Intel·ligència Artificial
Com entrenar i utilitzar els models Hunyuan Video LoRA

Aquest article us mostrarà com instal·lar i utilitzar programari basat en Windows que pot entrenar Models de vídeo Hunyuan LoRA, que permet a l'usuari generar personalitats personalitzades en el model de fundació Hunyuan Video:
Feu clic per jugar. Exemples de la recent explosió de celebritats Hunyuan LoRA de la comunitat civit.ai.
Actualment, les dues maneres més populars de generar models Hunyuan LoRA a nivell local són:
1) La diffusion-pipe-ui marc basat en Docker, que es basa Subsistema de Windows per a Linux (WSL) per gestionar alguns dels processos.
2) Sintonitzador Musubi, una nova incorporació al popular Kohya ss Arquitectura de formació de difusió. Musubi Tuner no requereix Docker i no depèn de WSL ni d'altres servidors intermediaris basats en Linux, però pot ser difícil posar-se en marxa a Windows.
Per tant, aquesta prova se centrarà en Musubi Tuner i en proporcionar una solució completament local per a la formació i la generació de Hunyuan LoRA, sense l'ús de llocs web basats en API o processos comercials de lloguer de GPU com Runpod.
Feu clic per jugar. Mostres de la formació de LoRA a Musubi Tuner per a aquest article. Tots els permisos concedits per la persona representada, per tal d'il·lustrar aquest article.
REQUISITS
La instal·lació requerirà com a mínim un ordinador Windows 10 amb una targeta NVIDIA de la sèrie 30+/40+ que tingui almenys 12 GB de VRAM (tot i que es recomana 16 GB). La instal·lació utilitzada per a aquest article es va provar en una màquina amb 64 GB de eOS® RAM i una targeta gràfica NVIDIA 3090 amb 24 GB de VRAM. Es va provar en un sistema de banc de proves dedicat mitjançant una instal·lació nova de Windows 10 Professional, en una partició amb més de 600 GB d'espai de disc de recanvi.
ADVERTÈNCIA
La instal·lació de Musubi Tuner i els seus requisits previs també implica la instal·lació de programari i paquets centrats en el desenvolupador directament a la instal·lació principal de Windows d'un ordinador. Tenint en compte la instal·lació de ComfyUI, per a les etapes finals, aquest projecte necessitarà uns 400-500 gigabytes d'espai en disc. Tot i que he provat el procediment sense incidents diverses vegades en entorns Windows 10 del banc de proves recent instal·lat, ni jo ni unite.ai som responsables de cap dany als sistemes si seguim aquestes instruccions. Us recomano que feu una còpia de seguretat de les dades importants abans d'intentar aquest tipus de procediment d'instal·lació.
Consideracions
Aquest mètode encara és vàlid?
L'escena d'IA generativa s'està movent molt ràpidament, i podem esperar mètodes millors i més racionalitzats dels marcs de vídeo LoRA de Hunyuan aquest any.
...o fins i tot aquesta setmana! Mentre escrivia aquest article, el desenvolupador de Kohya/Musubi va produir musubi-tuner-gui, una sofisticada GUI de Gradio per a Musubi Tuner:

Òbviament, és preferible una GUI fàcil d'utilitzar als fitxers BAT que faig servir en aquesta funció, una vegada que musubi-tuner-gui funcioni. Mentre escric, només es va connectar fa cinc dies i no puc trobar cap compte de ningú que l'utilitzi amb èxit.
Segons les publicacions del dipòsit, la nova GUI està pensada per incorporar-se directament al projecte Musubi Tuner tan aviat com sigui possible, que acabarà amb la seva existència actual com a dipòsit autònom de GitHub.
D'acord amb les instruccions d'instal·lació actuals, la nova GUI es clona directament a l'entorn virtual de Musubi existent; i, malgrat molts esforços, no puc aconseguir que s'associï amb la instal·lació de Musubi existent. Això vol dir que quan funcioni, es trobarà que no té motor!
Un cop la GUI estigui integrada a Musubi Tuner, segur que es resoldran problemes d'aquest tipus. Encara que l'autor admet que el nou projecte és "molt dur", és optimista pel seu desenvolupament i integració directament a Musubi Tuner.
Tenint en compte aquests problemes (també pel que fa als camins predeterminats en el moment de la instal·lació i l'ús del fitxer Paquet UV Python, que complica certs procediments en la nova versió), probablement haurem d'esperar una mica per obtenir una experiència d'entrenament Hunyuan Video LoRA més fluida. Dit això, sembla molt prometedor!
Però si no podeu esperar i esteu disposats a tirar-vos una mica les mànigues, podeu obtenir l'entrenament de vídeo LoRA de Hunyuan ara mateix.
Comencem.
Per què instal·lar Qualsevol cosa al Bare Metal?
(Omet aquest paràgraf si no ets un usuari avançat)
Els usuaris avançats es preguntaran per què he triat instal·lar tant del programari a la instal·lació de Windows 10 en lloc de fer-ho en un entorn virtual. La raó és que el port essencial de Windows del basat en Linux Paquet Triton és molt més difícil treballar en un entorn virtual. Totes les altres instal·lacions de metall nu del tutorial no s'han pogut instal·lar en un entorn virtual, ja que han d'interaccionar directament amb el maquinari local.
Instal·lació de paquets i programes de prerequisits
Per als programes i paquets que s'han d'instal·lar inicialment, l'ordre d'instal·lació és important. Comencem.
1: Baixeu Microsoft Redistributable
Baixeu i instal·leu el paquet Microsoft Redistributable des de https://aka.ms/vs/17/release/vc_redist.x64.exe.
Aquesta és una instal·lació senzilla i ràpida.

2: instal·leu Visual Studio 2022
Baixeu l'edició de la comunitat de Microsoft Visual Studio 2022 de https://visualstudio.microsoft.com/downloads/?cid=learn-onpage-download-install-visual-studio-page-cta
Inicieu l'instal·lador descarregat:

No necessitem tots els paquets disponibles, la qual cosa seria una instal·lació pesada i llarga. A la inicial Càrregues de treball pàgina que s'obre, marqueu Desenvolupament d'escriptori amb C++ (veure imatge a continuació).

Ara feu clic a la Components individuals pestanya a la part superior esquerra de la interfície i utilitzeu el quadre de cerca per trobar "Windows SDK".

Per defecte, només el Windows 11 SDK està marcat. Si esteu a Windows 10 (aquest procediment d'instal·lació no l'he provat a Windows 11), marqueu la darrera versió de Windows 10, que s'indica a la imatge de dalt.
Cerqueu "C++ CMake" i comproveu-ho C++ Eines CMake per a Windows està marcada.

Aquesta instal·lació ocuparà almenys 13 GB d'espai.

Un cop instal·lat Visual Studio, intentarà executar-se al vostre ordinador. Deixeu que s'obri completament. Quan finalment es vegi la interfície de pantalla completa de Visual Studio, tanqueu el programa.
3: instal·leu Visual Studio 2019
Alguns dels paquets posteriors per a Musubi esperen una versió anterior de Microsoft Visual Studio, mentre que d'altres en necessiten una de més recent.
Per tant, també descarregueu l'edició gratuïta de la comunitat de Visual Studio 19 des de Microsoft (https://visualstudio.microsoft.com/vs/older-downloads/ - Compte obligatori) o Techspot (https://www.techspot.com/downloads/7241-visual-studio-2019.html).
Instal·leu-lo amb les mateixes opcions que per a Visual Studio 2022 (vegeu el procediment anterior, tret que Windows SDK ja està marcada a l'instal·lador de Visual Studio 2019).
Veureu que l'instal·lador de Visual Studio 2019 ja coneix la versió més recent a mesura que s'instal·la:

Quan la instal·lació s'hagi completat i hàgiu obert i tancat l'aplicació Visual Studio 2019 instal·lada, obriu un indicador d'ordres de Windows (Escriviu CMD a Inicia la cerca) i escriviu i introduïu:
where cl
El resultat hauria de ser les ubicacions conegudes de les dues edicions de Visual Studio instal·lades.

Si en canvi ho aconsegueixes INFO: Could not find files for the given pattern(s), vegeu el Comprova el camí secció d'aquest article a continuació i utilitzeu aquestes instruccions per afegir els camins rellevants de Visual Studio a l'entorn Windows.
Deseu els canvis realitzats segons el Comproveu els camins secció següent i, a continuació, torneu a provar l'ordre where cl.
4: instal·leu CUDA 11 + 12 Toolkits
Els diferents paquets instal·lats a Musubi necessiten versions diferents de NVIDIA CUDA, que accelera i optimitza l'entrenament a les targetes gràfiques NVIDIA.
El motiu pel qual vam instal·lar les versions de Visual Studio 1 és que els instal·ladors de NVIDIA CUDA cerquen i s'integren amb qualsevol instal·lació de Visual Studio existent.
Baixeu un paquet d'instal·lació CUDA de la sèrie 11+ des de:
https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local (descarregar 'exe (local') )
Baixeu un paquet d'instal·lació de CUDA Toolkit de la sèrie 12+ des de:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
El procés d'instal·lació és idèntic per als dos instal·ladors. Ignoreu qualsevol advertència sobre l'existència o la inexistència de camins d'instal·lació a les variables d'entorn de Windows; ho atendrem manualment més endavant.
Instal·leu NVIDIA CUDA Toolkit V11+
Inicieu l'instal·lador de la sèrie 11+ CUDA Toolkit.


At Opcions d'instal·lació, seleccioneu Personalitzat (avançat) i procedir.

Desmarqueu l'opció NVIDIA GeForce Experience i feu clic El proper.

deixar Seleccioneu la ubicació d'instal·lació per defecte (això és important):

feu clic El proper i deixeu que la instal·lació conclogui.

Ignoreu qualsevol advertència o nota que l'instal·lador faci Nsight Visual Studio integració, que no és necessària per al nostre cas d'ús.
Instal·leu NVIDIA CUDA Toolkit V12+
Repetiu tot el procés per a l'instal·lador independent de NVIDIA Toolkit 12+ que heu baixat:

El procés d'instal·lació d'aquesta versió és idèntic al que s'indica més amunt (la versió 11+), excepte un avís sobre els camins d'entorn, que podeu ignorar:

Quan s'hagi completat la instal·lació de la versió CUDA 12+, obriu un indicador d'ordres a Windows i escriviu i introduïu:
nvcc --version
Això hauria de confirmar la informació sobre la versió del controlador instal·lat:

Per comprovar que la vostra targeta és reconeguda, escriviu i introduïu:
nvidia-smi

5: Instal·leu GIT
GIT s'encarregarà de la instal·lació del repositori Musubi a la vostra màquina local. Descarrega l'instal·lador de GIT a:
https://git-scm.com/downloads/win ("Configuració de Git de 64 bits per a Windows")

Executeu l'instal·lador:

Utilitzeu la configuració predeterminada per a Seleccioneu Components:
Deixeu l'editor predeterminat a empenta:

Deixeu que GIT decideixi sobre els noms de les branques:

Utilitzeu la configuració recomanada per a Camí Medi Ambient:

Utilitzeu la configuració recomanada per a SSH:

Utilitzeu la configuració recomanada per Backend de transport HTTPS:
Utilitzeu la configuració recomanada per a les conversions de final de línia:

Trieu la consola predeterminada de Windows com a emulador de terminal:
Utilitza la configuració predeterminada (Avança ràpidament o fusiona) per a Git Pull:

Utilitzeu Git-Credential Manager (la configuració predeterminada) per a Credential Helper:

In Configuració d'opcions addicionals, marxa Activa la memòria cau del sistema de fitxers marcat, i Activa els enllaços simbòlics desmarcada (tret que sou un usuari avançat que utilitzi enllaços durs per a un dipòsit de models centralitzat).

Conclou la instal·lació i comproveu que Git està instal·lat correctament obrint una finestra CMD i escrivint i introduint:
git --version

Inici de sessió a GitHub
Més tard, quan intenteu clonar els dipòsits de GitHub, és possible que us demanin les vostres credencials de GitHub. Per anticipar-ho, inicieu sessió al vostre compte de GitHub (creeu-ne un, si cal) a qualsevol navegador instal·lat al vostre sistema Windows. D'aquesta manera, el mètode d'autenticació 0Auth (una finestra emergent) hauria de trigar el menys temps possible.
Després d'aquest repte inicial, hauríeu de romandre autenticat automàticament.
6: Instal·leu CMake
Es requereix CMake 3.21 o posterior per a parts del procés d'instal·lació de Musubi. CMake és una arquitectura de desenvolupament multiplataforma capaç d'orquestrar diversos compiladors i de compilar programari a partir del codi font.
Descarrega'l a:
https://cmake.org/download/ ("Instal·lador de Windows x64")
Inicieu l'instal·lador:

Assegurar Afegiu Cmake a la variable d'entorn PATH està marcada.

Premsa El proper.

Escriviu i introduïu aquesta ordre en un indicador d'ordres de Windows:
cmake --version
Si CMake s'ha instal·lat correctament, es mostrarà alguna cosa com:
cmake version 3.31.4
CMake suite maintained and supported by Kitware (kitware.com/cmake).

7: instal·leu Python 3.10
L'intèrpret de Python és central en aquest projecte. Descarrega la versió 3.10 (el millor compromís entre les diferents demandes dels paquets Musubi) a:
https://www.python.org/downloads/release/python-3100/ ("Instal·lador de Windows (64 bits)")
Executeu l'instal·lador de descàrrega i deixeu la configuració predeterminada:

Al final del procés d'instal·lació, feu clic a Desactiva el límit de longitud del camí (requereix la confirmació de l'administrador de la UAC):

En un indicador d'ordres de Windows, escriviu i introduïu:
python --version
Això hauria de resultar en Python 3.10.0

Comproveu els camins
La clonació i instal·lació dels frameworks Musubi, així com el seu funcionament normal després de la instal·lació, requereix que els seus components coneguin el camí cap a diversos components externs importants a Windows, especialment CUDA.
Per tant, hem d'obrir l'entorn del camí i comprovar que hi ha tots els requisits.
Una manera ràpida d'arribar als controls de l'entorn de Windows és escriure Editeu les variables d'entorn del sistema a la barra de cerca de Windows.

En fer-hi clic, s'obrirà el fitxer Propietats del sistema panell de control. A la part inferior dreta de Propietats del sistema, Feu clic al Variables del mediambient botó i una finestra cridada Variables del mediambient s'obre. En el Variables del sistema tauler a la meitat inferior d'aquesta finestra, desplaceu-vos cap avall fins a Camí i feu-hi doble clic. Això obre una finestra anomenada Edita les variables d'entorn. Arrossegueu l'amplada d'aquesta finestra més àmplia perquè pugueu veure el camí complet de les variables:

Aquí les entrades importants són:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.42.34433\bin\Hostx64\x64
C:\Program Files\Git\cmd
C:\Program Files\CMake\bin
En la majoria dels casos, les variables de camí correctes ja haurien d'estar presents.
Afegiu els camins que faltin fent clic nou a l'esquerra del Edita les variables d'entorn finestra i enganxar al camí correcte:

NO només copieu i enganxeu dels camins indicats anteriorment; comproveu que cada camí equivalent existeix a la vostra instal·lació de Windows.
Si hi ha variacions menors del camí (especialment amb les instal·lacions de Visual Studio), utilitzeu els camins indicats anteriorment per trobar les carpetes de destinació correctes (és a dir, x64 in Amfitrió 64 en la seva pròpia instal·lació. Després enganxa aquells camins cap a la Edita les variables d'entorn finestra.
Després d'això, reinicieu l'ordinador.
Instal·lació de Musubi
Actualitza el PIP
L'ús de la darrera versió de l'instal·lador PIP pot suavitzar algunes de les etapes d'instal·lació. En un indicador d'ordres de Windows amb privilegis d'administrador (vegeu Elevació, a continuació), escriviu i introduïu:
pip install --upgrade pip
Elevació
Algunes ordres poden requerir privilegis elevats (és a dir, per ser executades com a administrador). Si rebeu missatges d'error sobre permisos en les etapes següents, tanqueu la finestra del símbol d'ordres i torneu-la a obrir en mode administrador escrivint CMD al quadre de cerca de Windows, fent clic amb el botó dret Símbol del sistema i seleccionant Executa com administrador:

Per a les següents etapes, farem servir Windows Powershell en lloc de l'indicador d'ordres de Windows. Podeu trobar-ho entrant PowerShell al quadre de cerca de Windows i (si cal) feu-hi clic amb el botó dret Executa com administrador:

Instal·leu Torch
A Powershell, escriviu i introduïu:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Tingueu paciència mentre s'instal·len els molts paquets.
Quan s'hagi completat, podeu verificar una instal·lació de PyTorch habilitat per a GPU escrivint i introduint:
python -c "import torch; print(torch.cuda.is_available())"
Això hauria de donar lloc a:
C:\WINDOWS\system32>python -c "import torch;
print(torch.cuda.is_available())"
True
Instal·leu Triton per a Windows
A continuació, la instal·lació del Triton per a Windows component. A Powershell elevat, introduïu (en una sola línia):
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post8/triton-3.1.0-cp310-cp310-win_amd64.whl
(L'instal·lador triton-3.1.0-cp310-cp310-win_amd64.whl funciona tant per a les CPU Intel com per a AMD, sempre que l'arquitectura sigui de 64 bits i l'entorn coincideixi amb la versió de Python)
Després de córrer, això hauria de donar lloc a:
Successfully installed triton-3.1.0
Podem comprovar si Triton funciona important-lo a Python. Introduïu aquesta comanda:
python -c "import triton; print('Triton is working')"
Això hauria de sortir:
Triton is working
Per comprovar que Triton està habilitat per a GPU, introduïu:
python -c "import torch; print(torch.cuda.is_available())"
Això hauria de resultar en True:

Crea l'entorn virtual per a Musubi
A partir d'ara, instal·larem qualsevol altre programari en a Entorn virtual Python (o venv). Això vol dir que tot el que haureu de fer per desinstal·lar tot el programari següent és arrossegar la carpeta d'instal·lació del venv a la paperera.
Creem aquesta carpeta d'instal·lació: fes una carpeta anomenada Musubi al teu escriptori. Els exemples següents suposen que aquesta carpeta existeix: C:\Users\[Your Profile Name]\Desktop\Musubi\.
A Powershell, navegueu a aquesta carpeta introduint:
cd C:\Users\[Your Profile Name]\Desktop\Musubi
Volem que l'entorn virtual tingui accés al que ja tenim instal·lat (especialment Triton), així que utilitzarem el --system-site-packages bandera. Introduïu això:
python -m venv --system-site-packages musubi
Espereu que es creï l'entorn i, a continuació, activeu-lo introduint:
.\musubi\Scripts\activate
A partir d'aquest moment, podeu dir que esteu a l'entorn virtual activat pel fet que (musubi) apareix al principi de totes les vostres indicacions.

Clonar el dipòsit
Navegueu fins al nou creat musubi carpeta (que es troba dins de Musubi carpeta a l'escriptori):
cd musubi
Ara que estem al lloc correcte, introduïu l'ordre següent:
git clone https://github.com/kohya-ss/musubi-tuner.git
Espereu que finalitzi la clonació (no trigarà gaire).

Requisits d'instal·lació
Aneu a la carpeta d'instal·lació:
cd musubi-tuner
Intro:
pip install -r requirements.txt
Espereu que acabin les moltes instal·lacions (això trigarà més temps).

Automatització de l'accés al vídeo Hunyuan Venv
Per activar i accedir fàcilment al nou venv per a futures sessions, enganxeu el següent al Bloc de notes i deseu-lo amb el nom activar.bat, guardant-lo amb Tots els fitxers opció (vegeu la imatge següent).
@echo off
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate
cd C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner
cmd
(Reemplaça [Your Profile Name]amb el nom real del vostre perfil d'usuari de Windows)

No importa en quina ubicació deseu aquest fitxer.
A partir d'ara podeu fer doble clic activar.bat i començar a treballar immediatament.

Utilitzant Musubi Tuner
Descàrrega de models
El procés d'entrenament de Hunyuan Video LoRA requereix la descàrrega d'almenys set models per tal de donar suport a totes les opcions d'optimització possibles per a la pre-emmagatzematge en memòria cau i entrenar un vídeo Hunyuan LoRA. En conjunt, aquests models pesen més de 60 GB.
Les instruccions actuals per descarregar-les es poden trobar a https://github.com/kohya-ss/musubi-tuner?tab=readme-ov-file#model-download
Tanmateix, aquestes són les instruccions de descàrrega en el moment d'escriure:
clip_l.safetensors
llava_llama3_fp16.safetensors
llava_llama3_fp8_scaled.safetensors
es pot descarregar a:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
mp_rank_00_model_states.pt
mp_rank_00_model_states_fp8.pt
mp_rank_00_model_states_fp8_map.pt
es pot descarregar a:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/transformers
pytorch_model.pt
es pot descarregar a:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/vae
Tot i que podeu col·locar-los a qualsevol directori que trieu, per a la coherència amb els scripts posteriors, posem-los a:
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\
Això és coherent amb la disposició del directori anterior a aquest punt. Totes les ordres o instruccions posteriors suposaran que aquí es troben els models; i no us oblideu de substituir [El vostre nom de perfil] pel nom real de la carpeta de perfil de Windows.
Preparació del conjunt de dades
Ignorant la controvèrsia de la comunitat sobre el tema, és just dir que necessitareu entre 10 i 100 fotos per a un conjunt de dades d'entrenament per al vostre Hunyuan LoRA. Es poden obtenir molt bons resultats fins i tot amb 15 imatges, sempre que les imatges estiguin ben equilibrades i de bona qualitat.
Un Hunyuan LoRA es pot entrenar tant en imatges com en videoclips molt curts i de baixa resolució, o fins i tot en una barreja de cadascun, tot i que utilitzar clips de vídeo com a dades d'entrenament és un repte, fins i tot per a una targeta de 24 GB.
Tanmateix, els videoclips només són realment útils si el vostre personatge es mou d'una manera tan inusual que potser el model de la fundació Hunyuan Video no ho sap, o poder endevinar.
Alguns exemples inclouen Roger Rabbit, un xenomorf, The Mask, Spider-Man o altres personalitats que posseeixen únic moviment característic.
Com que Hunyuan Video ja sap com es mouen els homes i les dones corrents, els videoclips no són necessaris per obtenir un personatge de tipus humà convincent de Hunyuan Video LoRA. Per tant, utilitzarem imatges estàtiques.
Preparació de la imatge
La llista de desitjos
La versió TLDR:
El millor és utilitzar imatges de la mateixa mida per al vostre conjunt de dades, o bé utilitzar una divisió 50/50 entre dues mides diferents, és a dir, 10 imatges de 512x768px i 10 de 768x512px.
L'entrenament podria anar bé fins i tot si no ho feu: els LoRA de vídeo de Hunyuan poden ser sorprenentment indulgents.
La versió llarga
Igual que amb Kohya-ss LoRA per a sistemes generatius estàtics com Stable Diffusion, cub s'utilitza per distribuir la càrrega de treball a través d'imatges de diferents mides, permetent que s'utilitzin imatges més grans sense causar errors de falta de memòria en el moment de l'entrenament (és a dir, la classificació "talla" les imatges en trossos que la GPU pot gestionar, tot i que es manté el integritat semàntica de tota la imatge).
Per a cada mida d'imatge que inclogueu al vostre conjunt de dades d'entrenament (és a dir, 512 x 768 px), es crearà un cub o "subtasques" per a aquesta mida. Per tant, si teniu la següent distribució d'imatges, així és com l'atenció de la galleda es desequilibra i corre el risc que algunes fotografies es tinguin més en compte a l'entrenament que d'altres:
Imatges de 2x 512x768px
Imatges de 7x 768x512px
1 imatge de 1000 x 600 píxels
Imatges de 3x 400x800px
Podem veure que l'atenció de la galleda es divideix de manera desigual entre aquestes imatges:

Per tant, seguiu una mida de format o intenteu mantenir la distribució de diferents mides relativament igual.
En qualsevol cas, eviteu imatges molt grans, ja que és probable que això retardi l'entrenament, amb un benefici insignificant.
Per simplificar, he utilitzat 512x768px per a totes les fotos del meu conjunt de dades.
Exempció de responsabilitat: El model (persona) utilitzat al conjunt de dades em va donar permís total per utilitzar aquestes imatges per a aquest propòsit i va exercir l'aprovació de totes les sortides basades en IA que representen la seva semblança que apareixen en aquest article.

El meu conjunt de dades consta de 40 imatges, en format PNG (tot i que JPG també està bé). Les meves imatges es van emmagatzemar a C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman
Hauríeu de crear un cache carpeta dins de la carpeta d'imatges d'entrenament:

Ara creem un fitxer especial que configurarà l'entrenament.
Fitxers TOML
Els processos d'entrenament i pre-emmagatzematge en memòria cau de Hunyuan Video LoRA obté els camins dels fitxers d'un fitxer de text pla amb el .toml extensió.
Per a la meva prova, el TOML es troba a C:\Users\Martin\Desktop\DATASETS_HUNYUAN\training.toml
Els continguts de la meva formació TOML són així:
[general]
resolution = [512, 768]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman"
cache_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman\\cache"
num_repeats = 1
(Les barres inclinades dobles per als directoris d'imatges i de memòria cau no sempre són necessàries, però poden ajudar a evitar errors en els casos en què hi ha un espai al camí. He entrenat models amb fitxers .toml que utilitzaven single-forward i single-forward). barres invertides)
Podem veure en el resolution apartat que es tindran en compte dues resolucions: 512px i 768px. També podeu deixar-ho al 512 i encara obtenir bons resultats.
Subtítols
Hunyuan Video és un text+model de base de la visió, per la qual cosa necessitem subtítols descriptius per a aquestes imatges, que es tindran en compte durant la formació. El procés de formació fallarà sense subtítols.
Hi ha una multitud de sistemes de subtítols de codi obert que podríem utilitzar per a aquesta tasca, però siguem-ho senzill i utilitzem el taggui sistema. Tot i que s'emmagatzema a GitHub i, tot i que baixa alguns models d'aprenentatge profund molt pesats a la primera execució, es presenta en forma d'un senzill executable de Windows que carrega biblioteques de Python i una GUI senzilla.
Després d'iniciar Taggui, utilitzeu Fitxer > Carrega el directori per navegar al conjunt de dades d'imatge i, opcionalment, posar un identificador de testimoni (en aquest cas, dona exemple) que s'afegirà a tots els subtítols:

(Assegureu-vos d'apagar-lo Carrega en 4 bits quan Taggui s'obre per primera vegada: llançarà errors durant els subtítols si es deixa activat)
Seleccioneu una imatge a la columna de vista prèvia de l'esquerra i premeu CTRL+A per seleccionar totes les imatges. A continuació, premeu el botó Inicia els subtítols automàtics a la dreta:

Veureu Taggui baixant models a la petita CLI de la columna de la dreta, però només si és la primera vegada que executeu el subtitulador. En cas contrari, veureu una vista prèvia dels subtítols.

Ara, cada foto té un títol .txt corresponent amb una descripció del contingut de la imatge:

Podeu fer clic Opcions avançades a Taggui per augmentar la longitud i l'estil dels subtítols, però això està fora de l'abast d'aquest resum.
Sortiu de Taggui i passem a...
Precaching latent
Per evitar una càrrega excessiva de la GPU en el moment de l'entrenament, cal crear dos tipus de fitxers pre-emmagatzemats a la memòria cau: un per representar la imatge latent derivada de les mateixes imatges i un altre per avaluar una codificació de text relacionada amb el contingut dels subtítols.
Per simplificar els tres processos (2x memòria cau + formació), podeu utilitzar fitxers .BAT interactius que us faran preguntes i emprendre els processos quan hàgiu donat la informació necessària.
Per a l'emmagatzematge previ latent, copieu el text següent al Bloc de notes i deseu-lo com a fitxer .BAT (és a dir, poseu-lo un nom com latent-precache.bat), com abans, assegurant-vos que el tipus de fitxer al menú desplegable del fitxer Desa el diàleg és Tots els fitxers (veure imatge a continuació):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with latent pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the latent pre-caching script
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_latents.py --dataset_config %TOML_PATH% --vae C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\pytorch_model.pt --vae_chunk_size 32 --vae_tiling
) else (
echo Operation canceled.
)
REM Keep the window open
pause
(Assegureu-vos de substituir [Nom del teu perfil] amb el nom real de la carpeta de perfil de Windows)

Ara podeu executar el fitxer .BAT per a la memòria cau latent automàtica:

Quan us demanin les diverses preguntes del fitxer BAT, enganxeu o escriviu el camí del vostre conjunt de dades, les carpetes de memòria cau i el fitxer TOML.
Preemmagatzematge en memòria cau de text
Crearem un segon fitxer BAT, aquesta vegada per a l'emmagatzematge previ del text.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with text encoder output pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Use the python executable from the virtual environment
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_text_encoder_outputs.py --dataset_config %TOML_PATH% --text_encoder1 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\llava_llama3_fp16.safetensors --text_encoder2 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\clip_l.safetensors --batch_size 16
) else (
echo Operation canceled.
)
REM Keep the window open
pause
Substituïu el vostre nom de perfil de Windows i deseu-lo com a text-cache.bat (o qualsevol altre nom que vulgueu), en qualsevol ubicació convenient, segons el procediment per al fitxer BAT anterior.
Executeu aquest nou fitxer BAT, seguiu les instruccions i els fitxers codificats de text necessaris apareixeran al fitxer cache carpeta:

Entrenant la Lora de vídeo Hunyuan
La formació del LoRA real trigarà molt més que aquests dos processos preparatoris.
Tot i que també hi ha diverses variables de les quals ens podríem preocupar (com ara la mida del lot, les repeticions, les èpoques i l'ús de models complets o quantificats, entre d'altres), guardarem aquestes consideracions per a un altre dia i una mirada més profunda a la complexos de la creació de LoRA.
De moment, minimitzem una mica les opcions i formem un LoRA en la configuració "mediana".
Crearem un tercer fitxer BAT, aquesta vegada per iniciar la formació. Enganxeu-ho al Bloc de notes i deseu-lo com a fitxer BAT, com abans, com entrenament.bat (o qualsevol nom que vulgueu):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p DATASET_CONFIG=Enter the path to the dataset configuration file:
set /p EPOCHS=Enter the number of epochs to train:
set /p OUTPUT_NAME=Enter the output model name (e.g., example0001):
set /p LEARNING_RATE=Choose learning rate (1 for 1e-3, 2 for 5e-3, default 1e-3):
if "%LEARNING_RATE%"=="1" set LR=1e-3
if "%LEARNING_RATE%"=="2" set LR=5e-3
if "%LEARNING_RATE%"=="" set LR=1e-3
set /p SAVE_STEPS=How often (in steps) to save preview images:
set /p SAMPLE_PROMPTS=What is the location of the text-prompt file for training previews?
echo You entered:
echo Dataset configuration file: %DATASET_CONFIG%
echo Number of epochs: %EPOCHS%
echo Output name: %OUTPUT_NAME%
echo Learning rate: %LR%
echo Save preview images every %SAVE_STEPS% steps.
echo Text-prompt file: %SAMPLE_PROMPTS%
REM Prepare the command
set CMD=accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\hv_train_network.py ^
--dit C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\mp_rank_00_model_states.pt ^
--dataset_config %DATASET_CONFIG% ^
--sdpa ^
--mixed_precision bf16 ^
--fp8_base ^
--optimizer_type adamw8bit ^
--learning_rate %LR% ^
--gradient_checkpointing ^
--max_data_loader_n_workers 2 ^
--persistent_data_loader_workers ^
--network_module=networks.lora ^
--network_dim=32 ^
--timestep_sampling sigmoid ^
--discrete_flow_shift 1.0 ^
--max_train_epochs %EPOCHS% ^
--save_every_n_epochs=1 ^
--seed 42 ^
--output_dir "C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models" ^
--output_name %OUTPUT_NAME% ^
--vae C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/pytorch_model.pt ^
--vae_chunk_size 32 ^
--vae_spatial_tile_sample_min_size 128 ^
--text_encoder1 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/llava_llama3_fp16.safetensors ^
--text_encoder2 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/clip_l.safetensors ^
--sample_prompts %SAMPLE_PROMPTS% ^
--sample_every_n_steps %SAVE_STEPS% ^
--sample_at_first
echo The following command will be executed:
echo %CMD%
set /p CONFIRM=Do you want to proceed with training (y/n)?
if /i "%CONFIRM%"=="y" (
%CMD%
) else (
echo Operation canceled.
)
REM Keep the window open
cmd /k
Com és habitual, assegureu-vos de substituir totes les instàncies of [Nom del teu perfil] amb el vostre nom de perfil de Windows correcte.
Assegureu-vos que el directori C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\ existeix, i creeu-lo en aquesta ubicació si no.
Previsualitzacions de la formació
Hi ha una funció de vista prèvia de l'entrenament molt bàsica recentment activada per a l'entrenador Musubi, que us permet forçar el model d'entrenament a fer una pausa i generar imatges en funció de les indicacions que heu desat. Aquests es guarden en una carpeta creada automàticament anomenada Mostra, al mateix directori on es guarden els models entrenats.

Per habilitar-ho, haureu de desar l'última sol·licitud en un fitxer de text. La formació BAT que hem creat us demanarà que introduïu la ubicació d'aquest fitxer; per tant, podeu anomenar el fitxer de sol·licitud perquè sigui el que vulgueu i desar-lo a qualsevol lloc.
A continuació, es mostren alguns exemples d'un fitxer que sortirà tres imatges diferents quan ho sol·liciti la rutina d'entrenament:

Com podeu veure a l'exemple anterior, podeu posar banderes al final del missatge que afectaran les imatges:
–w és width (per defecte és 256px si no s'estableix, segons els documents)
-h és height (per defecte és 256 px si no s'estableix)
–f és la nombre de fotogrames. Si s'estableix a 1, es produeix una imatge; més d'un, un vídeo.
–d és la llavor. Si no s'estableix, és aleatori; però hauríeu de configurar-lo perquè vegi un missatge que evoluciona.
–s és el nombre de passos en generació, per defecte 20.
veure la documentació oficial per a banderes addicionals.
Tot i que les visualitzacions prèvies de l'entrenament poden revelar ràpidament alguns problemes que poden fer que cancel·leu l'entrenament i reconsidereu les dades o la configuració, estalviant així temps, recordeu que cada indicació addicional alenteix l'entrenament una mica més.
A més, com més gran sigui l'amplada i l'alçada de la imatge de previsualització de l'entrenament (tal com s'estableix a les banderes esmentades anteriorment), més retardarà l'entrenament.
Inicieu el vostre fitxer BAT d'entrenament.
Pregunta 1 és "Introduïu el camí a la configuració del conjunt de dades. Enganxeu o escriviu el camí correcte al vostre fitxer TOML.
Pregunta 2 és "Introduïu el nombre d'èpoques a entrenar". Aquesta és una variable d'assaig i error, ja que es veu afectada per la quantitat i la qualitat de les imatges, així com els subtítols i altres factors. En general, el millor és posar-lo massa alt que massa baix, ja que sempre podeu aturar l'entrenament amb Ctrl+C a la finestra d'entrenament si creieu que el model ha avançat prou. Estableix-lo a 100 en primera instància i mira com va.
Pregunta 3 és "Introduïu el nom del model de sortida". Posa un nom al teu model! Pot ser millor mantenir el nom raonablement curt i senzill.
Pregunta 4 és "Tria la taxa d'aprenentatge", que per defecte és 1e-3 (opció 1). Aquest és un bon lloc per començar, a l'espera de més experiència.
Pregunta 5 és 'Con quina freqüència (en passos) s'han de desar les imatges de previsualització. Si l'ajusteu massa baix, veureu poc progrés entre els desats de la imatge de vista prèvia i això alentirà l'entrenament.
Pregunta 6 és "Quina és la ubicació del fitxer de sol·licitud de text per a visualitzacions prèvies d'entrenament?". Enganxeu o escriviu el camí al fitxer de text de sol·licituds.
Aleshores, el BAT us mostra l'ordre que enviarà al model Hunyuan i us pregunta si voleu continuar, y/n.
Avança i comença a entrenar:
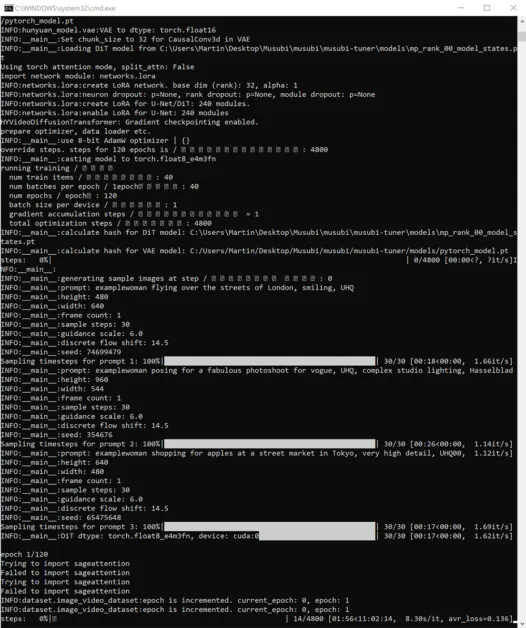
Durant aquest temps, si comproveu la secció GPU de la pestanya Rendiment del Gestor de tasques de Windows, veureu que el procés està prenent uns 16 GB de VRAM.

Pot ser que aquesta no sigui una xifra arbitrària, ja que aquesta és la quantitat de VRAM disponible en moltes targetes gràfiques NVIDIA i és possible que el codi ascendent s'hagi optimitzat per adaptar-se a les tasques en 16 GB en benefici dels propietaris d'aquestes targetes.
Dit això, és molt fàcil augmentar aquest ús, enviant banderes més exorbitants a l'ordre d'entrenament.
Durant l'entrenament, veureu a la part inferior dreta de la finestra CMD una xifra de quant de temps ha passat des que va començar l'entrenament i una estimació del temps total d'entrenament (que variarà molt en funció de les banderes establertes, del nombre d'imatges d'entrenament). , nombre d'imatges de vista prèvia de l'entrenament i diversos altres factors).

Un temps d'entrenament típic és d'unes 3-4 hores en la configuració mitjana, depenent del maquinari disponible, el nombre d'imatges, la configuració de la bandera i altres factors.
Ús dels teus models LoRA entrenats al vídeo Hunyuan
Selecció de punts de control
Quan finalitzi l'entrenament, tindreu un punt de control model per a cada època d'entrenament.

Aquesta freqüència d'estalvi pot ser modificada per l'usuari per desar amb més o menys freqüència, segons ho desitgi, modificant el --save_every_n_epochs [N] número al fitxer BAT d'entrenament. Si heu afegit una xifra baixa per a estalvis per passos quan configureu l'entrenament amb el BAT, hi haurà un gran nombre de fitxers de punts de control desats.
Quin punt de control triar?
Com s'ha esmentat anteriorment, els primers models entrenats seran més flexibles, mentre que els punts de control posteriors poden oferir més detalls. L'única manera de provar aquests factors és executar alguns dels LoRA i generar uns quants vídeos. D'aquesta manera podràs conèixer quins punts de control són més productius, i representen el millor equilibri entre flexibilitat i fidelitat.
ComfyUI
L'entorn més popular (encara que no l'únic) per utilitzar Hunyuan Video LoRA, actualment, és ComfyUI, un editor basat en nodes amb una elaborada interfície Gradio que s'executa al vostre navegador web.

Font: https://github.com/comfyanonymous/ComfyUI
Les instruccions d'instal·lació són senzilles i disponible al repositori oficial de GitHub (cal descarregar-se models addicionals).
Conversió de models per a ComfyUI
Els vostres models entrenats es guarden en un format (difusors) que no és compatible amb la majoria de les implementacions de ComfyUI. Musubi és capaç de convertir un model a un format compatible amb ComfyUI. Configurem un fitxer BAT per implementar-ho.
Abans d'executar aquesta BAT, creeu el C:\Users\[Your Profile Name]\Desktop\Musubi\CONVERTED\ carpeta que l'script espera.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
:START
REM Get user input
set /p INPUT_PATH=Enter the path to the input Musubi safetensors file (or type "exit" to quit):
REM Exit if the user types "exit"
if /i "%INPUT_PATH%"=="exit" goto END
REM Extract the file name from the input path and append 'converted' to it
for %%F in ("%INPUT_PATH%") do set FILENAME=%%~nF
set OUTPUT_PATH=C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\CONVERTED\%FILENAME%_converted.safetensors
set TARGET=other
echo You entered:
echo Input file: %INPUT_PATH%
echo Output file: %OUTPUT_PATH%
echo Target format: %TARGET%
set /p CONFIRM=Do you want to proceed with the conversion (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the conversion script with correctly quoted paths
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\convert_lora.py --input "%INPUT_PATH%" --output "%OUTPUT_PATH%" --target %TARGET%
echo Conversion complete.
) else (
echo Operation canceled.
)
REM Return to start for another file
goto START
:END
REM Keep the window open
echo Exiting the script.
pause
Igual que amb els fitxers BAT anteriors, deseu l'script com a "Tots els fitxers" del Bloc de notes, nomenant-lo convertir.bat (o el que vulguis).
Un cop desat, feu doble clic al nou fitxer BAT, que us demanarà la ubicació d'un fitxer a convertir.

Enganxeu o escriviu el camí del fitxer entrenat que voleu convertir, feu clic yi premeu Intro.
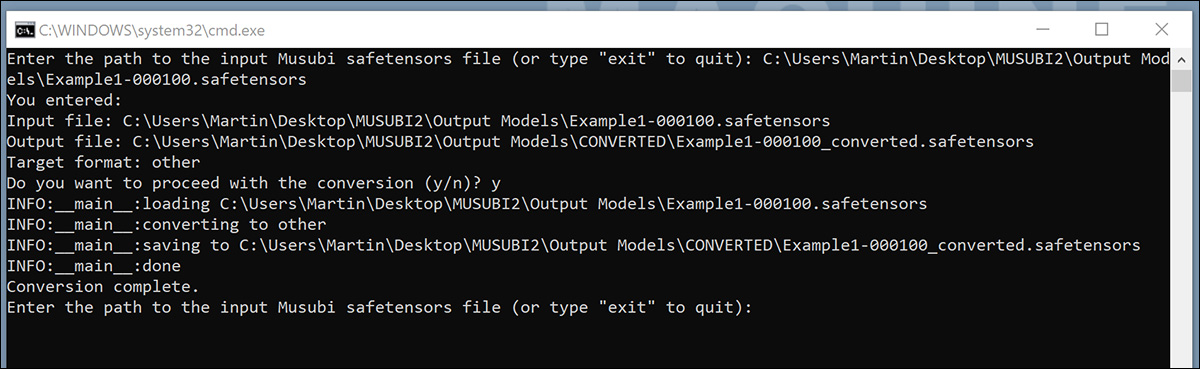
Després de desar el LoRA convertit al fitxer CONVERTS carpeta, l'script us demanarà si voleu convertir un altre fitxer. Si voleu provar diversos punts de control a ComfyUI, convertiu una selecció dels models.
Quan hàgiu convertit prou punts de control, tanqueu la finestra d'ordres BAT.
Ara podeu copiar els vostres models convertits a la carpeta models\loras de la vostra instal·lació de ComfyUI.
Normalment, la ubicació correcta és una cosa com:
C:\Users\[Your Profile Name]\Desktop\ComfyUI\models\loras\
Creació de LoRA de vídeo Hunyuan a ComfyUI
Tot i que els fluxos de treball basats en nodes de ComfyUI semblen complexos inicialment, la configuració d'altres usuaris més experts es pot carregar arrossegant una imatge (realitzada amb la ComfyUI de l'altre usuari) directament a la finestra de ComfyUI. Els fluxos de treball també es poden exportar com a fitxers JSON, que es poden importar manualment o arrossegar-los a una finestra ComfyUI.
Alguns fluxos de treball importats tindran dependències que potser no existeixen a la vostra instal·lació. Per tant, instal·leu ComfyUI-Manager, que pot recuperar els mòduls que falten automàticament.

Font: https://github.com/ltdrdata/ComfyUI-Manager
Per carregar un dels fluxos de treball utilitzats per generar vídeos a partir dels models d'aquest tutorial, descarregueu-lo aquest fitxer JSON i arrossegueu-lo a la vostra finestra ComfyUI (tot i que hi ha exemples de flux de treball molt millors disponibles a les diferents comunitats de Reddit i Discord que han adoptat Hunyuan Video, i el meu està adaptat d'una d'elles).
Aquest no és el lloc per a un tutorial ampliat sobre l'ús de ComfyUI, però val la pena esmentar alguns dels paràmetres crucials que afectaran la vostra sortida si descarregueu i utilitzeu el disseny JSON que he enllaçat anteriorment.

1) Amplada i alçada
Com més gran sigui la imatge, més temps trigarà la generació i més gran serà el risc d'error de memòria sense memòria (OOM).
2) Longitud
Aquest és el valor numèric del nombre de fotogrames. Quants segons suma depenen de la velocitat de fotogrames (establert a 30 fps en aquest disseny). Podeu convertir segons> fotogrames basats en fps a Omnicalculator.
3) Mida del lot
Com més gran sigui la mida del lot, més ràpid pot arribar el resultat, però més gran serà la càrrega de la VRAM. Estableix-ho massa alt i pots obtenir un MOO.
4) Control després de generar
Això controla la llavor aleatòria. Les opcions per a aquest subnode són fixa, va incrementar, decrement i aleatoritzar. Si ho deixes a fixa i no canvieu el missatge de text, obtindreu la mateixa imatge cada vegada. Si modifiqueu la sol·licitud de text, la imatge canviarà de manera limitada. El va incrementar i decrement la configuració us permet explorar els valors de llavors propers, mentre que aleatoritzar us ofereix una interpretació totalment nova del missatge.
5) Nom Lora
Haureu de seleccionar el vostre propi model instal·lat aquí abans d'intentar generar.
6) Fitxa
Si heu entrenat el vostre model per activar el concepte amb un testimoni (com ara 'persona-exemple'), poseu aquesta paraula activa al vostre indicador.
7) Passos
Això representa quants passos aplicarà el sistema al procés de difusió. Els passos més alts poden obtenir més detalls, però hi ha un límit sobre l'efectivitat d'aquest enfocament i aquest llindar pot ser difícil de trobar. El rang comú de passos és d'uns 20-30.
8) Mida de la rajola
Això defineix quanta informació es gestiona alhora durant la generació. De manera predeterminada, està configurat en 256. Aixecar-lo pot accelerar la generació, però augmentar-lo massa pot conduir a una experiència OOM especialment frustrant, ja que arriba al final d'un procés llarg.
9) Superposició temporal
La generació de persones Hunyuan Video pot provocar "fantasmes" o moviments poc convincents si s'estableix massa baix. En general, la saviesa actual és que s'hauria de configurar en un valor superior al nombre de fotogrames, per produir un millor moviment.
Conclusió
Tot i que una exploració addicional de l'ús de ComfyUI està fora de l'abast d'aquest article, l'experiència de la comunitat a Reddit i Discords pot facilitar la corba d'aprenentatge i hi ha diversos guies en línia que introdueixen les bases.
Publicat per primera vegada el dijous 23 de gener de 2025












