
Kacerdasan buatan
Optimasi Préferénsi Langsung: Pituduh Lengkep

aligning model basa badag (LLMs) jeung nilai manusa jeung karesep téh nangtang. Métode tradisional, sapertos Panguatan Diajar tina Eupan Balik Manusa (RLHF), geus diaspal jalan ku integrasi inputs manusa pikeun nyaring kaluaran model. Tapi, RLHF tiasa rumit sareng sumber daya-intensif, meryogikeun kakuatan komputasi anu ageung sareng ngolah data. Optimasi Préferénsi Langsung (DPO) muncul salaku novél sareng pendekatan anu langkung ramping, nawiskeun alternatif anu efisien pikeun metode tradisional ieu. Ku nyederhanakeun prosés optimasi, DPO henteu ngan ukur ngirangan beban komputasi tapi ogé ningkatkeun kamampuan modél pikeun adaptasi gancang kana kahoyong manusa.
Dina pituduh ieu urang bakal teuleum jero kana DPO, ngajalajah yayasanna, palaksanaan, sareng aplikasi praktis.
Kabutuhan pikeun Alignment Préferénsi
Pikeun ngartos DPO, penting pisan pikeun ngartos naha nyaluyukeun LLM sareng kahoyong manusa penting pisan. Sanaos kamampuan anu pikaresepeun, LLM anu dilatih dina set data anu ageung kadang-kadang tiasa ngahasilkeun kaluaran anu henteu konsisten, bias, atanapi teu saluyu sareng nilai-nilai manusa. misalignment ieu bisa manifest dina sababaraha cara:
- Ngahasilkeun eusi anu teu aman atanapi ngabahayakeun
- Nyadiakeun inpormasi anu teu akurat atanapi nyasabkeun
- Exhibiting biases hadir dina data latihan
Pikeun ngajawab masalah ieu, panalungtik geus ngembangkeun téknik pikeun fine-tune LLMs ngagunakeun eupan balik manusa. Anu paling menonjol tina pendekatan ieu nyaéta RLHF.
Ngarti RLHF: The prékursor pikeun DPO
Pangajaran Penguatan tina Umpan Balik Manusa (RLHF) parantos janten metodeu pikeun nyaluyukeun LLM sareng karesep manusa. Hayu urang ngarecah prosés RLHF pikeun ngartos pajeulitna:
a) Diawasan Fine-Tuning (SFT): Prosésna dimimitian ku fine-tuning LLM tos dilatih dina set data tina réspon kualitas luhur. Léngkah ieu ngabantosan modél ngahasilkeun kaluaran anu langkung relevan sareng koheren pikeun tugas target.
b) Modeling ganjaran: Modél ganjaran anu misah dilatih pikeun ngaduga kahoyong manusa. Ieu ngawengku:
- Ngahasilkeun pasangan réspon pikeun paréntah anu dipasihkeun
- Ngabogaan manusa meunteun respon anu aranjeunna pikaresep
- Ngalatih modél pikeun ngaduga preferensi ieu
c) Pembuatan Penguatan: LLM anu disampurnakeun satuluyna dioptimalkeun deui ngagunakeun pembelajaran penguatan. Modél ganjaran nyayogikeun eupan balik, nungtun LLM pikeun ngahasilkeun réspon anu saluyu sareng kahoyong manusa.
Ieu mangrupikeun pseudocode Python anu disederhanakeun pikeun ngagambarkeun prosés RLHF:
Sanaos efektif, RLHF ngagaduhan sababaraha kalemahan:
- Merlukeun latihan jeung ngajaga sababaraha model (SFT, model ganjaran, jeung model RL-dioptimalkeun)
- Prosés RL tiasa teu stabil sareng sénsitip kana hyperparameters
- Éta mahal sacara komputasi, meryogikeun seueur maju sareng mundur ngalangkungan modél
Watesan ieu ngamotivasi milarian alternatif anu langkung sederhana, langkung éfisién, ngarah kana pamekaran DPO.
Optimasi Préferénsi Langsung: Konsép Inti

Optimasi Préferénsi Langsung https://arxiv.org/abs/2305.18290
Gambar ieu ngabedakeun dua pendekatan anu béda pikeun nyaluyukeun kaluaran LLM sareng kahoyong manusa: Pangajaran Penguatan tina Umpan Balik Manusa (RLHF) sareng Optimasi Preferensi Langsung (DPO). RLHF ngandelkeun modél ganjaran pikeun nungtun kabijakan modél basa ngaliwatan puteran umpan balik iteratif, sedengkeun DPO langsung ngaoptimalkeun kaluaran modél pikeun nyocogkeun réspon anu dipikaresep ku manusa nganggo data preferensi. Perbandingan ieu nyorot kaunggulan sareng aplikasi poténsial unggal metode, masihan wawasan ngeunaan kumaha LLM ka hareup tiasa dilatih pikeun langkung saluyu sareng ekspektasi manusa.
Gagasan konci balik DPO:
a) Implisit Ganjaran Modeling: DPO ngaleungitkeun kabutuhan modél ganjaran anu misah ku ngarawat modél basa sorangan salaku fungsi ganjaran implisit.
b) Formulasi Dumasar Kabijakan: Gantina ngaoptimalkeun fungsi ganjaran, DPO langsung ngaoptimalkeun kawijakan (modél basa) pikeun maksimalkeun pungsi kamungkinan réspon pikaresep.
c) Solusi Bentuk Tertutup: DPO leverages hiji wawasan matematik nu ngamungkinkeun pikeun solusi katutup-formulir kana kawijakan optimal, Ngahindarkeun kabutuhan pikeun apdet RL iterative.
Ngalaksanakeun DPO: A Code Practical Walkthrough
Gambar di handap ieu nunjukkeun snippet kode anu ngalaksanakeun fungsi leungitna DPO nganggo PyTorch. Pungsi ieu maénkeun peran krusial dina nyaring kumaha model basa prioritas kaluaran dumasar kana preferensi manusa. Ieu ngarecahna komponén konci:
- Fungsi Signature: Nu
dpo_lossfungsi nyokot sababaraha parameter kaasup probabiliti log kawijakan (pi_logps), probabiliti log modél rujukan (ref_logps), jeung indéks nu ngagambarkeun completions pikaresep jeung dispreferred (yw_idxs,yl_idxs). Sajaba ti éta, abetaparameter ngadalikeun kakuatan pinalti KL. - Ékstrak Probabilitas Log: Kode extracts probabiliti log pikeun completions pikaresep tur dispreferred tina duanana kawijakan jeung model rujukan.
- Log Rasio Itungan: Beda antara probabiliti log pikeun completions pikaresep jeung dispreferred diitung keur duanana model kawijakan jeung rujukan. Rasio ieu kritis dina nangtukeun arah jeung gedena optimasi.
- Rugi jeung itungan ganjaran: Leungitna diitung ngagunakeun
logsigmoidfungsi, bari ganjaran ditangtukeun ku skala béda antara kawijakan jeung rujukan probabiliti log kubeta.

fungsi leungitna DPO maké PyTorch
Hayu urang teuleum kana matematika di tukangeun DPO pikeun ngartos kumaha éta ngahontal tujuan ieu.
Matematika DPO
DPO mangrupikeun réformulasi pinter tina masalah diajar anu dipikaresep. Ieu ngarecahna léngkah-léngkah:
a) Mimitian Point: KL-konstrain ganjaran Maximization
Tujuan RLHF aslina bisa ditembongkeun salaku:
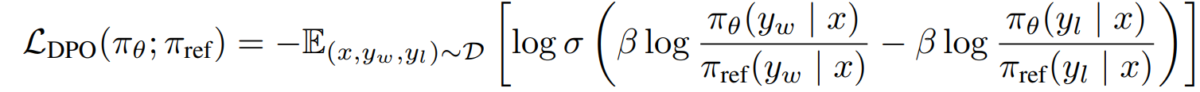
- πθ nyaéta kawijakan (modél basa) anu urang optimalkeun
- r(x,y) nyaéta fungsi ganjaran
- πref nyaéta kawijakan rujukan (biasana model SFT awal)
- β ngadalikeun kakuatan konstrain divergénsi KL
b) Bentuk Kawijakan Optimal: Ieu tiasa ditingalikeun yén kawijakan optimal pikeun tujuan ieu nyaéta:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Dimana Z(x) nyaéta konstanta normalisasi.
c) Dualitas Kawijakan-ganjaran: Wawasan konci DPO nyaéta pikeun nganyatakeun fungsi ganjaran dina hal kawijakan optimal:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Modél Préferénsi Lamun préferénsi nuturkeun modél Bradley-Terry, urang bisa ngécéskeun kamungkinan leuwih milih y1 tibatan y2 salaku:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Dimana σ nyaéta fungsi logistik.
e) Tujuan DPO Ngaganti dualitas kawijakan-ganjaran urang kana modél pilihan, kami dugi ka tujuan DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Tujuan ieu tiasa dioptimalkeun nganggo téknik turunan gradién standar, tanpa peryogi algoritma RL.
Palaksanaan DPO
Ayeuna urang ngartos téori di balik DPO, hayu urang tingali kumaha nerapkeunana dina prakna. Urang bakal ngagunakeun Python jeung PyTorch pikeun conto ieu:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Tantangan jeung Arah Future
Sanaos DPO nawiskeun kaunggulan anu signifikan tibatan pendekatan RLHF tradisional, masih aya tantangan sareng daérah pikeun panalungtikan salajengna:
a) Skalabilitas kana Modél anu langkung ageung:
Salaku model basa terus tumuwuh dina ukuranana, éfisién nerapkeun DPO ka model mibanda ratusan milyar parameter tetep hiji tantangan kabuka. Panaliti ngajalajah téknik sapertos:
- Métode fine-tuning efisien (misalna, LoRA, tuning awalan)
- optimizations latihan disebarkeun
- Pamariksaan gradién sareng latihan precision dicampur
Conto ngagunakeun LoRA sareng DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adaptasi Multi-Tugas sareng Sababaraha-Shot:
Ngembangkeun téknik DPO anu épisién tiasa adaptasi kana tugas atanapi domain énggal kalayan data pilihan terbatas mangrupikeun daérah panalungtikan anu aktip. Pendekatan anu ditalungtik kalebet:
- kerangka Meta-learning pikeun adaptasi gancang
- Denda-tuning dumasar ajakan pikeun DPO
- Mindahkeun diajar tina model preferensi umum kana domain husus
c) Nanganan Preferensi Ambigu atawa Konflik:
Data karesep dunya nyata sering ngandung ambiguitas atanapi konflik. Ningkatkeun kakuatan DPO kana data sapertos kitu penting pisan. Solusi poténsial kalebet:
- Modeling preferensi probabilistik
- Diajar aktip pikeun ngabéréskeun ambiguities
- Multi-agén aggregation leuwih sering dipake tinimbang
Conto modeling preferensi probabilistik:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Ngagabungkeun DPO jeung Téhnik Alignment lianna:
Ngahijikeun DPO sareng pendekatan alignment anu sanés tiasa nyababkeun sistem anu langkung kuat sareng mampuh:
- Prinsip AI konstitusional pikeun kapuasan konstrain eksplisit
- Debat sareng modeling ganjaran rekursif pikeun elicitation preferensi kompléks
- Pangajaran penguatan tibalik pikeun nyimpulkeun fungsi ganjaran dasar
Conto ngagabungkeun DPO sareng AI konstitusional:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Pertimbangan Praktis sareng Praktek Pangalusna
Nalika nerapkeun DPO pikeun aplikasi dunya nyata, pertimbangkeun tip ieu:
a) Quality data: Kualitas data preferensi Anjeun krusial. Pastikeun yén set data anjeun:
- Nyertakeun rupa-rupa input sareng paripolah anu dipikahoyong
- Mibanda annotations preferensi konsisten tur dipercaya
- Nyaimbangkeun sababaraha jinis karesep (contona, faktualitas, kaamanan, gaya)
b) Hyperparameter Tuning: Sedengkeun DPO boga hyperparameters pangsaeutikna ti RLHF, tuning masih penting:
- β (béta): Ngadalikeun trade-off antara kapuasan preferensi jeung divergénsi tina model rujukan. Mimitian ku nilai sabudeureun 0.1-0.5.
- Laju diajar: Anggo laju diajar anu langkung handap tibatan standar fine-tuning, biasana dina rentang 1e-6 nepi ka 1e-5.
- Ukuran bets: Ukuran bets langkung ageung (32-128) mindeng dianggo ogé pikeun leuwih sering dipake tinimbang learning.
c) Perbaikan Iteratif: DPO tiasa diterapkeun sacara iteratif:
- Ngalatih modél awal nganggo DPO
- Ngahasilkeun réspon énggal nganggo modél anu dilatih
- Kumpulkeun data preferensi anyar dina réspon ieu
- Latih deui nganggo set data anu dimekarkeun

Performance Optimasi Préferénsi langsung
Gambar ieu nunjukkeun kinerja LLM sapertos GPT-4 dibandingkeun sareng penilaian manusa dina sababaraha téknik pelatihan, kalebet Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT), sareng Proximal Policy Optimization (PPO). Tabél nembongkeun yén kaluaran GPT-4 beuki saluyu sareng kahoyong manusa, khususna dina tugas nyimpulkeun. Tingkat kasapukan antara GPT-4 sareng pamariksaan manusa nunjukkeun kamampuan modél pikeun ngahasilkeun kontén anu cocog sareng evaluator manusa, ampir sacaket sareng eusi buatan manusa.
Studi Kasus jeung Aplikasi
Pikeun ngagambarkeun efektivitas DPO, hayu urang tingali sababaraha aplikasi dunya nyata sareng sababaraha varianna:
- DPO Iteratif: Dimekarkeun ku Snorkel (2023), varian ieu ngagabungkeun tampikan sampling kalawan DPO, sangkan prosés Pilihan leuwih refined pikeun data latihan. Ku iterasi leuwih sababaraha rounds of preferensi sampling, model leuwih hadé bisa generalize sarta ulah overfitting kana preferensi ribut atawa bias.
- IPO (Optimasi Préferénsi Iterative): Diwanohkeun ku Azar dkk. (2023), IPO nambihan istilah regularisasi pikeun nyegah overfitting, anu mangrupikeun masalah umum dina optimasi dumasar-préferénsi. Ekstensi ieu ngamungkinkeun modél ngajaga kasaimbangan antara nuturkeun karesep sareng ngajaga kamampuan generalisasi.
- KTO (Optimasi Transfer Pangaweruh): A varian leuwih anyar ti Ethayarajh et al. (2023), KTO dispenses sareng karesep binér sadayana. Gantina, eta museurkeun kana mindahkeun pangaweruh tina model rujukan ka model kawijakan, optimizing pikeun alignment smoother tur leuwih konsisten jeung nilai manusa.
- Multi-Modal DPO pikeun Cross-Domain Learning ku Xu et al. (2024): Hiji pendekatan dimana DPO diterapkeun dina rupa-rupa modalitas-téks, gambar, jeung audio-demonstrating versatility dina aligning model jeung preferensi manusa sakuliah rupa-rupa tipe data. Panaliti ieu nyorot poténsi DPO dina nyiptakeun sistem AI anu langkung komprehensif anu sanggup nanganan tugas anu kompleks, multi-modal.











