Inteligencia artificial
MIT: Medir el sesgo de los medios en los principales medios de comunicación con aprendizaje automático

Un estudio de MIT ha utilizado técnicas de aprendizaje automático para identificar un lenguaje sesgado en alrededor de 100 de los medios de comunicación más grandes y más influyentes en EE. UU. y más allá, incluyendo 83 de las publicaciones de noticias impresas más influyentes. Es un esfuerzo de investigación que muestra el camino hacia sistemas automatizados que podrían auto-clasificar el carácter político de una publicación, y dar a los lectores una visión más profunda de la postura ética de un medio sobre temas que pueden sentir apasionadamente.
El trabajo se centra en la forma en que se abordan los temas con un lenguaje particular, como inmigrante indocumentado | inmigrante ilegal, feto | bebé nonato, manifestantes | anarquistas.
El proyecto utilizó técnicas de Procesamiento de Lenguaje Natural (NLP) para extraer y clasificar tales instancias de ‘lenguaje cargado’ (con la suposición de que los términos aparentemente más ‘neutrales’ también representan una postura política) en un mapa amplio que revela el sesgo de izquierda y derecha en más de tres millones de artículos de alrededor de 100 medios de comunicación, lo que resulta en un paisaje de sesgo navegable de las publicaciones en cuestión.
El artículo proviene de Samantha D’Alonzo y Max Tegmark del Departamento de Física de MIT, y observa que varias iniciativas recientes sobre ‘verificación de hechos’, en el contexto de numerosos escándalos de ‘noticias falsas’, pueden ser interpretadas como poco sinceras y servir a los intereses de ciertos grupos. El proyecto pretende proporcionar un enfoque más basado en datos para estudiar el uso de sesgo y ‘lenguaje de influencia’ en un contexto de noticias supuestamente neutrales.

Un espectro de frases, literal y figurativamente de izquierda a derecha, derivado del estudio. Fuente: https://arxiv.org/pdf/2109.00024.pdf
Procesamiento de NLP
Los datos de origen del estudio se obtuvieron de la base de datos de código abierto Newspaper3K, y comprendieron 3.078.624 artículos obtenidos de 100 fuentes de noticias, incluyendo 83 periódicos. Los periódicos se seleccionaron en función de su alcance, mientras que las fuentes de medios en línea también incluyeron artículos del sitio de análisis de noticias militares Defense One, y Ciencia.

Las fuentes utilizadas en el estudio.
El artículo informa que el texto descargado se ‘procesó mínimamente’. Se eliminaron las citas directas, ya que el estudio se centra en el lenguaje elegido por los periodistas (aunque la selección de citas es en sí misma un campo de estudio interesante).
Se cambiaron las grafías británicas a americanas para estandarizar la base de datos, se eliminaron todos los signos de puntuación y se eliminaron todos los números ordinales. La capitalización inicial de las oraciones se convirtió a minúsculas, pero se conservó toda la capitalización restante.
Se identificaron y clasificaron las primeras 100.000 frases más comunes, y finalmente se clasificaron, purgaron y fusionaron en una lista de frases. Todo el lenguaje redundante que se pudiera identificar (como ‘Compartir este artículo’ y ‘artículo republicado’) se eliminó. Las variaciones en frases esencialmente idénticas (es decir, ‘tecnología grande’ y ‘Big Tech’, ‘seguridad cibernética’ y ‘cyber security’) se estandarizaron.
‘Nutpicking’
La primera prueba se realizó sobre el tema ‘Black lives matter’, y pudo discernir el sesgo de frases y sinónimos valentes en los datos.
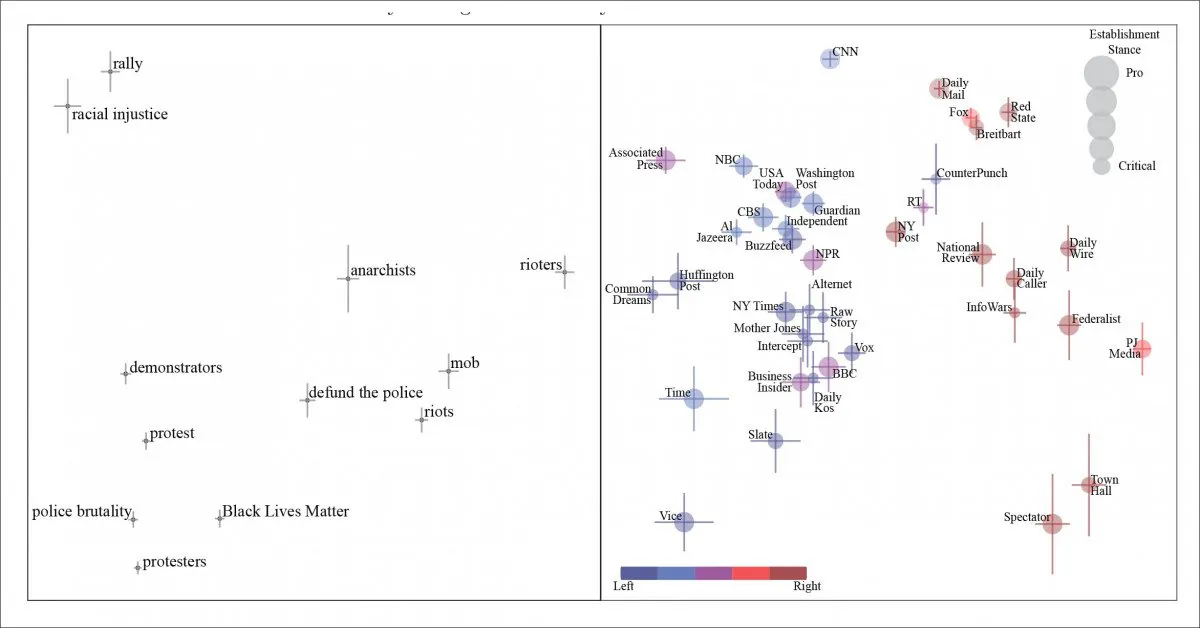
Componentes principales generalizados para artículos sobre Black Lives Matter (BLM). Vemos a personas participando en acción civil caracterizadas, literal y figurativamente de izquierda a derecha, como manifestantes, anarquistas y, en el extremo derecho del espectro, como ‘alborotadores’. Los periódicos que originaron la frase se representan en el panel de la derecha.
Mientras que ‘protestantes’ transitan de ‘anarquistas’ a ‘alborotadores’ a medida que nos desplazamos a lo largo de la postura política del medio en cuestión, el artículo señala que la extracción y análisis de NLP se ve obstaculizada por la práctica de ‘nutpicking’ – donde un medio de comunicación citará una frase que se considera válida por un segmento político diferente de la sociedad, y puede (aparentemente) confiar en que su audiencia vea la frase de manera negativa. El artículo cita ‘desfinanciar a la policía’ como un ejemplo de esto.
Naturalmente, esto significa que una frase ‘de izquierda’ aparece en un contexto de derecha, y representa un desafío inusual para un sistema de NLP que confía en frases codificadas para actuar como indicadores de posturas políticas.
Tales frases son ‘bi-valentes’ [SIC], mientras que ciertas otras frases tienen una connotación negativa tan universal (es decir, ‘infanticidio’) que siempre se representan como negativas en una variedad de medios.
La investigación también revela mapeos similares para temas ‘calientes’ como el aborto, la censura de la tecnología, la inmigración en EE. UU. y el control de armas.
Hobby Horses
Hay ciertas inclinaciones políticas controvertidas en los medios de comunicación que no se dividen de manera predecible de esta manera, como el tema del gasto militar. El artículo encontró que ‘izquierdista’ CNN terminó junto a la derechista National Review y Fox News sobre este tema.
En general, sin embargo, la postura política puede determinarse por otras frases, como preferir la frase ‘complejo militar-industrial’ sobre la más derechista ‘industria de la defensa’. Los resultados muestran que la primera se utiliza por medios críticos con el establishment como Canary y American Conservative, mientras que la segunda se utiliza con más frecuencia por Fox y CNN.
La investigación establece varias otras progresiones desde el lenguaje crítico con el establishment hasta el lenguaje pro-establishment, incluyendo el espectro desde ‘disparado’ hasta el más pasivo ‘el asesinato de’; ‘reclusos delincuentes’ a ‘personas encarceladas’; y ‘productores de petróleo’ a ‘petróleo grande’.

Sinónimos valentes con sesgo de establishment, de arriba a abajo.
La investigación reconoce que los medios pueden ‘alejarse’ de su postura política base, ya sea a nivel lingüístico (como el uso de frases bi-valentes), o por diversas otras motivaciones. Por ejemplo, la venerable publicación derechista del Reino Unido The Spectator, establecida en 1828, frecuentemente y prominentemente presenta artículos de pensamiento de izquierda que se oponen a la corriente política general de su flujo de contenido. Si esto se hace por un sentido de informe imparcial o para inflamar periódicamente a su audiencia principal en tormentas de comentarios que generan tráfico es una cuestión de conjetura – y no es un caso fácil para un sistema de aprendizaje automático que busca tokens claros y consistentes.
Estos ‘hobby horses’ y el uso ambiguo de ‘puntos de vista discordantes’ entre los medios de comunicación individuales confunden ligeramente el mapeo de izquierda a derecha que la investigación ofrece en última instancia, aunque proporciona una indicación general de afiliación política.

Significado retenido
Aunque está fechado el 2 de septiembre y publicado a fines de agosto de 2021, el artículo ha ganado relativamente poca tracción. Parcialmente, esto podría deberse a que la investigación crítica dirigida a los medios de comunicación principales es poco probable que sea recibida con entusiasmo por ellos; pero también podría deberse a la reluctancia de los autores a producir gráficos claros y inequívocos que estratifican dónde se encuentran los medios de comunicación influyentes y poderosos en varios temas, junto con valores agregados que indican el grado en que una publicación se inclina hacia la izquierda o la derecha. En efecto, los autores parecen tomar medidas para mitigar el efecto potencialmente incendiario de los resultados.
Asimismo, los datos extensos publicados del proyecto muestran recuentos de frecuencia de incidentes de palabras, pero parecen estar anonimizados, lo que hace difícil obtener una visión clara del sesgo de los medios en las publicaciones estudiadas. Sin operativizar el proyecto de alguna manera, esto solo deja los ejemplos seleccionados presentados en el artículo.
Estudios posteriores de este tipo podrían ser más útiles si consideraran no solo el lenguaje utilizado para los temas, sino si el tema se cubrió en absoluto, ya que el silencio habla por sí mismo, y tiene en sí mismo un carácter político distinto que a menudo habla de más que solo limitaciones presupuestarias u otros factores pragmáticos que pueden informar la selección de noticias.
Sin embargo, el estudio de MIT parece ser el más grande de su tipo hasta la fecha, y podría formar el marco para sistemas de clasificación futuros, e incluso tecnologías secundarias como complementos de navegador que podrían alertar a los lectores casuales al color político de la publicación que están leyendo actualmente.
Burbujas, sesgo y reacción
Además, tendría que considerarse si tales sistemas further comprenderían uno de los aspectos más controvertidos de los sistemas de recomendación algorítmicos – la tendencia a llevar a un espectador a entornos donde nunca vea una perspectiva contrastante o desafiante, lo que probablemente retrenchería aún más la postura del lector sobre cuestiones clave.
Si dicha burbuja de contenido es un ‘entorno seguro’, un impedimento para el crecimiento intelectual, o una protección contra la propaganda parcial, es un juicio de valor – un asunto filosófico que es difícil de abordar desde el punto de vista mecanicista y estadístico de los sistemas de aprendizaje automático.
Además, al igual que el estudio de MIT ha tomado medidas para dejar que los datos definan los resultados, la clasificación del valor político de las frases es inevitablemente también un tipo de juicio de valor, y uno que no puede fácilmente resistir la capacidad del lenguaje para recodificar contenido tóxico o controvertido en frases nuevas que no están en el manual, las reglas del foro o la base de datos de entrenamiento.
Si una codificación de este tipo se incorporara en sistemas en línea populares, es probable que un esfuerzo continuo para mapear la temperatura ética y política de los principales medios de comunicación podría desarrollarse en una guerra fría entre la capacidad de los sistemas de IA para discernir el sesgo y la capacidad de los editores para expresar su punto de vista en un idioma en evolución diseñado para superar rutinariamente la comprensión de la semántica del aprendizaje automático.
14/09/21 – 1.41 GMT+2 – Cambiado ‘100 periódicos’ a ‘100 medios de comunicación’
4:58pm – Corregida la cita del artículo para incluir a Samantha D’Alonzo, y correcciones relacionadas.












