
Sun'iy intellekt
To'g'ridan-to'g'ri afzalliklarni optimallashtirish: to'liq qo'llanma

Katta til modellarini (LLM) insoniy qadriyatlar va imtiyozlar bilan moslashtirish juda qiyin. An'anaviy usullar, masalan Insonlarning fikr-mulohazalaridan o'rganishni kuchaytirish (RLHF), model natijalarini yaxshilash uchun inson kirishlarini integratsiyalash orqali yo'l ochdi. Biroq, RLHF murakkab va resurs talab qiladigan bo'lishi mumkin, bu katta hisoblash quvvati va ma'lumotlarni qayta ishlashni talab qiladi. To'g'ridan-to'g'ri afzalliklarni optimallashtirish (DPO) yangi va soddalashtirilgan yondashuv sifatida paydo bo'lib, ushbu an'anaviy usullarga samarali alternativa taklif qiladi. Optimallashtirish jarayonini soddalashtirish orqali DPO nafaqat hisoblash yukini kamaytiradi, balki modelning inson xohishlariga tez moslashish qobiliyatini ham oshiradi.
Ushbu qo'llanmada biz DPO ga chuqur kirib boramiz, uning asoslari, amalga oshirilishi va amaliy qo'llanilishini o'rganamiz.
Afzalliklarni moslashtirish zarurati
DPO ni tushunish uchun nima uchun LLMlarni inson imtiyozlari bilan moslashtirish juda muhimligini tushunish juda muhimdir. O'zlarining ajoyib imkoniyatlariga qaramay, keng ma'lumotlar to'plamlarida o'qitilgan LLMlar ba'zida insoniy qadriyatlarga mos kelmaydigan, noxolis yoki noto'g'ri bo'lgan natijalarni berishi mumkin. Ushbu nosozlik turli yo'llar bilan namoyon bo'lishi mumkin:
- Xavfli yoki zararli kontent yaratish
- Noto'g'ri yoki noto'g'ri ma'lumotlarni taqdim etish
- Trening ma'lumotlarida mavjud bo'lgan noto'g'ri fikrlarni ko'rsatish
Ushbu muammolarni hal qilish uchun tadqiqotchilar insoniy fikr-mulohazalardan foydalangan holda LLMlarni nozik sozlash usullarini ishlab chiqdilar. Ushbu yondashuvlarning eng mashhuri RLHF bo'ldi.
RLHFni tushunish: DPO ning kashshofi
Insoniy fikr-mulohazalardan o'rganishni kuchaytirish (RLHF) LLMlarni insoniy imtiyozlarga moslashtirishning asosiy usuli bo'lib kelgan. Uning murakkabligini tushunish uchun RLHF jarayonini ajratamiz:
a) Nazorat ostidagi nozik sozlash (SFT): Jarayon yuqori sifatli javoblar ma'lumotlar to'plamida oldindan o'qitilgan LLMni nozik sozlashdan boshlanadi. Ushbu qadam modelga maqsadli vazifa uchun ko'proq mos va izchil natijalarni yaratishga yordam beradi.
b) Mukofot modellashtirish: Alohida mukofot modeli inson afzalliklarini bashorat qilish uchun o'qitiladi. Bunga quyidagilar kiradi:
- Berilgan takliflar uchun javob juftlarini yaratish
- Odamlar qaysi javobni afzal ko'rishlarini baholaydilar
- Ushbu imtiyozlarni bashorat qilish uchun modelni o'rgatish
c) Takomillashtirish: Yaxshi sozlangan LLM keyinchalik mustahkamlashni o'rganish yordamida yanada optimallashtiriladi. Mukofot modeli fikr-mulohazalarni taqdim etadi va LLMni insoniy imtiyozlarga mos keladigan javoblarni yaratishga yo'naltiradi.
RLHF jarayonini tasvirlash uchun soddalashtirilgan Python psevdokodi:
Samarali bo'lishiga qaramay, RLHF bir nechta kamchiliklarga ega:
- Bu bir nechta modellarni o'qitish va saqlashni talab qiladi (SFT, mukofot modeli va RL uchun optimallashtirilgan model)
- RL jarayoni beqaror va giperparametrlarga sezgir bo'lishi mumkin
- Bu hisoblash qimmat, modellar orqali ko'plab oldinga va orqaga o'tishlarni talab qiladi
Ushbu cheklovlar DPO ning rivojlanishiga olib keladigan oddiyroq, samaraliroq muqobillarni qidirishga turtki bo'ldi.
To'g'ridan-to'g'ri afzalliklarni optimallashtirish: asosiy tushunchalar

To'g'ridan-to'g'ri afzalliklarni optimallashtirish https://arxiv.org/abs/2305.18290
Ushbu rasm LLM natijalarini inson imtiyozlari bilan moslashtirishning ikkita alohida yondashuvini aks ettiradi: Insonning fikr-mulohazasidan o'rganishni kuchaytirish (RLHF) va to'g'ridan-to'g'ri afzalliklarni optimallashtirish (DPO). RLHF takroriy fikr-mulohaza zanjirlari orqali til modeli siyosatini boshqarish uchun mukofot modeliga tayanadi, DPO esa afzal maʼlumotlardan foydalangan holda inson afzal koʻrgan javoblarga mos keladigan model natijalarini toʻgʻridan-toʻgʻri optimallashtiradi. Ushbu taqqoslash har bir usulning kuchli tomonlari va potentsial qo'llanilishini ta'kidlab, kelajakdagi LLMlarni inson kutganlariga yaxshiroq moslashtirish uchun qanday o'qitilishi mumkinligi haqida tushuncha beradi.
DPO ortidagi asosiy g'oyalar:
a) Yashirin mukofotni modellashtirish: DPO til modelining o'ziga yashirin mukofot funktsiyasi sifatida qarash orqali alohida mukofot modeliga ehtiyojni yo'q qiladi.
b) Siyosatga asoslangan shakllantirish: Mukofot funktsiyasini optimallashtirish o'rniga, DPO afzal javoblar ehtimolini maksimal darajada oshirish uchun siyosatni (til modeli) to'g'ridan-to'g'ri optimallashtiradi.
c) Yopiq shakldagi yechim: DPO matematik tushunchadan foydalanadi, bu esa optimal siyosatga yopiq shaklda yechim topishga imkon beradi va takroriy RL yangilanishlariga ehtiyoj qolmaydi.
DPOni amalga oshirish: Amaliy kodni o'rganish
Quyidagi rasmda PyTorch yordamida DPO yo'qotish funksiyasini amalga oshiradigan kod parchasi ko'rsatilgan. Ushbu funktsiya til modellari natijalarini inson xohishlariga ko'ra qanday ustuvorligini aniqlashda hal qiluvchi rol o'ynaydi. Bu erda asosiy komponentlarning taqsimoti:
- Funktsiya imzosi:
dpo_lossfunktsiya bir nechta parametrlarni oladi, shu jumladan siyosat jurnali ehtimoli (pi_logps), mos yozuvlar modeli jurnali ehtimolliklari (ref_logps) va afzal qilingan va afzal ko'rilmagan to'ldirishlarni ifodalovchi indekslar (yw_idxs,yl_idxs). Bundan tashqari, abetaparametr KL jazosining kuchini nazorat qiladi. - Jurnal ehtimollik ekstrakti: Kod siyosat va mos yozuvlar modellaridan afzal qilingan va afzal ko'rilmagan tugatishlar jurnali ehtimolini chiqaradi.
- Jurnal nisbatlarini hisoblash: Afzal va afzal ko'rilmagan tugatishlar jurnali ehtimoli o'rtasidagi farq siyosat va mos yozuvlar modellari uchun hisoblanadi. Bu nisbat optimallashtirish yo'nalishi va hajmini aniqlashda hal qiluvchi ahamiyatga ega.
- Yo'qotish va mukofotni hisoblash: Zarar yordamida hisoblab chiqiladi
logsigmoidfunktsiyasi, mukofotlar esa siyosat va mos yozuvlar jurnali ehtimoli o'rtasidagi farqni miqyoslash orqali aniqlanadibeta.

PyTorch yordamida DPO yo'qotish funktsiyasi
Keling, bu maqsadlarga qanday erishayotganini tushunish uchun DPO ortidagi matematikaga sho'ng'iylik.
DPO matematikasi
DPO - bu afzal o'rganish muammosini aqlli qayta shakllantirish. Mana, bosqichma-bosqich taqsimot:
a) Boshlanish nuqtasi: KL-cheklangan mukofotni maksimallashtirish
RLHFning asl maqsadi quyidagicha ifodalanishi mumkin:
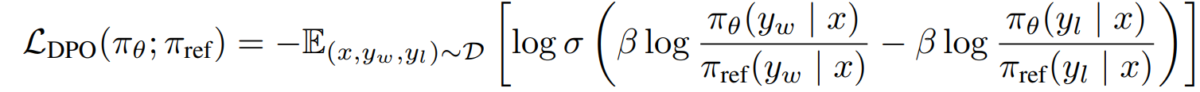
- pth - biz optimallashtirayotgan siyosat (til modeli).
- r(x,y) - mukofot funksiyasi
- pref mos yozuvlar siyosati (odatda dastlabki SFT modeli)
- b KL divergensiya cheklovining kuchini nazorat qiladi
b) Optimal siyosat shakli: Ko'rsatish mumkinki, ushbu maqsad uchun optimal siyosat quyidagi shaklda bo'ladi:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Bu yerda Z(x) normalanish konstantasi.
c) Mukofot siyosatining ikkiligi: DPO ning asosiy tushunchasi mukofot funktsiyasini optimal siyosat nuqtai nazaridan ifodalashdir:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Afzallik modeli Preferentlar Bredli-Terri modeliga mos keladi deb faraz qilsak, y1 ni y2 dan ustun qo'yish ehtimolini quyidagicha ifodalashimiz mumkin:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Bu erda s logistik funktsiya.
e) DPO maqsadi Mukofot siyosati ikkitomonlamasini imtiyozli modelga almashtirib, biz DPO maqsadiga erishamiz:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Ushbu maqsad RL algoritmlariga ehtiyoj sezmasdan, standart gradient tushish texnikasi yordamida optimallashtirilishi mumkin.
DPOni amalga oshirish
Endi biz DPO nazariyasini tushunganimizdan so'ng, uni amalda qanday amalga oshirishni ko'rib chiqaylik. Biz foydalanamiz Python va PyTorch bu misol uchun:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Qiyinchiliklar va kelajak yo'nalishlari
DPO an'anaviy RLHF yondashuvlariga nisbatan sezilarli afzalliklarga ega bo'lsa-da, hali ham muammolar va keyingi tadqiqotlar uchun yo'nalishlar mavjud:
a) Kattaroq modellarga o'lchash imkoniyati:
Til modellari hajmi o'sishda davom etar ekan, DPO ni yuzlab milliardlab parametrlarga ega modellarga samarali qo'llash ochiq muammo bo'lib qolmoqda. Tadqiqotchilar quyidagi usullarni o'rganmoqdalar:
- Samarali nozik sozlash usullari (masalan, LoRA, prefiksni sozlash)
- Taqdim etilgan o'quv optimallashtirishlari
- Gradientni tekshirish va aralash aniqlik bilan mashq qilish
DPO bilan LoRA dan foydalanishga misol:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Ko'p vazifali va bir nechta zarbali moslashuv:
Cheklangan imtiyozli ma'lumotlarga ega yangi vazifalar yoki domenlarga samarali moslasha oladigan DPO texnikasini ishlab chiqish faol tadqiqot sohasidir. O'rganilayotgan yondashuvlarga quyidagilar kiradi:
- Tez moslashish uchun meta-o'rganish ramkalari
- DPO uchun tezkor sozlash
- O'rganishni umumiy afzal modellardan ma'lum domenlarga o'tkazing
c) noaniq yoki ziddiyatli afzalliklarni boshqarish:
Haqiqiy dunyo ma'lumotlari ko'pincha noaniqliklar yoki ziddiyatlarni o'z ichiga oladi. DPO ning bunday ma'lumotlarga ishonchliligini oshirish juda muhimdir. Potentsial yechimlarga quyidagilar kiradi:
- Ehtimoliy afzalliklarni modellashtirish
- Noaniqliklarni hal qilish uchun faol o'rganish
- Ko'p agentli imtiyozlarni birlashtirish
Ehtimoliy afzalliklarni modellashtirishga misol:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) DPO ni boshqa moslashtirish usullari bilan birlashtirish:
DPO ni boshqa moslashtirish yondashuvlari bilan integratsiyalash yanada mustahkam va qobiliyatli tizimlarga olib kelishi mumkin:
- Aniq cheklovlarni qondirish uchun konstitutsiyaviy AI tamoyillari
- Murakkab afzal ko'rish uchun bahs va rekursiv mukofotni modellashtirish
- Mukofotning asosiy funktsiyalari haqida xulosa chiqarish uchun teskari mustahkamlashni o'rganish
DPOni konstitutsiyaviy AI bilan birlashtirishga misol:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Amaliy mulohazalar va eng yaxshi amaliyotlar
Haqiqiy ilovalar uchun DPO ni amalga oshirishda quyidagi maslahatlarga e'tibor bering:
a) Ma'lumot sifati: Siz tanlagan maʼlumotlarning sifati juda muhim. Ma'lumotlar to'plamiga ishonch hosil qiling:
- Turli xil ma'lumotlar va kerakli xatti-harakatlarni qamrab oladi
- Izchil va ishonchli imtiyozli izohlarga ega
- Har xil turdagi afzalliklarni muvozanatlashtiradi (masalan, haqiqat, xavfsizlik, uslub)
b) Giperparametrlarni sozlash: DPO RLHF ga qaraganda kamroq giperparametrlarga ega bo'lsa-da, sozlash hali ham muhim:
- b (beta): imtiyozlarni qondirish va mos yozuvlar modelidan ajralib chiqish o'rtasidagi muvozanatni boshqaradi. Atrofdagi qadriyatlardan boshlang 0.1-0.5.
- O'rganish tezligi: standart nozik sozlashdan pastroq o'rganish tezligidan foydalaning, odatda diapazonda 1e-6 dan 1e-5 gacha.
- Partiya hajmi: Kattaroq partiya o'lchamlari (32-128) ko'pincha afzal o'rganish uchun yaxshi ishlaydi.
c) Takroriy takomillashtirish: DPO iterativ tarzda qo'llanilishi mumkin:
- DPO yordamida dastlabki modelni o'rgating
- O'qitilgan model yordamida yangi javoblarni yarating
- Ushbu javoblar bo'yicha yangi afzal ma'lumotlarni to'plang
- Kengaytirilgan maʼlumotlar toʻplamidan foydalanib qayta oʻqitish

To'g'ridan-to'g'ri afzalliklarni optimallashtirish samaradorligi
Ushbu rasmda GPT-4 kabi LLMlarning turli xil o'qitish usullari, jumladan, To'g'ridan-to'g'ri afzalliklarni optimallashtirish (DPO), Nazorat qilinadigan nozik sozlash (SFT) va Proksimal siyosatni optimallashtirish (PPO) bo'yicha inson mulohazalari bilan solishtirganda ishlashi ko'rsatilgan. Jadvaldan ko'rinib turibdiki, GPT-4 natijalari odamlarning xohish-istaklariga, ayniqsa umumlashtirish vazifalariga tobora ko'proq mos keladi. GPT-4 va inson sharhlovchilari o'rtasidagi kelishuv darajasi modelning inson tomonidan yaratilgan kontent kabi inson baholovchilari bilan rezonanslashadigan kontent yaratish qobiliyatini namoyish etadi.
Case Studies va Ilovalar
DPO samaradorligini ko'rsatish uchun keling, ba'zi haqiqiy ilovalarni va uning ba'zi variantlarini ko'rib chiqaylik:
- Iterativ DPO: Snorkel (2023) tomonidan ishlab chiqilgan ushbu variant rad etish namunalarini DPO bilan birlashtirib, o'quv ma'lumotlarini yanada aniqroq tanlash jarayonini ta'minlaydi. Imtiyozli tanlab olishning bir necha raundini takrorlash orqali model umumlashtirishga va shovqinli yoki noxolis afzalliklarga haddan tashqari moslashishdan qochishga qodir.
- IPO (Iterativ afzalliklarni optimallashtirish): Azar va boshqalar tomonidan kiritilgan. (2023), IPO ortiqcha moslamani oldini olish uchun tartibga solish atamasini qo'shadi, bu afzalliklarga asoslangan optimallashtirishda keng tarqalgan muammodir. Ushbu kengaytma modellarga imtiyozlarga rioya qilish va umumlashtirish imkoniyatlarini saqlab qolish o'rtasidagi muvozanatni saqlashga imkon beradi.
- KTO (Bilimlarni uzatishni optimallashtirish): Ethayarajh va boshqalardan yangiroq variant. (2023), KTO ikkilik imtiyozlardan butunlay voz kechadi. Buning o'rniga u bilimlarni mos yozuvlar modelidan siyosat modeliga o'tkazishga, insoniy qadriyatlarga yanada yumshoq va izchil moslashish uchun optimallashtirishga qaratilgan.
- Domenlararo o'rganish uchun multi-modal DPO Xu va boshqalar tomonidan. (2024): DPO turli usullarda - matn, tasvir va audioda qo'llaniladigan yondashuv - turli xil ma'lumotlar turlari bo'yicha modellarni inson afzalliklari bilan moslashtirishda o'zining ko'p qirraliligini namoyish etadi. Ushbu tadqiqot DPO ning murakkab, ko'p modali vazifalarni bajarishga qodir bo'lgan keng qamrovli AI tizimlarini yaratishdagi salohiyatini ta'kidlaydi.











