
Intel·ligència Artificial
StyleTTS 2: Text-to-Speech a nivell humà amb grans models de llenguatge de parla

A causa de l'augment dels enfocaments de síntesi de veu naturals i sintètiques, un dels principals èxits que ha aconseguit la indústria de l'IA en els últims anys és sintetitzar eficaçment marcs de text a veu amb aplicacions potencials en diferents indústries, com ara audiollibres, assistents virtuals, veu. -Més de narracions i més, amb alguns modes d'última generació que ofereixen un rendiment i una eficiència a nivell humà en una àmplia gamma de tasques relacionades amb la parla. No obstant això, malgrat el seu bon rendiment, encara hi ha marge de millora per a les tasques gràcies a la parla expressiva i diversa, la necessitat d'una gran quantitat de dades d'entrenament per optimitzar els marcs de veu de text zero-shot i la robustesa dels textos OOD o fora de distribució que lideren desenvolupadors per treballar en un marc de text a veu més robust i accessible.
En aquest article, parlarem de StyleTTS-2, un marc de text a veu robust i innovador que es basa en els fonaments del marc StyleTTS i té com a objectiu presentar el següent pas cap als sistemes de text a veu d'última generació. El marc StyleTTS2 modela els estils de parla com a variables aleatòries latents i utilitza un model de difusió probabilística per a mostres d'aquests estils de parla o variables aleatòries, permetent així al marc StyleTTS2 sintetitzar parla realista de manera eficaç sense utilitzar entrades d'àudio de referència. A causa de l'enfocament, el marc StyleTTS2 és capaç d'oferir millors resultats i mostra una alta eficiència en comparació amb els marcs actuals de text a veu, però també és capaç d'aprofitar la diversa síntesi de veu que ofereixen els marcs de models de difusió. Parlarem del framework StyleTTS2 amb més detall i parlarem de la seva arquitectura i metodologia alhora que analitzarem els resultats aconseguits pel framework. Així que comencem.
StyleTTS2 per a la síntesi de text a veu: una introducció
StyleTTS2 és un model innovador de síntesi de text a veu que fa el següent pas cap a la construcció de marcs TTS a nivell humà, i es basa en StyleTTS, un text basat en estil per model generatiu de la parla. El marc StyleTTS2 modela els estils de parla com a variables aleatòries latents i utilitza un model de difusió probabilista per a mostres d'aquests estils de parla o variables aleatòries, permetent així al marc StyleTTS2 sintetitzar parla realista de manera eficaç sense utilitzar entrades d'àudio de referència. El modelatge d'estils com a variables aleatòries latents és el que separa el marc StyleTTS2 del seu predecessor, el marc StyleTTS, i té com a objectiu generar l'estil de parla més adequat per al text d'entrada sense necessitat d'una entrada d'àudio de referència, i és capaç d'aconseguir difusions latents efectives mentre es pren. avantatge de les diverses capacitats de síntesi de parla que ofereix models de difusió. A més, el marc StyleTTS2 també utilitza un model de llenguatge de parla o SLM gran pre-entrenat com a discriminadors com el marc WavLM, i l'acobla amb el seu propi enfocament nou de modelització de durada diferencial per entrenar el marc d'extrem a extrem i, finalment, generar parla amb una naturalitat millorada. Gràcies a l'enfocament que segueix, el marc StyleTTS2 supera els marcs actuals d'última generació per a tasques de generació de parla i és un dels marcs més eficients per a la formació prèvia de models de parla a gran escala en un entorn zero per a les tasques d'adaptació dels altaveus.
Avançant, per oferir una síntesi de veu a nivell humà, el marc StyleTTs2 incorpora els aprenentatges dels treballs existents, inclosos els models de difusió per a la síntesi de la parla i els grans models de llenguatge de parla. Els models de difusió s'utilitzen generalment per a tasques de síntesi de parla gràcies a les seves capacitats de control de la parla de gra fi i diverses capacitats de mostreig de la parla. Tanmateix, els models de difusió no són tan eficients com els marcs no iteratius basats en GAN i una de les raons principals d'això és el requisit de mostrejar representacions latents, formes d'ona i espectrogrames mel de manera iterativa fins a la durada objectiu del discurs.
D'altra banda, treballs recents al voltant dels grans models de llenguatge de parla han indicat la seva capacitat per millorar la qualitat de les tasques de generació de text a veu i adaptar-se bé al parlant. Els models de llenguatge de parla grans solen convertir l'entrada de text en representacions quantificades o contínues derivades de marcs de llenguatge de parla prèviament entrenats per a tasques de reconstrucció de la parla. Tanmateix, les característiques d'aquests models de llenguatge de parla no estan optimitzades per a la síntesi de parla directament. En canvi, el marc StyleTTS2 aprofita els coneixements adquirits pels grans marcs SLM que utilitzen entrenament adversari per sintetitzar les característiques dels models de llenguatge de parla sense utilitzar mapes espacials latents i, per tant, l'aprenentatge d'una síntesi de parla optimitza l'espai latent directament.
StyleTTS2: Arquitectura i Metodologia
En el seu nucli, StyleTTS2 es basa en el seu predecessor, el marc StyleTTS, que és un marc de text a veu no autoregressiu que fa ús d'un codificador d'estil per derivar un vector d'estil a partir de l'àudio de referència, permetent així una generació de parla expressiva i natural. El vector d'estil utilitzat al marc StyleTTS s'incorpora directament al codificador, la durada i els predictors fent ús d'AdaIN o Adaptive Instance Normalization, permetent així que el model StyleTTS generi sortides de parla amb diferents prosòdies, durades i fins i tot emocions. El marc StyleTTS consta de 8 models en total que es divideixen en tres categories
- Models acústics o sistema de generació de veu amb un codificador d'estil, un codificador de text i un descodificador de veu.
- Un sistema de predicció de text a veu que fa ús de predictors de prosòdia i durada.
- Un sistema d'utilitat que inclou un alineador de text, un extractor de to i un discriminador amb finalitats d'entrenament.
Gràcies al seu enfocament, el marc StyleTTS ofereix un rendiment d'última generació relacionat amb una síntesi de veu controlable i diversa. Tanmateix, aquest rendiment té els seus inconvenients com la degradació de la qualitat de la mostra, les limitacions expressives i la dependència d'aplicacions que dificulten la parla en temps real.
Millorant el marc StyleTTS, el model StyleTTS2 dóna com a resultat una millora expressiva text a veu tasques amb un millor rendiment fora de distribució i una alta qualitat a nivell humà. El marc StyleTTS2 fa ús d'un procés d'entrenament extrem a extrem que optimitza els diferents components amb l'entrenament adversari i la síntesi directa de formes d'ona conjuntament. A diferència del marc StyleTTS, el marc StyleTTS2 modela l'estil de parla com una variable latent i el mostra mitjançant models de difusió generant així diverses mostres de parla sense utilitzar un àudio de referència. Fem una ullada detallada a aquests components.
Entrenament d'extrem a extrem per a la interferència
En el marc StyleTTS2, s'utilitza un enfocament d'entrenament d'extrem a extrem per optimitzar diversos components de text a veu per a la interferència sense haver de dependre de components fixos. El marc StyleTTS2 ho aconsegueix modificant el descodificador per generar la forma d'ona directament a partir del vector d'estil, les corbes de to i energia i les representacions alineades. Aleshores, el marc elimina l'última capa de projecció del descodificador i la substitueix per un descodificador de forma d'ona. El marc StyleTTS2 fa ús de dos codificadors: un descodificador basat en HifiGAN per generar la forma d'ona directament i un descodificador basat en iSTFT per produir fase i magnitud que es converteixen en formes d'ona per a una interferència i un entrenament més ràpids.
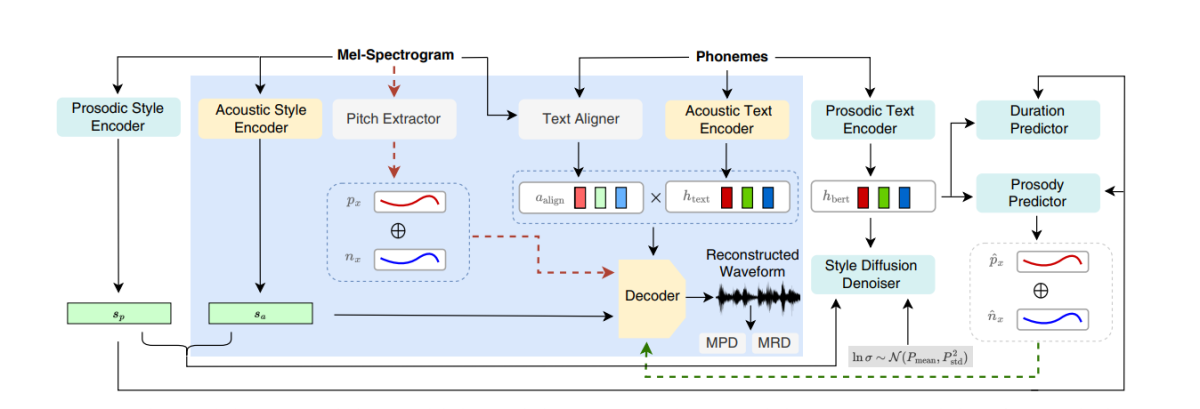
La figura anterior representa els models acústics utilitzats per a l'entrenament previ i l'entrenament conjunt. Per reduir el temps d'entrenament, primer s'optimitzen els mòduls en la fase prèvia a l'entrenament, seguida de l'optimització de tots els components menys l'extractor de camp durant l'entrenament conjunt. La raó per la qual l'entrenament conjunt no optimitza l'extractor de to és perquè s'utilitza per proporcionar la veritat del terreny per a les corbes de to.

La figura anterior representa l'entrenament adversari del model de parla i la interferència amb el marc WavLM prèviament entrenat però no ajustat prèviament. El procés és diferent de l'esmentat anteriorment, ja que pot prendre diferents textos d'entrada, però acumula els gradients per actualitzar els paràmetres de cada lot.
Difusió d'estil
El marc StyleTTS2 pretén modelar la parla com una distribució condicional mitjançant una variable latent que segueix la distribució condicional, i aquesta variable s'anomena estil de parla generalitzat i representa qualsevol característica de la mostra de parla més enllà de l'abast de qualsevol contingut fonètic inclòs l'accent lèxic. prosòdia, ritme de parla i fins i tot transicions formants.
Discriminadors de models de parla i llenguatge
Els models de llenguatge de parla són coneguts per les seves habilitats generals per codificar informació valuosa sobre una àmplia gamma d'aspectes semàntics i acústics, i les representacions SLM han estat tradicionalment capaços d'imitar les percepcions humanes per avaluar la qualitat de la parla sintetitzada generada. El marc StyleTTS2 utilitza un enfocament d'entrenament adversari per utilitzar la capacitat dels codificadors SLM per realitzar tasques generatives i utilitza un marc WavLM de 12 capes com a discriminador. Aquest enfocament permet que el marc permeti la formació sobre textos OOD o Out Of Distribution que poden ajudar a millorar el rendiment. A més, per evitar problemes d'ajustament excessiu, el marc mostra els textos OOD i la distribució amb la mateixa probabilitat.
Modelització de durada diferenciable
Tradicionalment, s'utilitza un predictor de durada en marcs de text a veu que produeix durades de fonema, però els mètodes de mostreig superior que utilitzen aquests predictors de durada sovint bloquegen el flux de gradient durant el procés d'entrenament E2E, i el marc NaturalSpeech empra un mostrador basat en l'atenció per a nivell humà. conversió de text a veu. Tanmateix, el marc StyleTTS2 considera que aquest enfocament és inestable durant l'entrenament adversari perquè l'StyleTTS2 s'entrena utilitzant un mostreig diferenciable amb diferents entrenaments adversaris sense la pèrdua de termes addicionals a causa del desajust en la longitud a causa de les desviacions. Tot i que l'ús d'un enfocament de deformació del temps dinàmica suau pot ajudar a mitigar aquest desajust, utilitzar-lo no només és car computacionalment, sinó que la seva estabilitat també és una preocupació quan es treballa amb objectius adversaris o tasques de reconstrucció de mel. Per tant, per aconseguir un rendiment a nivell humà amb entrenament adversari i estabilitzar el procés d'entrenament, el marc StyleTTC2 utilitza un enfocament de mostreig no paramètric. El sobremostreig gaussià és un enfocament popular de mostreig no paramètric per convertir les durades previstes, tot i que té les seves limitacions gràcies a la longitud fixa dels nuclis gaussians predeterminada. Aquesta restricció per al mostreig gaussià limita la seva capacitat de modelar amb precisió alineacions amb diferents longituds.
Per trobar aquesta limitació, el marc StyleTTC2 proposa utilitzar un nou enfocament de mostreig no paramètric sense cap formació addicional i capaç de comptabilitzar diferents longituds de les alineacions. Per a cada fonema, el marc StyleTTC2 modela l'alineació com una variable aleatòria i indica l'índex del marc de parla amb el qual s'alinea el fonema.
Model de Formació i Avaluació
El marc StyleTTC2 s'entrena i s'experimenta en tres conjunts de dades: VCTK, LibriTTS i LJSpeech. El component d'un sol altaveu del marc StyleTTS2 s'entrena mitjançant el conjunt de dades LJSpeech que conté aproximadament 13,000 mostres d'àudio dividides en 12,500 mostres d'entrenament, 100 mostres de validació i prop de 500 mostres de prova, amb un temps d'execució combinat de gairebé 24 hores. El component de diversos altaveus del marc s'entrena al conjunt de dades VCTK que consta de més de 44,000 clips d'àudio amb més de 100 parlants nadius individuals amb diferents accents, i es divideix en 43,500 mostres d'entrenament, 100 mostres de validació i prop de 500 mostres de prova. Finalment, per equipar el marc amb capacitats d'adaptació zero-shot, el marc s'entrena en el conjunt de dades LibriTTS combinat que consta de clips d'àudio que sumen unes 250 hores d'àudio amb més de 1,150 altaveus individuals. Per avaluar el seu rendiment, el model utilitza dues mètriques: MOS-N o Puntuació d'opinió mitjana de naturalitat, i MOLSA o Puntuació mitjana d'opinió de semblança.

Resultats
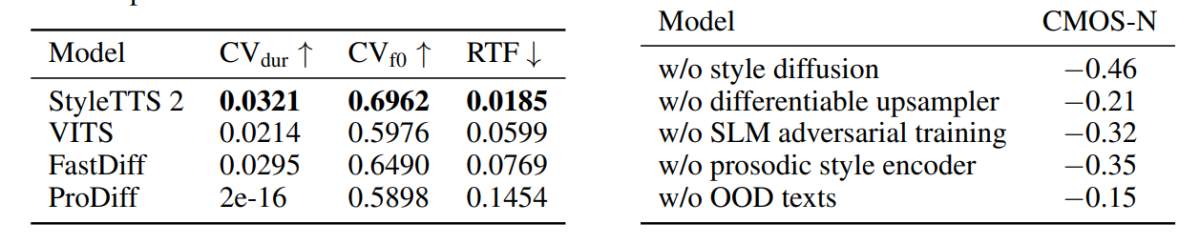
L'enfocament i la metodologia utilitzats al marc StyleTTS2 es mostren en el seu rendiment, ja que el model supera diversos marcs TTS d'última generació, especialment al conjunt de dades NaturalSpeech, i en ruta, establint un nou estàndard per al conjunt de dades. A més, el marc StyleTTS2 supera el marc VITS d'última generació al conjunt de dades VCTK, i els resultats es mostren a la figura següent.

El model StyleTTS2 també supera els models anteriors al conjunt de dades LJSpeech i no mostra cap grau de degradació de la qualitat en textos OOD o fora de distribució tal com es mostra en marcs anteriors amb les mateixes mètriques. A més, en la configuració zero-shot, el model StyleTTC2 supera el marc Vall-E existent en naturalitat, tot i que es queda endarrerit en termes de similitud. No obstant això, val la pena assenyalar que el marc StyleTTS2 és capaç d'aconseguir un rendiment competitiu malgrat l'entrenament només amb 245 hores de mostres d'àudio en comparació amb més de 60 hores de formació per al framework Vall-E, demostrant així que StyleTTC2 és una alternativa eficient en dades. als grans mètodes de preformació existents com s'utilitzen a la Vall-E.

Avançant, a causa de la manca de dades de text d'àudio etiquetades amb emoció, el marc StyleTTC2 utilitza el model GPT-4 per generar més de 500 instàncies a través de diferents emocions per a la visualització de vectors d'estil que el marc crea amb el seu radiodifusió procés.

A la primera figura, els estils emocionals en resposta als sentiments del text d'entrada estan il·lustrats pels vectors d'estil del model LJSpeech, i demostra la capacitat del marc StyleTTC2 per sintetitzar un discurs expressiu amb emocions variades. La segona figura representa diferents grups de forma per a cadascun dels cinc altaveus individuals, representant així una àmplia gamma de diversitat procedent d'un únic fitxer d'àudio. La figura final demostra el grup fluix d'emocions de l'altaveu 1 i revela que, malgrat algunes superposicions, els grups basats en les emocions són destacats, indicant així la possibilitat de manipular la melodia emocional d'un altaveu independentment de la mostra d'àudio de referència i el seu to d'entrada. . Tot i utilitzar un enfocament basat en la difusió, el marc StyleTTS2 aconsegueix superar els marcs d'última generació existents, inclosos VITS, ProDiff i FastDiff.
Consideracions finals
En aquest article, hem parlat de StyleTTS2, un marc de text a veu nou, robust i innovador que es basa en els fonaments del marc StyleTTS i té com a objectiu presentar el següent pas cap als sistemes de text a veu d'última generació. El marc StyleTTS2 modela els estils de parla com a variables aleatòries latents i utilitza un model de difusió probabilista per a mostres d'aquests estils de parla o variables aleatòries, permetent així que el marc StyleTTS2 sintetitzar la parla realista de manera eficaç sense utilitzar entrades d'àudio de referència. El marc StyleTTS2 utilitza discriminadors de difusió d'estil i SLM. per aconseguir un rendiment a nivell humà en tasques de text a veu i aconsegueix superar els marcs d'última generació existents en una àmplia gamma de tasques de parla.



