Intelligence artificielle
Édition d’objets assistée par IA avec Imagic de Google et ‘Erase and Replace’ de Runway

Cette semaine, deux nouveaux algorithmes graphiques à base d’IA, mais contrastés, offrent des moyens novateurs pour que les utilisateurs finals apportent des modifications très précises et efficaces aux objets dans les photos.
Le premier est Imagic, de Google Research, en association avec l’Institut de technologie d’Israël et l’Institut de science Weizmann. Imagic propose une édition fine et conditionnée par du texte d’objets via l’ajustement fin des modèles de diffusion.

Changez ce que vous aimez, et laissez le reste – Imagic promet une édition granulaire de seules les parties que vous souhaitez modifier. Source : https://arxiv.org/pdf/2210.09276.pdf
Quiconque a déjà essayé de modifier un seul élément dans une réédition de Stable Diffusion sait trop bien que pour chaque édition réussie, le système modifiera cinq choses que vous aimiez telles qu’elles étaient. C’est une lacune qui a actuellement de nombreux des plus talentueux enthousiastes de SD à constamment faire des aller-retour entre Stable Diffusion et Photoshop, pour réparer ce type de « dégâts collatéraux ». De ce point de vue seul, les réalisations d’Imagic semblent notables.
À l’heure de l’écriture, Imagic manque encore d’une vidéo promotionnelle, et, étant donné l’attitude circonspecte de Google à l’égard de la publication d’outils de synthèse d’images non bridés, il est incertain dans quelle mesure, le cas échéant, nous aurons la chance de tester le système.
La deuxième offre est la fonction Erase and Replace plus accessible de Runway ML, une nouvelle fonctionnalité dans la section « Outils de magie IA » de son ensemble exclusivement en ligne d’utilitaires d’effets visuels basés sur l’apprentissage automatique.
La fonction Erase and Replace de Runway ML, déjà vue dans une prévisualisation d’un système d’édition de vidéo à partir de texte. Source : https://www.youtube.com/watch?v=41Qb58ZPO60
Examinons d’abord la version de Runway.
Erase and Replace
Comme Imagic, Erase and Replace traite exclusivement des images fixes, bien que Runway ait prévisualisé la même fonctionnalité dans une solution d’édition de vidéo à partir de texte qui n’est pas encore publiée :

Bien que n’importe qui puisse tester la nouvelle fonction Erase and Replace sur des images, la version vidéo n’est pas encore disponible au public. Source : https://twitter.com/runwayml/status/1568220303808991232
Runway ML n’a pas publié de détails sur les technologies derrière Erase and Replace, mais la vitesse à laquelle vous pouvez substituer une plante d’intérieur à une effigie convaincante de Ronald Reagan suggère qu’un modèle de diffusion tel que Stable Diffusion (ou, beaucoup moins probable, un DALL-E 2 sous licence) est le moteur qui réinvente l’objet de votre choix dans Erase and Replace.

Remplacer une plante d’intérieur par une effigie du Gipper n’est pas tout à fait aussi rapide que cela, mais c’est assez rapide. Source : https://app.runwayml.com/
Le système a certaines restrictions de type DALL-E 2 – les images ou le texte qui déclenchent les filtres Erase and Replace déclencheront un avertissement sur une possible suspension de compte en cas de nouvelles infractions – pratiquement un clone de la politique de OpenAI pour DALL-E 2.
De nombreux résultats manquent des bords rugueux typiques de Stable Diffusion. Runway ML sont des investisseurs et des partenaires de recherche dans SD, et il est possible qu’ils aient formé un modèle propriétaire supérieur au point de repère ouvert 1.4 que nous utilisons actuellement (comme de nombreux autres groupes de développement, amateurs et professionnels, forment ou affinent actuellement des modèles de diffusion stables).
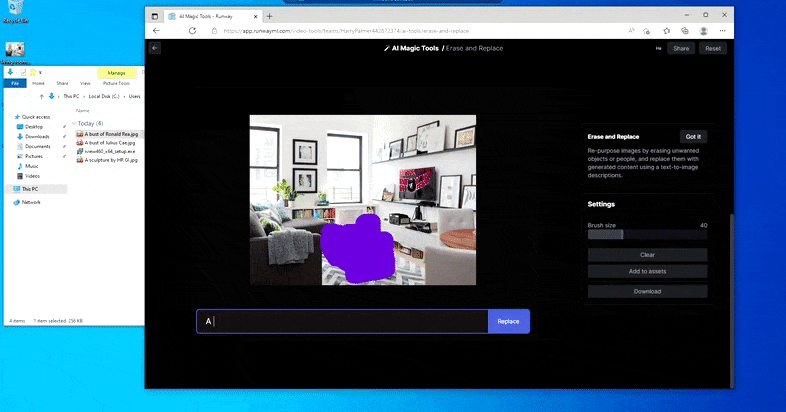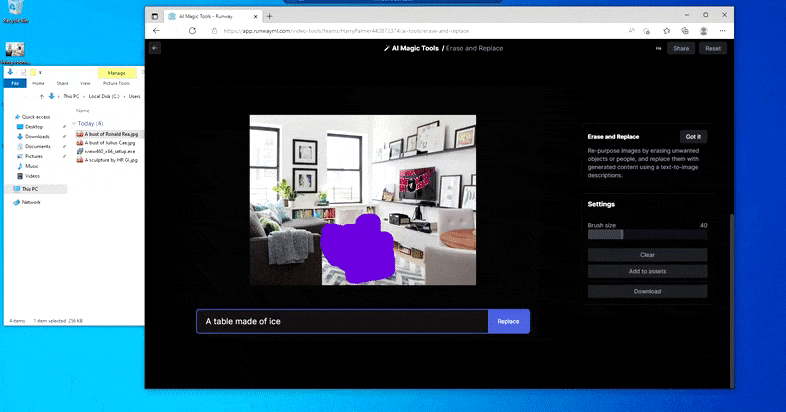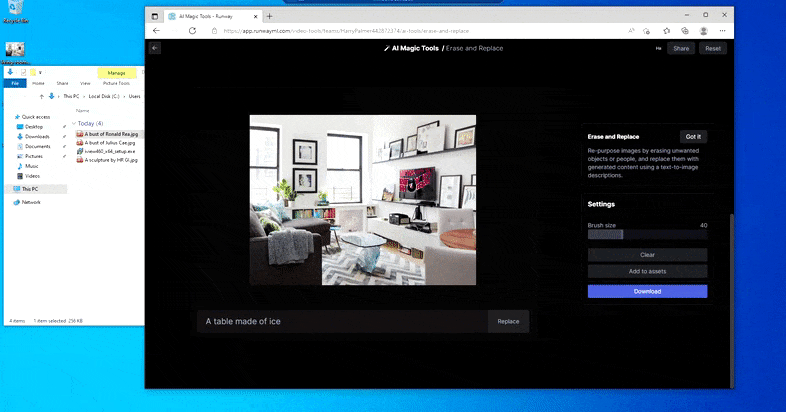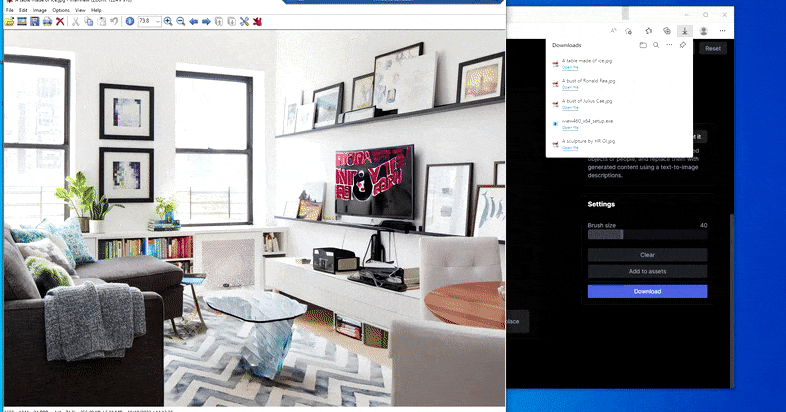
Substitution d’une table domestique par une ‘table en glace’ dans la fonction Erase and Replace de Runway ML.
Comme pour Imagic (voir ci-dessous), Erase and Replace est « orienté objet », pour ainsi dire – vous ne pouvez pas simplement effacer une « partie vide » de l’image et la repeindre avec le résultat de votre invite de texte ; dans ce scénario, le système suivra simplement l’objet le plus proche le long de la ligne de mire du masque (comme un mur ou une télévision) et appliquera la transformation là.
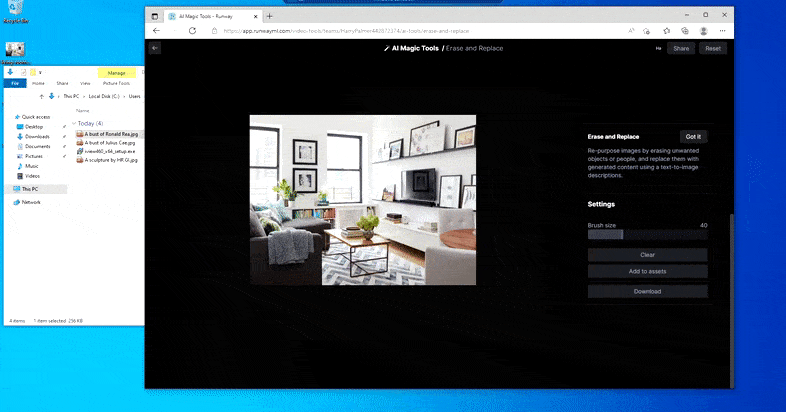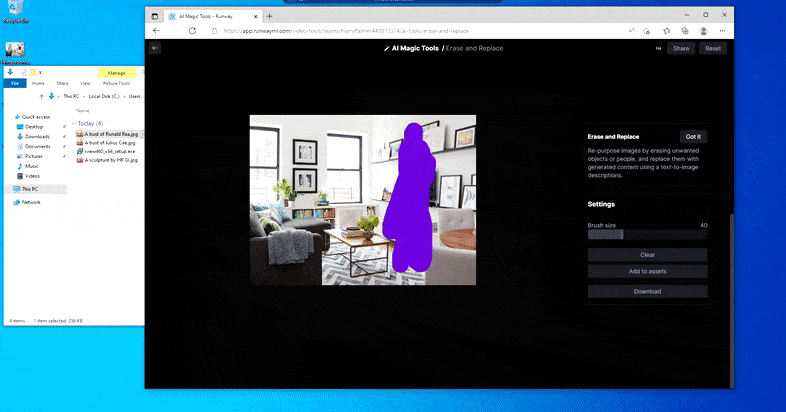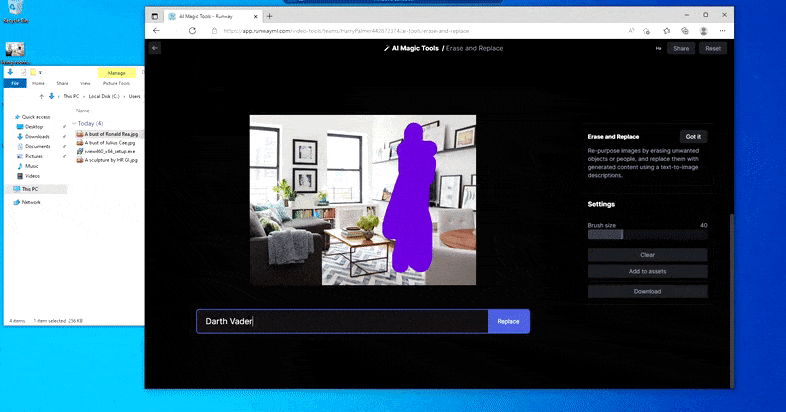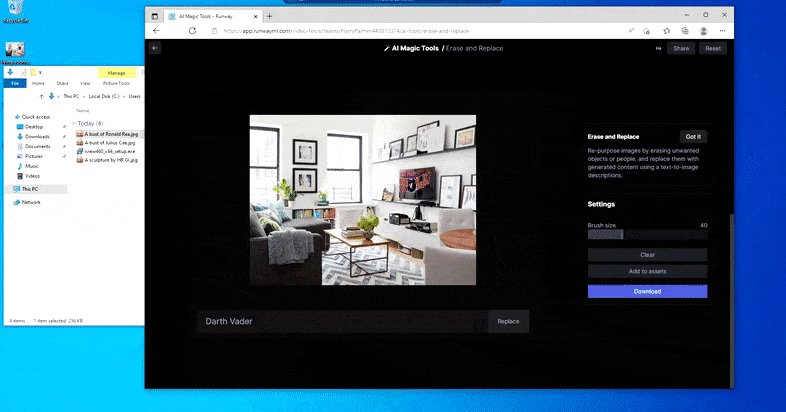
Comme le nom l’indique, vous ne pouvez pas injecter d’objets dans l’espace vide dans Erase and Replace. Ici, une tentative pour invoquer le plus célèbre des seigneurs Sith se traduit par une étrange fresque de Vader sur la télévision, approximativement là où la zone de ‘remplacement’ a été dessinée.
Il est difficile de dire si Erase and Replace est évasif en ce qui concerne l’utilisation d’images protégées par des droits d’auteur (qui sont toujours largement obstruées, bien que avec des succès variables, dans DALL-E 2), ou si le modèle utilisé dans le moteur de rendu est simplement pas optimisé pour ce type de chose.

La ‘fresque de Nicole Kidman’ légèrement NSFW indique que le modèle de diffusion présumé utilisé manque de la réjection systématique de DALL-E 2 de la représentation de visages réalistes ou de contenu osé, tandis que les résultats des tentatives pour évoquer des œuvres protégées par des droits d’auteur vont de l’ambigu (‘xénomorphe’) à l’absurde (‘le trône de fer’). En bas à droite, l’image source.
Il serait intéressant de savoir quels méthodes Erase and Replace utilise pour isoler les objets qu’il est capable de remplacer. Présumément, l’image est traitée par une dérivée de CLIP, avec les éléments discrets individués par la reconnaissance d’objets et la segmentation sémantique subséquente. Aucune de ces opérations ne fonctionne presque aussi bien dans une installation courante de Stable Diffusion.
Mais rien n’est parfait – parfois, le système semble effacer et ne pas remplacer, même lorsque (comme nous l’avons vu dans l’image ci-dessus), le mécanisme de rendu sous-jacent sait clairement ce qu’un texte invite signifie. Dans ce cas, il s’avère impossible de transformer une table basse en xénomorphe – plutôt, la table disparaît simplement.
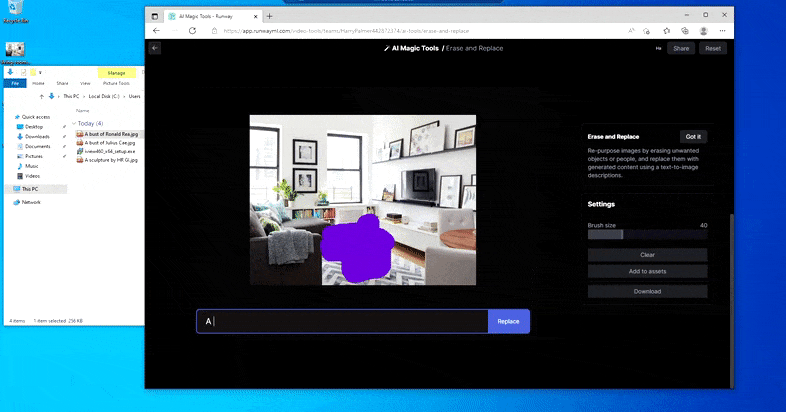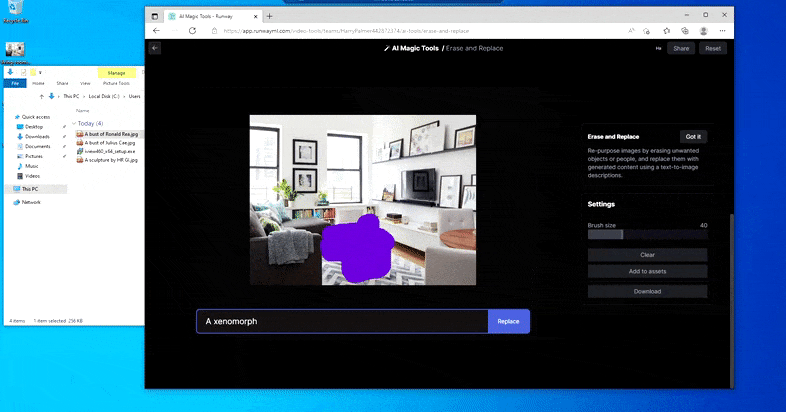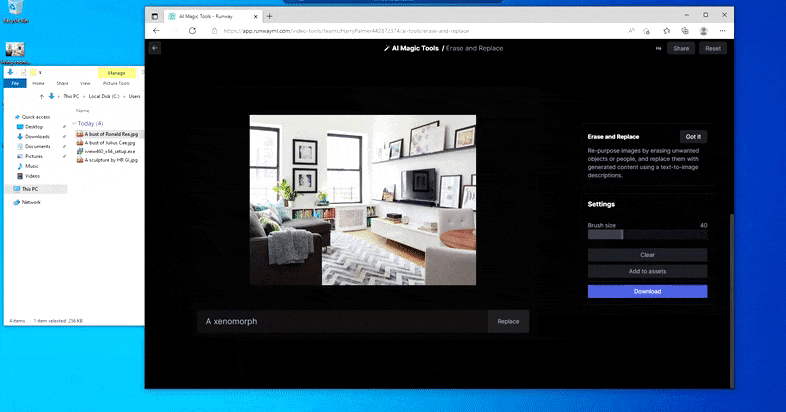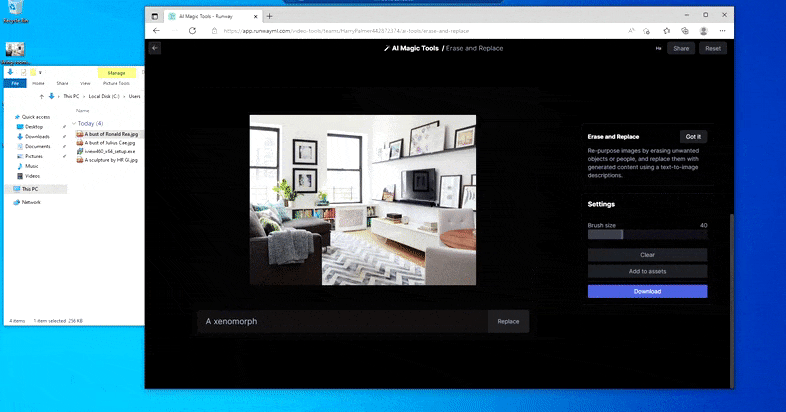
Une itération plus effrayante de ‘Où est Charlie ?’, alors qu’Erase and Replace échoue à produire un alien.
Erase and Replace semble être un système de substitution d’objets efficace, avec un excellent recoloriage. Cependant, il ne peut pas éditer les objets existants perçus, mais seulement les remplacer. Pour modifier réellement le contenu d’une image existante sans compromettre la matière ambiante est incontestablement une tâche beaucoup plus difficile, liée à la lutte de longue date du secteur de la vision par ordinateur vers la disjonction dans les divers espaces latents des cadres populaires.
Imagic
C’est une tâche que Imagic aborde. Le nouvel article propose de nombreux exemples d’éditions qui modifient avec succès des aspects individuels d’une photo tout en laissant le reste de l’image intact.

Dans Imagic, les images modifiées ne souffrent pas de l’étirement, de la distorsion et de la ‘supposition d’occlusion’ caractéristiques de la marionnette de deepfake, qui utilise des connaissances antérieures limitées dérivées d’une seule image.
Le système utilise un processus en trois étapes – optimisation de l’intégration du texte ; affinage du modèle ; et, enfin, génération de l’image modifiée.

Imagic code l’invite de texte cible pour récupérer l’intégration du texte initial, puis optimise le résultat pour obtenir l’image d’entrée. Après cela, le modèle génératif est affiné sur l’image source, en ajoutant une série de paramètres, avant d’être soumis à l’interpolation demandée.
Comme on pouvait s’y attendre, le cadre est basé sur l’architecture de texte-vidéo Imagen de Google, bien que les chercheurs déclarent que les principes du système sont largement applicables aux modèles de diffusion latents.
Imagen utilise une architecture à trois niveaux, plutôt que la série de sept niveaux utilisée pour l’itération plus récente de la société de texte-vidéo du logiciel. Les trois modules distincts comprennent un modèle de diffusion génératif fonctionnant à une résolution de 64x64px ; un modèle de super-résolution qui met à l’échelle cette sortie à 256x256px ; et un modèle de super-résolution supplémentaire pour prendre la sortie jusqu’à une résolution de 1024×1024.
Imagic intervient au stade le plus précoce de ce processus, en optimisant l’intégration du texte demandé au stade 64px sur un optimiseur Adam à un taux d’apprentissage statique de 0,0001.

Un cours de maîtrise de la disjonction : ceux qui ont tenté de modifier quelque chose d’aussi simple que la couleur d’un objet rendu dans un modèle de diffusion, de GAN ou de NeRF sauront combien il est important qu’Imagic puisse effectuer de telles transformations sans ‘déchirer’ la cohérence du reste de l’image.
L’affinage a ensuite lieu sur le modèle de base d’Imagen, pendant 1500 étapes par image d’entrée, conditionné par l’intégration révisée. Dans le même temps, la couche secondaire 64px>256px est optimisée en parallèle sur l’image conditionnée. Les chercheurs notent qu’une optimisation similaire pour la couche finale 256px>1024px a « peu ou pas d’effet » sur les résultats finaux, et n’ont donc pas mis en œuvre cela.
L’article indique que le processus d’optimisation prend environ huit minutes par image sur des puces TPUV4 jumelées. Le rendu final a lieu dans Imagen de base sous le schéma d’échantillonnage DDIM.
Comme pour les processus d’affinage similaires pour DreamBooth de Google, les intégrations résultantes peuvent également être utilisées pour alimenter la stylisation, ainsi que des éditions photoréalistes qui contiennent des informations tirées de la base de données sous-jacente plus large qui alimente Imagen (puisque, comme le montre la première colonne ci-dessous, les images sources n’ont aucune des informations nécessaires pour effectuer ces transformations).

Des mouvements et des éditions photoréalistes flexibles peuvent être évoqués via Imagic, tandis que les codes dérivés et disjoints obtenus dans le processus peuvent être utilisés aussi facilement pour la sortie stylisée.
Les chercheurs ont comparé Imagic à des travaux antérieurs SDEdit, une approche basée sur GAN de 2021, une collaboration entre l’Université de Stanford et l’Université Carnegie Mellon ; et Text2Live, une collaboration, d’avril 2022, entre l’Institut de science Weizmann et NVIDIA.

Une comparaison visuelle entre Imagic, SDEdit et Text2Live.
Il est clair que les approches antérieures ont du mal, mais dans la rangée inférieure, qui implique l’interjection d’un changement de pose massif, les prédécesseurs échouent complètement à réaménager la matière source, par rapport à un succès notable d’Imagic.
Les exigences en ressources et le temps de formation d’Imagic par image, bien que courts par rapport aux normes de telles poursuites, font qu’il est peu probable qu’il soit inclus dans une application d’édition d’images locale sur les ordinateurs personnels – et il n’est pas clair dans quelle mesure le processus d’affinage pourrait être réduit à des niveaux de consommation.
Comme il se présente, Imagic est une offre impressionnante qui est plus adaptée aux API – un environnement dans lequel Google Research, circonspect en ce qui concerne la critique de la facilitation du deepfaking, peut être le plus à l’aise.
Publié pour la première fois le 18 octobre 2022.












