
Tehisintellekt
YOLOv7: kõige arenenum objektituvastusalgoritm?

6. juuli 2022 märgitakse tehisintellekti ajaloo maamärgiks, sest just sel päeval ilmus YOLOv7. Alates selle käivitamisest on YOLOv7 olnud Computer Visioni arendajate kogukonna kuumim teema ja seda õigetel põhjustel. YOLOv7-t peetakse juba objektide tuvastamise tööstuse verstapostiks.
Vahetult pärast avaldati YOLOv7 paber, see osutus kiireimaks ja täpseimaks reaalajas vastuväidete tuvastamise mudeliks. Kuidas aga YOLOv7 oma eelkäijaid üle konkureerib? Mis teeb YOLOv7 arvutinägemisülesannete täitmisel nii tõhusaks?
Selles artiklis proovime analüüsida YOLOv7 mudelit ja leida vastust küsimusele, miks YOLOv7 on nüüd muutumas tööstuse standardiks? Kuid enne, kui saame sellele vastata, peame heitma pilgu objektide tuvastamise lühikesele ajaloole.
Mis on objektide tuvastamine?
Objektide tuvastamine on arvutinägemise haru mis tuvastab ja tuvastab pildil või videofailis olevad objektid. Objektide tuvastamine on paljude rakenduste ehitusplokk, sealhulgas isejuhtivad autod, jälgitav jälgimine ja isegi robootika.
Objekti tuvastamise mudeli võib jagada kahte erinevasse kategooriasse, ühe lasuga detektorid, ja mitme kaadri detektorid.
Reaalajas objektide tuvastamine
YOLOv7 toimimise tõeliseks mõistmiseks on oluline mõista YOLOv7 peamist eesmärki.Objekti reaalajas tuvastamine”. Objektide reaalajas tuvastamine on kaasaegse arvutinägemise põhikomponent. Reaalajas objektide tuvastamise mudelid püüavad tuvastada ja leida huvipakkuvaid objekte reaalajas. Reaalajas objektituvastuse mudelid muutsid arendajate jaoks tõeliselt tõhusaks huvipakkuvate objektide jälgimise liikuvas kaadris, näiteks videos või reaalajas jälgimissisendis.

Reaalajas objektituvastuse mudelid on tavapärastest pildituvastusmudelitest põhimõtteliselt sammu võrra ees. Kui esimest kasutatakse videofailides olevate objektide jälgimiseks, siis teine tuvastab ja tuvastab objektid statsionaarses kaadris nagu pilt.
Selle tulemusena on reaalajas objektituvastuse mudelid tõeliselt tõhusad videoanalüüsi, autonoomsete sõidukite, objektide loendamise, mitme objekti jälgimise ja palju muu jaoks.
Mis on YOLO?
YOLO või "Vaatad vaid korra” on reaalajas objektide tuvastamise mudelite perekond. YOLO kontseptsiooni tutvustas esmakordselt 2016. aastal Joseph Redmon ja see oli peaaegu kohe kõneaineks, sest see oli palju kiirem ja palju täpsem kui olemasolevad objektituvastusalgoritmid. Ei läinud kaua aega, kui YOLO algoritmist sai arvutinägemise tööstuse standard.

YOLO algoritmi pakutud põhikontseptsioon on kasutada reaalajas ennustuste tegemiseks otspunktidevahelist närvivõrku, kasutades piirdekaste ja klasside tõenäosusi. YOLO erines eelmisest objektide tuvastamise mudelist selles mõttes, et see pakkus välja erineva lähenemisviisi objektide tuvastamiseks klassifikaatorite ümberpaigutamise teel.
Lähenemisviisi muutus toimis, kuna YOLO-st sai peagi tööstusstandard, kuna jõudluse erinevus enda ja teiste reaalajas objektide tuvastamise algoritmide vahel oli märkimisväärne. Kuid mis oli põhjus, miks YOLO oli nii tõhus?
Võrreldes YOLO-ga, kasutasid objektide tuvastamise algoritmid sel ajal võimalike huvipakkuvate piirkondade tuvastamiseks piirkonna ettepanekute võrke. Seejärel viidi tuvastusprotsess läbi igas piirkonnas eraldi. Selle tulemusena tegid need mudelid sageli samale pildile mitu iteratsiooni ja sellest tulenevalt puudus täpsus ja pikem täitmisaeg. Teisest küljest kasutab YOLO algoritm üht täielikult ühendatud kihti, et ennustada korraga.
Kuidas YOLO töötab?
Seal on kolm sammu, mis selgitavad, kuidas YOLO algoritm töötab.
Objekti tuvastamise ümberkujundamine ühe regressiooniprobleemina
. YOLO algoritm üritab objekti tuvastamist ümber kujundada ühe regressiooniprobleemina, kaasa arvatud pildi pikslid, klassi tõenäosused ja piirdekasti koordinaadid. Seega peab algoritm piltidel sihtobjektide ennustamiseks ja asukoha määramiseks pilti vaatama ainult üks kord.
Põhjustab kuvandit globaalselt
Lisaks kui YOLO algoritm teeb prognoose, põhjendab see pilti globaalselt. See erineb piirkonna ettepanekupõhistest ja libisemismeetoditest, kuna YOLO algoritm näeb kogu pilti koolituse ja andmestiku testimise ajal ning suudab kodeerida kontekstipõhist teavet klasside ja nende ilmumise kohta.
Enne YOLO-t oli Fast R-CNN üks populaarsemaid objektituvastusalgoritme, mis ei näinud pildil laiemat konteksti, kuna pidas pildi taustaplaastreid objektiga ekslikult. Võrreldes Fast R-CNN algoritmiga on YOLO 50% täpsem kui tegemist on taustavigadega.
Üldistab objektide kujutamist
Lõpuks on YOLO algoritmi eesmärk ka objektide esitusviiside üldistamine pildil. Selle tulemusel, kui YOLO algoritmi käitati loomulike kujutistega andmekogul ja testiti tulemusi, ületas YOLO olemasolevaid R-CNN-i mudeleid suurel määral. Kuna YOLO on väga üldistatav, oli tõenäosus, et see ootamatutel sisenditel või uutel domeenidel juurutamisel laguneb, väike.
YOLOv7: mis on uut?
Nüüd, kui meil on põhiteadmised sellest, mis on reaalajas objektituvastusmudelid ja mis on YOLO algoritm, on aeg arutada YOLOv7 algoritmi.
Koolitusprotsessi optimeerimine
YOLOv7 algoritm mitte ainult ei püüa optimeerida mudeli arhitektuuri, vaid selle eesmärk on ka koolitusprotsessi optimeerimine. Selle eesmärk on kasutada optimeerimismooduleid ja meetodeid, et parandada objekti tuvastamise täpsust, suurendades koolituskulusid, säilitades samal ajal häirete kulud. Nendele optimeerimismoodulitele võib viidata kui a treenitav tasuta kott.
Jäme kuni peen plii juhitud etiketi määramine
Algoritm YOLOv7 kavatseb tavapärase asemel kasutada uut jämedast peenest pliist juhitavat etiketi määramist. Dünaamiline sildi määramine. Põhjus on selles, et dünaamilise sildi määramise korral põhjustab mitme väljundkihiga mudeli koolitamine mõningaid probleeme, millest kõige tavalisem on dünaamiliste sihtmärkide määramine erinevatele harudele ja nende väljunditele.
Mudeli ümberparameetristamine
Mudeli ümberparameetristamine on objektide tuvastamisel oluline kontseptsioon ja selle kasutamist järgitakse tavaliselt koolituse ajal teatud probleemide korral. YOLOv7 algoritm kavatseb kasutada kontseptsiooni gradiendi levitamise tee mudeli ümberparameetristamise poliitika analüüsimiseks rakendatav võrgu erinevatele kihtidele.
Laiendage ja ühendage skaleerimine
YOLOv7 algoritm tutvustab ka laiendatud ja liitskaala meetodid kasutada ja tõhusalt kasutada parameetreid ja arvutusi objektide reaalajas tuvastamiseks.

YOLOv7 : seotud tööd
Reaalajas objektide tuvastamine
YOLO on praegu tööstusstandard ja enamik reaalajas objektidetektoreid kasutavad YOLO algoritme ja FCOS-i (Fully Convolutional One-Stage Object-Detection). Nüüdisaegsel reaalajas objektidetektoril on tavaliselt järgmised omadused
- Tugevam ja kiirem võrguarhitektuur.
- Tõhus funktsioonide integreerimise meetod.
- Täpne objekti tuvastamise meetod.
- Tugev kadufunktsioon.
- Tõhus märgistuse määramise meetod.
- Tõhus treeningmeetod.
YOLOv7 algoritm ei kasuta enesejärelevalvega õppimis- ja destilleerimismeetodeid, mis nõuavad sageli suuri andmemahtusid. Seevastu YOLOv7 algoritm kasutab treenitavat tasuta kottide meetodit.
Mudeli ümberparameetristamine
Mudeli ümberparameetristamise tehnikaid peetakse ansamblitehnikaks, mis ühendab mitu arvutusmoodulit häiretetapis. Tehnika võib jagada kahte kategooriasse, mudeli tasemel ansambel, ja mooduli tasemel ansambel.
Nüüd, lõpliku interferentsi mudeli saamiseks, kasutab mudelitaseme ümberparameetristamise tehnika kahte praktikat. Esimesel praktikal kasutatakse arvukate identsete mudelite treenimiseks erinevaid treeningandmeid ja seejärel arvutatakse treenitud mudelite kaalud. Teise võimalusena keskmistatakse mudelite kaalud erinevate iteratsioonide ajal.
Moodulitaseme ümberparameetrite muutmine kogub viimasel ajal tohutut populaarsust, kuna see jagab mooduli koolitusfaasis erinevateks mooduliharudeks või erinevateks identseteks harudeks ja seejärel integreerib need erinevad harud häirete ajal samaväärseks mooduliks.
Parameetrite muutmise tehnikaid ei saa aga rakendada igasuguste arhitektuuride puhul. See on põhjus, miks YOLOv7 algoritm kasutab seotud strateegiate kujundamiseks uusi mudeli ümberparameetristamise tehnikaid sobib erinevatele arhitektuuridele.
Mudeli skaleerimine
Mudeli skaleerimine on olemasoleva mudeli suurendamise või vähendamise protsess, et see sobiks erinevate arvutusseadmetega. Mudeli skaleerimine kasutab üldiselt mitmesuguseid tegureid, nagu kihtide arv (sügavus), sisendpiltide suurus (resolutsioon), tunnuste püramiidide arv (etapp) ja kanalite arv (laius). Need tegurid mängivad otsustavat rolli võrguparameetrite, häirete kiiruse, arvutamise ja mudeli täpsuse tasakaalustatud kompromissi tagamisel.
Üks kõige sagedamini kasutatavaid skaleerimismeetodeid on NAS või võrguarhitektuuri otsing mis otsib otsingumootoritest automaatselt sobivaid skaleerimisfaktoreid ilma keeruliste reegliteta. NAS-i kasutamise peamine negatiivne külg on see, et see on kallis meetod sobivate skaleerimistegurite otsimiseks.
Peaaegu iga mudeli ümberparameetristamise mudel analüüsib individuaalseid ja kordumatuid skaleerimisfaktoreid iseseisvalt ning lisaks optimeerib neid tegureid iseseisvalt. Põhjus on selles, et NAS-i arhitektuur töötab mittekorreleeruvate skaleerimisteguritega.
Väärib märkimist, et konkatenatsioonipõhised mudelid meeldivad VoVNet or DenseNet muuta mõne kihi sisendlaiust, kui mudelite sügavust skaleeritakse. YOLOv7 töötab väljapakutud konkatenatsioonipõhisel arhitektuuril ja kasutab seetõttu liite skaleerimise meetodit.

Ülaltoodud joonisel võrreldakse laiendatud tõhusad kihtide koondamise võrgud (E-ELAN) erinevatest mudelitest. Kavandatud E-ELAN-meetod säilitab algse arhitektuuri gradiendi edastustee, kuid selle eesmärk on suurendada lisatud funktsioonide kardinaalsust rühmakonvolutsiooni abil. Protsess võib täiustada erinevate kaartide abil õpitud funktsioone ning veelgi tõhusamaks muuta arvutuste ja parameetrite kasutamist.
YOLOv7 arhitektuur
Mudel YOLOv7 kasutab alusena mudeleid YOLOv4, YOLO-R ja Scaled YOLOv4. YOLOv7 on nende mudelitega tehtud katsete tulemus, et parandada tulemusi ja muuta mudel täpsemaks.
Extended Efficient Layer Agregation Network ehk E-ELAN
E-ELAN on YOLOv7 mudeli põhiline ehitusplokk ja see tuleneb juba olemasolevatest võrgutõhususe mudelitest, peamiselt ELAN.
Peamised kaalutlused tõhusa arhitektuuri kujundamisel on parameetrite arv, arvutustihedus ja arvutusmaht. Teised mudelid võtavad arvesse ka selliseid tegureid nagu sisend- ja väljundkanalite suhte mõju, arhitektuurivõrgu harud, võrgu häirete kiirus, elementide arv konvolutsioonivõrgu tensorites ja palju muud.
. CSPVoNet mudel mitte ainult ei võta arvesse ülalnimetatud parameetreid, vaid analüüsib ka gradiendi teed, et õppida mitmekesisemaid funktsioone, võimaldades erinevate kihtide kaalu. See lähenemisviis võimaldab häiretel olla palju kiirem ja täpne. The ELAN arhitektuuri eesmärk on kujundada tõhus võrk, et juhtida lühimat pikima gradiendi teed, et võrk oleks õppimisel ja lähenemisel tõhusam.
ELAN on juba jõudnud stabiilsesse staadiumisse, olenemata arvutusplokkide virnastamise arvust ja gradiendi tee pikkusest. Kui arvutusplokke piiramatult virnastada, võib stabiilne olek hävida ja parameetrite kasutusmäär väheneb. The pakutud E-ELAN arhitektuur võib probleemi lahendada, kuna see kasutab laiendamist, segamist ja ühendamist et pidevalt parandada võrgu õppimisvõimet, säilitades samal ajal algse gradiendi tee.
Lisaks, kui võrrelda E-ELAN-i arhitektuuri ELAN-iga, ainus erinevus on arvutusplokis, samas kui üleminekukihi arhitektuur on muutumatu.
E-ELAN teeb ettepaneku laiendada arvutusplokkide kardinaalsust ja laiendada kanalit kasutades rühmakonvolutsioon. Seejärel arvutatakse objektikaart ja segatakse rühmadesse vastavalt rühma parameetrile ning seejärel ühendatakse need kokku. Kanalite arv igas rühmas jääb samaks kui algses arhitektuuris. Lõpuks lisatakse kardinaalsuse tagamiseks objektikaartide rühmad.
Konkatenatsioonipõhiste mudelite mudeli skaleerimine
Mudeli skaleerimine aitab kaasa mudelite atribuutide kohandamine mis aitab luua mudeleid vastavalt nõuetele ja erineva skaalaga, et vastata erinevatele häirete kiirustele.

Joonisel on juttu mudeli skaleerimisest erinevate konkatenatsioonipõhiste mudelite jaoks. Nagu näete joonistel (a) ja (b), suureneb arvutusploki väljundlaius koos mudelite sügavuse skaleerimise suurenemisega. Selle tulemusena suureneb edastuskihtide sisendlaius. Kui neid meetodeid rakendatakse konkatenatsioonipõhises arhitektuuris, viiakse skaleerimisprotsess läbi põhjalikult ja seda on kujutatud joonisel (c).
Seega võib järeldada, et konkatenatsioonipõhiste mudelite puhul ei ole võimalik skaleerimisfaktoreid iseseisvalt analüüsida, vaid pigem tuleb neid vaadelda või analüüsida koos. Seetõttu on konkatenatsioonipõhise mudeli puhul sobib kasutada vastavat liitmudeli skaleerimise meetodit. Lisaks tuleb sügavusteguri skaleerimisel skaleerida ka ploki väljundkanalit.
Treenitav tasuta kingituste kott
Tasuta kingituste kott on termin, mida arendajad kirjeldavad meetodite või tehnikate kogum, mis võib muuta koolitusstrateegiat või -kulusid mudeli täpsuse suurendamiseks. Mis on siis YOLOv7 treenitavad tasuta kingituste kotid? Vaatame üle.
Planeeritud ümberparameetritega konvolutsioon
YOLOv7 algoritm kasutab määramiseks gradiendi voo levimisradu kuidas ideaaljuhul ühendada võrk ümberparameetristatud konvolutsiooniga. See YOLov7 lähenemine on katse vastu seista RepConv algoritm kuigi see on VGG mudelil rahulikult toiminud, toimib see halvasti, kui seda otse rakendada DenseNeti ja ResNeti mudelitele.
Konvolutsioonikihis olevate ühenduste tuvastamiseks RepConv algoritm ühendab 3 × 3 konvolutsiooni ja 1 × 1 konvolutsiooni. Kui analüüsime algoritmi, selle jõudlust ja arhitektuuri, näeme, et RepConv hävitab konkatenatsioon DenseNetis ja jääk ResNetis.

Ülaltoodud pilt kujutab kavandatud ümberparameetritega mudelit. On näha, et YOLov7 algoritm leidis, et konkatenatsiooni- või jääkühendustega võrgukihil ei tohiks RepConv algoritmis olla identiteediühendust. Sellest tulenevalt on vastuvõetav lülituda RepConvN-iga ilma identiteediühendusteta.
Jäme lisaseadme jaoks ja peen plii kadumise korral
Sügav järelevalve on arvutiteaduse haru, mida kasutatakse sageli süvavõrkude koolitusprotsessis. Sügava järelevalve aluspõhimõte on see lisab võrgu keskmistesse kihtidesse täiendava abipea koos madalate võrguraskustega, mille juhisena on abiline kadu. YOLOv7 algoritm viitab peale, mis vastutab lõpliku väljundi eest, kui juhtpea, ja abipea on pea, mis aitab treenida.
Edasi liikudes kasutab YOLOv7 siltide määramiseks teistsugust meetodit. Tavaliselt on siltide määramist kasutatud siltide genereerimiseks, viidates otse põhitõele ja lähtudes etteantud reeglitest. Viimastel aastatel on aga ennustussisendi jaotus ja kvaliteet mänginud usaldusväärse märgistuse loomisel olulist rolli. YOLOv7 loob objekti pehme sildi kasutades piirava kasti ja maatõe ennustusi.
Lisaks kasutab YOLOv7 algoritmi uus sildi määramise meetod juhtpea ennustusi nii juht- kui ka abipea juhtimiseks. Sildi määramise meetodil on kaks väljapakutud strateegiat.
Juhtjuhi juhitud sildi määraja
Strateegia teeb arvutused juhtpea ennustustulemuste ja põhitõe põhjal ning kasutab seejärel pehmete siltide genereerimiseks optimeerimist. Neid pehmeid silte kasutatakse seejärel nii juhtpea kui ka abipea treeningmudelina.
Strateegia lähtub eeldusest, et kuna juhtival juhil on suurem õppimisvõime, peaksid tema loodud sildid olema representatiivsemad ning allika ja sihtmärgi vahel korrelatsioonis.
Jämedast peeneks juhtpeaga juhitava etiketi määraja
See strateegia teeb ka arvutusi juhtpea ennustustulemuste ja põhitõe põhjal ning kasutab seejärel pehmete siltide loomiseks optimeerimist. Siiski on oluline erinevus. Selles strateegias on kaks pehmete siltide komplekti, jäme tase, ja peen silt.
Jäme silt saadakse positiivse proovi piirangute leevendamisel
määramisprotsess, mis käsitleb rohkem ruudustikke positiivsete sihtmärkidena. Seda tehakse selleks, et vältida teabe kaotamise ohtu abipea nõrgema õppimisvõime tõttu.

Ülaltoodud joonisel on selgitatud treenitava tasuta kingituste koti kasutamist YOLOv7 algoritmis. See kujutab abipea puhul jämedat ja juhtpea puhul peent. Kui võrdleme abipeaga mudelit (b) tavamudeliga (a), näeme, et punktis (b) oleval skeemil on abipea, samas kui seda pole punktis (a).
Joonis (c) kujutab ühist sõltumatut sildi määrajat, samas kui joonisel (d) ja joonisel (e) on vastavalt juhtjuhitav määraja ja YOLOv7 poolt jämedast peeneks juhitud juhtmääraja.
Muu treenitav tasuta kott
Lisaks ülalmainitutele kasutab YOLOv7 algoritm täiendavaid tasuta kingituste kotte, kuigi nad ei pakkunud neid algselt välja. Nemad on
- Partii normaliseerimine Conv-Bn-aktiveerimistehnoloogias: Seda strateegiat kasutatakse konvolutsioonikihi ühendamiseks otse partii normaliseerimiskihiga.
- Kaudsed teadmised YOLORis: YOLOv7 ühendab strateegia Convolutional funktsioonikaardiga.
- EMA mudel: EMA mudelit kasutatakse YOLOv7-s lõpliku võrdlusmudelina, kuigi selle esmast kasutust tuleb kasutada keskmise õpetaja meetodis.
YOLOv7: katsed
Eksperimentaalne seadistus
YOLOv7 algoritm kasutab Microsoft COCO andmestik koolituseks ja valideerimiseks nende objektide tuvastamise mudelit ja mitte kõik need katsed ei kasuta eelkoolitatud mudelit. Arendajad kasutasid treenimiseks 2017. aasta rongiandmestikku ja hüperparameetrite valimiseks 2017. aasta valideerimisandmestikku. Lõpuks võrreldakse YOLOv7 objekti tuvastamise tulemuste jõudlust objekti tuvastamise nüüdisaegsete algoritmidega.
Arendajad kujundasid selle jaoks põhimudeli serva GPU (YOLOv7-tiny), tavaline GPU (YOLOv7) ja pilv-GPU (YOLOv7-W6). Lisaks kasutab YOLOv7 algoritm mudeli skaleerimiseks põhimudelit vastavalt erinevatele teenusenõuetele ja saab erinevaid mudeleid. YOLOv7 algoritmi puhul tehakse virna skaleerimine kaelal ning pakutud ühendeid kasutatakse mudeli sügavuse ja laiuse suurendamiseks.
Lähtejooned
Algoritm YOLOv7 kasutab varasemaid YOLO mudeleid ja YOLOR objektituvastusalgoritmi baasjoonena.

Ülaltoodud joonisel võrreldakse YOLOv7 mudeli lähtejoont teiste objektide tuvastamise mudelitega ja tulemused on üsna ilmsed. Kui võrrelda YOLOv4 algoritm, YOLOv7 mitte ainult ei kasuta 75% vähem parameetreid, vaid kasutab ka 15% vähem arvutusi ja selle täpsus on 0.4% suurem.
Võrdlus nüüdisaegsete objektidetektori mudelitega

Ülaltoodud joonisel on näidatud tulemused YOLOv7 võrdlemisel mobiilsete ja üldiste GPU-de tipptasemel objektituvastusmudelitega. Võib täheldada, et YOLOv7 algoritmi pakutud meetodil on parim kiiruse ja täpsuse kompromisskoor.
Ablatsiooniuuring: pakutud ühendi skaleerimise meetod

Ülaltoodud joonisel võrreldakse mudeli suurendamiseks erinevate strateegiate kasutamise tulemusi. YOLOv7 mudeli skaleerimisstrateegia suurendab arvutusploki sügavust 1.5 korda ja laiust 1.25 korda.
Võrreldes mudeliga, mis suurendab ainult sügavust, toimib YOLOv7 mudel 0.5% võrra paremini, kasutades vähem parameetreid ja arvutusvõimsust. Teisest küljest, võrreldes mudelitega, mis suurendavad ainult sügavust, paraneb YOLOv7 täpsus 0.2%, kuid parameetrite arvu tuleb skaleerida 2.9% ja arvutusi 1.2%.
Kavandatud planeeritud ümberparameetritega mudel
Selle pakutud ümberparameetristatud mudeli üldistuse kontrollimiseks YOLOv7 algoritm kasutab seda kontrollimiseks jääk- ja konkatenatsioonipõhistel mudelitel. Kinnitusprotsessi jaoks kasutab YOLOv7 algoritm 3-virnaline ELAN konkatenatsioonipõhise mudeli jaoks ja CSPDarknet jääkpõhise mudeli jaoks.
Konkateneerimisel põhineva mudeli puhul asendab algoritm 3-virnalise ELAN-i 3 × 3 konvolutsioonikihid RepConv-ga. Alloleval joonisel on näidatud Planned RepConvi ja 3-virnalise ELAN-i üksikasjalik konfiguratsioon.
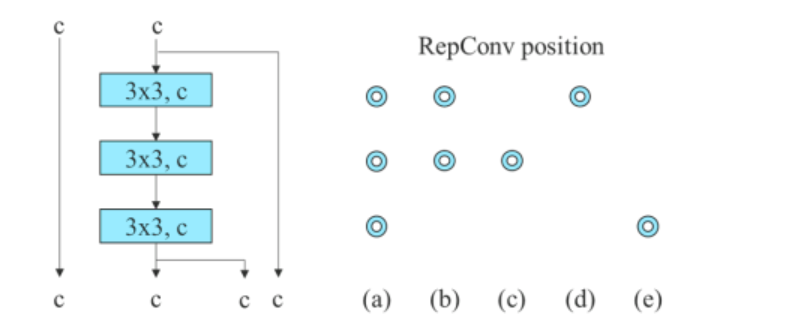
Lisaks kasutab YOLOv7 algoritm jääkpõhise mudeli käsitlemisel vastupidist tumedat plokki, kuna algsel tumedal plokil pole 3 × 3 konvolutsiooniplokki. Alloleval joonisel on kujutatud Reversed CSPDarkneti arhitektuur, mis muudab 3 × 3 ja 1 × 1 konvolutsioonikihi positsioonid vastupidiseks. 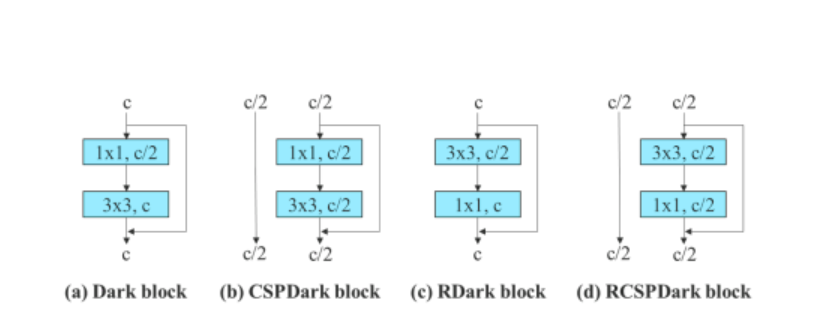
Kavandatud abijuhi assistendi kaotus
Abipea abikao jaoks võrdleb YOLOv7 mudel abipea ja juhtpea meetodi sõltumatut sildi määramist.

Ülaltoodud joonis sisaldab kavandatud abipea kohta tehtud uuringu tulemusi. On näha, et mudeli üldine jõudlus suureneb koos assistendi kaotuse suurenemisega. Lisaks toimib YOLOv7 mudelis pakutud müügivihjega juhitav sildi määramine paremini kui sõltumatud müügivihje määramise strateegiad.
YOLOv7 tulemused
Ülaltoodud katsete põhjal on siin YOLov7 jõudluse tulemus võrreldes teiste objektituvastusalgoritmidega.

Ülaltoodud joonisel võrreldakse YOLOv7 mudelit teiste objektituvastusalgoritmidega ning on selgelt näha, et YOLOv7 ületab teisi vastuväidete tuvastamise mudeleid. Average Precision (AP) v/s partii häired.
Lisaks võrreldakse alloleval joonisel YOLOv7 v/s teiste reaalajas vastuväidete tuvastamise algoritmide jõudlust. Taas saavutab YOLOv7 teiste mudelite edu üldise jõudluse, täpsuse ja tõhususe osas.

Siin on mõned täiendavad tähelepanekud YOLOv7 tulemustest ja esitustest.
- YOLOv7-Tiny on YOLO perekonna väikseim mudel, millel on üle 6 miljoni parameetri. YOLOv7-Tiny keskmine täpsus on 35.2% ja see ületab võrreldavate parameetritega YOLOv4-Tiny mudeleid.
- YOLOv7 mudelil on üle 37 miljoni parameetri ja see edestab kõrgemate parameetritega mudeleid, nagu YOLov4.
- YOLOv7 mudelil on suurim mAP ja FPS kiirus vahemikus 5 kuni 160 kaadrit sekundis.
Järeldus
YOLO ehk You Only Look Once on kaasaegse arvutinägemise objektide tuvastamise mudel. YOLO algoritm on tuntud oma suure täpsuse ja tõhususe poolest ning seetõttu leiab see laialdast rakendust objektide reaalajas tuvastamise valdkonnas. Alates esimese YOLO algoritmi kasutuselevõtust 2016. aastal on katsed võimaldanud arendajatel mudelit pidevalt täiustada.
YOLOv7 mudel on YOLO perekonna uusim täiendus ja see on seni võimsaim YOLo algoritm. Selles artiklis oleme rääkinud YOLOv7 põhitõdedest ja püüdnud selgitada, mis teeb YOLOv7 nii tõhusaks.















