Intel·ligència Artificial
MagicDance: generació de vídeos de dansa humana realista

La visió per ordinador és un dels camps més discutits a la indústria de la IA, gràcies a les seves aplicacions potencials en una àmplia gamma de tasques en temps real. En els últims anys, els marcs de visió per ordinador han avançat ràpidament, amb models moderns capaços d'analitzar trets facials, objectes i molt més en escenaris en temps real. Malgrat aquestes capacitats, la transferència de moviment humà segueix sent un repte formidable per als models de visió per ordinador. Aquesta tasca consisteix a reorientar els moviments facials i corporals d'una imatge o vídeo d'origen a una imatge o vídeo objectiu. La transferència de moviment humà s'utilitza àmpliament en models de visió per ordinador per dissenyar imatges o vídeos, editar contingut multimèdia, síntesi humana digital i fins i tot generar dades per a marcs basats en la percepció.
En aquest article, ens centrem en MagicDance, un model basat en la difusió dissenyat per revolucionar la transferència de moviment humà. El marc de MagicDance pretén específicament transferir expressions i moviments facials humans en 2D a vídeos de dansa humana desafiants. El seu objectiu és generar nous vídeos de dansa basats en seqüències de poses per a identitats objectiu específiques mantenint la identitat original. El marc de MagicDance empra una estratègia d'entrenament en dues etapes, centrada en la separació del moviment humà i factors d'aparença com el to de la pell, les expressions facials i la roba. Aprofundirem en el marc de MagicDance, explorant la seva arquitectura, funcionalitat i rendiment en comparació amb altres marcs de transferència de moviment humà d'última generació. Submergem-nos.
MagicDance: transferència de moviment humà realista
Com s'ha esmentat anteriorment, la transferència de moviment humà és una de les tasques de visió per ordinador més complexes a causa de la gran complexitat que implica la transferència de moviments i expressions humanes de la imatge o vídeo d'origen a la imatge o vídeo objectiu. Tradicionalment, els marcs de visió per ordinador han aconseguit la transferència del moviment humà entrenant un model generatiu específic de la tasca que inclou GAN o Xarxes adversàries generatives sobre conjunts de dades objectiu per a expressions facials i postures corporals. Tot i que la formació i l'ús de models generatius donen resultats satisfactoris en alguns casos, solen patir dues limitacions principals.
- Depenen molt d'un component de deformació de la imatge com a resultat del qual sovint lluiten per interpolar parts del cos invisibles a la imatge d'origen, ja sigui a causa d'un canvi de perspectiva o d'una autooclusió.
- No poden generalitzar-se a altres imatges d'origen extern, cosa que limita les seves aplicacions, especialment en escenaris en temps real a la natura.

Els models de difusió moderns han demostrat capacitats excepcionals de generació d'imatges en diferents condicions, i els models de difusió ara són capaços de presentar visuals potents en una sèrie de tasques posteriors, com ara la generació de vídeo i la pintura d'imatges aprenent a partir de conjunts de dades d'imatges a escala web. A causa de les seves capacitats, els models de difusió poden ser una opció ideal per a tasques de transferència de moviment humà. Tot i que es poden implementar models de difusió per a la transferència de moviment humà, té algunes limitacions, ja sigui pel que fa a la qualitat del contingut generat, o pel que fa a la preservació de la identitat o patint inconsistències temporals com a resultat del disseny del model i els límits de l'estratègia de formació. A més, els models basats en difusió no mostren cap avantatge significatiu Marcs GAN en termes de generalització.
Per superar els obstacles als quals s'enfronten els marcs de difusió i GAN basats en tasques de transferència de moviment humà, els desenvolupadors han introduït MagicDance, un nou marc que té com a objectiu explotar el potencial dels marcs de difusió per a la transferència de moviment humà demostrant un nivell sense precedents de preservació de la identitat, una qualitat visual superior, i generalització del domini. En el seu nucli, el concepte fonamental del marc MagicDance és dividir el problema en dues etapes: control de l'aparença i control del moviment, dues capacitats requerides pels marcs de difusió d'imatges per oferir sortides precises de transferència de moviment.

La figura anterior ofereix una breu visió general del marc de MagicDance i, com es pot veure, el marc utilitza el Model de difusió estable, i també desplega dos components addicionals: Model de control d'aparença i Pose ControlNet, on el primer proporciona una guia d'aparença al model SD a partir d'una imatge de referència mitjançant l'atenció, mentre que el segon proporciona una guia d'expressió/posició al model de difusió a partir d'una imatge o un vídeo condicionats. El marc també utilitza una estratègia d'entrenament en diverses etapes per aprendre aquests submòduls de manera eficaç per desvincular el control de la postura i l'aparença.
En resum, el marc de MagicDance és un
- Marc nou i eficaç que consisteix en un control de poses desvinculat de l'aparença i un entrenament previ al control de l'aparença.
- El marc de MagicDance és capaç de generar expressions facials humanes realistes i moviment humà sota el control de les entrades de condicions de posada i imatges o vídeos de referència.
- El marc de MagicDance pretén generar contingut humà coherent amb l'aparença mitjançant la introducció d'un mòdul d'atenció multifont que ofereix una guia precisa per al marc UNet de difusió estable.
- El marc MagicDance també es pot utilitzar com a extensió o complement convenient per al marc Stable Diffusion, i també garanteix la compatibilitat amb els pesos del model existents, ja que no requereix un ajustament addicional dels paràmetres.
A més, el marc MagicDance mostra capacitats de generalització excepcionals tant per a la generalització de l'aparença com del moviment.
- Generalització de l'aparença: el marc MagicDance demostra capacitats superiors quan es tracta de generar aparences diverses.
- Generalització de moviments: el marc de MagicDance també té la capacitat de generar una àmplia gamma de moviments.
MagicDance: Objectius i Arquitectura
Per a una imatge de referència determinada, ja sigui d'un humà real o d'una imatge estilitzada, l'objectiu principal del marc de MagicDance és generar una imatge de sortida o un vídeo de sortida condicionat a l'entrada i les entrades de posada {P, F} on P representa la postura humana. esquelet i F representa les fites facials. La imatge de sortida generada o el vídeo hauria de ser capaç de preservar l'aspecte i la identitat dels humans implicats juntament amb el contingut de fons present a la imatge de referència, tot conservant la postura i les expressions definides per les entrades de la postura.
arquitectura
Durant l'entrenament, el marc de MagicDance s'entrena com una tasca de reconstrucció de fotogrames per reconstruir la veritat del sòl amb la imatge de referència i l'entrada de poses procedents del mateix vídeo de referència. Durant les proves per aconseguir la transferència de moviment, l'entrada de postura i la imatge de referència s'obtenen de diferents fonts.
L'arquitectura general del marc de MagicDance es pot dividir en quatre categories: fase preliminar, entrenament previ al control de l'aparença, control de la postura desembolicada per l'aparença i mòdul de moviment.
Fase Preliminar
Els models de difusió latent o LDM representen models de difusió dissenyats de manera única per operar dins de l'espai latent facilitat per l'ús d'un codificador automàtic, i el marc de difusió estable és un exemple notable de LDM que empra un vector Quantized-Variational. Autoencoder i l'arquitectura temporal U-Net. El model de difusió estable utilitza un transformador basat en CLIP com a codificador de text per processar les entrades de text convertint les entrades de text en incrustacions. La fase d'entrenament del marc de difusió estable exposa el model a una condició de text i una imatge d'entrada amb el procés que implica la codificació de la imatge a una representació latent, i el sotmet a una seqüència predefinida de passos de difusió dirigits per un mètode gaussià. La seqüència resultant produeix una representació latent sorollosa que proporciona una distribució normal estàndard amb l'objectiu principal d'aprenentatge del marc de difusió estable que consisteix a eliminar les representacions latents sorolloses de manera iterativa en representacions latents.
Preentrenament de control d'aparença
Un problema important amb el marc de ControlNet original és la seva incapacitat per controlar l'aparença entre moviments que varien espacialment de manera consistent, tot i que tendeix a generar imatges amb posicions molt semblants a les de la imatge d'entrada, amb l'aspecte general influenciat principalment per les entrades textuals. Tot i que aquest mètode funciona, no és adequat per a la transferència de moviment que impliquen tasques on no són les entrades textuals sinó la imatge de referència que serveix com a font principal d'informació d'aparença.
El mòdul d'entrenament previ al control de l'aparença del marc MagicDance està dissenyat com una branca auxiliar per proporcionar una guia per al control de l'aparença en un enfocament capa per capa. En lloc de confiar en les entrades de text, el mòdul general se centra a aprofitar els atributs d'aparença de la imatge de referència amb l'objectiu de millorar la capacitat del marc per generar les característiques d'aparença amb precisió, especialment en escenaris que impliquen dinàmiques de moviment complexes. A més, només el model de control de l'aparença es pot entrenar durant l'entrenament previ al control de l'aparença.
Control de la postura desembolicada en l'aparença
Una solució ingènua per controlar la postura a la imatge de sortida és integrar el model ControlNet prèviament entrenat amb el model de control d'aparença prèviament entrenat directament sense ajustar-los. Tanmateix, la integració pot provocar que el marc lluiti amb un control de posicions independent de l'aparença que pot provocar una discrepància entre les posicions d'entrada i les posicions generades. Per fer front a aquesta discrepància, el marc MagicDance afina el model Pose ControlNet conjuntament amb el model de control d'aparença prèviament entrenat.
Mòdul de moviment
Quan es treballa junts, Pose ControlNet i el model de control d'aparença poden aconseguir una transferència d'imatge a moviment precisa i eficaç, tot i que pot provocar una inconsistència temporal. Per garantir la coherència temporal, el marc integra un mòdul de moviment addicional a l'arquitectura principal de Stable Diffusion UNet.
MagicDance: Pre-entrenament i conjunts de dades
Per a l'entrenament previ, el marc de MagicDance fa ús d'un conjunt de dades de TikTok que consta de més de 350 vídeos de ball de durada variable entre 10 i 15 segons que capturen una sola persona ballant amb la majoria d'aquests vídeos que contenen la cara i la part superior del cos de l'humà. El marc de MagicDance extreu cada vídeo individual a 30 FPS i executa OpenPose a cada fotograma individualment per inferir l'esquelet de la postura, les posicions de la mà i les fites facials.
Per a l'entrenament previ, el model de control d'aparença s'entrena prèviament amb una mida de lot de 64 en 8 GPU NVIDIA A100 durant 10 mil passos amb una mida d'imatge de 512 x 512, seguit d'un ajustament conjunt del control de la postura i dels models de control de l'aparença amb una mida de lot de 16 per 20 mil passos. Durant l'entrenament, el marc MagicDance mostra aleatòriament dos fotogrames com a objectiu i referència respectivament amb les imatges retallades a la mateixa posició a la mateixa alçada. Durant l'avaluació, el model retalla la imatge de manera central en lloc de retallar-la aleatòriament.
MagicDance: Resultats
Els resultats experimentals realitzats amb el marc MagicDance es mostren a la imatge següent i, com es pot veure, el marc MagicDance supera els marcs existents com Disco i DreamPose per a la transferència de moviment humà a través de totes les mètriques. Els marcs que consten d'un "*" davant del seu nom utilitzen la imatge de destinació directament com a entrada i inclouen més informació en comparació amb els altres marcs.
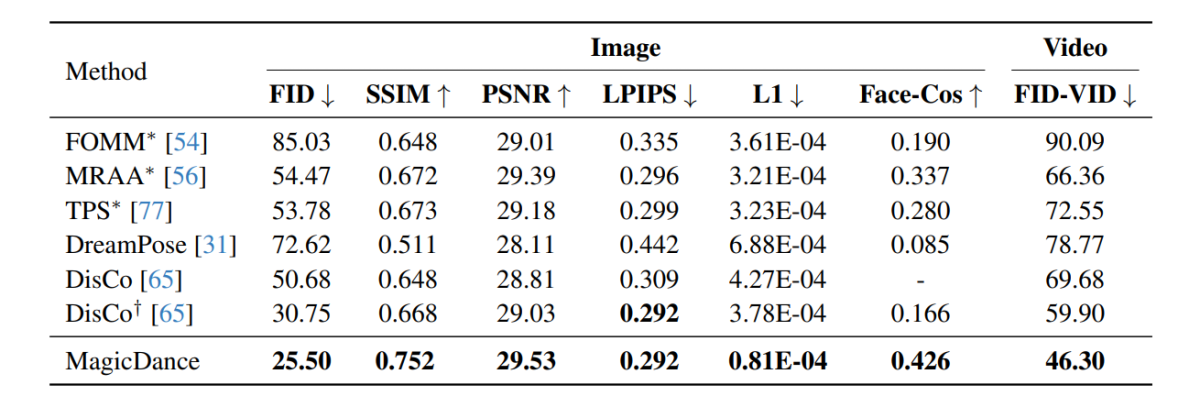
És interessant assenyalar que el marc MagicDance aconsegueix una puntuació de Face-Cos de 0.426, una millora del 156.62% respecte al marc Disco i un augment de gairebé el 400% en comparació amb el marc DreamPose. Els resultats indiquen la robusta capacitat del marc MagicDance per preservar la informació d'identitat, i l'augment visible del rendiment indica la superioritat del marc MagicDance sobre els mètodes d'última generació existents.
Les xifres següents comparen la qualitat de la generació de vídeo humà entre els marcs MagicDance, Disco i TPS. Com es pot observar, els resultats generats pels marcs GT, Disco i TPS pateixen una identitat de posició humana i expressions facials inconsistents.

A més, la imatge següent demostra la visualització de l'expressió facial i la transferència de posicions humanes al conjunt de dades de TikTok amb el marc de MagicDance capaç de generar expressions i moviments realistes i vius sota diversos punts de referència facials i entrades d'esquelets alhora que preserva amb precisió la informació d'identitat de l'entrada de referència. imatge.

Val la pena assenyalar que el marc MagicDance té capacitats de generalització excepcionals per a imatges de referència fora del domini de poses i estils invisibles amb un control d'aparença impressionant, fins i tot sense cap ajustament addicional al domini objectiu, amb els resultats que es demostren a la imatge següent. .

Les imatges següents demostren les capacitats de visualització del marc de MagicDance en termes de transferència d'expressió facial i moviment humà de tir zero. Com es pot veure, el marc de MagicDance es generalitza perfectament als moviments humans salvatges.

MagicDance: Limitacions
OpenPose és un component essencial del marc de MagicDance, ja que té un paper crucial per al control de la postura, afectant de manera significativa la qualitat i la consistència temporal de les imatges generades. Tanmateix, el marc de MagicDance encara troba una mica difícil detectar fites facials i posar esquelets amb precisió, especialment quan els objectes de les imatges són parcialment visibles o mostren un moviment ràpid. Aquests problemes poden provocar artefactes a la imatge generada.
Conclusió
En aquest article, hem parlat de MagicDance, un model basat en la difusió que pretén revolucionar la transferència de moviment humà. El marc de MagicDance intenta transferir expressions i moviments facials humans en 2D en vídeos de dansa humana desafiants amb l'objectiu específic de generar vídeos de dansa humana basats en seqüències de poses noves per a identitats objectiu específiques, mantenint la identitat constant. El marc de MagicDance és una estratègia d'entrenament en dues etapes per a la separació del moviment humà i l'aparença com el to de la pell, les expressions facials i la roba.
MagicDance és un enfocament nou per facilitar la generació de vídeos humans realistes mitjançant la incorporació de la transferència d'expressions facials i de moviment, i permetent una generació d'animació coherent a la natura sense necessitat d'ajustaments addicionals que demostrin un avenç significatiu sobre els mètodes existents. A més, el marc MagicDance demostra capacitats de generalització excepcionals sobre seqüències de moviment complexes i diverses identitats humanes, establint el marc MagicDance com a corredor principal en el camp de la transferència de moviment assistida per IA i la generació de vídeo.












