செயற்கை நுண்ணறிவு
கூகிளின் LipSync3D மேம்படுத்தப்பட்ட 'டீப்ஃபேக்டு' வாய் இயக்கம் ஒத்திசைவை வழங்குகிறது

A இணைந்து கூகுள் AI ஆராய்ச்சியாளர்கள் மற்றும் இந்திய தொழில்நுட்ப நிறுவனம் காரக்பூர் இடையே ஆடியோ உள்ளடக்கத்தில் இருந்து பேசும் தலைகளை ஒருங்கிணைக்க புதிய கட்டமைப்பை வழங்குகிறது. ஆடியோவில் இருந்து 'பேசும் தலை' வீடியோ உள்ளடக்கத்தை உருவாக்குவதற்கான உகந்த மற்றும் நியாயமான ஆதார வழிகளை உருவாக்குவதை நோக்கமாகக் கொண்டது, உதட்டு அசைவுகளை டப்பிங் செய்யப்பட்ட அல்லது இயந்திரம் மொழிபெயர்த்த ஆடியோவுடன் ஒத்திசைக்கும் நோக்கங்களுக்காகவும், அவதாரங்களில் பயன்படுத்துவதற்கும், ஊடாடும் பயன்பாடுகள் மற்றும் பிறவற்றில் பயன்படுத்தவும். நிகழ் நேர சூழல்கள்.

ஆதாரம்: https://www.youtube.com/watch?v=L1StbX9OznY
LipSync3D எனப்படும் - செயல்முறையில் பயிற்றுவிக்கப்பட்ட இயந்திர கற்றல் மாதிரிகளுக்கு, இலக்கு முக அடையாளத்தின் உள்ளீட்டுத் தரவின் ஒரு வீடியோ மட்டுமே தேவைப்படுகிறது. தரவுத் தயாரிப்பு பைப்லைன் ஒளியமைப்பு மற்றும் உள்ளீட்டு வீடியோவின் மற்ற அம்சங்களை மதிப்பீடு செய்வதிலிருந்து முக வடிவவியலைப் பிரித்தெடுக்கிறது, மேலும் சிக்கனமான மற்றும் கவனம் செலுத்தும் பயிற்சியை அனுமதிக்கிறது.
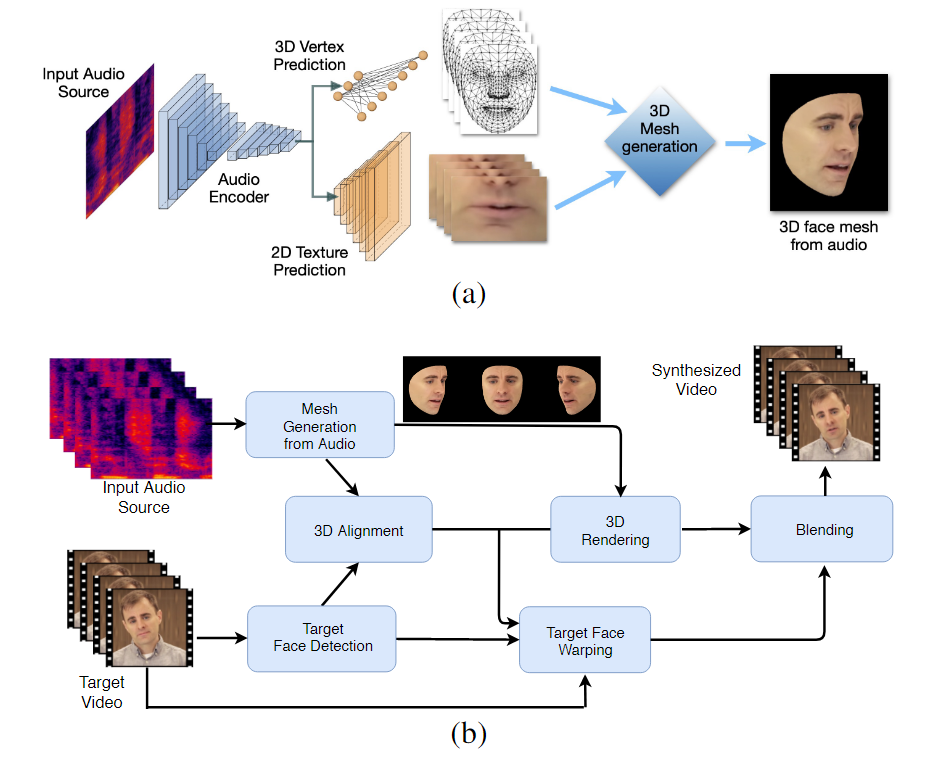
LipSync3D இன் இரண்டு-நிலை வேலை ஓட்டம். மேலே, 'டார்கெட்' ஆடியோவில் இருந்து டைனமிகல் டெக்ஸ்சர்டு 3D முகத்தின் உருவாக்கம்; கீழே, இலக்கு வீடியோவில் உருவாக்கப்பட்ட கண்ணி செருகல்.
உண்மையில், LipSync3D இன் மிகவும் குறிப்பிடத்தக்க பங்களிப்பானது இந்த பகுதியில் ஆராய்ச்சி முயற்சியின் அமைப்பில் அதன் லைட்டிங் இயல்பாக்குதல் அல்காரிதம் ஆகும், இது பயிற்சி மற்றும் அனுமான வெளிச்சத்தை துண்டிக்கிறது.

பொதுவான வடிவவியலில் இருந்து வெளிச்சம் தரவை துண்டிப்பது சவாலான சூழ்நிலையில் மிகவும் யதார்த்தமான உதடு இயக்க வெளியீட்டை உருவாக்க LipSync3D க்கு உதவுகிறது. சமீபத்திய ஆண்டுகளில் பிற அணுகுமுறைகள் தங்களை 'நிலையான' லைட்டிங் நிலைமைகளுக்கு மட்டுப்படுத்திக் கொண்டன, இது இந்த வகையில் அவற்றின் குறைந்த திறனை வெளிப்படுத்தாது.
உள்ளீட்டு தரவு பிரேம்களின் முன்-செயலாக்கத்தின் போது, கணினி ஸ்பெகுலர் புள்ளிகளைக் கண்டறிந்து அகற்ற வேண்டும், ஏனெனில் இவை வீடியோ எடுக்கப்பட்ட லைட்டிங் நிலைமைகளுக்கு குறிப்பிட்டவை, இல்லையெனில் ரீலைட்டிங் செயல்முறையில் தலையிடும்.

LipSync3D, அதன் பெயர் குறிப்பிடுவது போல, அது மதிப்பிடும் முகங்களில் வெறும் பிக்சல் பகுப்பாய்வைச் செய்வதில்லை, ஆனால் அடையாளம் காணப்பட்ட முக அடையாளங்களைத் தீவிரமாகப் பயன்படுத்தி, மரபுவழி CGI-ல் சுற்றியிருக்கும் 'அவிழ்க்கப்பட்ட' அமைப்புகளுடன், அசையும் CGI-பாணி மெஷ்களை உருவாக்குகிறது. குழாய்.

LipSync3D இல் இயல்பாக்கத்தை போஸ். இடதுபுறத்தில் உள்ளீடு சட்டங்கள் மற்றும் கண்டறியப்பட்ட அம்சங்கள் உள்ளன; நடுவில், உருவாக்கப்பட்ட கண்ணி மதிப்பீட்டின் இயல்பாக்கப்பட்ட முனைகள்; மற்றும் வலதுபுறத்தில், தொடர்புடைய அமைப்பு அட்லஸ், இது அமைப்புக் கணிப்புக்கான அடிப்படை உண்மையை வழங்குகிறது. ஆதாரம்: https://arxiv.org/pdf/2106.04185.pdf
நாவல் ரீலைட்டிங் முறையைத் தவிர, முந்தைய வேலைகளில் LipSync3D மூன்று முக்கிய கண்டுபிடிப்புகளை வழங்குகிறது என்று ஆராய்ச்சியாளர்கள் கூறுகின்றனர்: வடிவவியல், ஒளியமைப்பு, போஸ் மற்றும் அமைப்பு ஆகியவற்றை இயல்பாக்கப்பட்ட இடத்தில் தனித்தனி தரவு ஸ்ட்ரீம்களாகப் பிரித்தல்; தற்காலிகமாக சீரான வீடியோ தொகுப்பை உருவாக்கும் எளிதில் பயிற்சியளிக்கக்கூடிய தன்னியக்க-பின்னடைவு அமைப்பு முன்கணிப்பு மாதிரி; மனித மதிப்பீடுகள் மற்றும் புறநிலை அளவீடுகளால் மதிப்பிடப்பட்டபடி, அதிகரித்த யதார்த்தவாதம்.

வீடியோ முகப் படங்களின் பல்வேறு அம்சங்களைப் பிரிப்பது வீடியோ தொகுப்பில் அதிகக் கட்டுப்பாட்டை அனுமதிக்கிறது.
LipSync3D ஆனது ஒலிப்பதிவுகள் மற்றும் பேச்சின் பிற அம்சங்களைப் பகுப்பாய்வு செய்வதன் மூலம் பொருத்தமான உதடு வடிவியல் இயக்கத்தை நேரடியாக ஆடியோவிலிருந்து பெறலாம், மேலும் அவற்றை வாய்ப் பகுதியைச் சுற்றி தெரிந்த தொடர்புடைய தசை போஸ்களாக மொழிபெயர்க்கலாம்.

இந்த செயல்முறையானது கூட்டு-கணிப்பு பைப்லைனைப் பயன்படுத்துகிறது, இதில் ஊகிக்கப்பட்ட வடிவியல் மற்றும் அமைப்பு ஒரு தன்னியக்க குறியாக்கி அமைப்பில் பிரத்யேக குறியாக்கிகளைக் கொண்டுள்ளது, ஆனால் மாதிரியின் மீது திணிக்கப்படும் பேச்சுடன் ஆடியோ குறியாக்கியைப் பகிர்ந்து கொள்கிறது:

LipSync3D இன் லேபிள் இயக்கத் தொகுப்பு, பகட்டான CGI அவதாரங்களைச் செயல்படுத்தும் நோக்கத்துடன் உள்ளது, இது நிஜ-உலகப் படங்களின் அதே வகையான கண்ணி மற்றும் அமைப்புத் தகவல் மட்டுமே:
ஒரு பகட்டான 3D அவதார் அதன் உதடு அசைவுகளை நிகழ்நேரத்தில் மூல ஸ்பீக்கர் வீடியோ மூலம் இயக்குகிறது. அத்தகைய சூழ்நிலையில், தனிப்பயனாக்கப்பட்ட முன் பயிற்சி மூலம் சிறந்த முடிவுகளைப் பெறலாம்.
சற்று யதார்த்தமான உணர்வுடன் அவதாரங்களைப் பயன்படுத்துவதையும் ஆராய்ச்சியாளர்கள் எதிர்பார்க்கின்றனர்:
![]()
ஜியிபோர்ஸ் GTX 3 இல் TensorFlow, Python மற்றும் C++ ஆகியவற்றைப் பயன்படுத்தும் ஒரு பைப்லைனில், 5-2 நிமிட வீடியோவிற்கு, வீடியோக்களுக்கான மாதிரி பயிற்சி நேரம் 5-1080 மணிநேரம் வரை இருக்கும். பயிற்சி அமர்வுகள் 128-500 க்கு மேல் 1000 பிரேம்களின் தொகுதி அளவைப் பயன்படுத்தியது. சகாப்தங்கள், ஒவ்வொரு சகாப்தமும் வீடியோவின் முழுமையான மதிப்பீட்டைக் குறிக்கும்.

உதடு இயக்கத்தின் மாறும் மறு ஒத்திசைவை நோக்கி
புதிய ஆடியோ டிராக்கிற்கு இடமளிக்கும் வகையில் உதடுகளை மீண்டும் ஒத்திசைக்கும் துறை கடந்த சில ஆண்டுகளில் கணினி பார்வை ஆராய்ச்சியில் பெரும் கவனத்தைப் பெற்றுள்ளது (கீழே காண்க), இது சர்ச்சைக்குரிய ஒரு துணை தயாரிப்பு என்பதால் அல்ல. ஆழமான தொழில்நுட்பம்.
2017 இல் வாஷிங்டன் பல்கலைக்கழகம் ஆய்வுகளை முன்வைத்தார் அப்போதைய அதிபர் ஒபாமாவின் உதடு அசைவுகளை மாற்ற, ஆடியோவில் இருந்து உதட்டு ஒத்திசைவைக் கற்றுக் கொள்ளும் திறன் கொண்டது. 2018 இல்; மேக்ஸ் பிளாங்க் இன்ஸ்டிடியூட் ஃபார் இன்ஃபர்மேட்டிக்ஸ் தலைமையில் மற்றொரு ஆராய்ச்சி முயற்சி அடையாளம்>அடையாள வீடியோ பரிமாற்றத்தை இயக்க, உதட்டு ஒத்திசைவு a செயல்முறையின் துணை தயாரிப்பு; மே 2021 இல் AI ஸ்டார்ட்அப் FlawlessAI அதன் தனியுரிம லிப்-ஒத்திசைவு தொழில்நுட்பமான TrueSync ஐ பரவலாக வெளிப்படுத்தியது. பெற்றார் அனைத்து மொழிகளிலும் பெரிய திரைப்பட வெளியீடுகளுக்கு மேம்படுத்தப்பட்ட டப்பிங் தொழில்நுட்பங்களை செயல்படுத்தும் வகையில் பத்திரிகைகளில்.
மற்றும், நிச்சயமாக, டீப்ஃபேக் ஓப்பன் சோர்ஸ் களஞ்சியங்களின் தற்போதைய வளர்ச்சியானது, முகப் படத் தொகுப்பின் இந்த கோளத்தில் செயலில் உள்ள பயனர் பங்களிக்கும் ஆராய்ச்சியின் மற்றொரு கிளையை வழங்குகிறது.















