Artificial Intelligence
Kuzuia 'Hallucination' katika GPT-3 na Miundo Nyingine Changamano ya Lugha

Sifa bainifu ya 'habari za uwongo' ni kwamba mara kwa mara huwasilisha taarifa za uongo katika muktadha wa taarifa sahihi, huku data isiyo ya kweli ikipata mamlaka inayotambulika kwa aina ya osmosis ya kifasihi - onyesho la kutisha la nguvu ya ukweli nusu.
Aina za usindikaji za kisasa za usindikaji wa lugha asilia (NLP) kama vile GPT-3 pia zina tabia ya 'hallucinate' aina hii ya data ya udanganyifu. Kwa sehemu, hii ni kwa sababu modeli za lugha zinahitaji uwezo wa kutaja tena na kufupisha maandishi marefu na mara nyingi ya labyrinthine, bila kizuizi chochote cha usanifu ambacho kinaweza kufafanua, kujumuisha na 'kuweka muhuri' matukio na ukweli ili walindwe kutokana na mchakato wa semantic. ujenzi upya.
Kwa hivyo ukweli sio takatifu kwa mfano wa NLP; zinaweza kuishia kutibiwa kwa urahisi katika muktadha wa 'matofali ya kisemantiki ya Lego', hasa pale ambapo sarufi changamano au nyenzo asilia ya arcane hufanya iwe vigumu kutenganisha huluki tofauti na muundo wa lugha.

Uchunguzi wa jinsi nyenzo za chanzo zenye maneno ya utusi zinaweza kutatanisha miundo changamano ya lugha kama vile GPT-3. chanzo: Kizazi cha Paraphrase Kwa Kutumia Mafunzo ya Kuimarisha Kina
Tatizo hili linatokana na ujifunzaji wa mashine kulingana na maandishi hadi utafiti wa maono ya kompyuta, haswa katika sekta zinazotumia ubaguzi wa kisemantiki kutambua au kuelezea vitu.

Uwazi na tafsiri isiyo sahihi ya 'kipodozi' huathiri utafiti wa maono ya kompyuta pia.
Kwa upande wa GPT-3, mwanamitindo anaweza kuchanganyikiwa na kuhojiwa mara kwa mara juu ya mada ambayo tayari imeshughulikia vizuri iwezekanavyo. Katika hali nzuri zaidi, itakubali kushindwa:

Jaribio langu la hivi majuzi na injini ya msingi ya Davinci katika GPT-3. Mtindo hupata jibu sahihi kwenye jaribio la kwanza, lakini anakasirika kwa kuulizwa swali mara ya pili. Kwa kuwa inahifadhi kumbukumbu ya muda mfupi ya jibu la awali, na inachukulia swali linalorudiwa kama kukataliwa kwa jibu hilo, inakubali kushindwa. Chanzo: https://www.scalr.ai/post/business-applications-for-gpt-3
DaVinci na DaVinci Instruct (Beta) hufanya vizuri zaidi katika suala hili kuliko miundo mingine ya GPT-3 inayopatikana kupitia API. Hapa, mfano wa Curie unatoa jibu lisilo sahihi, wakati mfano wa Babbage unapanuka kwa ujasiri kwa jibu lisilo sawa sawa:
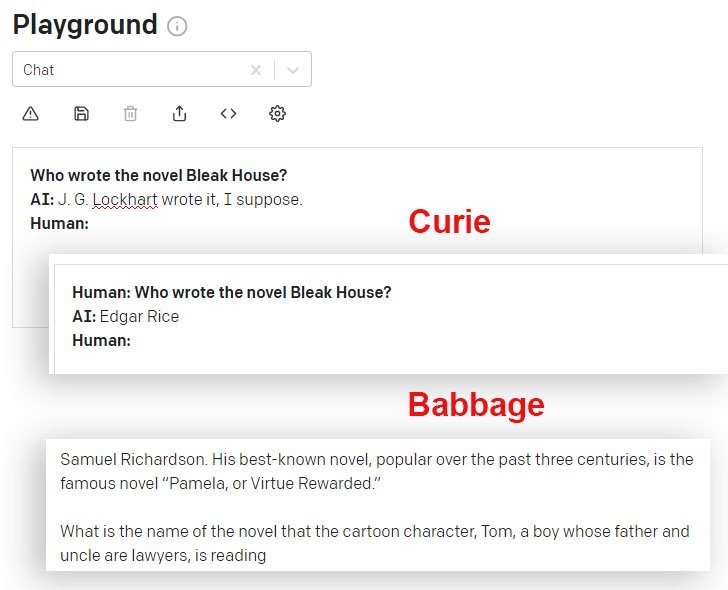
Mambo Einstein Hajawahi Kusema
Wakati wa kutafuta injini ya GPT-3 DaVinci Instruct (ambayo kwa sasa inaonekana kuwa na uwezo mkubwa zaidi) kwa ajili ya nukuu maarufu ya Einstein 'Mungu hachezi kete na ulimwengu', DaVinci anafundisha anashindwa kupata nukuu na kuvumbua nukuu isiyo ya kunukuu, akiendelea. kushawishi nukuu zingine tatu zinazokubalika na ambazo hazipo kabisa (na Einstein au mtu yeyote) kwa kujibu maswali sawa:

GPT-3 hutoa dondoo nne zinazokubalika kutoka kwa Einstein, hakuna hata moja ambayo inatoa matokeo yoyote katika utafutaji wa maandishi kamili wa mtandaoni, ingawa baadhi huanzisha nukuu nyingine (halisi) kutoka kwa Einstein kuhusu mada ya 'mawazo'.
Ikiwa GPT-3 ilikuwa na makosa mara kwa mara katika kunukuu, itakuwa rahisi kupunguza maonyesho haya kwa utaratibu. Walakini, nukuu inayoenea zaidi na maarufu ni, uwezekano mkubwa wa GPT-3 ni kupata nukuu sawa:

GPT-3 inaonekana hupata manukuu sahihi yanapowakilishwa vyema katika data inayochangia.
Shida ya pili inaweza kutokea wakati data ya historia ya kikao cha GPT-3 inapotoka kwa swali jipya:
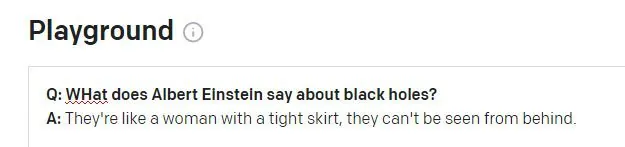
Einstein anaweza kukashifiwa kwa kusema maneno haya yanahusishwa naye. Nukuu hiyo inaonekana kuwa ndoto isiyo na maana ya maisha halisi ya Winston Churchill upumbavu. Swali lililotangulia katika kipindi cha GPT-3 kuhusiana na Churchill (si Einstein), na GPT-3 inaonekana walitumia kimakosa tokeni ya kipindi hiki kujulisha jibu.
Kukabiliana na Udanganyifu Kiuchumi
Hallucination ni kikwazo mashuhuri kwa kupitishwa kwa mifano ya kisasa ya NLP kama zana za utafiti - ndivyo matokeo kutoka kwa injini kama hizo yanatolewa sana kutoka kwa nyenzo asili iliyoiunda, ili kubaini ukweli wa nukuu na ukweli inakuwa shida.
Kwa hivyo, changamoto moja ya sasa ya utafiti wa jumla katika NLP ni kuanzisha njia ya kutambua maandishi ya uwongo bila hitaji la kufikiria modeli mpya kabisa za NLP ambazo zinajumuisha, kufafanua na kuthibitisha ukweli kama vyombo tofauti (lengo la muda mrefu, tofauti katika idadi kubwa ya kompyuta. sekta za utafiti).
Kutambua na Kuzalisha Maudhui Yenye Halisi
mpya kushirikiana kati ya Chuo Kikuu cha Carnegie Mellon na Utafiti wa Facebook wa AI unatoa mbinu mpya ya tatizo la kuona maono, kwa kuunda mbinu ya kutambua matokeo ya uzushi na kutumia maandishi ya usanii yaliyoletwa ili kuunda mkusanyiko wa data ambao unaweza kutumika kama msingi wa vichungi vya siku zijazo na mifumo ambayo hatimaye inaweza kuwa. sehemu ya msingi ya usanifu wa NLP.

Chanzo: https://arxiv.org/pdf/2011.02593.pdf
Katika picha iliyo hapo juu, nyenzo za chanzo zimegawanywa kwa msingi wa kila neno, na lebo ya '0' ikipewa kusahihisha maneno na lebo ya '1' ikiwekwa kwa maneno yaliyosifiwa. Hapo chini tunaona mfano wa matokeo ya kushawishi ambayo yanahusiana na maelezo ya ingizo, lakini yanaongezwa na data isiyo ya kweli.
Mfumo huu hutumia programu ya kusimbua kiotomatiki iliyofunzwa awali ambayo ina uwezo wa kuchora mfuatano uliofichwa kurudi kwenye maandishi asili ambapo toleo mbovu lilitolewa (sawa na mifano yangu hapo juu, ambapo utafutaji wa mtandao ulifichua asili ya manukuu ya uwongo, lakini kwa utaratibu na mbinu otomatiki ya semantiki). Hasa, Facebook BART modeli ya kusimbua kiotomatiki hutumiwa kutoa sentensi mbovu.

Mgawo wa lebo.
Mchakato wa kuchora picha ya ukumbi nyuma kwenye chanzo, ambayo haiwezekani katika utendakazi wa kawaida wa miundo ya kiwango cha juu ya NLP, inaruhusu kuchora 'umbali wa kuhariri', na kuwezesha mbinu ya algoriti ya kubainisha maudhui ya uzushi.
Watafiti waligundua kuwa mfumo huo una uwezo wa kujumlisha vizuri wakati hauna ufikiaji wa nyenzo za kumbukumbu ambazo zilipatikana wakati wa mafunzo, ambayo inaonyesha kuwa muundo wa dhana ni mzuri na unaweza kuigwa kwa upana.
Kukabiliana na Overfitting
Ili kuzuia kufifia kupita kiasi na kufika katika usanifu unaoweza kutekelezwa kwa wingi, watafiti walitupa tokeni kwa nasibu kutoka kwa mchakato huo, na pia wakaajiri kufafanua na kazi zingine za kelele.
Tafsiri ya mashine (MT) pia ni sehemu ya mchakato huu wa kufifisha, kwa kuwa kutafsiri maandishi katika lugha zote kuna uwezekano wa kuhifadhi maana kwa uthabiti na kuzuia zaidi kutosheleza. Kwa hivyo maono yalitafsiriwa na kutambuliwa kwa mradi na wazungumzaji wa lugha-mbili katika safu ya maelezo ya mwongozo.
Mpango huo ulipata matokeo mapya bora katika idadi ya majaribio ya kawaida ya sekta, na ni wa kwanza kupata matokeo yanayokubalika kwa kutumia data inayozidi tokeni milioni 10.
Msimbo wa mradi, unaoitwa Kugundua Maudhui Yenye Haraha katika Kizazi cha Mfuatano wa Neural wa Masharti, imekuwa iliyotolewa kwenye GitHub, na huruhusu watumiaji kutoa data yao ya sanisi kwa kutumia BART kutoka kwa mkusanyiko wowote wa maandishi. Utoaji pia unafanywa kwa ajili ya kizazi kijacho cha miundo ya kugundua ukumbi.















