Intelligence Artificielle
Adobe Research étend l'édition de visage GAN désenchevêtré

Il n’est pas difficile de comprendre pourquoi enchevêtrement C'est un problème en synthèse d'images, car c'est souvent le cas dans d'autres domaines de la vie ; par exemple, il est bien plus difficile de retirer le curcuma d'un curry que de jeter le cornichon d'un hamburger, et il est pratiquement impossible de désucrér une tasse de café. Certains produits sont simplement vendus en paquets.
De même, l'intrication est une pierre d'achoppement pour les architectures de synthèse d'images qui souhaiteraient idéalement séparer différentes fonctionnalités et concepts lors de l'utilisation de l'apprentissage automatique pour créer ou modifier des visages (ou des visages). chiens, bateaux, ou tout autre domaine).
Si vous pouviez séparer les brins tels que âge, le sexe, la couleur des cheveux, teint, émotion, et ainsi de suite, vous auriez les débuts d'une véritable instrumentalité et d'une flexibilité dans un cadre qui pourrait créer et éditer des images de visage à un niveau vraiment granulaire, sans entraîner de « passagers » indésirables dans ces conversions.

Au maximum d'enchevêtrement (en haut à gauche), tout ce que vous pouvez faire est de changer l'image d'un réseau GAN appris en l'image d'une autre personne.
Il s'agit d'utiliser efficacement la dernière technologie de vision par ordinateur de l'IA pour réaliser quelque chose qui a été résolu par d'autres moyens. il y a plus de trente ans.
Avec un certain degré de séparation (« Séparation moyenne » dans l'image ci-dessus), il est possible d'effectuer des changements basés sur le style tels que la couleur des cheveux, l'expression, l'application de cosmétiques et la rotation limitée de la tête, entre autres.

Source: FEAT : Retouche faciale avec attention, février 2022, https://arxiv.org/pdf/2202.02713.pdf
Il y a eu un certain nombre de tentatives au cours des deux dernières années pour créer des environnements interactifs d'édition de visage qui permettent à un utilisateur de modifier les caractéristiques faciales avec des curseurs et d'autres interactions d'interface utilisateur traditionnelles, tout en conservant intactes les caractéristiques essentielles du visage cible lors d'ajouts ou de modifications. Cependant, cela s'est avéré un défi en raison de l'enchevêtrement caractéristique/style sous-jacent dans l'espace latent du GAN.
Par exemple, le lunettes trait est souvent lié à la âgé trait, ce qui signifie que l'ajout de lunettes pourrait également « vieillir » le visage, tandis que le vieillissement du visage pourrait ajouter des lunettes, en fonction du degré de séparation appliqué des caractéristiques de haut niveau (voir « Test » ci-dessous pour des exemples).
Plus particulièrement, il a été presque impossible de modifier la couleur des cheveux et d'autres facettes des cheveux sans que les mèches et la disposition des cheveux soient recalculées, ce qui donne un effet de transition « grésillant ».

Source : Démo InterFaceGAN (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Traversée GAN latente à latente
Un nouveau papier dirigé par Adobe entré pour WACV 2022 offre une nouvelle approche de ces problèmes sous-jacents dans un papier droit Latent to Latent : un mappeur appris pour la modification de plusieurs attributs de visage dans les images générées par StyleGAN.

Matériel supplémentaire du papier Latent to Latent : un mappeur appris pour la modification de plusieurs attributs de visage dans les images générées par StyleGAN. Ici, nous voyons que les caractéristiques de base du visage appris ne sont pas entraînées dans des changements sans rapport. Voir la vidéo complète intégrée à la fin de l'article pour de meilleurs détails et une meilleure résolution. Source : https://www.youtube.com/watch?v=rf_61llRH0Q
L'article est dirigé par Siavash Khodadadeh, scientifique appliqué d'Adobe, avec quatre autres chercheurs d'Adobe et un chercheur du Département d'informatique de l'Université de Floride centrale.
L'article est intéressant en partie parce qu'Adobe opère dans ce domaine depuis un certain temps, et il est tentant d'imaginer que cette fonctionnalité entre dans un projet Creative Suite dans les prochaines années ; mais surtout parce que l'architecture créée pour le projet adopte une approche différente pour maintenir l'intégrité visuelle dans un éditeur de visage GAN pendant que les modifications sont appliquées.
Les auteurs déclarent :
"[Nous] entraînons un réseau de neurones pour effectuer une transformation latente à latente qui trouve le codage latent correspondant à l'image avec l'attribut modifié. Comme la technique est monocoup, elle ne repose pas sur une trajectoire linéaire ou non linéaire du changement progressif des attributs.
«En entraînant le réseau de bout en bout sur l'ensemble du pipeline de génération, le système peut s'adapter aux espaces latents des architectures de générateurs prêts à l'emploi. Les propriétés de conservation, telles que le maintien de l'identité de la personne, peuvent être codées sous la forme de pertes d'entraînement.
« Une fois le réseau latent à latent formé, il peut être réutilisé pour des images arbitraires sans réentraînement. »
Cette dernière partie signifie que l'architecture proposée est livrée à l'utilisateur final dans un état final. Elle doit encore exécuter un réseau neuronal sur des ressources locales, mais de nouvelles images peuvent être intégrées et prêtes à être modifiées presque immédiatement, car le framework est suffisamment découplé pour ne pas nécessiter d'entraînement supplémentaire spécifique aux images.
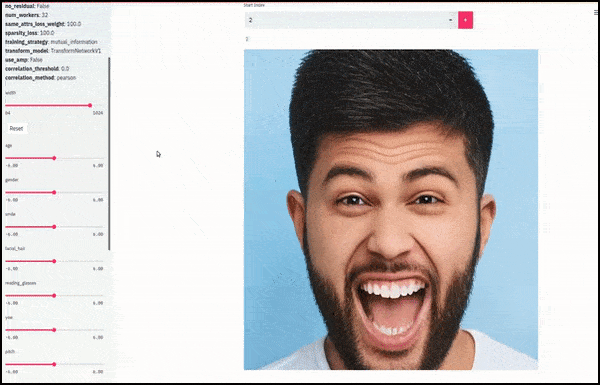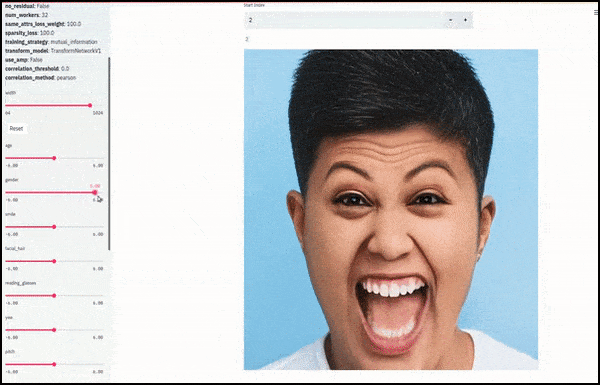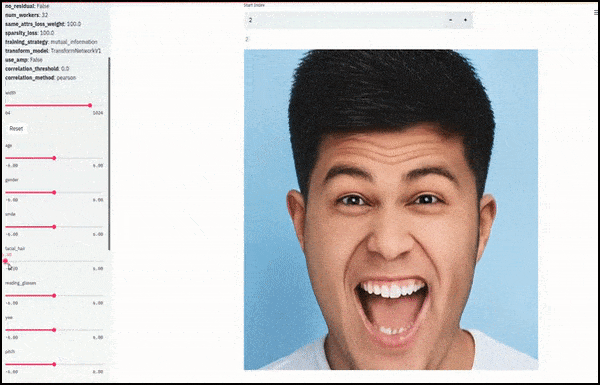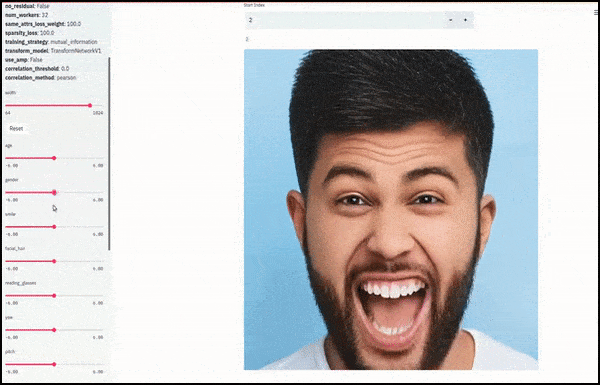
Le sexe et la pilosité faciale ont été modifiés à mesure que les curseurs tracent des chemins aléatoires et arbitraires dans l'espace latent, et non pas simplement en effectuant un « frottement entre les extrémités ». Voir la vidéo intégrée à la fin de l'article pour plus de transformations en meilleure résolution.
Parmi les principales réalisations de ce travail figure la capacité du réseau à « geler » les identités dans l’espace latent en modifiant uniquement l’attribut dans un vecteur cible et en fournissant des « termes de correction » qui conservent les identités en cours de transformation.
Essentiellement, le réseau proposé est intégré dans une architecture plus large qui orchestre tous les éléments traités, qui passent par des composants pré-formés avec des poids figés qui ne produiront pas d'effets latéraux indésirables sur les transformations.
Étant donné que le processus de formation repose sur triplés qui peut être généré soit par une image de départ (sous Inversion GAN) ou un codage latent initial existant, l'ensemble du processus de formation n'est pas supervisé, avec les actions tacites de la gamme habituelle de systèmes d'étiquetage et de curation dans de tels systèmes intégrés efficacement dans l'architecture. En fait, le nouveau système utilise des régresseurs d'attributs prêts à l'emploi :
« Le nombre d'attributs que notre réseau peut contrôler indépendamment n'est limité que par les capacités du ou des outils de reconnaissance : si l'on dispose d'un outil de reconnaissance pour un attribut, nous pouvons l'ajouter à des visages arbitraires. Lors de nos expériences, nous avons entraîné le réseau latent-à-latent à permettre l'ajustement de 35 attributs faciaux différents, soit plus que toute autre approche antérieure. »
Le système intègre une protection supplémentaire contre les transformations « à effet secondaire » indésirables : en l'absence de demande de changement d'attribut, le réseau latent à latent mappera un vecteur latent sur lui-même, augmentant encore la persistance stable de l'identité cible.
La reconnaissance faciale
Un problème récurrent avec GAN et les éditeurs de visage basés sur l'encodeur/décodeur de ces dernières années est que les transformations appliquées ont tendance à dégrader la ressemblance. Pour lutter contre cela, le projet Adobe utilise un réseau de reconnaissance faciale intégré appelé FaceNet comme discriminant.

Architecture du projet, voir en bas au milieu à gauche pour l'inclusion de FaceNet. Source: Latent to Latent : un mappeur appris pour la modification de plusieurs attributs de visage dans les images générées par StyleGAN, Accès libre.
(Sur une note personnelle, cela semble un pas encourageant vers l'intégration de systèmes standard d'identification faciale et même de reconnaissance d'expression dans des réseaux génératifs, sans doute la meilleure voie à suivre pour surmonter le pixel aveugle> mappage de pixels qui domine les architectures deepfake actuelles au détriment de la fidélité d'expression et d'autres domaines importants dans le secteur de la génération de visages.)
Accès à toutes les zones dans l'espace latent
Une autre caractéristique impressionnante du framework est sa capacité à naviguer arbitrairement entre les transformations potentielles dans l'espace latent, au gré de l'utilisateur. Plusieurs systèmes antérieurs proposant des interfaces exploratoires laissaient souvent l'utilisateur se contenter de « scruter » entre des chronologies fixes de transformation des caractéristiques – une expérience impressionnante, mais souvent assez linéaire ou contraignante.

À partir de Améliorer l'équilibre GAN en augmentant la conscience spatiale: ici, l'utilisateur parcourt une gamme de points de transition potentiels entre deux emplacements d'espace latent, mais dans les limites d'emplacements pré-formés dans l'espace latent. Pour appliquer d'autres types de transformation à partir du même matériau, une reconfiguration et/ou un recyclage est nécessaire. Source : https://genforce.github.io/eqgan/
Outre la possibilité d'accepter des images entièrement nouvelles, l'utilisateur peut également « figer » manuellement les éléments qu'il souhaite conserver pendant le processus de transformation. Il peut ainsi s'assurer, par exemple, que les arrière-plans restent fixes ou que les yeux restent ouverts ou fermés.
Date
Le réseau de régression d'attributs a été entraîné sur trois réseaux : FFHQ, CelebAMask-HQ, et un réseau local généré par GAN obtenu en échantillonnant 400,000 XNUMX vecteurs à partir de l'espace Z de StyleGAN-V2.
Les images hors distribution (OOD) ont été filtrées et les attributs extraits à l'aide de Microsoft API Face, avec l'ensemble d'images résultant divisé 90/10, laissant 721,218 72,172 images d'entraînement et XNUMX XNUMX images de test à comparer.
Tests
Bien que le réseau expérimental ait été initialement configuré pour accueillir 35 transformations potentielles, celles-ci ont été réduites à huit afin d'entreprendre des tests analogues par rapport aux cadres comparables. InterfaceGAN, GANSpace et Flux de style.
Les huit attributs sélectionnés étaient Âge , Calvitie, Barbe, Expression, Genre, Lunettes, Emplacement et Embardée. Il a été nécessaire de rééquiper les frameworks concurrents pour certains des huit attributs qui n'étaient pas provisionnés dans la distribution d'origine, comme l'ajout calvitie barbe à InterfaceGAN.
Comme prévu, un plus grand niveau d'enchevêtrement s'est produit dans les architectures rivales. Par exemple, dans un test, InterFaceGAN et StyleFlow ont tous deux changé le sexe du sujet lorsqu'on lui a demandé de postuler âge:

Deux des frameworks concurrents ont intégré un changement de genre dans la transformation « âge », changeant également la couleur des cheveux sans demande directe de l'utilisateur.
De plus, deux des rivaux ont trouvé que les lunettes et l'âge sont des facettes indissociables :

Lunettes et changement de couleur de cheveux inclus sans frais supplémentaires !
Ce n'est pas une victoire uniforme pour la recherche : comme on peut le voir dans la vidéo d'accompagnement intégrée à la fin de l'article, le cadre est le moins efficace lorsqu'on essaie d'extrapoler divers angles (lacet), tandis que GANSpace a un meilleur résultat général pour âge et l'imposition de lunettes. Le cadre latent à latent lié à GANSpace et StyleFlow concernant l'ajout de pas (angle de tête).

Résultats calculés sur la base d'un étalonnage de la Détecteur de visage MTCNN. Les résultats inférieurs sont meilleurs.
Pour plus de détails et une meilleure résolution des exemples, consultez la vidéo accompagnant l'article ci-dessous.
Première publication le 16 février 2022.












