
ປັນຍາປະດິດ
MIT: ການວັດແທກຄວາມລຳອຽງສື່ໃນສື່ຂ່າວໃຫຍ່ດ້ວຍການຮຽນຮູ້ເຄື່ອງຈັກ

ການສຶກສາຈາກ MIT ໄດ້ນໍາໃຊ້ເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກເພື່ອກໍານົດຄໍາທີ່ມີອະຄະຕິໃນທົ່ວປະມານ 100 ຂອງສໍານັກຂ່າວສານທີ່ໃຫຍ່ທີ່ສຸດແລະມີອິດທິພົນທີ່ສຸດໃນສະຫະລັດແລະຫຼາຍກວ່າ, ລວມທັງ 83 ຂອງສິ່ງພິມທີ່ມີອິດທິພົນທີ່ສຸດ. ມັນເປັນຄວາມພະຍາຍາມຄົ້ນຄ້ວາທີ່ສະແດງໃຫ້ເຫັນວິທີການໄປສູ່ລະບົບອັດຕະໂນມັດທີ່ສາມາດຈັດປະເພດລັກສະນະທາງດ້ານການເມືອງຂອງສິ່ງພິມໄດ້ໂດຍອັດຕະໂນມັດ, ແລະໃຫ້ຜູ້ອ່ານເຂົ້າໃຈຢ່າງເລິກເຊິ່ງກ່ຽວກັບຈຸດຢືນດ້ານຈັນຍາບັນຂອງຮ້ານຂາຍໃນຫົວຂໍ້ທີ່ເຂົາເຈົ້າອາດຈະມີຄວາມຮູ້ສຶກ passionate ກ່ຽວກັບ.
ການເຮັດວຽກເປັນຈຸດໃຈກາງກ່ຽວກັບວິທີທີ່ຫົວຂໍ້ຖືກແກ້ໄຂດ້ວຍປະໂຫຍກໂດຍສະເພາະ, ເຊັ່ນ: ຄົນເຂົ້າເມືອງທີ່ບໍ່ມີເອກະສານ | ຄົນເຂົ້າເມືອງຜິດກົດໝາຍ, fetus | ເດັກນ້ອຍທີ່ຍັງບໍ່ທັນເກີດ, ສາທິດ | ອະທິປະໄຕ.
ໂຄງການດັ່ງກ່າວໄດ້ນໍາໃຊ້ເຕັກນິກການປຸງແຕ່ງພາສາທໍາມະຊາດ (NLP) ເພື່ອສະກັດແລະຈັດປະເພດຕົວຢ່າງຂອງພາສາ 'ຄິດຄ່າທໍານຽມ' (ຕາມສົມມຸດຕິຖານທີ່ປາກົດຂື້ນວ່າຄໍາສັບ 'ເປັນກາງ' ຍັງເປັນຕົວແທນທາງດ້ານການເມືອງ) ເຂົ້າໄປໃນແຜນທີ່ກວ້າງທີ່ເປີດເຜີຍຄວາມລໍາອຽງຊ້າຍແລະຂວາ. ໃນທົ່ວສາມລ້ານບົດຄວາມຈາກປະມານ 100 ຂ່າວສານ, ສົ່ງຜົນໃຫ້ສາມາດນໍາທາງ ພູມສັນຖານອະຄະຕິ ຂອງສິ່ງພິມທີ່ເປັນຄໍາຖາມ.
ໄດ້ ເຈ້ຍ ມາຈາກ Samantha D'Alonzo ແລະ Max Tegmark ຢູ່ພະແນກຟີຊິກຂອງ MIT, ແລະສັງເກດເຫັນວ່າການລິເລີ່ມທີ່ຜ່ານມາຈໍານວນຫນຶ່ງກ່ຽວກັບ 'ການກວດສອບຄວາມຈິງ', ຫລັງຈາກມີເລື່ອງຂີ້ຕົວະ 'ຂ່າວປອມ' ຈໍານວນຫລາຍ, ສາມາດເປັນ. ຕີລາຄາວ່າເປັນບໍ່ສັດຊື່ ແລະຮັບໃຊ້ສາເຫດຂອງຜົນປະໂຫຍດໂດຍສະເພາະ. ໂຄງການດັ່ງກ່າວແມ່ນມີຈຸດປະສົງເພື່ອສະຫນອງວິທີການທີ່ມີຂໍ້ມູນຫຼາຍຂຶ້ນໃນການສຶກສາການນໍາໃຊ້ຄວາມລໍາອຽງແລະພາສາ 'ອິດທິພົນ' ໃນສະພາບການຂ່າວທີ່ເປັນກາງ.
ຂອບເຂດຂອງປະໂຫຍກຈາກຊ້າຍຫາຂວາ (ຕາມຕົວອັກສອນ) ທີ່ໄດ້ມາຈາກການສຶກສາ. ທີ່ມາ: https://arxiv.org/pdf/2109.00024.pdf
ການປະມວນຜົນ NLP
ຂໍ້ມູນແຫຼ່ງຂໍ້ມູນຈາກການສຶກສາແມ່ນໄດ້ມາຈາກແຫຼ່ງເປີດ ຖານຂໍ້ມູນ Newspaper3Kແລະ ລວມມີ 3,078,624 ບົດທີ່ໄດ້ມາຈາກ 100 ແຫຼ່ງຂ່າວຂອງສື່ມວນຊົນ, ໃນນັ້ນມີໜັງສືພິມ 83 ສະບັບ. ຫນັງສືພິມໄດ້ຖືກຄັດເລືອກບົນພື້ນຖານຂອງການເຂົ້າເຖິງຂອງເຂົາເຈົ້າ, ໃນຂະນະທີ່ແຫຼ່ງສື່ມວນຊົນອອນໄລນ໌ຍັງລວມເອົາບົດຄວາມຈາກເວັບໄຊທ໌ວິເຄາະຂ່າວທະຫານ ປ້ອງກັນຫນຶ່ງ, ແລະ ວິທະຍາສາດ.
ແຫຼ່ງຂໍ້ມູນທີ່ໃຊ້ໃນການສຶກສາ.
ເອກະສານລາຍງານວ່າຂໍ້ຄວາມທີ່ດາວໂຫລດມາແມ່ນ "ຫນ້ອຍທີ່ສຸດ" ກ່ອນທີ່ຈະດໍາເນີນການ. ຄໍາເວົ້າໂດຍກົງໄດ້ຖືກລົບລ້າງ, ນັບຕັ້ງແຕ່ການສຶກສາມີຄວາມສົນໃຈໃນພາສາທີ່ເລືອກໂດຍນັກຂ່າວ (ເຖິງແມ່ນວ່າການເລືອກຄໍາອ້າງອີງແມ່ນຢູ່ໃນຕົວຂອງມັນເອງ. ຂົງເຂດການສຶກສາທີ່ຫນ້າສົນໃຈ).
ການສະກົດຄໍາຂອງອັງກິດໄດ້ຖືກປ່ຽນເປັນພາສາອາເມລິກາເພື່ອມາດຕະຖານຖານຂໍ້ມູນ, ເຄື່ອງຫມາຍວັກຕອນທັງຫມົດຖືກໂຍກຍ້າຍອອກ, ແລະທັງຫມົດຍົກເວັ້ນຕົວເລກຕາມລໍາດັບ. ການໃຊ້ຕົວພິມໃຫຍ່ຂອງປະໂຫຍກເບື້ອງຕົ້ນຖືກປ່ຽນເປັນຕົວພິມນ້ອຍ, ແຕ່ຕົວພິມໃຫຍ່ອື່ນໆທັງໝົດຍັງຄົງຢູ່.
100,000 ປະໂຫຍກ ທຳ ອິດທີ່ພົບເລື້ອຍທີ່ສຸດໄດ້ຖືກລະບຸ, ແລະສຸດທ້າຍຖືກຈັດອັນດັບ, ລ້າງແລະລວມເຂົ້າໃນບັນຊີລາຍຊື່ປະໂຫຍກ. ພາສາທີ່ຊ້ຳຊ້ອນທັງໝົດທີ່ສາມາດລະບຸໄດ້ (ເຊັ່ນ: 'ແບ່ງປັນບົດຄວາມນີ້' ແລະ 'ບົດຄວາມທີ່ເຜີຍແຜ່ໃໝ່') ກໍ່ຖືກລຶບຄືກັນ. ການປ່ຽນແປງໃນທົ່ວປະໂຫຍກທີ່ຄືກັນ (ເຊັ່ນ: 'ເຕັກໂນໂລຊີໃຫຍ່' ແລະ 'ເຕັກໂນໂລຊີໃຫຍ່', 'ຄວາມປອດໄພທາງອິນເຕີເນັດ' ແລະ 'ຄວາມປອດໄພທາງໄຊເບີ') ໄດ້ມາດຕະຖານ.
'ເກັບໝາກນັດ'
ການທົດສອບເບື້ອງຕົ້ນແມ່ນກ່ຽວກັບຫົວຂໍ້ 'Black life matter', ແລະສາມາດແນມເບິ່ງຄວາມລໍາອຽງຂອງປະໂຫຍກແລະຄໍາສັບຄ້າຍຄືກັນໃນທົ່ວຂໍ້ມູນ.
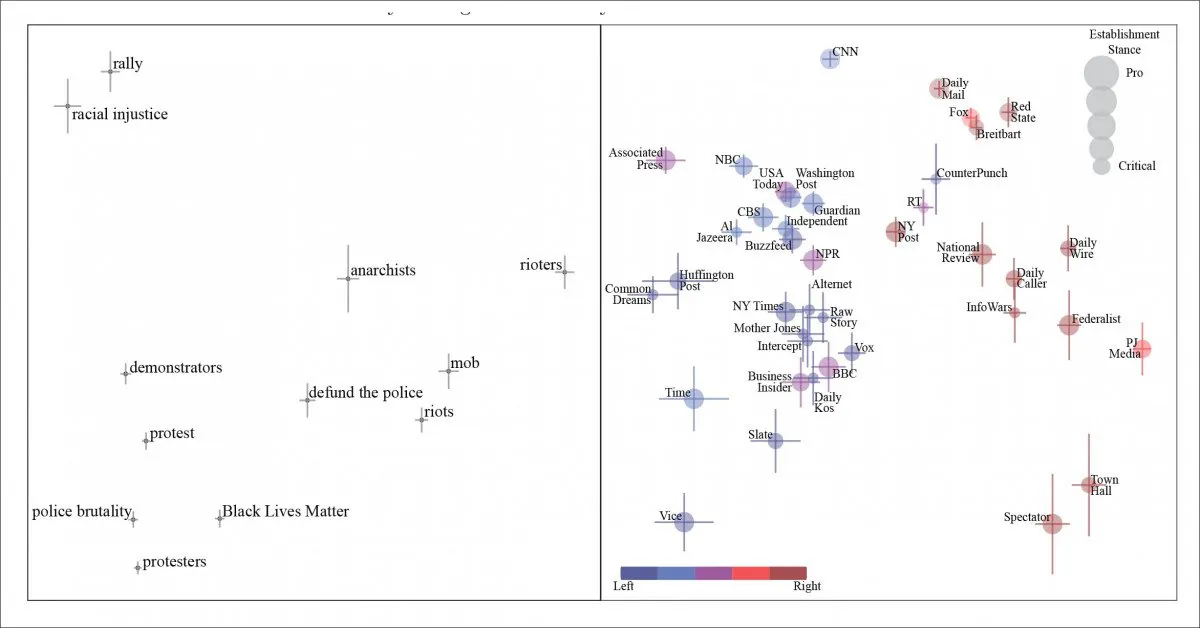
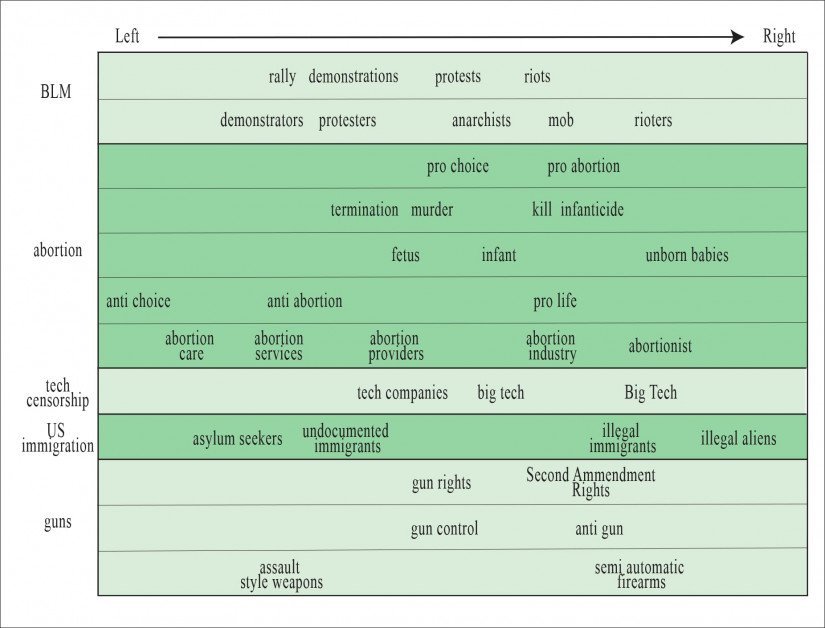
ອົງປະກອບຫຼັກການທົ່ວໄປສໍາລັບບົດຄວາມກ່ຽວກັບ Black Lives Matter (BLM). ພວກເຮົາເຫັນຄົນທີ່ເຂົ້າຮ່ວມການກະທຳທາງແພ່ງມີລັກສະນະເປັນຕົວລະຄອນ ແລະຕົວເລກຈາກຊ້າຍໄປຂວາ, ໃນຖານະຜູ້ປະທ້ວງ, ນິກາຍທິປະໄຕ ແລະ, ໃນຕອນທ້າຍຂວາສຸດຂອງສະເປກ, ເປັນ 'ຜູ້ກໍ່ຄວາມວຸ້ນວາຍ'. ຫນັງສືພິມທີ່ມາຂອງປະໂຫຍກແມ່ນເປັນຕົວແທນຢູ່ໃນກະດານຂວາມື.
ໃນຂະນະທີ່ 'ພວກປະທ້ວງ' ຂ້າມຈາກ 'ອະນາທິປະໄຕ' ໄປເປັນ 'ພວກກໍ່ຄວາມວຸ້ນວາຍ' ໃນຂະນະທີ່ພວກເຮົາເລື່ອນໄປຕາມຈຸດຢືນທາງດ້ານການເມືອງຂອງທາງອອກໃນຄຳຖາມ, ເອກະສານໃຫ້ຂໍ້ສັງເກດວ່າ ທ່າທີການສະກັດ ແລະ ວິເຄາະຂອງ NLP ແມ່ນຖືກຂັດຂວາງໂດຍການປະຕິບັດຂອງ 'ການລັກລອບ' - ບ່ອນທີ່ສື່ມວນຊົນ. ຈະອ້າງເຖິງປະໂຫຍກທີ່ເຫັນວ່າຖືກຕ້ອງໂດຍພາກສ່ວນທາງດ້ານການເມືອງທີ່ແຕກຕ່າງກັນຂອງສັງຄົມ, ແລະສາມາດ (ປາກົດຂື້ນ) ອີງໃສ່ຜູ້ອ່ານຂອງມັນເພື່ອເບິ່ງປະໂຫຍກໃນທາງລົບ. ເອກະສານອ້າງເຖິງ 'ປ້ອງກັນຕໍາຫຼວດ' ເປັນຕົວຢ່າງຂອງເລື່ອງນີ້.
ຕາມທໍາມະຊາດ, ນີ້ຫມາຍຄວາມວ່າປະໂຫຍກທີ່ 'ແນມຊ້າຍ' ປາກົດຢູ່ໃນສະພາບການທາງດ້ານຂວາ, ແລະເປັນຕົວແທນຂອງສິ່ງທ້າທາຍທີ່ຜິດປົກກະຕິສໍາລັບລະບົບ NLP ທີ່ອີງໃສ່ປະໂຫຍກທີ່ຖືກດັດແປງເພື່ອເຮັດຫນ້າທີ່ເປັນຕົວຊີ້ບອກທາງດ້ານການເມືອງ.
ປະໂຫຍກດັ່ງກ່າວແມ່ນ 'bi-valent' [SIC] , ໃນຂະນະທີ່ບາງປະໂຫຍກອື່ນມີຄວາມໝາຍທາງລົບທົ່ວໄປ (ເຊັ່ນ: 'ການຂ້າເດັກນ້ອຍ') ທີ່ພວກມັນຖືກສະແດງເປັນທາງລົບຢູ່ສະເໝີໃນຂອບເຂດຂອງຮ້ານຂາຍຕ່າງໆ.
ການຄົ້ນຄວ້າຍັງເປີດເຜີຍແຜນທີ່ທີ່ຄ້າຍຄືກັນສໍາລັບຫົວຂໍ້ 'ຮ້ອນ' ເຊັ່ນການເອົາລູກອອກ, ການເຊັນເຊີເຕັກໂນໂລຢີ, ການເຂົ້າເມືອງຂອງສະຫະລັດແລະການຄວບຄຸມປືນ.
Hobby Horses
ມີການໂຕ້ແຍ້ງທາງດ້ານການເມືອງທີ່ແນ່ນອນຢູ່ໃນບັນດາສື່ມວນຊົນທີ່ບໍ່ໄດ້ແບ່ງອອກຕາມຄາດຫມາຍໃນລັກສະນະນີ້, ເຊັ່ນຫົວຂໍ້ຂອງການໃຊ້ຈ່າຍທາງທະຫານ. ເອກະສານດັ່ງກ່າວໄດ້ພົບເຫັນວ່າ CNN 'ເອື່ອຍຊ້າຍ' ສິ້ນສຸດລົງຕໍ່ໄປກັບການທົບທວນແຫ່ງຊາດທີ່ເນີ້ງຂວາແລະ Fox News ກ່ຽວກັບເລື່ອງນີ້.
ໂດຍທົ່ວໄປ, ແນວໃດກໍ່ຕາມ, ຈຸດຢືນທາງດ້ານການເມືອງສາມາດຖືກກໍານົດໂດຍປະໂຫຍກອື່ນໆ, ເຊັ່ນວ່າມັກຄໍາວ່າ 'ການທະຫານ - ອຸດສາຫະກໍາສະລັບສັບຊ້ອນ' ຫຼາຍກວ່າ 'ອຸດສາຫະກໍາປ້ອງກັນປະເທດ' ທີ່ມີຂວາຫຼາຍ. ຜົນໄດ້ຮັບສະແດງໃຫ້ເຫັນວ່າອະດີດໄດ້ຖືກນໍາໃຊ້ໂດຍຮ້ານຂາຍເຄື່ອງທີ່ສໍາຄັນເຊັ່ນ: Canary ແລະ ອາເມລິກາອະນຸລັກ, ໃນຂະນະທີ່ອັນສຸດທ້າຍແມ່ນໃຊ້ເລື້ອຍໆໂດຍ Fox ແລະ CNN.
ການຄົ້ນຄວ້າສ້າງຄວາມຄືບຫນ້າອື່ນໆຈໍານວນຫນຶ່ງຈາກການສ້າງຕັ້ງທີ່ສໍາຄັນກັບພາສາສົ່ງເສີມການສ້າງຕັ້ງ, ລວມທັງ gamut ຈາກ 'shot dead' ກັບ passive ຫຼາຍ 'ການຂ້າຂອງ'; 'ນັກໂທດນັກໂທດ' ເຖິງ 'ຜູ້ຖືກຄຸມຂັງ'; ແລະ 'ຜູ້ຜະລິດນໍ້າມັນ' ກັບ 'ນໍ້າມັນໃຫຍ່'.
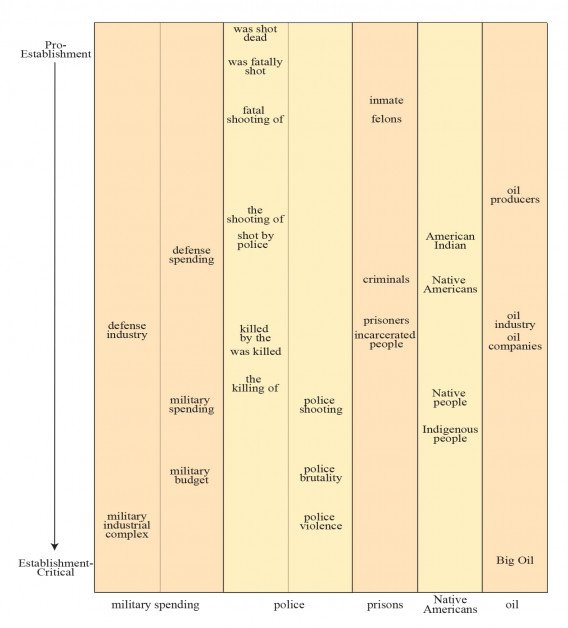
ຄຳສັບຄ້າຍຄືກັນກັບຄວາມລຳອຽງໃນການຈັດຕັ້ງ, ເທິງຫາລຸ່ມສຸດ.
ການຄົ້ນຄວ້າຮັບຮູ້ວ່າຮ້ານຈະ 'swing ຫ່າງ' ຈາກຈຸດຢືນທາງດ້ານການເມືອງຂອງເຂົາເຈົ້າ, ໃນລະດັບພາສາ (ເຊັ່ນ: ການໃຊ້ປະໂຫຍກສອງຢ່າງ), ຫຼືສໍາລັບແຮງຈູງໃຈອື່ນໆ. ສໍາລັບຕົວຢ່າງ, ຫນັງສືອັງກິດປີກຂວາ The Spectator, ສ້າງຕັ້ງຂຶ້ນໃນ 1828, ເລື້ອຍໆແລະເປັນຄູຊັດເຈນມີອົງປະກອບຄວາມຄິດຂອງປີກຊ້າຍທີ່ແຕກແຍກຕໍ່ກັບກະແສທາງດ້ານການເມືອງທົ່ວໄປຂອງກະແສເນື້ອຫາຂອງມັນ. ບໍ່ວ່າຈະເປັນການລາຍງານແບບບໍ່ລຳອຽງ ຫຼືເຮັດໃຫ້ຜູ້ອ່ານຫຼັກຂອງຕົນເປັນຊ່ວງໄລຍະໄປສູ່ການສັນຈອນທີ່ສ້າງຄຳເຫັນ-ພະຍຸແມ່ນເປັນເລື່ອງຂອງການຄາດເດົາ – ແລະບໍ່ແມ່ນກໍລະນີທີ່ງ່າຍສຳລັບລະບົບການຮຽນຮູ້ເຄື່ອງຈັກທີ່ຊອກຫາໂທເຄັນທີ່ຊັດເຈນ ແລະສອດຄ່ອງ.
ເຫຼົ່ານີ້ ' hobby horses ' ແລະການນໍາໃຊ້ທີ່ບໍ່ຊັດເຈນຂອງທັດສະນະ 'jarring ' ໃນບັນດາອົງການຈັດຕັ້ງຂ່າວສ່ວນບຸກຄົນໄດ້ສັບສົນບາງແຜນທີ່ຊ້າຍຂວາທີ່ການຄົ້ນຄວ້າສະເຫນີໃນທີ່ສຸດ, ເຖິງແມ່ນວ່າການສະຫນອງການຊີ້ບອກຢ່າງກວ້າງຂວາງຂອງການພົວພັນທາງດ້ານການເມືອງ.

ຄວາມສຳຄັນທີ່ຍຶດໄວ້
ເຖິງແມ່ນວ່າລົງວັນທີ 2 ເດືອນກັນຍາແລະຈັດພີມມາໃນທ້າຍເດືອນສິງຫາ 2021, ເອກະສານດັ່ງກ່າວໄດ້ຮັບການດຶງດູດຂ້ອນຂ້າງຫນ້ອຍ. ບາງສ່ວນນີ້ອາດຈະເປັນຍ້ອນວ່າການຄົ້ນຄວ້າທີ່ສໍາຄັນທີ່ມີຈຸດປະສົງໃນສື່ມວນຊົນຕົ້ນຕໍແມ່ນເບິ່ງຄືວ່າບໍ່ໄດ້ຮັບການກະຕືລືລົ້ນ; ແຕ່ມັນອາດຈະເປັນຍ້ອນຄວາມບໍ່ເຕັມໃຈຂອງຜູ້ຂຽນໃນການຜະລິດເສັ້ນສະແດງທີ່ຊັດເຈນແລະບໍ່ຊັດເຈນທີ່ຈັດວາງບ່ອນທີ່ສື່ສິ່ງພິມທີ່ມີອິດທິພົນແລະມີອໍານາດຢືນຢູ່ໃນບັນຫາຕ່າງໆ, ພ້ອມກັບມູນຄ່າລວມທີ່ຊີ້ໃຫ້ເຫັນເຖິງຂອບເຂດທີ່ສິ່ງພິມໄດ້ຫັນໄປທາງຊ້າຍຫຼືຂວາ. ໃນຄວາມເປັນຈິງ, ຜູ້ຂຽນເບິ່ງຄືວ່າຈະເຈັບປວດເພື່ອເຮັດໃຫ້ຜົນກະທົບ incendiary ທີ່ເປັນໄປໄດ້ຂອງຜົນໄດ້ຮັບ.
ເຊັ່ນດຽວກັນ, ຢ່າງກວ້າງຂວາງ ຂໍ້ມູນທີ່ເຜີຍແຜ່ ຈາກໂຄງການສະແດງໃຫ້ເຫັນການນັບຄວາມຖີ່ຂອງເຫດການຂອງຄໍາສັບຕ່າງໆ, ແຕ່ເບິ່ງຄືວ່າບໍ່ເປີດເຜີຍຊື່, ເຮັດໃຫ້ມັນຍາກທີ່ຈະໄດ້ຮັບຮູບພາບທີ່ຊັດເຈນກ່ຽວກັບຄວາມລໍາອຽງສື່ມວນຊົນໃນທົ່ວສິ່ງພິມທີ່ໄດ້ສຶກສາ. ໂດຍບໍ່ມີການປະຕິບັດໂຄງການໃນທາງໃດທາງຫນຶ່ງ, ນີ້ປ່ອຍໃຫ້ພຽງແຕ່ຕົວຢ່າງທີ່ເລືອກທີ່ນໍາສະເຫນີໃນເຈ້ຍ.
ຕໍ່ມາການສຶກສາລັກສະນະນີ້ອາດຈະເປັນປະໂຫຍດກວ່າຖ້າພວກເຂົາພິຈາລະນາບໍ່ພຽງແຕ່ປະໂຫຍກທີ່ໃຊ້ສໍາລັບຫົວຂໍ້, ແຕ່ວ່າຫົວຂໍ້ແມ່ນກວມເອົາທັງຫມົດ, ນັບຕັ້ງແຕ່. ຄວາມງຽບເວົ້າປະລິມານ, ແລະມີລັກສະນະທາງດ້ານການເມືອງທີ່ແຕກຕ່າງກັນໃນຕົວມັນເອງທີ່ມັກຈະເວົ້າເຖິງຫຼາຍກ່ວາພຽງແຕ່ຂໍ້ຈໍາກັດດ້ານງົບປະມານຫຼືປັດໃຈປະຕິບັດອື່ນໆທີ່ອາດຈະແຈ້ງການຄັດເລືອກຂ່າວ.
ຢ່າງໃດກໍຕາມ, ການສຶກສາຂອງ MIT ເບິ່ງຄືວ່າເປັນປະເພດທີ່ໃຫຍ່ທີ່ສຸດຈົນເຖິງປະຈຸບັນ, ແລະສາມາດສ້າງກອບສໍາລັບລະບົບການຈັດປະເພດໃນອະນາຄົດ, ແລະແມ້ກະທັ້ງເຕັກໂນໂລຢີຂັ້ນສອງເຊັ່ນ plug-ins ຂອງຕົວທ່ອງເວັບທີ່ອາດຈະເຕືອນຜູ້ອ່ານແບບປົກກະຕິກ່ຽວກັບສີທາງດ້ານການເມືອງຂອງສິ່ງພິມທີ່ພວກເຂົາເປັນ. ກຳລັງອ່ານຢູ່.
ຟອງ, ຄວາມລໍາອຽງ ແລະ Blowback
ນອກຈາກນັ້ນ, ມັນຈະຕ້ອງພິຈາລະນາວ່າລະບົບດັ່ງກ່າວຈະເພີ່ມເຕີມຫນຶ່ງໃນລັກສະນະທີ່ຂັດແຍ້ງທີ່ສຸດຂອງລະບົບຄໍາແນະນໍາ algorithmic - ແນວໂນ້ມທີ່ຈະນໍາຜູ້ຊົມໄປສູ່ສະພາບແວດລ້ອມທີ່ພວກເຂົາບໍ່ເຄີຍເຫັນທັດສະນະທີ່ກົງກັນຂ້າມຫຼືທ້າທາຍ, ເຊິ່ງມີແນວໂນ້ມທີ່ຈະດຶງຂໍ້ມູນໃຫມ່. ຈຸດຢືນຂອງຜູ້ອ່ານກ່ຽວກັບບັນຫາຫຼັກ.
ບໍ່ວ່າຈະເປັນ ຫຼື ບໍ່ ຟອງເນື້ອໃນ ແມ່ນ 'ສະພາບແວດລ້ອມທີ່ປອດໄພ', ເປັນອຸປະສັກຕໍ່ການຂະຫຍາຍຕົວທາງປັນຍາ, ຫຼືການປົກປ້ອງການເຜີຍແຜ່ບາງສ່ວນ, ເປັນການຕັດສິນມູນຄ່າ - ເປັນປັດຊະຍາທີ່ຍາກທີ່ຈະເຂົ້າຫາຈາກຈຸດຢືນທາງສະຖິຕິຂອງກົນໄກ, ສະຖິຕິຂອງລະບົບການຮຽນຮູ້ເຄື່ອງຈັກ.
ຍິ່ງໄປກວ່ານັ້ນ, ຍ້ອນວ່າການສຶກສາຂອງ MIT ໄດ້ເຈັບປວດເພື່ອໃຫ້ຂໍ້ມູນກໍານົດຜົນໄດ້ຮັບ, ການຈັດປະເພດຂອງມູນຄ່າທາງດ້ານການເມືອງຂອງປະໂຫຍກແມ່ນເປັນປະເພດການຕັດສິນມູນຄ່າ, ແລະສິ່ງທີ່ບໍ່ສາມາດທົນກັບຄວາມສາມາດຂອງພາສາໄດ້ຢ່າງງ່າຍດາຍ. ແປງໃໝ່ ເນື້ອໃນທີ່ເປັນພິດ ຫຼືການຖົກຖຽງກັນໃນປະໂຫຍກໃໝ່ທີ່ບໍ່ມີຢູ່ໃນປຶ້ມຄູ່ມື, ກົດລະບຽບຂອງເວທີສົນທະນາ ຫຼືຖານຂໍ້ມູນການຝຶກອົບຮົມ.
ຖ້າການເຂົ້າລະຫັດປະເພດນີ້ຖືກຝັງຢູ່ໃນລະບົບອອນໄລນ໌ທີ່ນິຍົມ, ມັນເບິ່ງຄືວ່າຄວາມພະຍາຍາມຢ່າງຕໍ່ເນື່ອງເພື່ອວາງແຜນອຸນຫະພູມດ້ານຈັນຍາບັນແລະທາງດ້ານການເມືອງຂອງບັນດາຂ່າວໃຫຍ່ສາມາດພັດທະນາໄປສູ່ສົງຄາມເຢັນລະຫວ່າງຄວາມສາມາດຂອງ AI ທີ່ຈະເຂົ້າໃຈຄວາມລໍາອຽງແລະຄວາມສາມາດຂອງຜູ້ເຜີຍແຜ່. ສະແດງຈຸດຢືນຂອງພວກເຂົາໃນສະໄຕລ໌ທີ່ພັດທະນາຂຶ້ນທີ່ອອກແບບມາເພື່ອພັດທະນາຄວາມເຂົ້າໃຈຂອງການຮຽນຮູ້ເຄື່ອງຈັກກ່ຽວກັບຄວາມໝາຍທາງຄວາມໝາຍ.
14/09/21 – 1.41 GMT+2 – ປ່ຽນ '100 ໜັງສືພິມ' ເປັນ '100 ໜັງສືພິມ'
4:58 ໂມງແລງ - ການແກ້ໄຂເອກະສານອ້າງອີງເພື່ອປະກອບມີ Samantha D'Alonzo, ແລະການແກ້ໄຂທີ່ກ່ຽວຂ້ອງ.















