
ປັນຍາປະດິດ
ການຮຽນຮູ້ເຄື່ອງຈັກທຽບກັບວິທະຍາສາດຂໍ້ມູນ: ຄວາມແຕກຕ່າງທີ່ ສຳ ຄັນ

ການຮຽນຮູ້ເຄື່ອງຈັກ (ML) ແລະວິທະຍາສາດຂໍ້ມູນແມ່ນສອງແນວຄວາມຄິດທີ່ແຍກຕ່າງຫາກທີ່ກ່ຽວຂ້ອງກັບພາກສະຫນາມຂອງປັນຍາປະດິດ (AI). ແນວຄວາມຄິດທັງສອງແມ່ນອີງໃສ່ຂໍ້ມູນເພື່ອປັບປຸງຜະລິດຕະພັນ, ບໍລິການ, ລະບົບ, ຂະບວນການຕັດສິນໃຈ, ແລະອື່ນໆອີກ. ທັງການຮຽນຮູ້ຂອງເຄື່ອງຈັກ ແລະວິທະຍາສາດຂໍ້ມູນແມ່ນໄດ້ຮັບການສະແຫວງຫາຢ່າງສູງໃນເສັ້ນທາງອາຊີບໃນໂລກທີ່ຂັບເຄື່ອນດ້ວຍຂໍ້ມູນໃນປະຈຸບັນຂອງພວກເຮົາ.
ທັງ ML ແລະວິທະຍາສາດຂໍ້ມູນຖືກນໍາໃຊ້ໂດຍນັກວິທະຍາສາດຂໍ້ມູນໃນການເຮັດວຽກຂອງພວກເຂົາ, ແລະພວກເຂົາຖືກຮັບຮອງເອົາໃນເກືອບທຸກອຸດສາຫະກໍາ. ສໍາລັບທຸກຄົນທີ່ກໍາລັງຊອກຫາການມີສ່ວນຮ່ວມໃນສາຂາເຫຼົ່ານີ້, ຫຼືຜູ້ນໍາທຸລະກິດທີ່ກໍາລັງຊອກຫາວິທີການຂັບເຄື່ອນ AI ເຂົ້າໄປໃນອົງການຂອງພວກເຂົາ, ຄວາມເຂົ້າໃຈສອງແນວຄວາມຄິດນີ້ແມ່ນສໍາຄັນ.
Machine Learning ແມ່ນຫຍັງ?
ການຮຽນຮູ້ເຄື່ອງຈັກມັກຈະຖືກໃຊ້ແລກປ່ຽນກັນກັບປັນຍາປະດິດ, ແຕ່ນັ້ນບໍ່ຖືກຕ້ອງ. ມັນເປັນເຕັກນິກແຍກຕ່າງຫາກແລະສາຂາຂອງ AI ທີ່ອີງໃສ່ສູດການຄິດໄລ່ເພື່ອສະກັດຂໍ້ມູນແລະຄາດຄະເນແນວໂນ້ມໃນອະນາຄົດ. ຊອບແວທີ່ມີໂຄງການແບບຈໍາລອງຊ່ວຍໃຫ້ວິສະວະກອນປະຕິບັດເຕັກນິກຕ່າງໆເຊັ່ນການວິເຄາະສະຖິຕິເພື່ອຊ່ວຍໃຫ້ເຂົ້າໃຈຮູບແບບພາຍໃນຊຸດຂໍ້ມູນໄດ້ດີຂຶ້ນ.
ການຮຽນຮູ້ຂອງເຄື່ອງຈັກແມ່ນສິ່ງທີ່ເຮັດໃຫ້ເຄື່ອງຈັກສາມາດຮຽນຮູ້ໄດ້ໂດຍບໍ່ໄດ້ຕັ້ງໂຄງການຢ່າງຊັດເຈນ, ນັ້ນແມ່ນເຫດຜົນທີ່ບໍລິສັດໃຫຍ່ແລະເວທີສື່ມວນຊົນສັງຄົມເຊັ່ນ Facebook, Twitter, Instagram ແລະ YouTube ໃຊ້ມັນເພື່ອຄາດຄະເນຄວາມສົນໃຈແລະແນະນໍາການບໍລິການ, ຜະລິດຕະພັນ, ແລະອື່ນໆ.
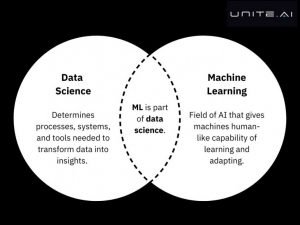
ໃນຖານະເປັນຊຸດຂອງເຄື່ອງມືແລະແນວຄວາມຄິດ, ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນສ່ວນຫນຶ່ງຂອງວິທະຍາສາດຂໍ້ມູນ. ດ້ວຍວ່າ, ການເຂົ້າເຖິງຂອງມັນໄກກວ່າພາກສະຫນາມ. ປົກກະຕິແລ້ວນັກວິທະຍາສາດຂໍ້ມູນແມ່ນອີງໃສ່ການຮຽນຮູ້ເຄື່ອງຈັກເພື່ອລວບລວມຂໍ້ມູນຢ່າງໄວວາແລະປັບປຸງການວິເຄາະແນວໂນ້ມ.
ເມື່ອເວົ້າເຖິງວິສະວະກອນການຮຽນຮູ້ເຄື່ອງຈັກ, ຜູ້ຊ່ຽວຊານເຫຼົ່ານີ້ຕ້ອງການທັກສະທີ່ກວ້າງຂວາງ, ເຊັ່ນ:
ຄວາມເຂົ້າໃຈຢ່າງເລິກເຊິ່ງກ່ຽວກັບສະຖິຕິ ແລະຄວາມເປັນໄປໄດ້
ຄວາມຊໍານານໃນວິທະຍາສາດຄອມພິວເຕີ
ວິສະວະກຳຊອບແວ ແລະການອອກແບບລະບົບ
ຄວາມຮູ້ການຂຽນໂປຼແກຼມ
ການສ້າງແບບຈໍາລອງຂໍ້ມູນແລະການວິເຄາະ

ວິທະຍາສາດຂໍ້ມູນແມ່ນຫຍັງ?
ວິທະຍາສາດຂໍ້ມູນແມ່ນການສຶກສາຂອງຂໍ້ມູນແລະວິທີການສະກັດຄວາມຫມາຍຈາກມັນໂດຍການນໍາໃຊ້ຊຸດຂອງວິທີການ, algorithms, ເຄື່ອງມື, ແລະລະບົບ. ທັງຫມົດເຫຼົ່ານີ້ເຮັດໃຫ້ຜູ້ຊ່ຽວຊານສາມາດສະກັດຄວາມເຂົ້າໃຈຈາກຂໍ້ມູນທີ່ມີໂຄງສ້າງແລະບໍ່ມີໂຄງສ້າງ. ປົກກະຕິແລ້ວນັກວິທະຍາສາດຂໍ້ມູນແມ່ນຮັບຜິດຊອບໃນການສຶກສາຂໍ້ມູນຈໍານວນຫຼວງຫຼາຍພາຍໃນບ່ອນເກັບມ້ຽນຂອງອົງການຈັດຕັ້ງ, ແລະການສຶກສາມັກຈະກ່ຽວຂ້ອງກັບເລື່ອງເນື້ອຫາແລະວິທີການນໍາໃຊ້ຂໍ້ມູນຂອງບໍລິສັດ.
ໂດຍການສຶກສາຂໍ້ມູນທີ່ມີໂຄງສ້າງຫຼືບໍ່ມີໂຄງສ້າງ, ນັກວິທະຍາສາດຂໍ້ມູນສາມາດສະກັດຄວາມເຂົ້າໃຈທີ່ມີຄຸນຄ່າກ່ຽວກັບທຸລະກິດຫຼືຮູບແບບການຕະຫຼາດ, ຊ່ວຍໃຫ້ທຸລະກິດສາມາດປະຕິບັດໄດ້ດີກວ່າຄູ່ແຂ່ງ.
ນັກວິທະຍາສາດຂໍ້ມູນນໍາໃຊ້ຄວາມຮູ້ຂອງເຂົາເຈົ້າກັບທຸລະກິດ, ລັດຖະບານ, ແລະອົງການຈັດຕັ້ງອື່ນໆເພື່ອເພີ່ມກໍາໄລ, ປະດິດສ້າງຜະລິດຕະພັນ, ແລະສ້າງໂຄງສ້າງພື້ນຖານແລະລະບົບສາທາລະນະທີ່ດີກວ່າ.
ສາຂາຂອງວິທະຍາສາດຂໍ້ມູນມີຄວາມກ້າວຫນ້າຢ່າງຫຼວງຫຼາຍຍ້ອນການຂະຫຍາຍຕົວຂອງໂທລະສັບສະຫຼາດແລະການຫັນເປັນດິຈິຕອນຂອງຫຼາຍພາກສ່ວນຂອງຊີວິດປະຈໍາວັນ, ເຊິ່ງໄດ້ເຮັດໃຫ້ຈໍານວນຂໍ້ມູນທີ່ບໍ່ຫນ້າເຊື່ອທີ່ມີໃຫ້ພວກເຮົາ. ວິທະຍາສາດຂໍ້ມູນຍັງໄດ້ຮັບຜົນກະທົບໂດຍກົດຫມາຍວ່າດ້ວຍ Moore, ຊຶ່ງຫມາຍເຖິງຄວາມຄິດວ່າຄອມພິວເຕີເພີ່ມຂຶ້ນຢ່າງຫຼວງຫຼາຍໃນຂະນະທີ່ການຫຼຸດລົງຂອງຄ່າໃຊ້ຈ່າຍໃນໄລຍະທີ່ຈະນໍາໄປສູ່ການມີຂະຫນາດກວ້າງຂອງພະລັງງານຄອມພິວເຕີລາຄາຖືກ. ວິທະຍາສາດຂໍ້ມູນເຊື່ອມຕໍ່ນະວັດຕະກໍາທັງສອງນີ້ຮ່ວມກັນ, ແລະໂດຍການລວມອົງປະກອບ, ວິທະຍາສາດຂໍ້ມູນສາມາດດຶງດູດຄວາມເຂົ້າໃຈຫຼາຍກ່ວາທີ່ເຄີຍມີຈາກຂໍ້ມູນ.
ຜູ້ຊ່ຽວຊານດ້ານວິທະຍາສາດຂໍ້ມູນຍັງຕ້ອງການທັກສະການຂຽນໂປລແກລມແລະການວິເຄາະຂໍ້ມູນຫຼາຍຢ່າງເຊັ່ນ:
ຄວາມເຂົ້າໃຈຢ່າງເລິກເຊິ່ງກ່ຽວກັບພາສາການຂຽນໂປຼແກຼມເຊັ່ນ Python
ຄວາມສາມາດໃນການເຮັດວຽກກັບຈໍານວນຂະຫນາດໃຫຍ່ຂອງຂໍ້ມູນທີ່ມີໂຄງສ້າງແລະບໍ່ມີໂຄງສ້າງ
ຄະນິດສາດ, ສະຖິຕິ, ຄວາມເປັນໄປໄດ້
ການເບິ່ງເຫັນຂໍ້ມູນ
ການວິເຄາະຂໍ້ມູນແລະການປຸງແຕ່ງສໍາລັບທຸລະກິດ
ຂັ້ນຕອນການຮຽນຮູ້ເຄື່ອງຈັກ ແລະແບບຈໍາລອງ
ການສື່ສານແລະການຮ່ວມມືຂອງທີມງານ

ຄວາມແຕກຕ່າງລະຫວ່າງການຮຽນຮູ້ເຄື່ອງຈັກ ແລະວິທະຍາສາດຂໍ້ມູນ
ຫຼັງຈາກກໍານົດວ່າແຕ່ລະແນວຄວາມຄິດແມ່ນຫຍັງ, ມັນເປັນສິ່ງສໍາຄັນທີ່ຈະສັງເກດຄວາມແຕກຕ່າງທີ່ສໍາຄັນລະຫວ່າງການຮຽນຮູ້ເຄື່ອງຈັກແລະວິທະຍາສາດຂໍ້ມູນ. ແນວຄວາມຄິດເຊັ່ນນີ້, ພ້ອມກັບສິ່ງອື່ນໆ ເຊັ່ນ: ປັນຍາປະດິດ ແລະ ການຮຽນຮູ້ເລິກເຊິ່ງ, ບາງຄັ້ງອາດສັບສົນ ແລະ ງ່າຍທີ່ຈະປະສົມເຂົ້າກັນ.
ວິທະຍາສາດຂໍ້ມູນແມ່ນສຸມໃສ່ການສຶກສາຂໍ້ມູນແລະວິທີການສະກັດຄວາມຫມາຍຈາກມັນ, ໃນຂະນະທີ່ການຮຽນຮູ້ເຄື່ອງຈັກກ່ຽວຂ້ອງກັບຄວາມເຂົ້າໃຈແລະການກໍ່ສ້າງວິທີການນໍາໃຊ້ຂໍ້ມູນເພື່ອປັບປຸງການປະຕິບັດແລະການຄາດຄະເນ.
ອີກວິທີຫນຶ່ງທີ່ວາງໄວ້ແມ່ນວ່າພາກສະຫນາມຂອງວິທະຍາສາດຂໍ້ມູນກໍານົດຂະບວນການ, ລະບົບ, ແລະເຄື່ອງມືທີ່ຈໍາເປັນເພື່ອຫັນປ່ຽນຂໍ້ມູນເຂົ້າໄປໃນຄວາມເຂົ້າໃຈ, ເຊິ່ງຫຼັງຈາກນັ້ນສາມາດຖືກນໍາໃຊ້ໃນທົ່ວອຸດສາຫະກໍາຕ່າງໆ. ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນພາກສະຫນາມຂອງປັນຍາປະດິດທີ່ຊ່ວຍໃຫ້ເຄື່ອງຈັກບັນລຸຄວາມສາມາດໃນການຮຽນຮູ້ແລະການປັບຕົວແບບຂອງມະນຸດໂດຍຜ່ານຕົວແບບສະຖິຕິແລະສູດການຄິດໄລ່.
ເຖິງແມ່ນວ່ານີ້ແມ່ນສອງແນວຄວາມຄິດທີ່ແຍກຕ່າງຫາກ, ມີການຊ້ອນກັນບາງຢ່າງ. ຕົວຈິງແລ້ວການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນສ່ວນຫນຶ່ງຂອງວິທະຍາສາດຂໍ້ມູນ, ແລະສູດການຄິດໄລ່ການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນທີ່ສົ່ງໂດຍວິທະຍາສາດຂໍ້ມູນ. ພວກເຂົາທັງສອງປະກອບມີທັກສະດຽວກັນບາງຢ່າງເຊັ່ນ: ຄະນິດສາດ, ສະຖິຕິ, ຄວາມເປັນໄປໄດ້, ແລະການຂຽນໂປຼແກຼມ.
ສິ່ງທ້າທາຍຂອງວິທະຍາສາດຂໍ້ມູນ ແລະ ML
ທັງວິທະຍາສາດຂໍ້ມູນ ແລະການຮຽນຮູ້ເຄື່ອງຈັກນຳສະເໜີຊຸດຂອງສິ່ງທ້າທາຍຂອງຕົນເອງ, ເຊິ່ງຍັງຊ່ວຍແຍກແນວຄວາມຄິດທັງສອງ.
ສິ່ງທ້າທາຍຕົ້ນຕໍຂອງການຮຽນຮູ້ເຄື່ອງຈັກລວມມີການຂາດຂໍ້ມູນຫຼືຄວາມຫຼາກຫຼາຍໃນຊຸດຂໍ້ມູນ, ເຊິ່ງເຮັດໃຫ້ມັນຍາກທີ່ຈະສະກັດຄວາມເຂົ້າໃຈທີ່ມີຄຸນຄ່າ. ເຄື່ອງຈັກບໍ່ສາມາດຮຽນຮູ້ໄດ້ຖ້າບໍ່ມີຂໍ້ມູນທີ່ມີຢູ່, ໃນຂະນະທີ່ຊຸດຂໍ້ມູນທີ່ຂາດຫາຍໄປເຮັດໃຫ້ມັນຍາກທີ່ຈະເຂົ້າໃຈຮູບແບບຕ່າງໆ. ສິ່ງທ້າທາຍອີກອັນໜຶ່ງຂອງການຮຽນຮູ້ຂອງເຄື່ອງຈັກແມ່ນມັນບໍ່ໜ້າຈະເປັນໄປໄດ້ວ່າ algorithm ສາມາດສະກັດຂໍ້ມູນໄດ້ເມື່ອບໍ່ມີ ຫຼື ມີການປ່ຽນແປງໜ້ອຍໜຶ່ງ.
ໃນເວລາທີ່ມັນມາກັບວິທະຍາສາດຂໍ້ມູນ, ສິ່ງທ້າທາຍຕົ້ນຕໍຂອງຕົນປະກອບມີຄວາມຕ້ອງການສໍາລັບຄວາມຫລາກຫລາຍຂອງຂໍ້ມູນແລະຂໍ້ມູນສໍາລັບການວິເຄາະທີ່ຖືກຕ້ອງ. ອີກອັນຫນຶ່ງແມ່ນວ່າຜົນໄດ້ຮັບວິທະຍາສາດຂໍ້ມູນແມ່ນບາງຄັ້ງບໍ່ຖືກນໍາໃຊ້ຢ່າງມີປະສິດທິພາບໂດຍຜູ້ຕັດສິນໃຈໃນທຸລະກິດ, ແລະແນວຄວາມຄິດສາມາດຍາກທີ່ຈະອະທິບາຍໃຫ້ທີມງານ. ມັນຍັງນໍາສະເຫນີບັນຫາຄວາມເປັນສ່ວນຕົວແລະຈັນຍາບັນຕ່າງໆ.
ຄໍາຮ້ອງສະຫມັກຂອງແຕ່ລະແນວຄວາມຄິດ
ໃນຂະນະທີ່ວິທະຍາສາດຂໍ້ມູນ ແລະການຮຽນຮູ້ເຄື່ອງຈັກມີການທັບຊ້ອນກັນເມື່ອເວົ້າເຖິງແອັບພລິເຄຊັນ, ພວກເຮົາສາມາດແຍກແຕ່ລະອັນໄດ້.
ນີ້ແມ່ນບາງຕົວຢ່າງຂອງຄໍາຮ້ອງສະຫມັກວິທະຍາສາດຂໍ້ມູນ:
- ຊອກຫາທາງອິນເຕີເນັດ: ການຄົ້ນຫາຂອງ Google ອີງໃສ່ວິທະຍາສາດຂໍ້ມູນເພື່ອຄົ້ນຫາຜົນໄດ້ຮັບສະເພາະໃນສ່ວນຫນຶ່ງຂອງວິນາທີ.
- ລະບົບການແນະນຳ: ວິທະຍາສາດຂໍ້ມູນແມ່ນກຸນແຈໃນການສ້າງລະບົບການແນະນໍາ.
- ການຮັບຮູ້ຮູບພາບ/ສຽງເວົ້າ: ລະບົບການຮັບຮູ້ສຽງເວົ້າເຊັ່ນ Siri ແລະ Alexa ອີງໃສ່ວິທະຍາສາດຂໍ້ມູນ, ເຊັ່ນດຽວກັນກັບລະບົບການຮັບຮູ້ຮູບພາບ.
- ເກມ: ໂລກຂອງເກມໃຊ້ເຕັກໂນໂລຊີວິທະຍາສາດຂໍ້ມູນເພື່ອເພີ່ມປະສົບການການຫຼິ້ນເກມ.
ນີ້ແມ່ນບາງຕົວຢ່າງຄໍາຮ້ອງສະຫມັກຂອງການຮຽນຮູ້ເຄື່ອງຈັກ:
- ການເງິນ: ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນຖືກນໍາໃຊ້ຢ່າງກວ້າງຂວາງໃນທົ່ວອຸດສາຫະກໍາການເງິນ, ໂດຍທະນາຄານອີງໃສ່ມັນເພື່ອກໍານົດຮູບແບບພາຍໃນຂໍ້ມູນແລະເພື່ອປ້ອງກັນການສໍ້ໂກງ.
- ອັດຕະໂນມັດ: ການຮຽນຮູ້ເຄື່ອງຈັກຊ່ວຍໃຫ້ວຽກງານອັດຕະໂນມັດພາຍໃນອຸດສາຫະກໍາຕ່າງໆ, ເຊັ່ນຫຸ່ນຍົນໃນໂຮງງານຜະລິດ.
- ລັດຖະບານ: ການຮຽນຮູ້ເຄື່ອງຈັກບໍ່ພຽງແຕ່ຖືກນໍາໃຊ້ໃນພາກເອກະຊົນ. ອົງການຈັດຕັ້ງຂອງລັດຖະບານນໍາໃຊ້ມັນໃນການຄຸ້ມຄອງຄວາມປອດໄພສາທາລະນະແລະສາທາລະນະ.
- ຮັກສາສຸຂະພາບ: ການຮຽນຮູ້ເຄື່ອງຈັກກໍາລັງລົບກວນອຸດສາຫະກໍາການດູແລສຸຂະພາບໃນຫຼາຍວິທີ. ມັນແມ່ນ ໜຶ່ງ ໃນອຸດສາຫະ ກຳ ທຳ ອິດທີ່ ນຳ ໃຊ້ການຮຽນຮູ້ເຄື່ອງຈັກດ້ວຍການກວດຫາຮູບພາບ.
ຖ້າທ່ານກໍາລັງຊອກຫາທັກສະບາງຢ່າງພາຍໃນຂົງເຂດເຫຼົ່ານີ້, ໃຫ້ແນ່ໃຈວ່າກວດເບິ່ງລາຍຊື່ການຢັ້ງຢືນທີ່ດີທີ່ສຸດຂອງພວກເຮົາສໍາລັບ ວິທະຍາສາດຂໍ້ມູນ ແລະ ການຮຽນຮູ້ເຄື່ອງຈັກ.















