
ปัญญาประดิษฐ์
การแพร่กระจายที่เสถียรสามารถพัฒนาเป็นผลิตภัณฑ์ผู้บริโภคหลักได้อย่างไร

กระแทกแดกดัน การแพร่กระจายที่เสถียรn กรอบการสังเคราะห์ภาพด้วย AI แบบใหม่ที่ทำให้โลกต้องตกตะลึง ไม่มีทั้งความเสถียรหรือ 'กระจัดกระจาย' อย่างน้อยที่สุดก็ยังไม่ใช่
ความสามารถทั้งหมดของระบบกระจายอยู่ทั่วหลากหลายข้อเสนอที่เปลี่ยนแปลงตลอดเวลาจากนักพัฒนาจำนวนหนึ่งที่แลกเปลี่ยนข้อมูลและทฤษฎีล่าสุดอย่างเมามันในการสนทนาที่หลากหลายบน Discord และขั้นตอนการติดตั้งส่วนใหญ่สำหรับแพ็คเกจที่พวกเขากำลังสร้างหรือ การปรับเปลี่ยนอยู่ไกลจาก 'ปลั๊กแอนด์เพลย์'
แต่พวกเขามักจะต้องการบรรทัดคำสั่งหรือ ขับเคลื่อนด้วย BAT การติดตั้งผ่าน GIT, Conda, Python, Miniconda และเฟรมเวิร์กการพัฒนาขั้นสูงอื่น ๆ - แพ็คเกจซอฟต์แวร์ซึ่งหาได้ยากในหมู่ผู้บริโภคทั่วไปที่มีการติดตั้ง มักจะถูกตั้งค่าสถานะ โดยผู้จำหน่ายโปรแกรมป้องกันไวรัสและโปรแกรมป้องกันมัลแวร์เพื่อเป็นหลักฐานของระบบโฮสต์ที่ถูกบุกรุก

สเตจที่เลือกเพียงเล็กน้อยในถุงมือที่การติดตั้ง Stable Diffusion แบบมาตรฐานต้องการในปัจจุบัน การแจกจ่ายจำนวนมากยังต้องการเวอร์ชันเฉพาะของ Python ซึ่งอาจขัดแย้งกับเวอร์ชันที่มีอยู่แล้วซึ่งติดตั้งบนเครื่องของผู้ใช้ – แม้ว่าสิ่งนี้สามารถหลีกเลี่ยงได้ด้วยการติดตั้งบน Docker และในระดับหนึ่งผ่านการใช้สภาพแวดล้อม Conda
เธรดข้อความในชุมชน Stable Diffusion ของ SFW และ NSFW นั้นเต็มไปด้วยเคล็ดลับและลูกเล่นที่เกี่ยวข้องกับการแฮ็กสคริปต์ Python และการติดตั้งมาตรฐาน เพื่อให้สามารถใช้งานฟังก์ชันการทำงานที่ได้รับการปรับปรุง หรือเพื่อแก้ไขข้อผิดพลาดในการพึ่งพาบ่อยครั้ง และปัญหาอื่นๆ อีกมากมาย
สิ่งนี้ทำให้ผู้บริโภคทั่วไปสนใจ สร้างภาพที่น่าทึ่ง จากข้อความแจ้ง ค่อนข้างจะเป็นไปตามความเมตตาของอินเทอร์เฟซเว็บ API ที่สร้างรายได้ซึ่งมีจำนวนเพิ่มขึ้น ซึ่งส่วนใหญ่มีการสร้างรูปภาพฟรีจำนวนน้อยที่สุดก่อนที่จะต้องซื้อโทเค็น
นอกจากนี้ ข้อเสนอบนเว็บเกือบทั้งหมดเหล่านี้ปฏิเสธที่จะส่งออกเนื้อหา NSFW (ซึ่งส่วนใหญ่อาจเกี่ยวข้องกับหัวข้อที่ไม่ใช่ภาพอนาจารที่เป็นที่สนใจทั่วไป เช่น 'สงคราม') ซึ่งทำให้ Stable Diffusion แตกต่างจากบริการ DALL-E ของ OpenAI 2.
'Photoshop สำหรับการแพร่กระจายที่เสถียร'
ยั่วเย้าด้วยภาพที่สวยงาม มีชีวิตชีวา หรือภาพอื่น ๆ ที่ติดแฮชแท็ก #stablediffusion ของ Twitter ทุกวัน สิ่งที่คนทั้งโลกกำลังรอคอยก็คือ 'Photoshop สำหรับการแพร่กระจายที่เสถียร' – แอปพลิเคชันที่ติดตั้งข้ามแพลตฟอร์มได้ซึ่งรวมเอาฟังก์ชันการทำงานที่ดีที่สุดและทรงพลังที่สุดของสถาปัตยกรรม Stability.ai รวมถึงนวัตกรรมอันชาญฉลาดต่างๆ ของชุมชนการพัฒนา SD ที่เกิดขึ้นใหม่ โดยไม่มีหน้าต่าง CLI แบบลอยตัว การติดตั้งและอัปเดตที่คลุมเครือและเปลี่ยนแปลงตลอดเวลา กิจวัตรหรือคุณสมบัติที่ขาดหายไป
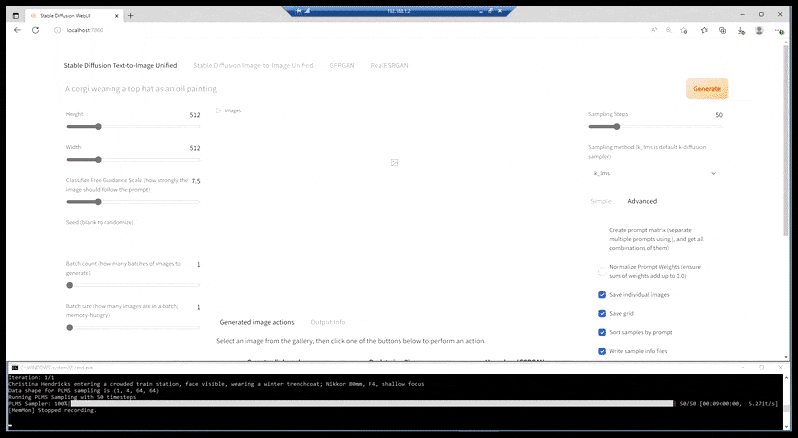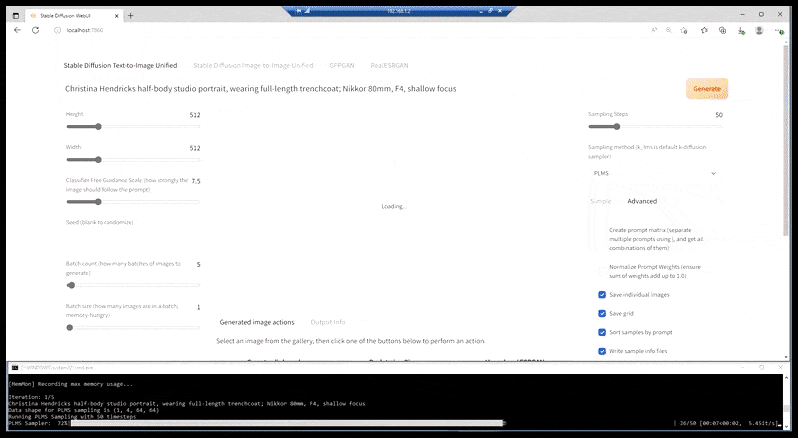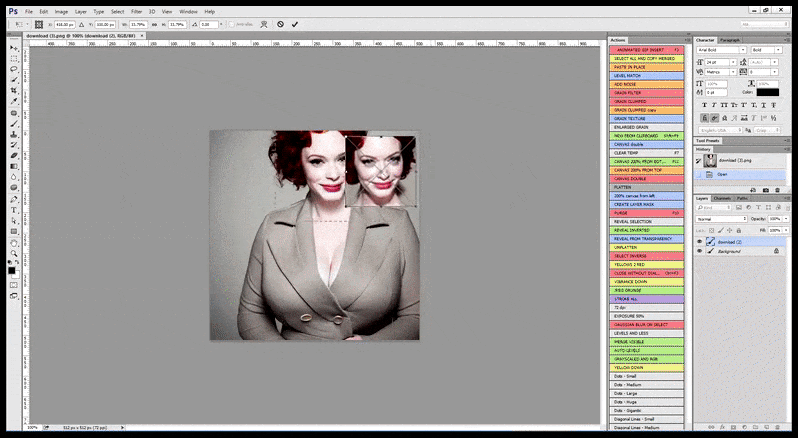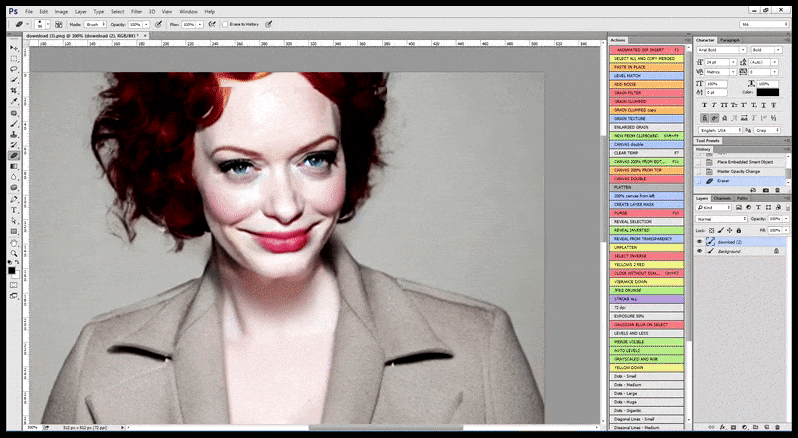
สิ่งที่เรามีอยู่ในขณะนี้ในการติดตั้งที่มีความสามารถส่วนใหญ่คือหน้าเว็บที่สวยงามหลากหลายซึ่งคร่อมด้วยหน้าต่างบรรทัดคำสั่งที่แยกส่วน และ URL ของมันคือพอร์ต localhost:

คล้ายกับแอปการสังเคราะห์ที่ขับเคลื่อนด้วย CLI เช่น FaceSwap และ DeepFaceLab ที่ใช้ BAT เป็นหลัก การติดตั้ง 'prepack' ของ Stable Diffusion จะแสดงรากของบรรทัดคำสั่ง พร้อมอินเทอร์เฟซที่เข้าถึงได้ผ่านพอร์ต localhost (ดูด้านบนสุดของภาพด้านบน) ซึ่งสื่อสาร ด้วยฟังก์ชันการแพร่กระจายที่เสถียรบนพื้นฐาน CLI
ไม่ต้องสงสัยเลยว่ามีแอปพลิเคชั่นที่มีประสิทธิภาพมากขึ้น มีแอปพลิเคชันอินทิกรัลที่ใช้ Patreon อยู่แล้วหลายตัวที่สามารถดาวน์โหลดได้ เช่น ก. ความเสี่ยง และ เอ็น.เอ็ม.เค (ดูภาพด้านล่าง) – แต่ยังไม่มีคุณลักษณะใดที่ผสานรวมฟีเจอร์เต็มรูปแบบที่การใช้งาน Stable Diffusion ขั้นสูงและเข้าถึงได้น้อยกว่าบางส่วนสามารถนำเสนอได้

แพ็คเกจเริ่มต้นของ Stable Diffusion ที่ใช้ Patreon เป็นแบบ 'app-ized' เล็กน้อย NMKD's เป็นรายแรกที่รวมเอาต์พุต CLI เข้ากับ GUI โดยตรง
มาดูกันว่าในที่สุดแล้วการใช้งานโอเพ่นซอร์สที่น่าอัศจรรย์นี้อาจมีลักษณะอย่างไร และอาจเผชิญกับความท้าทายอะไรบ้าง
ข้อพิจารณาทางกฎหมายสำหรับแอปพลิเคชันการแพร่กระจายที่เสถียรเชิงพาณิชย์ที่ได้รับทุนเต็มจำนวน
ปัจจัย NSFW
ซอร์สโค้ด Stable Diffusion ได้รับการเผยแพร่ภายใต้ ใบอนุญาตที่อนุญาตอย่างมาก ซึ่งไม่ได้ห้ามการใช้งานซ้ำในเชิงพาณิชย์และผลงานที่ได้รับซึ่งสร้างขึ้นอย่างกว้างขวางจากซอร์สโค้ด
นอกเหนือจากการสร้าง Stable Diffusion ที่สร้างจาก Patreon ที่กล่าวมาข้างต้นและจำนวนที่เพิ่มขึ้นเรื่อย ๆ รวมถึงปลั๊กอินแอปพลิเคชันจำนวนมากที่ได้รับการพัฒนาสำหรับ มะเดื่อ, Krita, Photoshop, GIMPและ เครื่องปั่น (ในหมู่อื่น ๆ ) ไม่มี ในทางปฏิบัติ เหตุผลที่บริษัทพัฒนาซอฟต์แวร์ที่มีทุนสนับสนุนดีไม่สามารถพัฒนาแอปพลิเคชัน Stable Diffusion ที่ซับซ้อนและมีความสามารถมากกว่านี้ได้ จากมุมมองของตลาด มีเหตุผลทุกประการที่จะเชื่อได้ว่าโครงการริเริ่มดังกล่าวหลายโครงการกำลังดำเนินไปได้ด้วยดี
ในที่นี้ ความพยายามดังกล่าวเผชิญกับภาวะที่กลืนไม่เข้าคายไม่ออกในทันทีว่า เช่นเดียวกับ API เว็บส่วนใหญ่สำหรับ Stable Diffusion หรือไม่ แอปพลิเคชันจะอนุญาตให้ใช้ตัวกรอง NSFW ดั้งเดิมของ Stable Diffusion (a ส่วนของรหัส) ที่จะถูกปิด
'ฝัง' สวิตช์ NSFW
แม้ว่าใบอนุญาตโอเพ่นซอร์สของ Stability.ai สำหรับ Stable Diffusion จะมีรายการแอปพลิเคชันที่สามารถตีความได้กว้างๆ ซึ่งอาจ ไม่ นำไปใช้ (เนื้อหารวมถึง เนื้อหาลามกอนาจาร และ deepfakes) วิธีเดียวที่ผู้ขายสามารถห้ามการใช้งานดังกล่าวได้อย่างมีประสิทธิภาพคือการรวบรวมตัวกรอง NSFW ลงในไฟล์ปฏิบัติการทึบแสงแทนพารามิเตอร์ในไฟล์ Python หรือบังคับใช้การเปรียบเทียบการตรวจสอบในไฟล์ Python หรือ DLL ที่มีคำสั่ง NSFW ดังนั้นการแสดงผลจะไม่เกิดขึ้นหากผู้ใช้เปลี่ยนการตั้งค่านี้
สิ่งนี้จะทำให้แอปพลิเคชันสมมุติ 'ทำหมัน' ในลักษณะเดียวกับที่ DALL-E 2 ในปัจจุบันคือทำให้ความน่าดึงดูดใจในเชิงพาณิชย์ลดลง นอกจากนี้ คอมโพเนนต์เหล่านี้ในเวอร์ชัน 'doctored' ที่คอมไพล์แล้วอย่างหลีกเลี่ยงไม่ได้ (ไม่ว่าจะเป็นองค์ประกอบรันไทม์ Python ดั้งเดิมหรือไฟล์ DLL ที่คอมไพล์แล้ว ดังที่ใช้ในเครื่องมือปรับปรุงภาพ AI รุ่น Topaz) มีแนวโน้มที่จะเกิดขึ้นในชุมชนทอร์เรนต์/แฮ็กเพื่อปลดล็อกข้อจำกัดดังกล่าว เพียงแค่เปลี่ยนองค์ประกอบที่กีดขวาง และลบล้างข้อกำหนดการตรวจสอบใดๆ
ในท้ายที่สุด ผู้จำหน่ายอาจเลือกที่จะทำซ้ำคำเตือนของ Stability.ai เพื่อป้องกันไม่ให้ใช้งานในทางที่ผิด ซึ่งเป็นลักษณะของการเรียกใช้ครั้งแรกของการกระจาย Stable Diffusion จำนวนมากในปัจจุบัน
อย่างไรก็ตาม นักพัฒนาซอฟต์แวร์โอเพ่นซอร์สรายเล็กที่ใช้คำปฏิเสธอย่างไม่เป็นทางการในลักษณะนี้แทบไม่ต้องสูญเสียเมื่อเทียบกับบริษัทซอฟต์แวร์ที่ลงทุนทั้งเงินและเวลาจำนวนมากในการทำให้ Stable Diffusion มีคุณสมบัติครบถ้วนและเข้าถึงได้ ซึ่งเชิญชวนให้พิจารณาอย่างลึกซึ้งยิ่งขึ้น
ความรับผิดของ Deepfake
อย่างที่เรามี เมื่อเร็ว ๆ นี้ตั้งข้อสังเกตฐานข้อมูลความงามของ LAION ซึ่งเป็นส่วนหนึ่งของรูปภาพจำนวน 4.2 พันล้านภาพที่ได้รับการฝึกอบรมโมเดลที่กำลังดำเนินอยู่ของ Stable Diffusion นั้น มีรูปภาพของคนดังจำนวนมาก ซึ่งทำให้ผู้ใช้สามารถสร้างสรรค์ภาพแบบ Deepfake ได้อย่างมีประสิทธิภาพ รวมถึงภาพโป๊ของคนดังแบบ Deepfake

จากบทความล่าสุดของเรา สี่ขั้นตอนของเจนนิเฟอร์ คอนเนลลีตลอดสี่ทศวรรษในอาชีพการงานของเธอ โดยอนุมานจาก Stable Diffusion
นี่เป็นประเด็นที่แยกจากกันและเป็นที่ถกเถียงกันมากกว่าการสร้างภาพอนาจาร 'นามธรรม' ทางกฎหมาย (ซึ่งปกติแล้ว) ซึ่งไม่ได้แสดงถึงบุคคลที่ 'มีตัวตนจริง' (แม้ว่าภาพดังกล่าวจะอนุมานจากภาพถ่ายจริงหลายภาพในสื่อการฝึกอบรมก็ตาม)
เนื่องจากรัฐและประเทศต่างๆ ของสหรัฐฯ กำลังพัฒนาหรือออกกฎหมายต่อต้านสื่อลามกอนาจารจำนวนมากขึ้น ความสามารถของ Stable Diffusion ในการสร้างภาพลามกอนาจารของคนดังอาจหมายความว่าแอปพลิเคชันเชิงพาณิชย์ที่ไม่ถูกเซ็นเซอร์ทั้งหมด (เช่น สามารถสร้างเนื้อหาลามกอนาจาร) อาจยังต้องการอยู่บ้าง ความสามารถในการกรองใบหน้าคนดังที่รับรู้
วิธีหนึ่งคือการจัดเตรียม 'บัญชีดำ' ในตัวของข้อกำหนดที่จะไม่ได้รับการยอมรับในพรอมต์ของผู้ใช้ ซึ่งเกี่ยวข้องกับชื่อคนดังและตัวละครสมมติที่อาจเกี่ยวข้องด้วย สันนิษฐานว่าการตั้งค่าดังกล่าวจะต้องจัดทำขึ้นในภาษาต่างๆ มากกว่าภาษาอังกฤษ เนื่องจากข้อมูลต้นทางมีภาษาอื่นๆ อีกวิธีหนึ่งคือรวมระบบการจดจำคนดังเช่นที่พัฒนาโดย Clarifai
ผู้ผลิตซอฟต์แวร์อาจจำเป็นต้องรวมวิธีการดังกล่าว ซึ่งอาจปิดในตอนแรก เนื่องจากอาจช่วยป้องกันแอปพลิเคชัน Stable Diffusion แบบสแตนด์อโลนเต็มรูปแบบไม่ให้สร้างใบหน้าคนดัง ซึ่งอยู่ระหว่างรอกฎหมายใหม่ที่อาจทำให้การทำงานดังกล่าวผิดกฎหมาย
อย่างไรก็ตาม เป็นอีกครั้งที่ฟังก์ชันดังกล่าวสามารถถูกแยกส่วนและย้อนกลับโดยผู้มีส่วนได้ส่วนเสียอย่างหลีกเลี่ยงไม่ได้ อย่างไรก็ตาม ในเหตุการณ์นั้น ผู้ผลิตซอฟต์แวร์สามารถอ้างว่านี่เป็นการก่อกวนที่ไม่ได้รับอนุญาตอย่างมีประสิทธิภาพ ตราบใดที่การทำวิศวกรรมย้อนกลับประเภทนี้ไม่ได้ทำได้ง่ายเกินไป
คุณสมบัติที่สามารถรวมได้
ฟังก์ชันการทำงานหลักในการกระจายของ Stable Diffusion นั้นคาดว่าจะมาจากแอปพลิเคชันเชิงพาณิชย์ที่ได้รับทุนสนับสนุนอย่างดี ซึ่งรวมถึงความสามารถในการใช้ข้อความแจ้งเพื่อสร้างรูปภาพที่เกี่ยวข้อง (ข้อความเป็นภาพ); ความสามารถในการใช้ภาพร่างหรือรูปภาพอื่นเป็นแนวทางสำหรับรูปภาพที่สร้างขึ้นใหม่ (ภาพต่อภาพ); วิธีที่จะปรับวิธีการ 'จินตนาการ' ที่ระบบได้รับคำสั่งให้เป็น; วิธีการแลกเปลี่ยนเวลาในการเรนเดอร์กับคุณภาพ และ 'พื้นฐาน' อื่นๆ เช่น การเก็บถาวรรูปภาพ/พรอมต์อัตโนมัติที่เป็นตัวเลือก และการเพิ่มสเกลทางเลือกที่ทำเป็นประจำผ่าน จริงESRGANและอย่างน้อย 'การแก้ไขใบหน้า' ขั้นพื้นฐานด้วย จีเอฟพีกัน or รหัสอดีต.
นั่นเป็น 'การติดตั้งวานิลลา' ที่ค่อนข้างสวย มาดูคุณสมบัติขั้นสูงบางอย่างที่กำลังพัฒนาหรือขยายอยู่ในขณะนี้ ซึ่งอาจรวมอยู่ในแอปพลิเคชัน Stable Diffusion 'ดั้งเดิม' เต็มรูปแบบ
การแช่แข็งสุ่ม
แม้ว่าคุณจะ นำเมล็ดกลับมาใช้ใหม่ จากการเรนเดอร์ที่ประสบความสำเร็จก่อนหน้านี้ เป็นเรื่องยากมากที่จะทำให้ Stable Diffusion ทำการแปลงซ้ำอย่างแม่นยำถ้า ส่วนใดส่วนหนึ่ง ของพรอมต์หรืออิมเมจต้นฉบับ (หรือทั้งสองอย่าง) เปลี่ยนไปสำหรับการเรนเดอร์ที่ตามมา
นี่เป็นปัญหาหากคุณต้องการใช้ เอ็บซินธ์ เพื่อกำหนดการเปลี่ยนแปลงของ Stable Diffusion ลงบนวิดีโอจริงในลักษณะที่สอดคล้องกันทางโลก แม้ว่าเทคนิคนี้จะมีประสิทธิภาพมากสำหรับการถ่ายภาพส่วนหัวและไหล่ที่เรียบง่าย:

การเคลื่อนไหวที่จำกัดสามารถทำให้ EbSynth เป็นสื่อที่มีประสิทธิภาพในการเปลี่ยนการแปลง Stable Diffusion ให้เป็นวิดีโอที่สมจริง ที่มา: https://streamable.com/u0pgzd
EbSynth ทำงานโดยการคาดคะเนคีย์เฟรมที่ 'แก้ไข' เพียงเล็กน้อยลงในวิดีโอที่ได้รับการเรนเดอร์เป็นชุดไฟล์ภาพ (และสามารถนำมาประกอบกลับเป็นวิดีโอได้ในภายหลัง)

ในตัวอย่างนี้จากไซต์ EbSynth เฟรมจำนวนหนึ่งจากวิดีโอได้รับการวาดอย่างมีศิลปะ EbSynth ใช้เฟรมเหล่านี้เป็นแนวทางสไตล์เพื่อปรับเปลี่ยนวิดีโอทั้งหมดในลักษณะเดียวกันเพื่อให้ตรงกับสไตล์ที่ทาสี ที่มา: https://www.youtube.com/embed/eghGQtQhY38
ในตัวอย่างด้านล่างซึ่งแทบไม่มีการเคลื่อนไหวใดๆ จากครูสอนโยคะผมบลอนด์ (ตัวจริง) ทางด้านซ้าย Stable Diffusion ยังคงมีปัญหาในการรักษาใบหน้าที่สอดคล้องกัน เนื่องจากภาพทั้งสามที่ถูกแปลงเป็น 'คีย์เฟรม' ไม่เหมือนกันโดยสิ้นเชิง แม้ว่าพวกมันทั้งหมดจะแบ่งปันเมล็ดพันธุ์ที่เป็นตัวเลขเดียวกันก็ตาม

ที่นี่ แม้จะมีพรอมต์และเมล็ดเหมือนกันในการแปลงทั้งสาม และมีการเปลี่ยนแปลงน้อยมากระหว่างเฟรมต้นทาง กล้ามเนื้อของร่างกายมีขนาดและรูปร่างแตกต่างกันไป แต่ที่สำคัญกว่านั้น ใบหน้าไม่สอดคล้องกัน ซึ่งเป็นอุปสรรคต่อความสม่ำเสมอทางโลกในการเรนเดอร์ EbSynth ที่อาจเกิดขึ้น
แม้ว่าวิดีโอ SD/EbSynth ด้านล่างจะสร้างสรรค์มาก โดยนิ้วของผู้ใช้ถูกเปลี่ยนให้เป็นขากางเกงและเป็ด (ตามลำดับ) ความไม่สอดคล้องกันของกางเกงทำให้เกิดปัญหาที่ Stable Diffusion มีในการรักษาความสม่ำเสมอในคีย์เฟรมต่างๆ แม้ว่าเฟรมต้นทางจะคล้ายกันและเมล็ดมีความสอดคล้องกัน

นิ้วของมนุษย์กลายเป็นคนเดินได้และเป็ด ผ่าน Stable Diffusion และ EbSynth ที่มา: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
ผู้ใช้ที่สร้างวิดีโอนี้ แสดงความคิดเห็น ว่าการแปลงรูปเป็ด ซึ่งว่ากันว่ามีประสิทธิภาพมากกว่าในทั้งสองแบบ หากโดดเด่นน้อยกว่าและไม่เหมือนใคร ต้องใช้คีย์เฟรมแปลงเดียวเพียงอันเดียว ในขณะที่จำเป็นต้องแสดงภาพการแพร่กระจายที่เสถียร 50 ภาพเพื่อสร้างกางเกงเดิน ซึ่งแสดงชั่วขณะมากขึ้น ความไม่ลงรอยกัน ผู้ใช้ยังสังเกตว่าต้องใช้ความพยายาม 50 ครั้งเพื่อให้ได้คีย์เฟรมแต่ละรายการจาก XNUMX คีย์เฟรมที่สอดคล้องกัน
ดังนั้นจึงเป็นประโยชน์อย่างยิ่งสำหรับแอปพลิเคชัน Stable Diffusion ที่ครอบคลุมอย่างแท้จริง เพื่อให้ฟังก์ชันการทำงานที่รักษาลักษณะต่างๆ ในขอบเขตสูงสุดทั่วทั้งคีย์เฟรม
ความเป็นไปได้ประการหนึ่งคือแอปพลิเคชันอนุญาตให้ผู้ใช้ 'หยุด' การเข้ารหัสสุ่มสำหรับการแปลงในแต่ละเฟรม ซึ่งปัจจุบันสามารถทำได้โดยการแก้ไขซอร์สโค้ดด้วยตนเองเท่านั้น ดังตัวอย่างด้านล่าง วิธีนี้ช่วยในเรื่องความสอดคล้องทางโลกแม้ว่าจะไม่สามารถแก้ปัญหาได้อย่างแน่นอน:

ผู้ใช้ Reddit รายหนึ่งแปลงภาพวิดีโอจากเว็บแคมของตัวเองให้เป็นบุคคลที่มีชื่อเสียงต่างๆ โดยไม่เพียงแค่คงเมล็ดพันธุ์ไว้ (ซึ่งการใช้งาน Stable Diffusion สามารถทำได้) แต่ด้วยการทำให้มั่นใจว่าพารามิเตอร์ stochastic_encode() เหมือนกันในการแปลงแต่ละครั้ง สิ่งนี้ทำได้โดยการแก้ไขรหัส แต่สามารถกลายเป็นสวิตช์ที่ผู้ใช้สามารถเข้าถึงได้ง่าย อย่างไรก็ตาม เห็นได้ชัดว่ามันไม่ได้แก้ปัญหาทางโลกทั้งหมด ที่มา: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
การผกผันข้อความบนคลาวด์
ทางออกที่ดีกว่าสำหรับการทำให้ตัวละครและวัตถุมีความสอดคล้องกันทางโลกคือการ 'ทำให้' พวกมันกลายเป็น การผกผันข้อความ – ไฟล์ขนาด 5KB ที่สามารถฝึกฝนได้ภายในเวลาไม่กี่ชั่วโมงโดยอ้างอิงจากรูปภาพที่มีคำอธิบายประกอบเพียงห้าภาพ ซึ่งจากนั้นสามารถดึงข้อมูลพิเศษออกมา '*' พร้อมท์ เปิดใช้งาน ตัวอย่างเช่น การปรากฏตัวอย่างต่อเนื่องของตัวละครใหม่เพื่อรวมไว้ในเรื่องเล่า

รูปภาพที่เชื่อมโยงกับแท็กที่เกี่ยวข้องสามารถแปลงเป็นเอนทิตีที่ไม่ต่อเนื่องได้ผ่าน Textual Inversion และเรียกใช้โดยไม่คลุมเครือ และในบริบทและรูปแบบที่ถูกต้องด้วยคำโทเค็นพิเศษ ที่มา: https://huggingface.co/docs/diffusers/training/text_inversion
Textual Inversions เป็นไฟล์เสริมของโมเดลขนาดใหญ่มากและได้รับการฝึกฝนอย่างเต็มที่ซึ่ง Stable Diffusion ใช้ และ 'แอบสตรีม' เข้าสู่กระบวนการกระตุ้น/กระตุ้นอย่างมีประสิทธิภาพ เพื่อให้พวกเขาสามารถ มีส่วนร่วม ในฉากที่ได้มาจากโมเดล และได้รับประโยชน์จากฐานข้อมูลขนาดใหญ่ของโมเดลที่มีความรู้เกี่ยวกับวัตถุ สไตล์ สภาพแวดล้อม และการโต้ตอบ
อย่างไรก็ตาม แม้ว่า Textual Inversion จะใช้เวลาฝึกไม่นาน แต่ก็ต้องใช้ VRAM ในปริมาณที่สูง ตามแนวทางปัจจุบันที่หลากหลายอยู่ระหว่าง 12, 20 และ 40GB
เนื่องจากผู้ใช้ทั่วไปส่วนใหญ่ไม่น่าจะมีพลัง GPU มากขนาดนั้น บริการคลาวด์จึงเกิดขึ้นแล้วที่จะจัดการกับการทำงาน รวมถึงเวอร์ชัน Hugging Face แม้ว่าจะมี การใช้งาน Google Colab ที่สามารถสร้างข้อความผกผันสำหรับการแพร่กระจายที่เสถียร VRAM ที่จำเป็นและข้อกำหนดด้านเวลาอาจทำให้สิ่งเหล่านี้ท้าทายสำหรับผู้ใช้ Colab ระดับฟรี
สำหรับแอปพลิเคชัน Stable Diffusion (ติดตั้งแล้ว) ที่มีศักยภาพเต็มเปี่ยมและได้รับการลงทุนอย่างดี การส่งงานหนักนี้ไปยังเซิร์ฟเวอร์คลาวด์ของบริษัทดูเหมือนจะเป็นกลยุทธ์การสร้างรายได้ที่ชัดเจน (สมมติว่าแอปพลิเคชัน Stable Diffusion ที่มีต้นทุนต่ำหรือไม่มีค่าใช้จ่ายถูกแทรกซึมไปด้วย ฟังก์ชันฟรี ซึ่งดูเหมือนว่าเป็นไปได้ในหลายๆ แอปพลิเคชันที่จะเกิดจากเทคโนโลยีนี้ในอีก 6-9 เดือนข้างหน้า)
นอกจากนี้ กระบวนการที่ค่อนข้างซับซ้อนในการใส่คำอธิบายประกอบและจัดรูปแบบรูปภาพและข้อความที่ส่งมาอาจได้รับประโยชน์จากการทำงานอัตโนมัติในสภาพแวดล้อมแบบบูรณาการ ศักยภาพของ 'ปัจจัยเสพติด' ในการสร้างองค์ประกอบที่ไม่เหมือนใครที่สามารถสำรวจและโต้ตอบกับโลกอันกว้างใหญ่ของ Stable Diffusion ดูเหมือนจะเป็นสิ่งที่ต้องบังคับ ทั้งสำหรับผู้ที่ชื่นชอบทั่วไปและผู้ใช้ที่อายุน้อย
การชั่งน้ำหนักพร้อมท์ที่หลากหลาย
มีการใช้งานปัจจุบันหลายอย่างที่อนุญาตให้ผู้ใช้กำหนดเน้นมากขึ้นในส่วนของข้อความแจ้งแบบยาว แต่เครื่องมือจะแตกต่างกันค่อนข้างมากระหว่างสิ่งเหล่านี้ และมักจะเกะกะหรือใช้งานไม่ได้
Stable Diffusion fork ที่ได้รับความนิยมอย่างมาก โดย AUTOMATIC1111ตัวอย่างเช่น สามารถลดหรือเพิ่มค่าของคำพร้อมท์โดยใส่ไว้ในวงเล็บเดี่ยวหรือหลายอัน (สำหรับการเน้นเสียงต่ำ) หรือวงเล็บเหลี่ยมเพื่อเน้นเป็นพิเศษ

วงเล็บเหลี่ยมและ/หรือวงเล็บสามารถเปลี่ยนอาหารเช้าของคุณให้เป็นน้ำหนักพร้อมท์การกระจายแบบเสถียรเวอร์ชันนี้ แต่ก็ไม่ทางใดก็ทางหนึ่งมันก็เป็นฝันร้ายของคอเลสเตอรอล
การทำซ้ำแบบอื่นๆ ของ Stable Diffusion จะใช้เครื่องหมายอัศเจรีย์เพื่อเน้น ในขณะที่แบบอเนกประสงค์ที่สุดช่วยให้ผู้ใช้สามารถกำหนดน้ำหนักให้กับแต่ละคำในพรอมต์ผ่าน GUI
ระบบควรอนุญาตด้วย น้ำหนักพรอมต์เชิงลบ - ไม่ใช่แค่สำหรับ แฟนสยองขวัญแต่เนื่องจากอาจมีความลึกลับที่น่าตกใจน้อยกว่าและน่าจรรโลงใจในพื้นที่ซ่อนเร้นของ Stable Diffusion เกินกว่าที่การใช้ภาษาอย่างจำกัดของเราจะเรียกขึ้นมาได้
วาดภาพระบายสี
ไม่นานหลังจากการโอเพนซอร์สที่น่าตื่นเต้นของ Stable Diffusion OpenAI ก็พยายามอย่างไร้ประโยชน์เพื่อยึด DALL-E 2 บางส่วนกลับคืนมาโดย ประกาศ 'outpainting' ซึ่งช่วยให้ผู้ใช้สามารถขยายภาพเกินขอบเขตด้วยตรรกะเชิงความหมายและการเชื่อมโยงกันของภาพ
โดยธรรมชาติแล้วตั้งแต่นั้นเป็นต้นมา การดำเนินการ ในรูปแบบต่างๆ สำหรับ Stable Diffusion รวมทั้ง ในกฤติยาและควรรวมอยู่ใน Stable Diffusion เวอร์ชัน Photoshop ที่ครอบคลุมอย่างแน่นอน
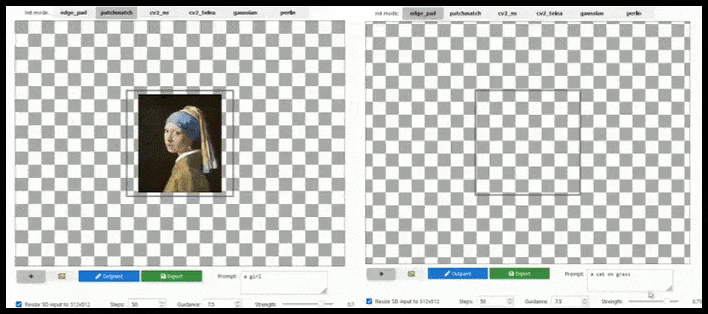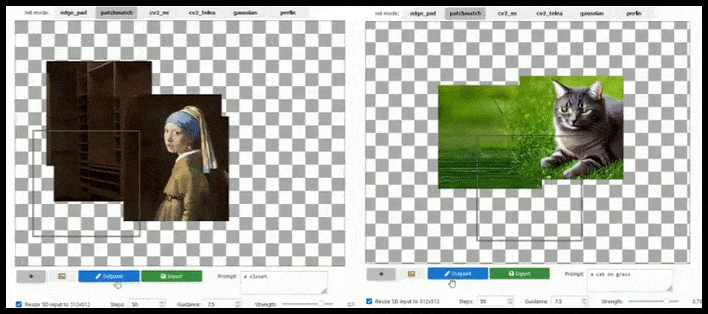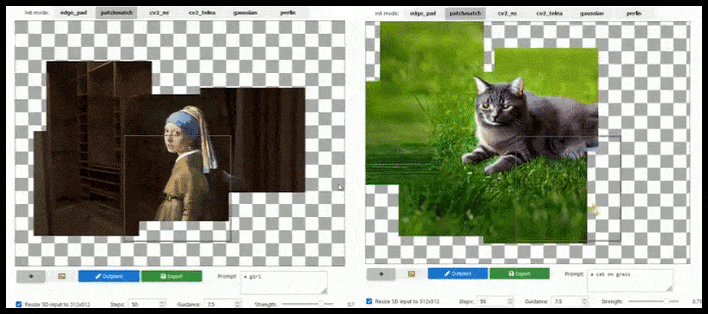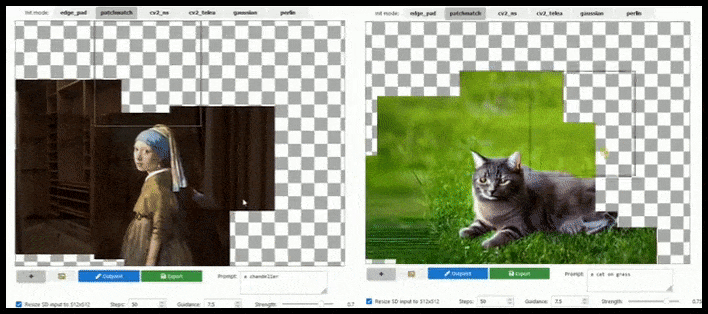
การต่อขยายตามไทล์สามารถขยายการเรนเดอร์มาตรฐาน 512×512 ได้เกือบไม่จำกัด ตราบใดที่ข้อความแจ้ง รูปภาพที่มีอยู่ และตรรกะเชิงความหมายอนุญาต ที่มา: https://github.com/lkwq007/stablediffusion-infinity
เนื่องจาก Stable Diffusion ได้รับการฝึกบนภาพขนาด 512x512px (และด้วยเหตุผลอื่นๆ อีกหลายประการ) จึงมักตัดส่วนหัว (หรือส่วนอื่นๆ ของร่างกายที่จำเป็น) ออกจากตัวแบบ แม้ว่าจะระบุอย่างชัดเจนว่า 'เน้นส่วนหัว' ฯลฯ ก็ตาม

ตัวอย่างทั่วไปของการแพร่กระจายที่เสถียร 'การตัดหัว'; แต่การลงสีอาจทำให้จอร์จกลับมาอยู่ในภาพได้
การใช้ภาพระบายสีประเภทใด ๆ ที่แสดงในภาพเคลื่อนไหวด้านบน (ซึ่งอิงตามไลบรารี Unix เท่านั้น แต่ควรสามารถจำลองแบบบน Windows ได้) ควรเป็นเครื่องมือในการแก้ไขด้วยคลิกเดียว/พร้อมท์สำหรับสิ่งนี้
ปัจจุบัน ผู้ใช้จำนวนหนึ่งขยายผ้าใบของการแสดงภาพที่ 'หัวขาด' ขึ้นไป เติมพื้นที่ส่วนหัวอย่างคร่าว ๆ และใช้ img2img เพื่อทำให้การเรนเดอร์ไม่เรียบร้อย
การกำบังอย่างมีประสิทธิภาพที่เข้าใจบริบท
การกำบัง อาจเป็นเรื่องที่พลาดไม่ได้อย่างมากใน Stable Diffusion ทั้งนี้ขึ้นอยู่กับทางแยกหรือเวอร์ชันที่เป็นปัญหา บ่อยครั้งที่สามารถวาดมาสก์เหนียวๆ ได้ พื้นที่ที่ระบุจะลงเอยด้วยเนื้อหาที่ไม่ได้คำนึงถึงบริบททั้งหมดของรูปภาพ
มีอยู่ครั้งหนึ่ง ฉันได้ปกปิดกระจกตาของภาพใบหน้าและให้ข้อมูลพร้อมรับคำ 'ดวงตาสีฟ้า' ในฐานะที่เป็นหน้ากากทาสี – เพียงเพื่อจะพบว่าฉันกำลังมองผ่านดวงตาของมนุษย์ที่ถูกตัดออกสองข้างไปยังภาพระยะไกลของหมาป่าที่ดูพิสดาร ฉันเดาว่าฉันโชคดีที่ไม่ใช่แฟรงก์ ซินาตร้า
นอกจากนี้ยังสามารถแก้ไขความหมายได้ด้วย การระบุเสียงรบกวน ที่สร้างภาพตั้งแต่แรก ซึ่งช่วยให้ผู้ใช้สามารถระบุองค์ประกอบโครงสร้างเฉพาะในการเรนเดอร์โดยไม่รบกวนส่วนที่เหลือของภาพ:

การเปลี่ยนองค์ประกอบหนึ่งอย่างในภาพโดยไม่ใช้การปิดบังแบบดั้งเดิมและไม่ต้องแก้ไขเนื้อหาที่อยู่ติดกัน โดยระบุจุดรบกวนที่เป็นจุดกำเนิดของภาพก่อน และระบุส่วนต่าง ๆ ที่ทำให้เกิดพื้นที่เป้าหมาย ที่มา: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
วิธีนี้ขึ้นอยู่กับ ตัวอย่าง K-Diffusion.
ตัวกรองความหมายสำหรับคนโง่ทางสรีรวิทยา
ดังที่เราได้กล่าวไว้ก่อนหน้านี้ Stable Diffusion สามารถเพิ่มหรือลบแขนขาได้บ่อยครั้ง สาเหตุหลักมาจากปัญหาด้านข้อมูลและข้อบกพร่องในคำอธิบายประกอบที่มาพร้อมกับรูปภาพที่ฝึกฝน

เช่นเดียวกับเด็กหลงทางที่แลบลิ้นออกมาในภาพถ่ายกลุ่มของโรงเรียน ความโหดร้ายทางชีวภาพของ Stable Diffusion มักไม่ชัดเจนในทันที และคุณอาจลง Instagram กับผลงานชิ้นเอก AI ล่าสุดของคุณก่อนที่คุณจะสังเกตเห็นมือที่เกินมาหรือแขนขาที่ละลาย
การแก้ไขข้อผิดพลาดประเภทนี้เป็นเรื่องยากมาก ซึ่งจะเป็นประโยชน์หากแอปพลิเคชัน Stable Diffusion ขนาดเต็มมีระบบการจดจำทางกายวิภาคบางประเภทที่ใช้การแบ่งกลุ่มความหมายเพื่อคำนวณว่ารูปภาพที่เข้ามามีข้อบกพร่องทางกายวิภาคขั้นรุนแรงหรือไม่ (ตามภาพด้านบน ) และทิ้งไปเพื่อเรนเดอร์ใหม่ก่อนที่จะนำเสนอต่อผู้ใช้

แน่นอน คุณอาจต้องการแสดงเทพธิดากาลีหรือด็อกเตอร์ออคโตปุส หรือแม้แต่ช่วยเหลือส่วนที่ไม่ได้รับผลกระทบของภาพที่พิการ ดังนั้นฟีเจอร์นี้ควรเป็นทางเลือกเสริม
หากผู้ใช้สามารถทนต่อการวัดและส่งข้อมูลทางไกลได้ สัญญาณผิดพลาดดังกล่าวอาจถูกส่งโดยไม่ระบุตัวตนในความพยายามร่วมกันของการเรียนรู้แบบสมาพันธ์ ซึ่งอาจช่วยโมเดลในอนาคตในการปรับปรุงความเข้าใจของพวกเขาเกี่ยวกับตรรกะทางกายวิภาค
การปรับปรุงใบหน้าอัตโนมัติโดยใช้ LAION
ตามที่ฉันระบุไว้ในของฉัน ภาพก่อนหน้า ในสามสิ่งที่ Stable Diffusion สามารถระบุได้ในอนาคต ไม่ควรปล่อยให้ GFPGAN เวอร์ชันใดๆ เพียงอย่างเดียวพยายาม 'ปรับปรุง' ใบหน้าที่เรนเดอร์ในการเรนเดอร์อินสแตนซ์แรก
'การปรับปรุง' ของ GFPGAN เป็นเรื่องทั่วไปอย่างมาก มักจะบั่นทอนเอกลักษณ์ของบุคคลที่ปรากฎ และดำเนินการเฉพาะบนใบหน้าที่มักจะแสดงผลได้ไม่ดี เนื่องจากไม่ได้รับเวลาในการประมวลผลหรือความสนใจมากไปกว่าส่วนอื่นๆ ของภาพ
ดังนั้นโปรแกรมมาตรฐานระดับมืออาชีพสำหรับ Stable Diffusion จึงควรสามารถจดจำใบหน้าได้ (ด้วยไลบรารี่มาตรฐานและค่อนข้างเบา เช่น YOLO) ใช้น้ำหนักเต็มของพลัง GPU ที่มีอยู่เพื่อแสดงผลซ้ำ และผสมผสานใบหน้าที่แก้ไขแล้วเข้ากับ การเรนเดอร์บริบทแบบเต็มต้นฉบับ หรือบันทึกแยกต่างหากสำหรับการจัดองค์ประกอบใหม่ด้วยตนเอง ขณะนี้เป็นการดำเนินการแบบ 'ลงมือทำ' พอสมควร
ในกรณีที่ Stable Diffusion ได้รับการฝึกอบรมเกี่ยวกับรูปภาพของคนดังในจำนวนที่เพียงพอ คุณสามารถเน้นความสามารถของ GPU ทั้งหมดไปที่การเรนเดอร์ใบหน้าของรูปภาพที่เรนเดอร์เท่านั้น ซึ่งโดยปกติแล้วจะเป็นการปรับปรุงที่โดดเด่น ซึ่งแตกต่างจาก GFPGAN ดึงข้อมูลจากข้อมูลที่อบรมโดย LAION แทนที่จะปรับพิกเซลที่แสดง
การค้นหา LAION ในแอป
เนื่องจากผู้ใช้เริ่มตระหนักว่าการค้นหาแนวคิด ผู้คน และธีมในฐานข้อมูลของ LAION สามารถพิสูจน์ได้ว่าสามารถช่วยในการใช้งาน Stable Diffusion ได้ดียิ่งขึ้น นักสำรวจ LAION ออนไลน์หลายคนได้ถูกสร้างขึ้น รวมถึง haveibeentrained.com

ฟังก์ชันการค้นหาที่ haveibeentrained.com ช่วยให้ผู้ใช้สำรวจรูปภาพที่ขับเคลื่อน Stable Diffusion และค้นพบว่าวัตถุ ผู้คน หรือแนวคิดที่พวกเขาอาจต้องการดึงออกมาจากระบบนั้นน่าจะได้รับการฝึกอบรมมาแล้วหรือไม่ ระบบดังกล่าวยังมีประโยชน์ในการค้นหาสิ่งที่อยู่ติดกัน เช่น วิธีจัดกลุ่มคนดัง หรือ 'แนวคิดถัดไป' ที่ต่อยอดจากแนวคิดปัจจุบัน ที่มา: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
แม้ว่าฐานข้อมูลบนเว็บดังกล่าวมักจะเปิดเผยแท็กบางส่วนที่มาพร้อมกับรูปภาพ แต่กระบวนการของ ลักษณะทั่วไป ที่เกิดขึ้นระหว่างการฝึกโมเดลหมายความว่าไม่น่าเป็นไปได้ที่รูปภาพใดๆ จะถูกเรียกใช้โดยใช้แท็กเป็นพรอมต์
นอกจากนี้ การกำจัด 'หยุดคำพูด' และการฝึกแยกคำและย่อคำในการประมวลผลภาษาธรรมชาติ หมายความว่าวลีจำนวนมากที่จัดแสดงถูกแยกออกหรือละเว้นก่อนที่จะได้รับการฝึกฝนให้เป็น Stable Diffusion
อย่างไรก็ตาม วิธีที่กลุ่มสุนทรียภาพเชื่อมโยงเข้าด้วยกันในอินเทอร์เฟซเหล่านี้สามารถสอนผู้ใช้ได้มากมายเกี่ยวกับตรรกะ (หรืออาจหมายถึง 'บุคลิกภาพ') ของ Stable Diffusion และพิสูจน์ได้ว่าเป็นผู้ช่วยในการผลิตภาพที่ดีขึ้น
สรุป
มีคุณลักษณะอื่นๆ อีกมากมายที่ฉันต้องการเห็นในการใช้งานเดสก์ท็อปแบบเนทีฟเต็มรูปแบบของ Stable Diffusion เช่น การวิเคราะห์รูปภาพตาม CLIP แบบดั้งเดิม ซึ่งย้อนกลับกระบวนการ Stable Diffusion มาตรฐาน และช่วยให้ผู้ใช้สามารถดึงวลีและคำที่ระบบ ย่อมเชื่อมโยงกับภาพต้นทางหรือการเรนเดอร์
นอกจากนี้ การปรับขนาดตามไทล์จริงก็เป็นส่วนเพิ่มเติมที่น่ายินดี เนื่องจาก ESRGAN เป็นเครื่องมือที่ค่อนข้างทื่อพอๆ กับ GFPGAN โชคดีที่มีแผนจะรวม txt2imhd การนำ GOBIG ไปใช้ทำให้สิ่งนี้เป็นจริงได้อย่างรวดเร็วทั่วทั้งดิสทริบิวชัน และดูเหมือนว่าจะเป็นตัวเลือกที่ชัดเจนสำหรับการทำซ้ำบนเดสก์ท็อป
คำขอยอดนิยมอื่นๆ บางคำขอจากชุมชน Discord ทำให้ฉันสนใจน้อยลง เช่น พจนานุกรมพร้อมท์ในตัวและรายชื่อศิลปินและสไตล์ที่เกี่ยวข้อง แม้ว่าสมุดบันทึกในแอปหรือคำศัพท์ที่ปรับแต่งได้ดูเหมือนจะเป็นส่วนเสริมที่สมเหตุสมผล
ในทำนองเดียวกัน ข้อจำกัดในปัจจุบันของแอนิเมชันที่เน้นมนุษย์เป็นศูนย์กลางใน Stable Diffusion แม้ว่าจะเริ่มโดย CogVideo และโปรเจ็กต์อื่นๆ มากมาย แต่ยังคงเกิดขึ้นอย่างไม่น่าเชื่อ และด้วยความเมตตาของการวิจัยต้นน้ำเกี่ยวกับยุคก่อนหน้าที่เกี่ยวข้องกับการเคลื่อนไหวของมนุษย์ที่แท้จริง
สำหรับตอนนี้ วิดีโอ Stable Diffusion นั้นเคร่งครัด ซึ่งทำให้เคลิบเคลิ้มแม้ว่าในอนาคตอันใกล้นี้อาจมีอนาคตที่สดใสกว่ามากในหุ่นกระบอก Deepfake ผ่าน EbSynth และการริเริ่มแปลงข้อความเป็นวิดีโออื่นๆ ที่ค่อนข้างใหม่ (และควรสังเกตว่าการขาดคนสังเคราะห์หรือ 'ดัดแปลง' ใน Runway's วิดีโอโปรโมตล่าสุด).
ฟังก์ชันที่มีประโยชน์อีกประการหนึ่งคือ Photoshop pass-through แบบโปร่งใส ซึ่งก่อตั้งมายาวนานในโปรแกรมแก้ไขพื้นผิวของ Cinema4D ท่ามกลางการใช้งานอื่นๆ ที่คล้ายคลึงกัน ด้วยสิ่งนี้ ผู้ใช้สามารถสับเปลี่ยนรูปภาพระหว่างแอปพลิเคชันต่างๆ ได้อย่างง่ายดาย และใช้แต่ละแอปพลิเคชันเพื่อทำการแปลงที่เหนือกว่า
สุดท้าย และบางทีอาจสำคัญที่สุด โปรแกรม Stable Diffusion บนเดสก์ท็อปเต็มรูปแบบไม่ควรเพียงแค่สามารถสลับไปมาระหว่างจุดตรวจสอบได้อย่างง่ายดาย (เช่น เวอร์ชันของโมเดลพื้นฐานที่ขับเคลื่อนระบบ) แต่ควรสามารถอัปเดต Textual Inversions แบบกำหนดเองที่ใช้งานได้ กับรุ่นที่วางจำหน่ายอย่างเป็นทางการก่อนหน้านี้ แต่อาจถูกทำลายโดยรุ่นที่ใหม่กว่า
แดกดัน องค์กรที่อยู่ในตำแหน่งที่ดีที่สุดในการสร้างเมทริกซ์เครื่องมือที่ทรงพลังและผสานรวมสำหรับ Stable Diffusion อย่าง Adobe ได้ร่วมมืออย่างแข็งแกร่งกับ การริเริ่มความถูกต้องของเนื้อหา อาจดูเหมือนเป็นการถอยหลังเข้าคลอง PR ที่ผิดพลาดสำหรับบริษัท นอกเสียจากว่าจะเป็นการขัดขวางพลังการกำเนิดของ Stable Diffusion อย่างละเอียดถี่ถ้วนเหมือนกับที่ OpenAI ทำกับ DALL-E 2 และวางตำแหน่งให้เป็นวิวัฒนาการตามธรรมชาติของการถือครองจำนวนมากในการถ่ายภาพสต็อก
เผยแพร่ครั้งแรก 15 กันยายน 2022











