مصنوعی ذہانت
ChatGPT کی پہلی سالگرہ: AI تعامل کے مستقبل کو نئی شکل دینا

ChatGPT کے پہلے سال پر غور کرتے ہوئے، یہ واضح ہے کہ اس ٹول نے AI منظر کو نمایاں طور پر تبدیل کر دیا ہے۔ 2022 کے آخر میں شروع کیا گیا، ChatGPT اپنے صارف دوست، گفتگو کے انداز کی وجہ سے نمایاں ہوا جس نے AI کے ساتھ بات چیت کو مشین سے زیادہ کسی شخص کے ساتھ چیٹنگ کرنے جیسا محسوس کیا۔ اس نئے انداز نے عوام کی نظروں کو تیزی سے اپنی گرفت میں لے لیا۔ اپنی ریلیز کے صرف پانچ دنوں کے اندر، ChatGPT پہلے ہی ایک ملین صارفین کو اپنی طرف متوجہ کر چکا ہے۔ 2023 کے اوائل تک، یہ تعداد تقریباً 100 ملین ماہانہ صارفین تک پہنچ گئی، اور اکتوبر تک، پلیٹ فارم دنیا بھر میں تقریباً 1.7 بلین وزٹ کر رہا تھا۔ یہ نمبر اس کی مقبولیت اور افادیت کے بارے میں جلدیں بولتے ہیں۔
پچھلے ایک سال کے دوران، صارفین نے ChatGPT استعمال کرنے کے لیے ہر طرح کے تخلیقی طریقے تلاش کیے ہیں، جیسے کہ ای میلز لکھنے اور ریزیومے کو اپ ڈیٹ کرنے سے لے کر کامیاب کاروبار شروع کرنے تک۔ لیکن یہ صرف اس بارے میں نہیں ہے کہ لوگ اسے کس طرح استعمال کر رہے ہیں۔ ٹیکنالوجی خود بڑھی اور بہتر ہوئی ہے۔ ابتدائی طور پر، ChatGPT ایک مفت سروس تھی جو متنی جوابات پیش کرتی تھی۔ اب، ChatGPT Plus ہے، جس میں ChatGPT-4 شامل ہے۔ یہ اپ ڈیٹ شدہ ورژن زیادہ ڈیٹا پر تربیت یافتہ ہے، کم غلط جواب دیتا ہے، اور پیچیدہ ہدایات کو بہتر طور پر سمجھتا ہے۔
سب سے بڑی اپ ڈیٹس میں سے ایک یہ ہے کہ ChatGPT اب متعدد طریقوں سے بات چیت کر سکتا ہے – یہ سن سکتا ہے، بول سکتا ہے اور یہاں تک کہ تصاویر پر کارروائی بھی کر سکتا ہے۔ اس کا مطلب ہے کہ آپ اس کے موبائل ایپ کے ذریعے اس سے بات کر سکتے ہیں اور جوابات حاصل کرنے کے لیے اسے تصاویر دکھا سکتے ہیں۔ ان تبدیلیوں نے AI کے لیے نئے امکانات کھول دیے ہیں اور یہ بدل دیا ہے کہ لوگ ہماری زندگی میں AI کے کردار کو کس طرح دیکھتے اور سوچتے ہیں۔
ٹیک ڈیمو کے طور پر اپنے آغاز سے لے کر ٹیک دنیا میں ایک بڑے کھلاڑی کے طور پر اس کی موجودہ حیثیت تک، ChatGPT کا سفر کافی متاثر کن ہے۔ ابتدائی طور پر، اسے عوام سے رائے حاصل کرکے ٹیکنالوجی کو جانچنے اور بہتر بنانے کے طریقے کے طور پر دیکھا گیا۔ لیکن یہ تیزی سے AI زمین کی تزئین کا ایک لازمی حصہ بن گیا۔ یہ کامیابی ظاہر کرتی ہے کہ بڑے لینگویج ماڈلز (LLMs) کو انسانوں کے زیر نگرانی سیکھنے اور فیڈ بیک دونوں کے ساتھ ٹھیک کرنا کتنا موثر ہے۔ نتیجے کے طور پر، ChatGPT سوالات اور کاموں کی ایک وسیع رینج کو سنبھال سکتا ہے۔
سب سے زیادہ قابل اور ورسٹائل AI سسٹمز تیار کرنے کی دوڑ نے اوپن سورس اور ChatGPT جیسے ملکیتی ماڈل دونوں کے پھیلاؤ کو جنم دیا ہے۔ ان کی عمومی صلاحیتوں کو سمجھنے کے لیے کاموں کے وسیع میدان میں جامع بینچ مارکس کی ضرورت ہوتی ہے۔ یہ سیکشن ان معیارات کو دریافت کرتا ہے، اس بات پر روشنی ڈالتا ہے کہ کس طرح مختلف ماڈلز بشمول ChatGPT، ایک دوسرے کے خلاف کھڑے ہوتے ہیں۔
ایل ایل ایم کی تشخیص: بینچ مارکس
- ایم ٹی بنچ: یہ بینچ مارک آٹھ ڈومینز میں ملٹی ٹرن گفتگو اور ہدایات کی پیروی کرنے کی صلاحیتوں کی جانچ کرتا ہے: تحریر، رول پلے، معلومات کا اخراج، استدلال، ریاضی، کوڈنگ، STEM علم، اور انسانیت/سماجی علوم۔ مضبوط LLMs جیسے GPT-4 کو تشخیص کار کے طور پر استعمال کیا جاتا ہے۔
- الپاکا ایول: AlpacaFarm تشخیصی سیٹ کی بنیاد پر، یہ LLM پر مبنی خودکار تشخیص کار امیدوار ماڈلز کی جیت کی شرح کا حساب لگاتے ہوئے، GPT-4 اور Claude جیسے اعلی درجے کے LLMs کے جوابات کے خلاف ماڈلز کو معیار بناتا ہے۔
- ایل ایل ایم لیڈر بورڈ کھولیں۔: لینگویج ماڈل ایویلیوایشن ہارنس کا استعمال کرتے ہوئے، یہ لیڈر بورڈ صفر شاٹ اور چند شاٹ سیٹنگز دونوں میں، استدلال کے چیلنجز اور جنرل نالج ٹیسٹ سمیت سات اہم بینچ مارکس پر LLMs کا جائزہ لیتا ہے۔
- بڑا بنچ: یہ باہمی تعاون پر مبنی بینچ مارک مختلف موضوعات اور زبانوں پر محیط 200 سے زیادہ نئے زبان کے کاموں کا احاطہ کرتا ہے۔ اس کا مقصد LLMs کی تحقیقات کرنا اور ان کی مستقبل کی صلاحیتوں کی پیش گوئی کرنا ہے۔
- چیٹ ایول: ایک ملٹی ایجنٹ ڈیبیٹ فریم ورک جو ٹیموں کو آزادانہ سوالات اور روایتی قدرتی زبان کی تخلیق کے کاموں پر مختلف ماڈلز کے جوابات کے معیار پر خود مختار طور پر بحث کرنے اور جانچنے کی اجازت دیتا ہے۔
تقابلی کارکردگی
عمومی معیارات کے لحاظ سے، اوپن سورس LLMs نے قابل ذکر پیش رفت دکھائی ہے۔ Llama-2-70Bمثال کے طور پر، متاثر کن نتائج حاصل کیے، خاص طور پر انسٹرکشن ڈیٹا کے ساتھ ٹھیک ٹیون ہونے کے بعد۔ اس کے مختلف قسم، Llama-2-chat-70B، نے GPT-92.66-ٹربو کو پیچھے چھوڑتے ہوئے، 3.5% جیت کی شرح کے ساتھ AlpacaEval میں شاندار کارکردگی کا مظاہرہ کیا۔ تاہم، GPT-4 95.28% جیت کی شرح کے ساتھ سب سے آگے ہے۔
Zephyr-7B، ایک چھوٹا ماڈل، بڑے 70B LLMs کے مقابلے کی صلاحیتوں کا مظاہرہ کیا، خاص طور پر AlpacaEval اور MT-Bench میں۔ دریں اثنا، WizardLM-70B، متنوع رینج کے ہدایات کے اعداد و شمار کے ساتھ ٹھیک ہے، نے MT-Bench پر اوپن سورس LLMs میں سب سے زیادہ اسکور کیا۔ تاہم، یہ اب بھی GPT-3.5-turbo اور GPT-4 سے پیچھے ہے۔
ایک دلچسپ اندراج، GodziLLa2-70B، نے اوپن LLM لیڈر بورڈ پر ایک مسابقتی اسکور حاصل کیا، جس میں متنوع ڈیٹاسیٹس کے امتزاج کے تجرباتی ماڈلز کی صلاحیت کو ظاہر کیا گیا۔ اسی طرح، Yi-34B، شروع سے تیار کیا گیا، GPT-3.5-turbo کے مقابلے کے سکور کے ساتھ نمایاں رہا اور GPT-4 سے تھوڑا پیچھے رہا۔
الٹرا للاما نے متنوع اور اعلیٰ معیار کے ڈیٹا پر اپنے فائن ٹیوننگ کے ساتھ اپنے مجوزہ بینچ مارکس میں GPT-3.5-ٹربو کو ملایا اور یہاں تک کہ اسے دنیا اور پیشہ ورانہ علم کے شعبوں میں بھی پیچھے چھوڑ دیا۔
اسکیلنگ اپ: دی رائز آف دی جائنٹ ایل ایل ایم
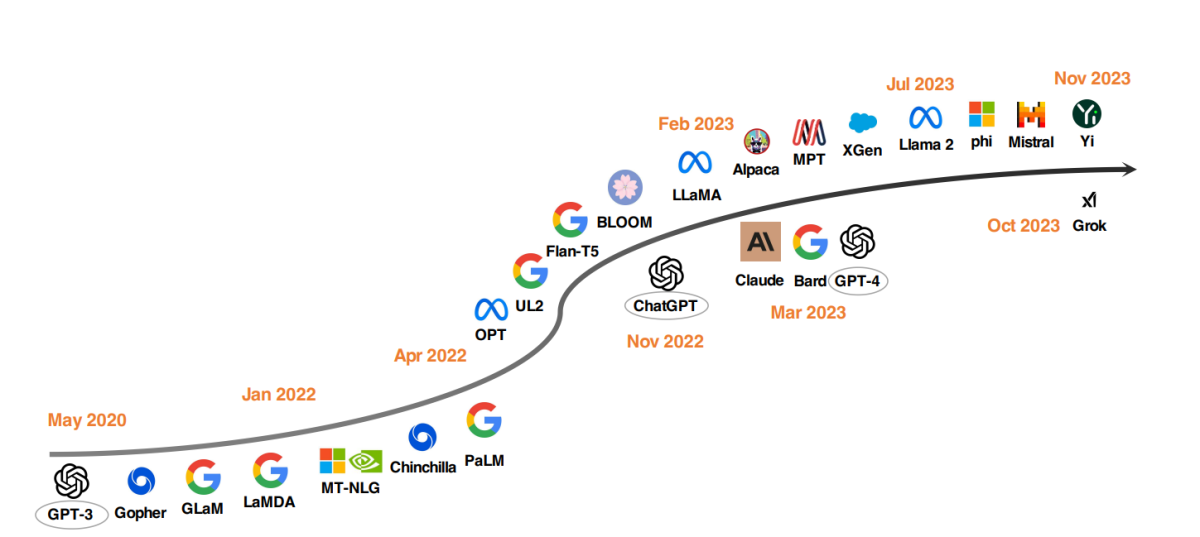
2020 سے سرفہرست LLM ماڈل
ایل ایل ایم کی ترقی میں ایک قابل ذکر رجحان ماڈل پیرامیٹرز کو بڑھانا رہا ہے۔ Gopher، GLaM، LaMDA، MT-NLG، اور PaLM جیسے ماڈلز نے حدوں کو آگے بڑھایا ہے، جس کا اختتام 540 بلین پیرامیٹرز کے ساتھ ہوا۔ ان ماڈلز نے غیر معمولی صلاحیتوں کا مظاہرہ کیا ہے، لیکن ان کے بند ماخذ کی نوعیت نے ان کے وسیع اطلاق کو محدود کر دیا ہے۔ اس حد نے اوپن سورس LLMs کو تیار کرنے میں دلچسپی کو ہوا دی ہے، یہ ایک ایسا رجحان ہے جو زور پکڑ رہا ہے۔
ماڈل کے سائز کو بڑھانے کے متوازی طور پر، محققین نے متبادل حکمت عملیوں کی تلاش کی ہے۔ صرف ماڈلز کو بڑا بنانے کے بجائے، انہوں نے چھوٹے ماڈلز کی پری ٹریننگ کو بہتر بنانے پر توجہ مرکوز کی ہے۔ مثالوں میں Chinchilla اور UL2 شامل ہیں، جس نے دکھایا ہے کہ زیادہ ہمیشہ بہتر نہیں ہوتا ہے۔ ہوشیار حکمت عملی بھی موثر نتائج دے سکتی ہے۔ مزید برآں، FLAN، T0، اور Flan-T5 جیسے پروجیکٹس کے ساتھ لینگویج ماڈلز کی انسٹرکشن ٹیوننگ پر کافی توجہ دی گئی ہے۔
چیٹ جی پی ٹی کیٹالسٹ
اوپن اے آئی کا تعارف چیٹ جی پی ٹی NLP تحقیق میں ایک اہم موڑ کا نشان لگایا۔ OpenAI کا مقابلہ کرنے کے لیے، Google اور Anthropic جیسی کمپنیوں نے بالترتیب اپنے ماڈل، Bard اور Claude کو لانچ کیا۔ اگرچہ یہ ماڈل بہت سے کاموں میں ChatGPT کے مقابلے کی کارکردگی دکھاتے ہیں، لیکن وہ اب بھی OpenAI، GPT-4 کے تازہ ترین ماڈل سے پیچھے ہیں۔ ان ماڈلز کی کامیابی بنیادی طور پر انسانی تاثرات (RLHF) سے کمک سیکھنے سے منسوب ہے، یہ ایک ایسی تکنیک ہے جو مزید بہتری کے لیے تحقیق پر توجہ مرکوز کر رہی ہے۔
OpenAI کے Q* (Q-Star) کے ارد گرد افواہیں اور قیاس آرائیاں
حالیہ رپورٹیں تجویز کرتے ہیں کہ اوپن اے آئی کے محققین نے Q* (تلفظ Q ستارہ) نامی ایک نئے ماڈل کی ترقی کے ساتھ AI میں اہم پیشرفت حاصل کی ہے۔ مبینہ طور پر، Q* میں گریڈ-اسکول کی سطح کی ریاضی کو انجام دینے کی صلاحیت ہے، یہ ایک ایسا کارنامہ ہے جس نے ماہرین کے درمیان مصنوعی جنرل انٹیلی جنس (AGI) کی جانب ایک سنگ میل کے طور پر اس کی صلاحیت کے بارے میں بحث کو جنم دیا ہے۔ اگرچہ OpenAI نے ان رپورٹس پر کوئی تبصرہ نہیں کیا ہے، لیکن Q* کی افواہوں کی صلاحیتوں نے سوشل میڈیا اور AI کے شوقین افراد میں کافی جوش اور قیاس آرائیاں پیدا کی ہیں۔
Q* کی ترقی قابل ذکر ہے کیونکہ موجودہ زبان کے ماڈل جیسے ChatGPT اور GPT-4، جبکہ کچھ ریاضی کے کاموں کے قابل ہیں، انہیں قابل اعتماد طریقے سے سنبھالنے میں خاص طور پر ماہر نہیں ہیں۔ چیلنج AI ماڈلز کے لیے نہ صرف پیٹرن کو پہچاننے کی ضرورت میں ہے، جیسا کہ وہ فی الحال گہری سیکھنے اور ٹرانسفارمرز کے ذریعے کرتے ہیں، بلکہ تجریدی تصورات کو استدلال اور سمجھنا بھی ہے۔ ریاضی، استدلال کے لیے ایک معیار ہونے کے ناطے، تجریدی تصورات کی گہری گرفت کا مظاہرہ کرتے ہوئے، AI کو متعدد مراحل کی منصوبہ بندی اور ان پر عمل درآمد کرنے کی ضرورت ہوتی ہے۔ یہ قابلیت AI صلاحیتوں میں ایک اہم چھلانگ کا نشان بنائے گی، ممکنہ طور پر ریاضی سے آگے دوسرے پیچیدہ کاموں تک پھیلے گی۔
تاہم، ماہرین اس پیشرفت کو زیادہ کرنے کے خلاف احتیاط کرتے ہیں۔ اگرچہ ایک AI نظام جو ریاضی کے مسائل کو قابل اعتماد طریقے سے حل کرتا ہے ایک متاثر کن کامیابی ہو گی، لیکن یہ ضروری نہیں کہ یہ سپر انٹیلجنٹ AI یا AGI کی آمد کا اشارہ کرے۔ موجودہ AI تحقیق، بشمول OpenAI کی کوششوں نے، زیادہ پیچیدہ کاموں میں کامیابی کی مختلف ڈگریوں کے ساتھ، ابتدائی مسائل پر توجہ مرکوز کی ہے۔
ممکنہ ایپلی کیشنز کی ترقی جیسے Q* وسیع ہیں، ذاتی ٹیوشن سے لے کر سائنسی تحقیق اور انجینئرنگ میں معاونت تک۔ تاہم، توقعات کا انتظام کرنا اور اس طرح کی پیشرفت سے وابستہ حدود اور حفاظتی خدشات کو پہچاننا بھی ضروری ہے۔ AI کے وجودی خطرات لاحق ہونے کے خدشات، OpenAI کی ایک بنیادی پریشانی، مناسب رہتی ہے، خاص طور پر جب AI سسٹمز حقیقی دنیا کے ساتھ زیادہ انٹرفیس کرنا شروع کر دیتے ہیں۔
اوپن سورس ایل ایل ایم موومنٹ
اوپن سورس ایل ایل ایم ریسرچ کو فروغ دینے کے لیے، میٹا نے لاما سیریز کے ماڈلز جاری کیے، جس سے لاما پر مبنی نئی پیشرفت کی لہر شروع ہوئی۔ اس میں ہدایات کے اعداد و شمار کے ساتھ ٹھیک بنائے گئے ماڈلز شامل ہیں، جیسے کہ الپاکا، ویکونا، لیما، اور وزرڈ ایل ایم۔ تحقیق ایجنٹ کی صلاحیتوں کو بڑھانے، منطقی استدلال، اور لاما پر مبنی فریم ورک کے اندر طویل سیاق و سباق کی ماڈلنگ میں بھی برانچ کر رہی ہے۔
مزید برآں، MPT، Falcon، XGen، Phi، Baichuan، جیسے پروجیکٹس کے ساتھ شروع سے طاقتور LLM تیار کرنے کا ایک بڑھتا ہوا رجحان ہے۔ مجرم, گروک، اور یی۔ یہ کوششیں بند سورس LLMs کی صلاحیتوں کو جمہوری بنانے کے عزم کی عکاسی کرتی ہیں، جس سے جدید AI ٹولز کو مزید قابل رسائی اور موثر بنایا جاتا ہے۔
ہیلتھ کیئر میں چیٹ جی پی ٹی اور اوپن سورس ماڈلز کا اثر
ہم ایک ایسے مستقبل کی طرف دیکھ رہے ہیں جہاں LLMs کلینیکل نوٹ لینے، معاوضے کے لیے فارم بھرنے، اور تشخیص اور علاج کی منصوبہ بندی میں معالجین کی معاونت کرتے ہیں۔ اس نے ٹیک جنات اور صحت کی دیکھ بھال کے اداروں دونوں کی توجہ حاصل کی ہے۔
مائیکروسافٹ ایپک کے ساتھ بات چیتایک معروف الیکٹرانک ہیلتھ ریکارڈ سافٹ ویئر فراہم کنندہ، صحت کی دیکھ بھال میں LLMs کے انضمام کا اشارہ دیتا ہے۔ UC سان ڈیاگو ہیلتھ اور سٹینفورڈ یونیورسٹی میڈیکل سنٹر میں پہلے سے ہی اقدامات جاری ہیں۔ اسی طرح، گوگل کے میو کلینک اور ایمیزون ویب سروسز کے ساتھ شراکت داری' HealthScribe کا آغاز، ایک AI کلینیکل ڈاکومنٹیشن سروس، اس سمت میں اہم پیش رفت کو نشان زد کرتی ہے۔
تاہم، یہ تیزی سے تعیناتیاں ادویات کے کنٹرول کو کارپوریٹ مفادات کے حوالے کرنے کے بارے میں خدشات پیدا کرتی ہیں۔ ان LLMs کی ملکیتی نوعیت ان کا اندازہ لگانا مشکل بناتی ہے۔ منافع بخش وجوہات کی بنا پر ان کی ممکنہ ترمیم یا بندش سے مریض کی دیکھ بھال، رازداری اور حفاظت پر سمجھوتہ ہو سکتا ہے۔
صحت کی دیکھ بھال میں ایل ایل ایم کی ترقی کے لیے کھلے اور جامع نقطہ نظر کی فوری ضرورت ہے۔ صحت کی دیکھ بھال کے اداروں، محققین، معالجین، اور مریضوں کو صحت کی دیکھ بھال کے لیے اوپن سورس LLMs بنانے کے لیے عالمی سطح پر تعاون کرنا چاہیے۔ یہ نقطہ نظر، ٹریلین پیرامیٹر کنسورشیم کی طرح، کمپیوٹیشنل، مالی وسائل، اور مہارت کو جمع کرنے کی اجازت دے گا۔















