
Intel·ligència Artificial
Edició d'objectes assistida per IA amb Imagic de Google i 'Erase and Replace' de la pista

Aquesta setmana, dos algorismes de gràfics nous, però contrastats, basats en IA ofereixen maneres noves perquè els usuaris finals facin canvis molt granulars i efectius als objectes de les fotos.
El primer és Màgic, de Google Research, en associació amb l'Institut de Tecnologia d'Israel i l'Institut de Ciència Weizmann. Imagic ofereix edició d'objectes amb text condicionat i granulat mitjançant l'ajustament dels models de difusió.

Canvieu el que us agradi i deixeu la resta: Imagic promet una edició granular només de les parts que voleu que es canviïn. Font: https://arxiv.org/pdf/2210.09276.pdf
Qualsevol que hagi provat de canviar només un element en una reproducció de Stable Diffusion sabrà massa bé que per a cada edició reeixida, el sistema canviarà cinc coses que us van agradar tal com eren. És una deficiència que actualment té molts dels entusiastes de SD més talentosos que es barregen constantment entre Stable Diffusion i Photoshop per solucionar aquest tipus de "danys col·laterals". Només des d'aquest punt de vista, els èxits d'Imagic semblen notables.
En el moment d'escriure, Imagic encara no té un vídeo promocional i, tenint en compte el de Google actitud circumspecta per alliberar eines de síntesi d'imatges il·limitades, no se sap fins a quin punt, si n'hi ha, tindrem l'oportunitat de provar el sistema.
La segona oferta és més accessible de Runway ML Esborra i substitueix instal·lació, a nova característica a la secció "AI Magic Tools" de la seva suite exclusivament en línia d'utilitats d'efectes visuals basades en l'aprenentatge automàtic.
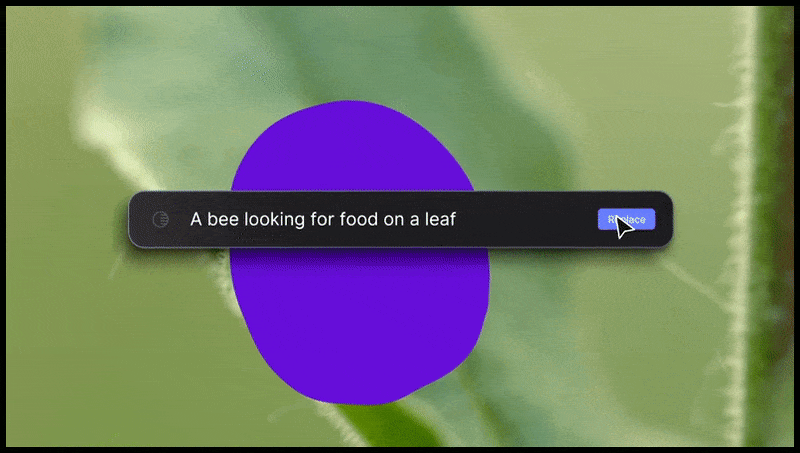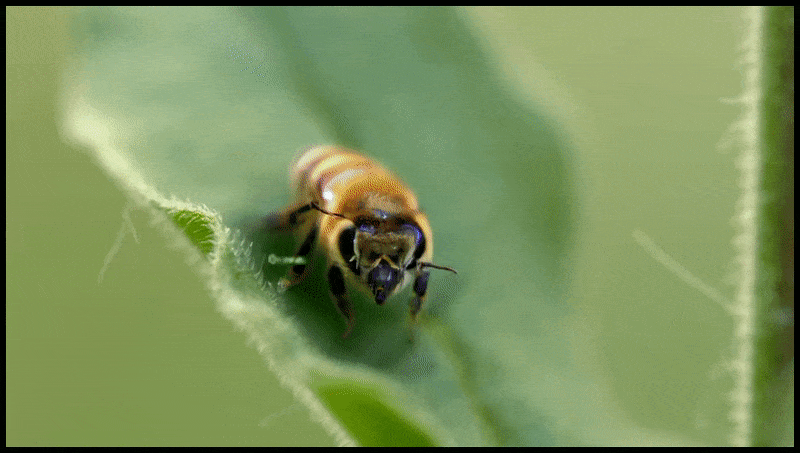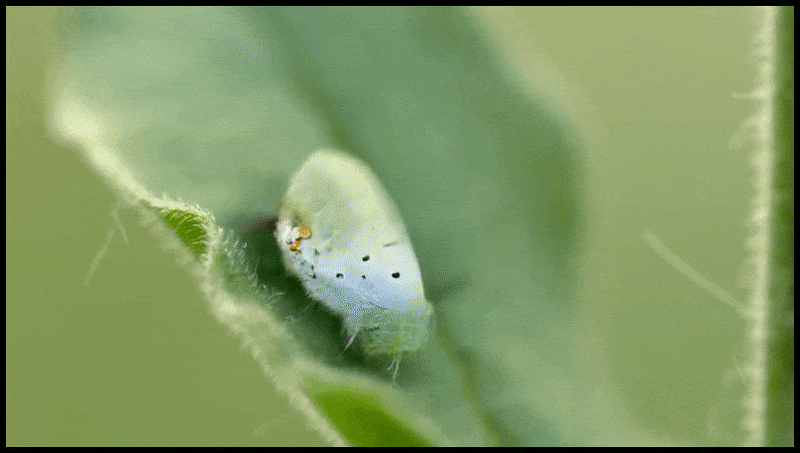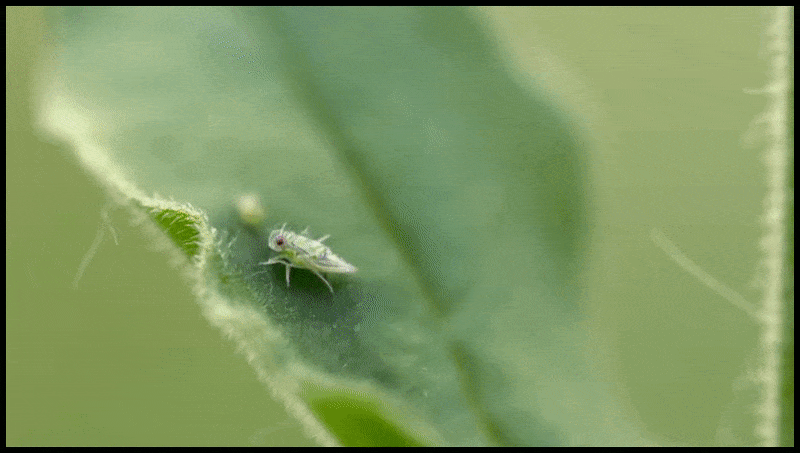
La funció d'esborrar i substituir de Runway ML, que ja s'ha vist en una vista prèvia d'un sistema d'edició de text a vídeo. Font: https://www.youtube.com/watch?v=41Qb58ZPO60
Fem primer una ullada a la sortida de Runway.
Esborra i substitueix
Igual que Imagic, Erase and Replace s'ocupa exclusivament d'imatges fixes, tot i que Runway ho té vista prèvia la mateixa funcionalitat en una solució d'edició de text a vídeo que encara no s'ha publicat:

Tot i que qualsevol pot provar el nou Erase and Replace a les imatges, la versió de vídeo encara no està disponible públicament. Font: https://twitter.com/runwayml/status/1568220303808991232
Tot i que Runway ML no ha publicat detalls de les tecnologies darrere d'Erase and Replace, la velocitat a la qual podeu substituir una planta d'interior per un bust raonablement convincent de Ronald Reagan suggereix que un model de difusió com Stable Diffusion (o, molt menys probable, un amb llicència DALL-E 2) és el motor que està reinventant l'objecte que trieu a Esborrar i substituir.

Substituir una planta d'interior per un bust de The Gipper no és tan ràpid com això, però és bastant ràpid. Font: https://app.runwayml.com/
El sistema té algunes restriccions de tipus DALL-E 2: les imatges o el text que marquen els filtres Esborra i Substituïu activaran un avís sobre la possible suspensió del compte en cas de més infraccions; pràcticament un clon complet de l'OpenAI en curs. policies per DALL-E 2 .
Molts dels resultats no tenen les típiques vores aspres de Stable Diffusion. Runway ML són inversors i socis de recerca a SD, i és possible que hagin entrenat un model propietari que sigui superior als pesos del punt de control 1.4 de codi obert amb què la resta de nosaltres estem lluitant actualment (com molts altres grups de desenvolupament, tant aficionats com professionals, actualment s'estan entrenant o ajustant). Models de difusió estable).
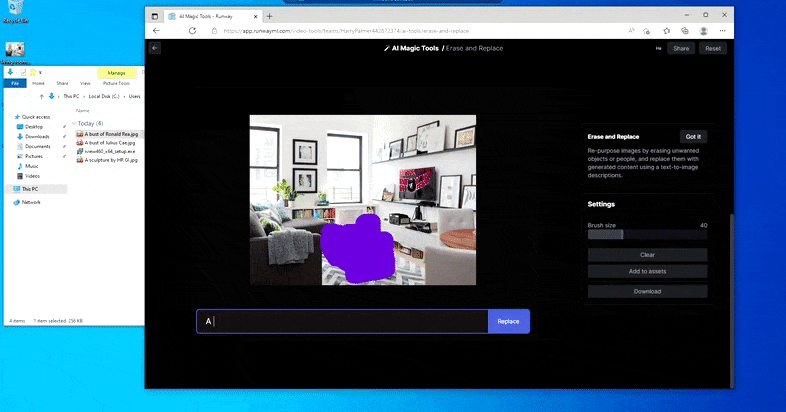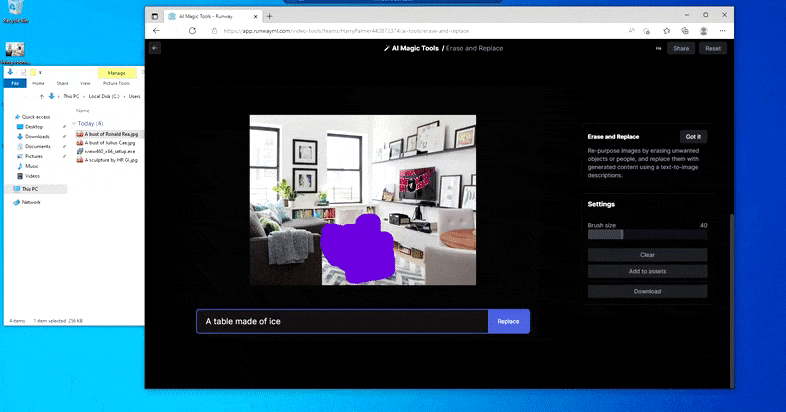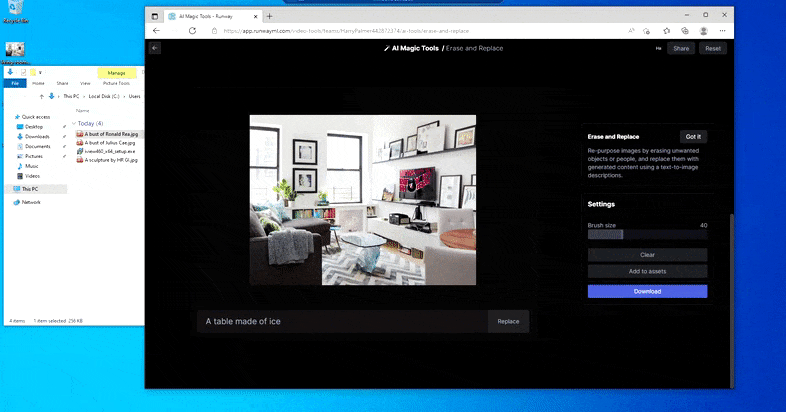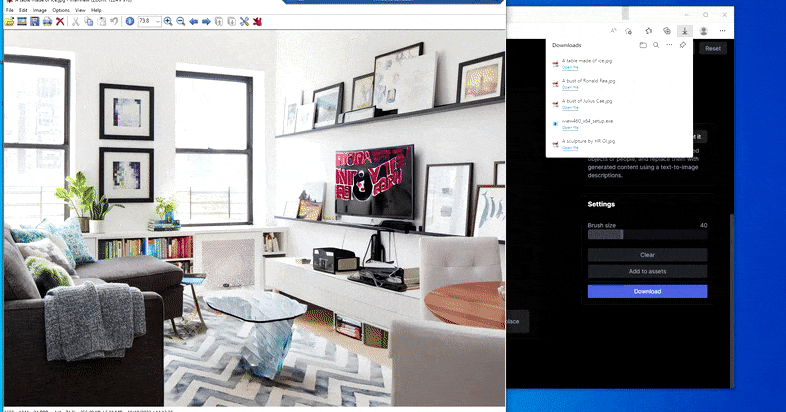
Substituint una taula domèstica per una "taula feta de gel" a Erase and Replace de Runway ML.
Igual que amb Imagic (vegeu més avall), Erase and Replace està "orientat a objectes", per dir-ho, no podeu esborrar una part "buida" de la imatge i pintar-la amb el resultat del vostre missatge de text; en aquest escenari, el sistema simplement traçarà l'objecte aparent més proper al llarg de la línia de visió de la màscara (com una paret o un televisor) i aplicarà la transformació allí.
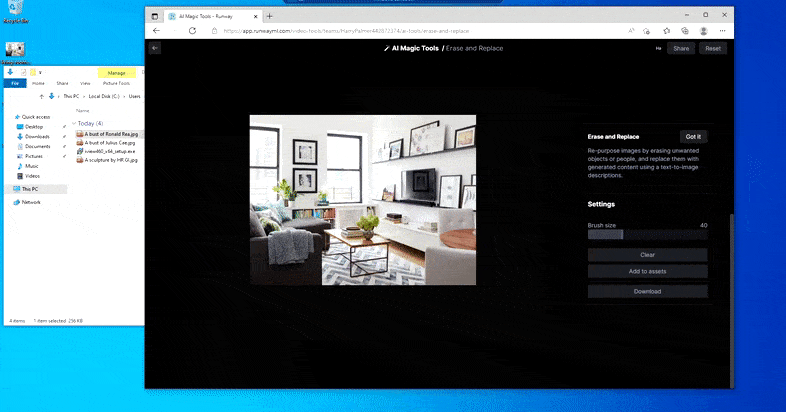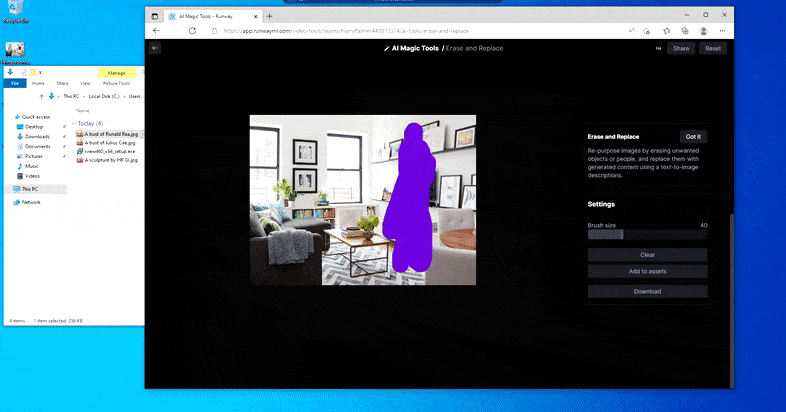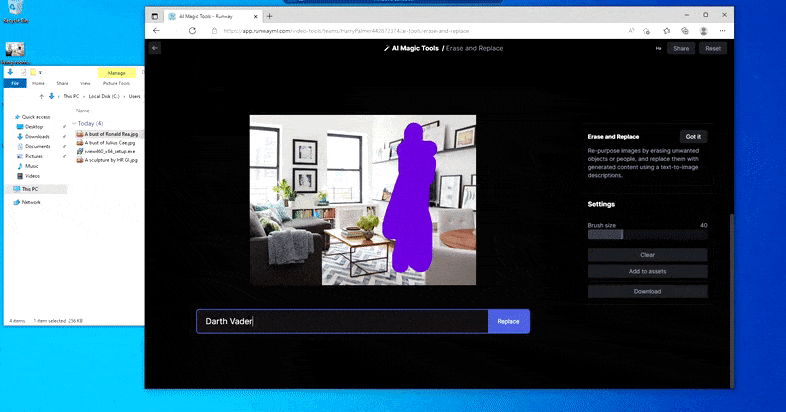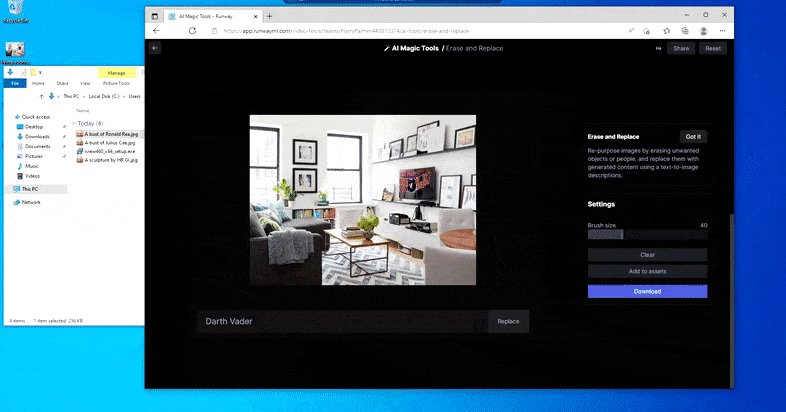
Com el seu nom indica, no podeu injectar objectes a l'espai buit a Esborrar i substituir. Aquí, un esforç per convocar el més famós dels senyors Sith dóna lloc a un estrany mural relacionat amb Vader a la televisió, aproximadament on es va dibuixar l'àrea de "reemplaçar".
És difícil saber si Erase and Replace està sent evasiva pel que fa a l'ús d'imatges amb drets d'autor (que encara estan en gran part obstruïdes, encara que amb èxit variable, a DALL-E 2), o si el model que s'utilitza al motor de renderització de fons. simplement no està optimitzat per a aquest tipus de coses.

El "Mural de Nicole Kidman" lleugerament NSFW indica que el model (presumiblement) basat en la difusió a la mà no té l'antic rebuig sistemàtic de DALL-E 2 de representar cares realistes o contingut atrevit, mentre que els resultats dels intents d'evidenciar obres amb drets d'autor van des de l'ambigüitat. ('xenomorf') a l'absurd ('el tron de ferro'). Inserció a la part inferior dreta, la imatge d'origen.
Seria interessant saber quins mètodes utilitza Erase and Replace per aïllar els objectes que és capaç de substituir. És de suposar que la imatge s'està executant a través d'alguna derivació de CLIP, amb els ítems discrets individuats per reconeixement d'objectes i posterior segmentació semàntica. Cap d'aquestes operacions funciona tan bé en una instal·lació comuna o de jardí de Stable Diffusion.
Però res és perfecte: de vegades el sistema sembla esborrar i no substituir, fins i tot quan (com hem vist a la imatge de dalt), el mecanisme de representació subjacent sap definitivament el que significa un missatge de text. En aquest cas, resulta impossible convertir una taula de cafè en un xenomorf; més aviat, la taula simplement desapareix.
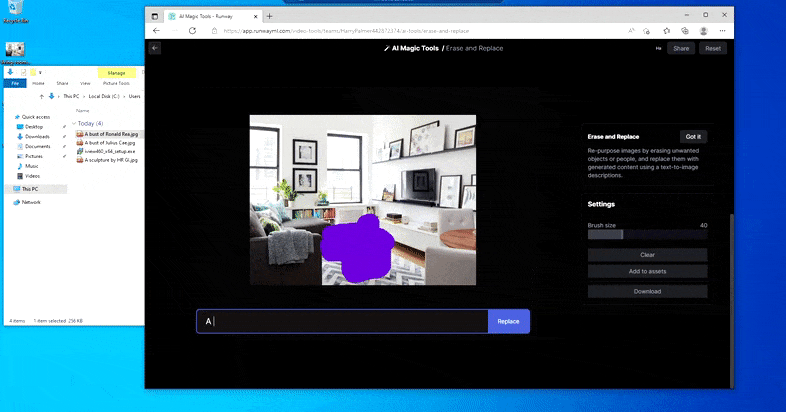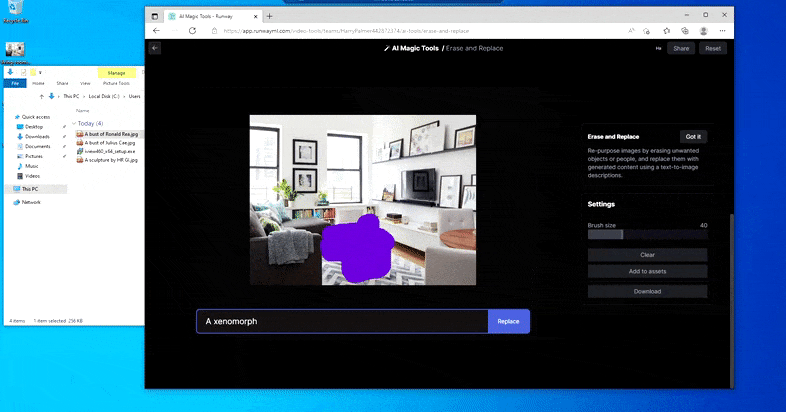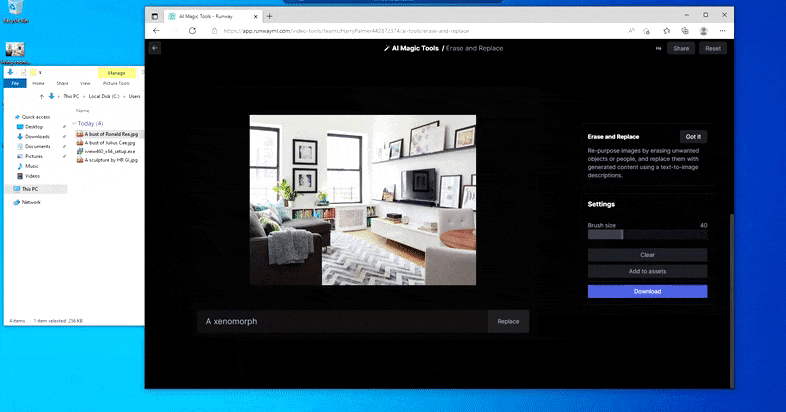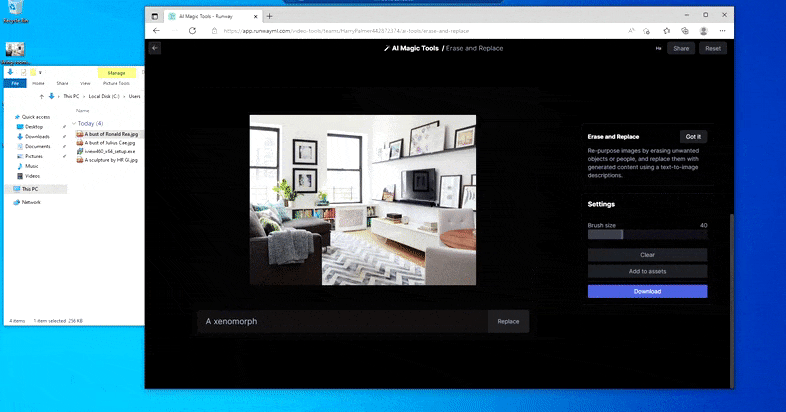
Una iteració més terrorífica de "On és Waldo", ja que Erase and Replace no aconsegueix produir un extraterrestre.
Esborrar i substituir sembla ser un sistema de substitució d'objectes eficaç, amb una excel·lent pintura. Tanmateix, no pot editar objectes percebuts existents, sinó només substituir-los. Alterar el contingut d'imatge existent sense comprometre el material ambiental és sens dubte una tasca molt més difícil, lligada a la llarga lluita del sector de la investigació de la visió per ordinador desenredament en els diversos espais latents dels marcs populars.
Màgic
És una tasca que aborda Imagic. El nou document ofereix nombrosos exemples d'edicions que modifiquen amb èxit les facetes individuals d'una foto sense tocar la resta de la imatge.

A Imagic, les imatges modificades no pateixen l'estirament, la distorsió i l'"endevinació d'oclusió" característics de les titelles deepfake, que utilitza anteriors limitats derivats d'una sola imatge.
El sistema utilitza un procés de tres etapes: optimització d'inserció de text; ajustament del model; i, finalment, la generació de la imatge modificada.

L'imagic codifica el missatge de text de destinació per recuperar la incrustació de text inicial i, a continuació, optimitza el resultat per obtenir la imatge d'entrada. Després d'això, el model generatiu s'ajusta amb precisió a la imatge d'origen, afegint una sèrie de paràmetres, abans de ser sotmès a la interpolació sol·licitada.
No és sorprenent que el marc es basa en el de Google Imatge arquitectura de text a vídeo, tot i que els investigadors afirmen que els principis del sistema són àmpliament aplicables als models de difusió latent.
Imagen utilitza una arquitectura de tres nivells, en lloc de la matriu de set nivells utilitzada per a la més recent de l'empresa iteració de text a vídeo del programari. Els tres mòduls diferents comprenen un model de difusió generativa que funciona amb una resolució de 64x64px; un model de superresolució que augmenta aquesta sortida a 256x256px; i un model addicional de superresolució per portar la sortida fins a una resolució de 1024 × 1024.
Imagic intervé en l'etapa més primerenca d'aquest procés, optimitzant la incrustació de text sol·licitada a l'etapa de 64 píxels en un optimitzador Adam a una taxa d'aprenentatge estàtica de 0.0001.

Una classe magistral en el desenrelament: aquells usuaris finals que han intentat canviar alguna cosa tan simple com el color d'un objecte representat en un model de difusió, GAN o NeRF, sabran com d'important és que Imagic pugui realitzar aquestes transformacions sense "esquinçar-se". ' la consistència de la resta de la imatge.
Aleshores, l'ajustament es realitza al model base d'Imagen, per 1500 passos per imatge d'entrada, condicionat a la incrustació revisada. Al mateix temps, la capa secundària de 64px>256px s'optimitza paral·lelament a la imatge condicionada. Els investigadors assenyalen que una optimització similar per a la capa final de 256px>1024px té "poc o cap efecte" en els resultats finals i, per tant, no ho han implementat.
El document afirma que el procés d'optimització triga aproximadament vuit minuts per a cada imatge a bessons TPUV4 xips. La renderització final té lloc al nucli d'Imatge sota el Esquema de mostreig DDIM.
En comú amb processos d'ajustament similars per a Google DreamBooth, les incrustacions resultants també es poden utilitzar per potenciar l'estilització, així com edicions fotorealistes que contenen informació extreta de la base de dades subjacent més àmplia que alimenta Imagen (ja que, com mostra la primera columna següent, les imatges d'origen no tenen el contingut necessari per efectuar aquestes transformacions).

Es poden obtenir moviments i edicions fotoreals flexibles mitjançant Imagic, mentre que els codis derivats i desenredats obtinguts en el procés es poden utilitzar amb la mateixa facilitat per a una sortida estilitzada.
Els investigadors van comparar Imagic amb treballs anteriors SDEdit, un enfocament basat en GAN del 2021, una col·laboració entre la Universitat de Stanford i la Universitat Carnegie Mellon; i Text2Live, una col·laboració, des d'abril de 2022, entre el Weizmann Institute of Science i NVIDIA.

Una comparació visual entre Imagic, SDEdit i Text2Live.
Està clar que els primers enfocaments estan lluitant, però a la fila inferior, que implica introduir un canvi massiu de postura, els titulars no aconsegueixen refigurar completament el material original, en comparació amb un èxit notable d'Imagic.
Els requisits de recursos d'Imagic i el temps d'entrenament per imatge, tot i que són curts per als estàndards d'aquestes activitats, fan que sigui poc probable que s'inclogui en una aplicació local d'edició d'imatges en ordinadors personals, i no està clar fins a quin punt el procés d'ajustament es podria fer. reduït als nivells de consumidors.
Tal com està, Imagic és una oferta impressionant que s'adapta més a les API: en qualsevol cas, pot ser més còmode un entorn amb el qual Google Research, amb crítiques pel que fa a facilitar el deepfaking.
Publicat per primera vegada el 18 d'octubre de 2022.















