
Sirdoonka Artificial
Xulashada Tooska ah ee Hagaajinta: Hage Dhamaystiran

Isku toosinta moodooyinka luqadaha waaweyn (LLMs) ee leh qiyamka aadanaha iyo dookhyada waa caqabad. Hababka dhaqanka, sida Xoojinta Barashada Jawaab celinta Aadanaha (RLHF), waxay jeexjeexeen dariiqa iyaga oo isku daraya agabyada aadanaha si loo nadiifiyo wax soo saarka moodeelka. Si kastaba ha ahaatee, RLHF waxay noqon kartaa mid adag oo kheyraad badan leh, una baahan awood xisaabeed oo la taaban karo iyo habaynta xogta. Xulashada tooska ah (DPO) waxa ay u soo ifbaxdaa qaab cusub oo la toosiyey, oo bixisa beddel hufan oo hababkan soo jireenka ah. Iyadoo la fududeynayo habka wanaajinta, DPO kaliya ma dhimeyso culeyska xisaabinta laakiin sidoo kale waxay kor u qaadaysaa awoodda moodeelka si uu dhaqso ula qabsado dookhyada aadanaha
Tilmaan-bixiyahan waxa aanu si qoto dheer ugu dhex milmi doonaa DPO, anagoo sahaminaya aasaaskeeda, hirgalintiisa, iyo codsiyadiisa la taaban karo.
Baahida Kala-doorbidista
Si loo fahmo DPO, waa muhiim in la fahmo sababta la waafajinta LLMs iyo dookhyada aadanaha ay muhiim u tahay. In kasta oo ay jiraan awoodahooda cajiibka ah, LLM-yada lagu tababaray xog-ururin ballaadhan ayaa mararka qaarkood soo saari kara wax-soo-saar aan ku habboonayn, eex, ama ku khaldan qiyamka aadanaha. Is-waafajintani waxay u muuqan kartaa siyaabo kala duwan:
- Soo saarista waxyaabo aan ammaan ahayn ama waxyeello leh
- Bixinta macluumaad aan sax ahayn ama marin habaabin ah
- Muujinta eexda ka jirta xogta tababarka
Si wax looga qabto arrimahan, cilmi-baarayaashu waxay soo saareen farsamooyin si ay u hagaajiyaan LLM-yada iyagoo isticmaalaya jawaab-celinta aadanaha. Habka ugu caansan ee kuwan waa RLHF.
Fahamka RLHF: Horudhaca DPO
Xoojinta Barashada Jawaab celinta Aadanaha (RLHF) ayaa ahayd habka loo socdo ee lagu waafajinayo LLM-yada iyo dookhyada aadanaha. Aynu kala jebinno habka RLHF si aan u fahanno kakankiisa:
a) Habaynta Wanaagsan ee La Korjoogo (SFT)Nidaamku wuxuu ku bilaabmayaa hagaajinta LLM horay loo tababaray oo ku saabsan kaydinta jawaabaha tayada sare leh. Talaabadani waxay ka caawisaa qaabka inuu soo saaro wax soo saar badan oo khuseeya oo isku xidhan oo loogu talagalay hawsha la beegsanayo.
b) Qaabaynta Abaalmarinta: Qaab abaalgud gaar ah ayaa loo tababbaray inuu saadaaliyo dookhyada aadanaha. Tani waxay ku lug leedahay:
- Abuurista lammaane jawaab celin ah oo loogu talagalay dardargelinta la bixiyay
- Inaad bani'aadamku qiimeeyaan jawaabta ay door bidaan
- Tababar qaab lagu saadaaliyo dookhyadan
c) Xoojinta WaxbarashadaLLM oo si fiican loo hagaajiyay ayaa markaa la sii wanaajiyay iyadoo la isticmaalayo xoojinta barashada. Qaabka abaalgudka wuxuu bixiyaa jawaab celin, hagaya LLM si ay u abuurto jawaabo la jaan qaada dookhyada aadanaha.
Waa kan Python pseudocode la fududeeyay si loo muujiyo habka RLHF:
Iyadoo waxtar leh, RLHF waxay leedahay cillado dhowr ah:
- Waxay u baahan tahay tababbarka iyo ilaalinta noocyo badan (SFT, moodeel abaal-marin, iyo moodal-RL-la hagaajiyay)
- Habka RL wuxuu noqon karaa mid aan degganayn oo xasaasi u ah cabbirrada sare
- Xisaab ahaan waa qaali, una baahan in badan oo hore iyo gadaal u maraan moodooyinka
Xaddidaadahan ayaa dhiirigeliyay raadinta beddelka fudud, waxtarka badan, taasoo horseeday horumarinta DPO.
Xulashada tooska ah: Fikradaha Muhiimka ah

Xulashada tooska ah https://arxiv.org/abs/2305.18290
Sawirkaani waxa uu ka soo horjeedaa laba hab oo kala duwan oo lagu waafajinayo wax soo saarka LLM iyo dookhyada aadanaha: Xoojinta Barashada Jawaab celinta Aadanaha (RLHF) iyo Xulashada Tooska ah (DPO). RLHF waxay ku tiirsan tahay moodal abaal-marin ah si ay u hagto siyaasadda qaabka luqadda iyada oo loo marayo wareegyo jawaab celin ah, halka DPO ay si toos ah u wanaajiso wax-soo-saarka moodeelka si ay ugu habboonaato jawaabaha ay door bidaan bini'aadamka iyadoo la adeegsanayo xogta doorbidida. Isbarbardhiggani wuxuu muujinayaa awoodaha iyo codsiyada suurtagalka ah ee hab kasta, iyada oo siinaya fikrado ku saabsan sida mustaqbalka LLMs loogu tababari karo si ay si wanaagsan ula jaanqaadaan filashooyinka aadanaha.
Fikradaha muhiimka ah ee ka dambeeya DPO:
a) Qaabaynta Abaalmarinta DaahsoonDPO waxay meesha ka saartaa baahida loo qabo nooc abaal-marineed oo gaar ah iyadoo ula dhaqmaysa qaabka luqadda lafteeda sidii shaqo abaal-marineed oo qarsoon.
b) Qaabaynta Siyaasada Ku SalaysanHalkii laga horumarin lahaa shaqada abaal-marinta, DPO waxay si toos ah u wanaajisaa siyaasadda (qaabka luqadda) si loo kordhiyo suurtogalnimada jawaabaha la door bidayo.
c) Xalka Foomka Xidhan: DPO waxa ay ka faa'iidaysataa aragti xisaabeed taas oo u ogolaanaysa qaab xidhan oo lagu xaliyo siyaasadda ugu fiican, iyada oo laga fogaanayo baahida loo qabo cusboonaysiinta RL.
Dhaqangelinta DPO: Socod Sharci oo Dhaqan ah
Sawirka hoose waxa uu tusayaa qayb yar oo kood ah oo fulinaysa shaqada khasaaraha DPO iyadoo la isticmaalayo PyTorch. Shaqadani waxay door muhiim ah ka ciyaartaa sifaynta sida moodooyinka luqaddu u kala horraysiiyaan wax soo saarka iyadoo lagu saleynayo dookhyada aadanaha. Halkan waxaa ah kala qaybinta qaybaha muhiimka ah:
- Saxeexa Shaqada: The
dpo_lossShaqadu waxay qaadataa dhowr cabir oo ay ku jiraan ixtimaalka log-ka siyaasada (pi_logps), tusaalaha tixraaca ixtimaalka log (ref_logps), iyo tusmooyinka ka tarjumaya dhammaystirka la doorbiday iyo kuwa aan la jeclayn (yw_idxs,yl_idxs). Intaa waxaa dheer, abetahalbeeggu wuxuu xakameynayaa xoogga ciqaabta KL. - Log Soo saaridda itimaalkaKoodhku waxa uu ka soo saarayaa itimaalka log ee la door bidayo iyo dhamaystirka aan la jeclayn ee siyaasada iyo moodooyinka tixraaca.
- Xisaabinta Ratio LogFarqiga udhaxeeya itimaalka logu ee dhamaystirka la door bidayo iyo kuwa aan la jeclayn waxa loo xisaabiyaa siyaasada iyo moodooyinka tixraaca labadaba. Saamigani wuxuu muhiim u yahay go'aaminta jihada iyo baaxadda hagaajinta.
- Xisaabinta Khasaaraha iyo AbaalmarintaKhasaaraha waxaa lagu xisaabiyaa iyadoo la isticmaalayo
logsigmoidshaqada, halka abaal-marinnada lagu go'aamiyo iyada oo la cabbirayo farqiga u dhexeeya siyaasadda iyo log tix-raacida itimaalka bybeta.

Shaqada luminta DPO adoo isticmaalaya PyTorch
Aan u dhex galno xisaabta ka danbaysa DPO si aan u fahanno sida loo gaaro yoolalkan.
Xisaabta DPO
DPO waa dib-u-habayn xariif ah oo lagu sameeyo dhibaatada waxbarashada doorbidida. Waa kan tallaabo-tallaabo u-kala-saar:
a) Goobta laga bilaabayo: Kordhinta Abaalmarinta KL-kooban
Ujeeddada asalka ah ee RLHF waxaa lagu tilmaami karaa sidan:
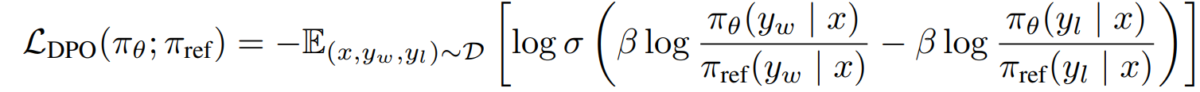
- πθ waa siyaasadda (qaabka luqadda) ee aan hagaajineyno
- r(x,y) waa shaqada abaalgudka
- πref waa siyaasad tixraac (badanaa qaabka hore ee SFT)
- β waxay xakameysaa xoogga kala duwanaanshaha KL
b) Foomka Siyaasadda ugu Fiican: Waxa la tusi karaa in siyaasadda ugu habboon ee ujeeddadani ay qaadato qaabkan:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Meesha Z(x) ay tahay caadi ka dhigid joogto ah.
c) Labada Siyaasad Abaalmarinta: Aragtida muhiimka ah ee DPO waa in ay muujiso shaqada abaal-marinta marka la eego siyaasadda ugu wanaagsan:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Moodelka Dookhyada Haddii aad doorbidayso inay raacdo qaabka Bradley-Terry, waxaynu ku muujin karnaa suurtogalnimada in y1 laga doorbido y2 sida:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Halka σ ay tahay shaqada saadka.
e) Ujeedada DPO Anaga oo ku beddelayna laba-siyaasadeedka abaal-marinta ee qaabka doorashada, waxaanu gaadhnay ujeeddada DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Ujeedadan waxaa lagu wanaajin karaa iyadoo la adeegsanayo farsamooyinka farcanka jaangooyada caadiga ah, iyada oo aan loo baahnayn algorithms RL.
Fulinta DPO
Hadda oo aan fahamnay aragtida ka dambeysa DPO, aan eegno sida loo hirgeliyo ficil ahaan. Waan isticmaali doonaa Python iyo PyTorch tusaale ahaan:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Caqabadaha iyo Tilmaamaha Mustaqbalka
Iyadoo DPO ay bixiso faa'iidooyin la taaban karo marka loo eego hababka RLHF ee dhaqameed, waxaa weli jira caqabado iyo meelo cilmi baaris dheeraad ah:
a) Miisaanka Modelka Waaweyn:
Sida moodooyinka luqaddu ay sii wadaan inay koraan cabbirkooda, si wax ku ool ah u adeegsiga DPO moodooyinka leh boqollaal balaayiin cabbirro ayaa weli ah caqabad furan. Cilmi-baarayaashu waxay sahamiyaan farsamooyinka sida:
- Hababka hagaajinta wax-ku-oolka ah (tusaale, LoRA, hagaajinta horgalayaasha)
- Hagaajinta tababbarka qaybsan
- Isbaaro tartiib tartiib ah iyo tababar sax ah oo isku dhafan
Tusaale ahaan isticmaalka LoRA ee DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Hawlo badan iyo La qabsiga Rasaas yar:
Horumarinta farsamooyinka DPO ee si wax ku ool ah ula qabsan kara hawlo cusub ama goobo leh xogta doorbidida xaddidan waa aag firfircoon oo cilmi baaris ah. Hababka la sahaminayo waxaa ka mid ah:
- Qaab dhismeedka barashada-meta-ga ee la qabsiga degdega ah
- Hagaajinta ganaax ku salaysan degdega ah ee DPO
- Ka beddel barashada moodooyinka doorbidida guud una beddel meelo gaar ah
c) Xakamaynta dookhyada madmadow ama is khilaafaya:
Xogta doorbidida-dhabta ah waxay inta badan ka kooban tahay madmadow ama isku dhacyo. Hagaajinta adkaanta DPO ee xogtan waa muhiim. Xalalka suurtagalka ah waxaa ka mid ah:
- Qaabaynta doorbidida suurtogalka ah
- Barashada firfircoon si loo xalliyo madmadowga
- Isku-darka doorbidida wakiillada badan
Tusaalaha qaabaynta doorashada ixtimaalka ah:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Isku-dubarid DPO iyo Farsamooyinka Is-waafajinta kale:
Isku-darka DPO iyo habab kale oo toosin ah waxay u horseedi kartaa habab aad u adag oo karti leh:
- Mabaadi'da AI ee dastuuriga ah ee ku qanacsanaanta xaddidan ee cad
- dooda iyo qaabaynta abaalgudka soo noqnoqda ee xulashada kakan
- Barashada xoojinta ee rogaal celiska ah si loo qiimeeyo hawlaha abaalgudka hoose
Tusaalaha isku darka DPO iyo AI dastuuriga ah:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Tixgelinta Wax-ku-oolka ah iyo Dhaqanka ugu Fiican
Markaad fulinayso DPO codsiyada adduunka dhabta ah, tixgeli talooyinka soo socda:
a) Tayada Data: Tayada xogta aad door bidayso waa muhiim. Hubi in xogtaada:
- Waxay dabooshaa noocyo kala duwan oo wax-soo-gelin ah iyo dabeecadaha la rabo
- Leh sharraxaadyo doorbidid joogto ah oo la isku halayn karo
- Waxay miisaamaysaa noocyada kala duwan ee dookhyada (tusaale, xaqiiqda, badbaadada, qaabka)
b) Dabaylaha Hyperparameter: Iyadoo DPO ay leedahay cabbirro-beegtiyo ka yar RLHF, hagaajintu weli waa muhiim:
- β (beta): Waxay xakameysaa isdhaafsiga u dhexeeya ku qanacsanaanta doorbidka iyo ka-duwanaanta tusaalaha tixraaca. Ka bilow qiyamka agagaarka 0.1-0.5.
- Heerka waxbarashada: Isticmaal heerka waxbarasho ka hooseeya hab-habaynta caadiga ah, sida caadiga ah inta u dhaxaysa 1e-6 ilaa 1e-5.
- Cabbirka dufcadda: Cabbirrada dufcadaha waaweyn (32-128) inta badan waxay si fiican ugu shaqeeyaan dookha waxbarashada.
c) Dib-u-habaynta is-beddelkaDPO waxaa lagu dabaqi karaa si isdaba joog ah:
- Ku tababar qaabka hore adoo isticmaalaya DPO
- Samee jawaabo cusub adoo isticmaalaya qaabka la tababaray
- Uruuri xogta doorashada cusub ee jawaabahaan
- Dib u tabobar adoo isticmaalaya xogta la balaariyay

Waxqabadka Tooska ah ee Xulashada Tooska ah
Sawirkaani wuxuu muujinayaa waxqabadka LLM-yada sida GPT-4 marka la barbardhigo xukunnada aadanaha ee farsamooyinka kala duwan ee tababarka, oo ay ku jiraan Xulashada Tooska ah (DPO), Korjoogteynta Fine-Tuning (SFT), iyo Horumarinta Siyaasadda Proximal (PPO). Shaxdu waxay daaha ka qaadaysaa in wax-soo-saarka GPT-4 ay si isa soo taraysa ula jaan qaadayaan dookhyada aadanaha, gaar ahaan hawlaha soo koobidda. Heerarka heshiiska u dhexeeya GPT-4 iyo dib-u-eegayaasha bini'aadamka ayaa muujinaya awoodda moodeelka ee soo saarista nuxurka la xidhiidha qiimeeyayaasha bini'aadamka, ku dhawaad si la mid ah sida waxyaabaha bani'aadamku soo saaray ay sameeyaan.
Daraasadaha Kiis iyo Codsiyada
Si loo muujiyo waxtarka DPO, aynu eegno qaar ka mid ah codsiyada adduunka dhabta ah iyo qaar ka mid ah noocyada ay:
- Isku dhafka DPO: Waxaa sameeyay Snorkel (2023), kala duwanaanshiyahani wuxuu isku daraa muunad diidmo iyo DPO, taasoo awood u siinaya hab doorasho oo la sifeeyay ee xogta tababarka. Marka lagu celceliyo wareegyo badan oo muunad dookh ah, moodeelku waxa uu si fiican u awoodayaa in uu si guud u gudbiyo oo uu iska ilaaliyo ku-habboonaanta dookhyada buuqa ama eexda leh.
- IPO (Kordhinta Dookhyada is-beddelka): Waxaa soo bandhigay Azar et al. (2023), IPO waxay ku daraysaa erey joogtayn ah si looga hortago xad dhaafka, taas oo ah arrin caadi ah oo ku salaysan doorbidida. Kordhintaani waxay u oggolaanaysaa moodooyinka inay ilaaliyaan dheelitirka u dhexeeya u hoggaansanaanta dookhyada iyo ilaalinta awoodaha guud.
- KTO (Kordhinta Wareejinta Aqoonta)Kala duwanaansho dhawaan ka timid Ethayarajh et al. (2023), KTO waxay bixisaa dookhyada binary gebi ahaanba. Taa beddelkeeda, waxa ay diiradda saartaa ka wareejinta aqoonta tusaalaha tixraaca una gudbiso qaabka siyaasadda, iyada oo wanaajinaysa si fudud oo joogto ah oo la jaan qaadi kara qiyamka aadanaha.
- Multi-Modal DPO ee Waxbarashada Isku-tallaabta-Domain by Xu et al. (2024): Habka DPO lagu dabaqo habab kala duwan - qoraal, muuqaal, iyo maqal - taasoo muujinaysa kala-duwanaanshaha ay ku habboon tahay moodooyinka leh dookhyada aadanaha ee noocyada kala duwan ee xogta. Cilmi-baadhistani waxay muujinaysaa awoodda DPO ee abuurista habab AI oo dhammaystiran oo awood u leh inay qabtaan hawlo isku dhafan, qaabab badan.











