préférences
- Apprentissage actif pour résoudre les ambiguïtés
- Agrégation de préférences multi-agents
Exemple de modélisation probabiliste des préférences :
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combinaison du DPO avec d'autres techniques d'alignement :
L’intégration du DPO avec d’autres approches d’alignement pourrait conduire à des systèmes plus robustes et plus performants :
- Principes constitutionnels de l'IA pour la satisfaction explicite des contraintes
- Modélisation de débats et de récompenses récursives pour l’élicitation de préférences complexes
- Apprentissage par renforcement inverse pour déduire les fonctions de récompense sous-jacentes
Exemple de combinaison de DPO avec une IA constitutionnelle :
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Considérations pratiques et meilleures pratiques
Lors de la mise en œuvre du DPO pour des applications réelles, tenez compte des conseils suivants :
a) Qualité des données: La qualité de vos données de préférences est cruciale. Assurez-vous que votre ensemble de données :
- Couvre une gamme diversifiée d’entrées et de comportements souhaités
- Possède des annotations de préférences cohérentes et fiables
- Équilibre différents types de préférences (par exemple, factualité, sécurité, style)
b) Réglage des hyperparamètres: Bien que DPO ait moins d'hyperparamètres que RLHF, le réglage est toujours important :
- β (bêta) : contrôle le compromis entre la satisfaction des préférences et la divergence par rapport au modèle de référence. Commencez par des valeurs autour 0.1-0.5.
- Taux d'apprentissage : utilisez un taux d'apprentissage inférieur à celui du réglage fin standard, généralement de l'ordre de 1e-6 à 1e-5.
- Taille du lot : tailles de lots plus grandes (32-128) fonctionnent souvent bien pour l’apprentissage des préférences.
c) Raffinement itératif: DPO peut être appliqué de manière itérative :
- Former un modèle initial à l'aide de DPO
- Générez de nouvelles réponses à l'aide du modèle formé
- Collecter de nouvelles données de préférences sur ces réponses
- Réentraîner à l'aide de l'ensemble de données étendu

Performances d’optimisation des préférences directes
Cette image illustre les performances de LLM comme GPT-4 par rapport aux jugements humains selon diverses techniques d'apprentissage, notamment l'optimisation directe des préférences (DPO), le réglage fin supervisé (SFT) et l'optimisation des politiques proximales (PPO). Le tableau révèle que les résultats de GPT-4 sont de plus en plus alignés sur les préférences humaines, notamment dans les tâches de synthèse. Le niveau de concordance entre GPT-4 et les évaluateurs humains démontre la capacité du modèle à générer du contenu qui résonne auprès des évaluateurs humains, presque aussi étroitement que le contenu généré par les humains.
Études de cas et applications
Pour illustrer l’efficacité du DPO, examinons quelques applications concrètes et certaines de ses variantes :
- DPO itératif: Développée par Snorkel (2023), cette variante combine l'échantillonnage par rejet avec le DPO, permettant un processus de sélection plus raffiné pour les données d'entraînement. En itérant sur plusieurs cycles d'échantillonnage des préférences, le modèle est mieux à même de généraliser et d'éviter le surajustement à des préférences bruyantes ou biaisées.
- Introduction en bourse (Optimisation itérative des préférences): Introduit par Azar et al. (2023), IPO ajoute un terme de régularisation pour éviter le surajustement, qui est un problème courant dans l'optimisation basée sur les préférences. Cette extension permet aux modèles de maintenir un équilibre entre le respect des préférences et la préservation des capacités de généralisation.
- KTO (Optimisation du transfert de connaissances): Une variante plus récente d'Ethayarajh et al. (2023), KTO renonce complètement aux préférences binaires. Au lieu de cela, il se concentre sur le transfert de connaissances d’un modèle de référence vers le modèle politique, en optimisant pour un alignement plus fluide et plus cohérent avec les valeurs humaines.
- DPO multimodal pour l'apprentissage inter-domaines par Xu et al. (2024): Une approche où le DPO est appliqué à travers différentes modalités (texte, image et audio) démontrant sa polyvalence dans l'alignement des modèles avec les préférences humaines sur divers types de données. Cette recherche met en évidence le potentiel du DPO dans la création de systèmes d’IA plus complets, capables de gérer des tâches complexes et multimodales.












