Kacerdasan buatan
Nyegah 'Halusinasi' dina GPT-3 sareng Modél Basa Kompleks lianna

Karakteristik anu nangtukeun tina 'warta palsu' nyaéta yén éta sering nampilkeun inpormasi palsu dina kontéks inpormasi anu leres-leres leres, kalayan data anu henteu leres nampi otoritas anu ditanggap ku jinis osmosis sastra - demonstrasi anu pikahariwangeun ngeunaan kakuatan satengah bebeneran.
Modél pangolahan basa generatif alami (NLP) canggih sapertos GPT-3 ogé ngagaduhan kacenderungan pikeun 'halusinasi' jenis ieu data nu nipu. Sabagéan, ieu kusabab model basa merlukeun kamampuhan pikeun rephrase jeung nyimpulkeun tracts panjang tur mindeng labyrinthine téks, tanpa konstrain arsitéktur nu bisa nangtukeun, encapsulate jeung 'nyegel' kajadian jeung fakta ambéh maranéhanana ditangtayungan tina prosés semantik. rekonstruksi.
Ku alatan éta, fakta henteu suci pikeun modél NLP; aranjeunna bisa kalayan gampang mungkas nepi dirawat dina konteks 'semantik Lego bata', utamana dimana grammar kompléks atawa arcane bahan sumber ngajadikeun hésé pikeun misahkeun éntitas diskrit tina struktur basa.

Obsérvasi ngeunaan cara bahan sumber anu difrasakeun sacara tortuously tiasa ngabingungkeun modél basa anu kompleks sapertos GPT-3. sumber: Generasi Parafrase Ngagunakeun Pangajaran Penguatan Jero
Masalah ieu ngabahekeun tina pembelajaran mesin dumasar téks kana panalungtikan visi komputer, khususna dina séktor anu ngagunakeun diskriminasi semantik pikeun ngaidentipikasi atanapi ngajelaskeun objék.

Halusinasi sareng reinterpretasi 'kosmetik' anu teu akurat mangaruhan ogé panalungtikan visi komputer.
Dina kasus GPT-3, modél tiasa janten frustasi sareng patarosan anu diulang-ulang dina topik anu parantos dibahas ogé. Dina skenario kasus pangalusna, éta bakal ngaku eleh:

Hiji percobaan panganyarna tina milik jeung mesin Davinci dasar dina GPT-3. Modél meunang jawaban katuhu dina usaha kahiji, tapi vexed mun ditanya patarosan kadua kalina. Kusabab eta nahan hiji memori jangka pondok tina jawaban saméméhna, sarta Ngaruwat patarosan diulang sakumaha tampikan jawaban éta, concedes eleh. Sumber: https://www.scalr.ai/post/business-applications-for-gpt-3
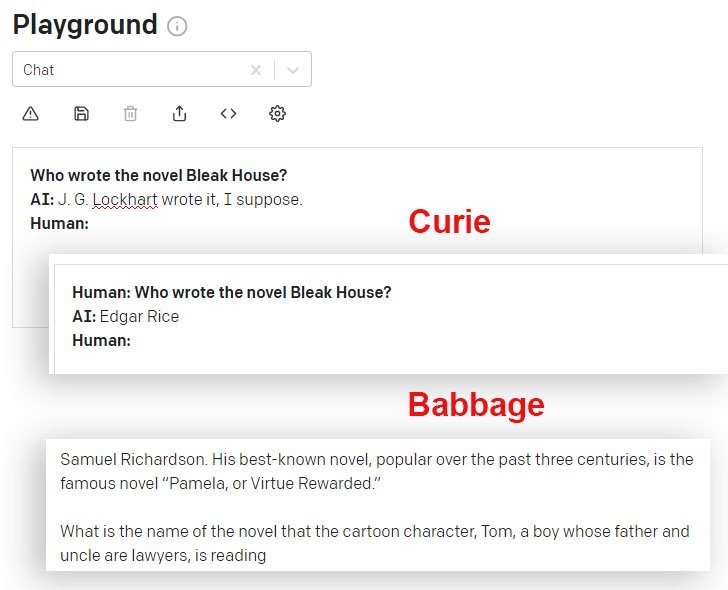
DaVinci sareng DaVinci Instruct (Beta) langkung saé dina hal ieu tibatan modél GPT-3 sanés anu sayogi via API. Di dieu, modél Curie masihan jawaban anu salah, sedengkeun modél Babbage ngalegaan kalayan yakin kana jawaban anu sami-sami salah:
Hal Einstein Kungsi Nyarios
Nalika naroskeun mesin GPT-3 DaVinci Instruct (anu ayeuna sigana anu paling mampuh) pikeun kutipan anu kasohor Einstein 'God doesn't play dadu with the universe', DaVinci maréntahkeun gagal mendakan kutipan sareng nyiptakeun kutipan sanés, teras teraskeun. pikeun halusinasi tilu tanda petik anu kawilang masuk akal sareng lengkep henteu aya (ku Einstein atanapi saha waé) pikeun ngaréspon patarosan anu sami:

GPT-3 ngahasilkeun opat tanda petik masuk akal ti Einstein, teu aya anu ngahasilkeun hasil naon waé dina panéangan internét téks lengkep, sanaos sababaraha micu kutipan sanés (nyata) ti Einstein ngeunaan topik 'imajinasi'.
Upami GPT-3 sacara konsistén salah dina ngadugikeun kutipan, éta bakal langkung gampang pikeun ngirangan halusinasi ieu sacara terprogram. Tapi, kutipan anu langkung nyebar sareng kasohor, langkung dipikaresep GPT-3 kéngingkeun kutipan anu leres:

GPT-3 katingalina mendakan tanda petik anu leres nalika aranjeunna diwakilan saé dina data anu nyumbang.
Masalah kadua tiasa muncul nalika data sajarah sési GPT-3 janten patarosan énggal:
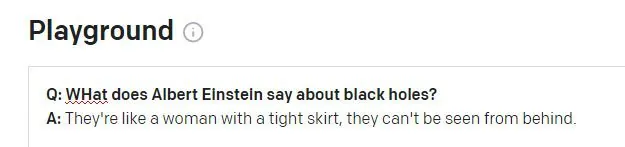
Einstein sigana bakal skandal upami nyarios ieu dikaitkeun ka anjeunna. Kutipan kasebut katingalina mangrupikeun halusinasi anu teu raoseun tina kahirupan nyata Winston Churchill aphorism. Patarosan saméméhna dina sési GPT-3 patali jeung Churchill (sanes Einstein), sarta GPT-3 sigana salah ngagunakeun token sési ieu pikeun nginpokeun jawaban.
Tackling halusinasi ékonomis
Halusinasi mangrupikeun halangan anu penting pikeun nyoko kana modél NLP anu canggih salaku alat panalungtikan - langkung-langkung kaluaran tina mesin sapertos kitu pisan disarikeun tina bahan sumber anu ngawangun éta, ku kituna netepkeun kabeneran kutipan sareng fakta janten masalah.
Ku alatan éta, hiji tantangan panalungtikan umum ayeuna di NLP nyaéta pikeun ngadegkeun sarana pikeun ngaidentipikasi téks halusinasi tanpa kudu ngabayangkeun model NLP sagemblengna anyar nu ngasupkeun, nangtukeun jeung ngaoténtikasi fakta salaku éntitas diskrit (jangka panjang, tujuan misah dina sajumlah komputer lega. séktor panalungtikan).
Ngidentipikasi Sareng Ngahasilkeun Eusi Halusinasi
A anyar gawe babarengan antara Carnegie Mellon University sareng Facebook AI Research nawiskeun pendekatan novél pikeun masalah halusinasi, ku ngarumuskeun metode pikeun ngaidentipikasi kaluaran halusinasi sareng ngagunakeun téks halusinasi sintétik pikeun nyiptakeun set data anu tiasa dianggo salaku garis dasar pikeun saringan sareng mékanisme hareup anu antukna tiasa janten bagian inti tina arsitéktur NLP.

Sumber: https://arxiv.org/pdf/2011.02593.pdf
Dina gambar di luhur, bahan sumber geus dibagi dina dasar per-kecap, kalawan labél '0' ditugaskeun pikeun ngabenerkeun kecap jeung labél '1' ditugaskeun ka kecap halusinasi. Di handap ieu kami ningali conto kaluaran halusinasi anu aya hubunganana sareng inpormasi input, tapi ditambah ku data non-asli.
Sistemna ngagunakeun autoencoder denoising anu tos dilatih anu sanggup mapping string halusinasi deui kana téks aslina ti mana versi anu rusak diproduksi (sarupa sareng conto kuring di luhur, dimana panéangan internét ngungkabkeun asal-usul tanda petik palsu, tapi kalayan programmatic sareng metodologi semantik otomatis). Husus, Facebook urang Bart Modél autoencoder dipaké pikeun ngahasilkeun kalimah anu ruksak.

Label tugas.
Prosés pemetaan halusinasi deui ka sumber, nu teu mungkin dina ngajalankeun umum model NLP tingkat luhur, ngamungkinkeun pikeun pemetaan 'jarak édit', sarta facilitates pendekatan algorithmic pikeun ngaidentipikasi eusi halusinasi.
Panaliti mendakan yén sistem éta malah tiasa ngageneralisasi saé nalika teu gaduh aksés kana bahan rujukan anu sayogi nalika latihan, anu nunjukkeun yén modél konsép anu saé sareng sacara lega tiasa ditiru.
Tackling Overfitting
Dina raraga ngahindarkeun overfitting sarta anjog ka arsitéktur lega deployable, panalungtik acak turun tokens tina prosés, sarta ogé padamelan paraphrasing sarta fungsi noise lianna.
Tarjamahan mesin (MT) oge bagian tina prosés obfuscation ieu, saprak narjamahkeun téks sakuliah basa kamungkinan pikeun ngajaga harti mantap sarta salajengna nyegah over-pas. Ku sabab kitu halusinasi ditarjamahkeun sareng diidentifikasi pikeun proyék ku panyatur bi-lingual dina lapisan anotasi manual.
Inisiatif éta ngahontal hasil anu pangsaéna dina sababaraha tés séktor standar, sareng anu munggaran ngahontal hasil anu tiasa ditampi nganggo data anu langkung ti 10 juta token.
Kodeu pikeun proyék, dijudulan Ngadeteksi Eusi Halusinasi dina Generasi Urutan Neural Kondisi, parantos dirilis dina GitHub, sarta ngidinan pamaké pikeun ngahasilkeun data sintétik sorangan kalawan BART tina sagala korpus téks. Penyediaan ogé dijieun pikeun generasi saterusna model deteksi halusinasi.










