
ປັນຍາປະດິດ
ຂໍ້ສະເໜີ LipSync3D ຂອງ Google ປັບປຸງການຊິ້ງຂໍ້ມູນການເຄື່ອນໄຫວປາກ 'Deepfaked'

A ການຮ່ວມມື ລະຫວ່າງນັກຄົ້ນຄວ້າ Google AI ແລະສະຖາບັນເຕັກໂນໂລຢີອິນເດຍ Kharagpur ສະເຫນີກອບໃຫມ່ເພື່ອສັງເຄາະຫົວເວົ້າຈາກເນື້ອຫາສຽງ. ໂຄງການດັ່ງກ່າວມີຈຸດປະສົງເພື່ອຜະລິດວິທີການເພີ່ມປະສິດທິພາບແລະສົມເຫດສົມຜົນເພື່ອສ້າງເນື້ອຫາວິດີໂອ 'ຫົວເວົ້າ' ຈາກສຽງ, ເພື່ອຈຸດປະສົງຂອງການຊິງຄ໌ການເຄື່ອນໄຫວປາກໄປຫາສຽງທີ່ມີສຽງຫຼືແປດ້ວຍເຄື່ອງຈັກ, ແລະສໍາລັບການນໍາໃຊ້ໃນຮູບແທນຕົວ, ໃນຄໍາຮ້ອງສະຫມັກການໂຕ້ຕອບ, ແລະອື່ນໆ. ສະພາບແວດລ້ອມໃນເວລາຈິງ.

ທີ່ມາ: https://www.youtube.com/watch?v=L1StbX9OznY
ຮູບແບບການຮຽນຮູ້ເຄື່ອງຈັກທີ່ໄດ້ຮັບການຝຶກອົບຮົມໃນຂະບວນການ - ເອີ້ນວ່າ LipSync3D - ຕ້ອງການພຽງແຕ່ວິດີໂອດຽວຂອງຕົວຕົນໃບຫນ້າເປົ້າຫມາຍເປັນຂໍ້ມູນປ້ອນຂໍ້ມູນ. ທໍ່ການກະກຽມຂໍ້ມູນໄດ້ແຍກການສະກັດເອົາເລຂາຄະນິດຂອງໃບໜ້າຈາກການປະເມີນແສງ ແລະລັກສະນະອື່ນໆຂອງວິດີໂອການປ້ອນຂໍ້ມູນ, ຊ່ວຍໃຫ້ການຝຶກອົບຮົມປະຫຍັດ ແລະສຸມໃສ່ຫຼາຍຂຶ້ນ.
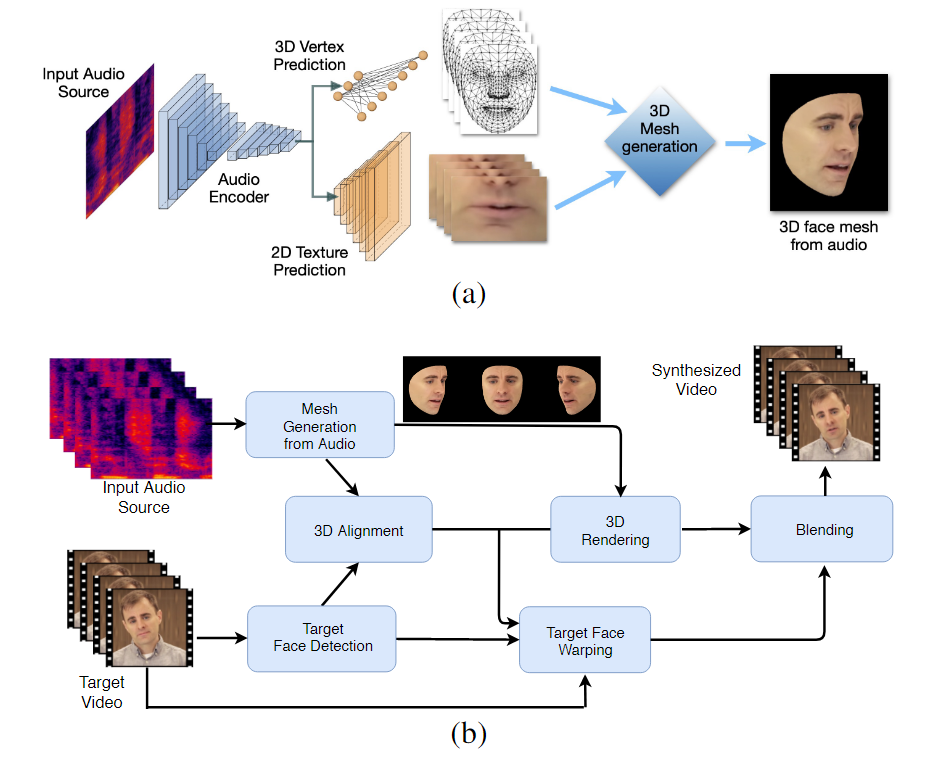
ຂັ້ນຕອນການເຮັດວຽກສອງຂັ້ນຕອນຂອງ LipSync3D. ຂ້າງເທິງ, ການຜະລິດໃບຫນ້າ 3D ທີ່ມີໂຄງສ້າງແບບເຄື່ອນໄຫວຈາກສຽງ 'ເປົ້າຫມາຍ'; ຂ້າງລຸ່ມນີ້, ການແຊກຕາຫນ່າງທີ່ສ້າງຂຶ້ນເຂົ້າໄປໃນວິດີໂອເປົ້າຫມາຍ.
ໃນຄວາມເປັນຈິງ, ການປະກອບສ່ວນທີ່ໂດດເດັ່ນທີ່ສຸດຂອງ LipSync3D ຕໍ່ກັບຮ່າງກາຍຂອງຄວາມພະຍາຍາມໃນການຄົ້ນຄວ້າໃນຂົງເຂດນີ້ອາດຈະເປັນສູດການເຮັດໃຫ້ແສງສະຫວ່າງເປັນປົກກະຕິ, ເຊິ່ງ decouples ການຝຶກອົບຮົມແລະການ illumination inference.

ການຖອດຂໍ້ມູນການສ່ອງແສງຈາກເລຂາຄະນິດທົ່ວໄປຊ່ວຍໃຫ້ LipSync3D ສາມາດຜະລິດຜົນການເຄື່ອນໄຫວຂອງປາກໄດ້ຕາມຄວາມເປັນຈິງຫຼາຍຂຶ້ນພາຍໃຕ້ເງື່ອນໄຂທີ່ທ້າທາຍ. ວິທີການອື່ນໆໃນຊຸມປີມໍ່ໆມານີ້ໄດ້ຈໍາກັດຕົວເອງກັບ 'ແກ້ໄຂ' ສະພາບແສງສະຫວ່າງທີ່ຈະບໍ່ເປີດເຜີຍຄວາມສາມາດທີ່ຈໍາກັດຫຼາຍຂຶ້ນໃນເລື່ອງນີ້.
ໃນລະຫວ່າງການປະມວນຜົນຂໍ້ມູນກອບຂໍ້ມູນເບື້ອງຕົ້ນ, ລະບົບຈະຕ້ອງກໍານົດແລະເອົາຈຸດທີ່ໂດດເດັ່ນ, ເພາະວ່າສິ່ງເຫຼົ່ານີ້ແມ່ນສະເພາະກັບສະພາບແສງສະຫວ່າງທີ່ວິດີໂອໄດ້ຖືກຖ່າຍ, ແລະຖ້າບໍ່ດັ່ງນັ້ນຈະແຊກແຊງຂະບວນການ relighting.

LipSync3D, ຕາມຊື່ຂອງມັນຊີ້ໃຫ້ເຫັນ, ບໍ່ໄດ້ປະຕິບັດການວິເຄາະພຽງແຕ່ pixels ລວງຂອງໃບຫນ້າທີ່ມັນປະເມີນ, ແຕ່ຢ່າງຈິງຈັງການນໍາໃຊ້ຈຸດຫມາຍປາຍທາງໃບຫນ້າທີ່ຖືກກໍານົດເພື່ອສ້າງຕາຫນ່າງແບບ CGI ທີ່ມີການເຄື່ອນໄຫວ, ພ້ອມກັບໂຄງສ້າງ 'unfolded' ທີ່ຖືກຫໍ່ຢູ່ອ້ອມຮອບພວກເຂົາໃນ CGI ແບບດັ້ງເດີມ. ທໍ່.

ສ້າງການປັບແຕ່ງປົກກະຕິໃນ LipSync3D. ຢູ່ເບື້ອງຊ້າຍແມ່ນກອບການປ້ອນຂໍ້ມູນແລະລັກສະນະທີ່ກວດພົບ; ຢູ່ເຄິ່ງກາງ, ເສັ້ນຕັ້ງປົກກະຕິຂອງການປະເມີນຜົນຕາຫນ່າງທີ່ຜະລິດ; ແລະທາງດ້ານຂວາ, atlas ໂຄງສ້າງທີ່ສອດຄ້ອງກັນ, ເຊິ່ງສະຫນອງຄວາມຈິງພື້ນຖານສໍາລັບການຄາດຄະເນໂຄງສ້າງ. ທີ່ມາ: https://arxiv.org/pdf/2106.04185.pdf
ນອກຈາກວິທີການ relighting ນະວະນິຍາຍ, ນັກຄົ້ນຄວ້າໄດ້ອ້າງວ່າ LipSync3D ສະເຫນີສາມປະດິດສ້າງຕົ້ນຕໍໃນການເຮັດວຽກທີ່ຜ່ານມາ: ການແຍກເລຂາຄະນິດ, ແສງສະຫວ່າງ, pose ແລະໂຄງສ້າງເຂົ້າໄປໃນສາຍນ້ໍາຂໍ້ມູນ discrete ໃນຊ່ອງປົກກະຕິ; ຮູບແບບການຄາດຄະເນໂຄງສ້າງແບບອັດຕະໂນມັດທີ່ສາມາດຝຶກໄດ້ຢ່າງງ່າຍດາຍທີ່ຜະລິດການສັງເຄາະວິດີໂອທີ່ສອດຄ່ອງຊົ່ວຄາວ; ແລະຄວາມເປັນຈິງເພີ່ມຂຶ້ນ, ຕາມການປະເມີນໂດຍການຈັດອັນດັບຂອງມະນຸດແລະຕົວຊີ້ວັດຈຸດປະສົງ.

ການແຍກລັກສະນະຕ່າງໆຂອງຮູບພາບໃບໜ້າຂອງວິດີໂອເຮັດໃຫ້ສາມາດຄວບຄຸມການສັງເຄາະວິດີໂອໄດ້ຫຼາຍຂຶ້ນ.
LipSync3D ສາມາດໄດ້ຮັບການເຄື່ອນໄຫວເລຂາຄະນິດຂອງປາກທີ່ເຫມາະສົມໂດຍກົງຈາກສຽງໂດຍການວິເຄາະ phonemes ແລະລັກສະນະອື່ນໆຂອງການປາກເວົ້າ, ແລະແປໃຫ້ເຂົາເຈົ້າເຂົ້າໄປໃນທີ່ຮູ້ຈັກຂອງກ້າມເນື້ອທີ່ສອດຄ້ອງກັນ poses ບໍລິເວນປາກ.

ຂະບວນການນີ້ໃຊ້ທໍ່ການຄາດເດົາຮ່ວມກັນ, ບ່ອນທີ່ເລຂາຄະນິດແລະໂຄງສ້າງທີ່ສົມມຸດຕິຖານມີຕົວເຂົ້າລະຫັດທີ່ອຸທິດຕົນໃນການຕັ້ງຄ່າຕົວເຂົ້າລະຫັດອັດຕະໂນມັດ, ແຕ່ແບ່ງປັນຕົວເຂົ້າລະຫັດສຽງກັບຄໍາເວົ້າທີ່ມີຈຸດປະສົງເພື່ອກໍານົດຮູບແບບ:

ການສັງເຄາະການເຄື່ອນໄຫວຂອງ labile ຂອງ LipSync3D ແມ່ນຍັງມີຈຸດປະສົງເພື່ອພະລັງງານຮູບແທນຕົວ CGI ທີ່ມີສະໄຕລ໌, ເຊິ່ງໃນຕົວຈິງແລ້ວແມ່ນພຽງແຕ່ປະເພດຂອງຕາຫນ່າງແລະຂໍ້ມູນໂຄງສ້າງດຽວກັນກັບຮູບພາບທີ່ແທ້ຈິງ:
ຮູບແທນຕົວ 3 ມິຕິທີ່ມີສະໄຕລ໌ມີການເຄື່ອນໄຫວຮິມຝີປາກທີ່ຂັບເຄື່ອນໃນເວລາຈິງໂດຍວິດີໂອລໍາໂພງຕົ້ນສະບັບ. ໃນສະຖານະການດັ່ງກ່າວ, ຜົນໄດ້ຮັບທີ່ດີທີ່ສຸດຈະໄດ້ຮັບໂດຍການຝຶກອົບຮົມສ່ວນບຸກຄົນ.
ນັກຄົ້ນຄວ້າຍັງຄາດວ່າຈະໃຊ້ avatars ດ້ວຍຄວາມຮູ້ສຶກທີ່ແທ້ຈິງກວ່າເລັກນ້ອຍ:
![]()
ເວລາການຝຶກອົບຮົມຕົວຢ່າງສໍາລັບວິດີໂອແມ່ນຕັ້ງແຕ່ 3-5 ຊົ່ວໂມງສໍາລັບວິດີໂອ 2-5 ນາທີ, ໃນທໍ່ທີ່ໃຊ້ TensorFlow, Python ແລະ C++ ໃນ GeForce GTX 1080. ກອງປະຊຸມການຝຶກອົບຮົມໄດ້ນໍາໃຊ້ຂະຫນາດ batch ຂອງ 128 ເຟຣມໃນໄລຍະ 500-1000. ແຕ່ລະຍຸກ, ໂດຍແຕ່ລະຍຸກສະແດງເຖິງການປະເມີນວິດີໂອທີ່ສົມບູນ.

ໄປສູ່ການຊິງຄ໌ຄືນໃໝ່ແບບເຄື່ອນໄຫວຂອງການເຄື່ອນໄຫວປາກ
ພາກສະຫນາມຂອງການ syncing ຮິມຝີປາກໃຫມ່ເພື່ອຮອງຮັບສຽງເພງໃຫມ່ໄດ້ຮັບຄວາມສົນໃຈຢ່າງຫຼວງຫຼາຍໃນການຄົ້ນຄວ້າວິໄສທັດຄອມພິວເຕີໃນສອງສາມປີຜ່ານມາ (ເບິ່ງຂ້າງລຸ່ມນີ້), ຢ່າງຫນ້ອຍເນື່ອງຈາກວ່າມັນເປັນຜົນມາຈາກການຂັດແຍ້ງ. ເຕັກໂນໂລຢີເລິກລັບ.
ໃນປີ 2017 ມະຫາວິທະຍາໄລວໍຊິງຕັນ ການຄົ້ນຄວ້ານໍາສະເຫນີ ມີຄວາມສາມາດຮຽນຮູ້ການຊິ້ງປາກຈາກສຽງ, ນໍາໃຊ້ມັນເພື່ອປ່ຽນການເຄື່ອນໄຫວປາກຂອງປະທານາທິບໍດີໂອບາມາ. ໃນປີ 2018; ສະຖາບັນ Max Planck ສໍາລັບຂໍ້ມູນຂ່າວສານນໍາພາ ການລິເລີ່ມການຄົ້ນຄວ້າອື່ນ ເພື່ອເປີດໃຊ້ຕົວຕົນ>ການຖ່າຍທອດວິດີໂອຕົວຕົນ, ດ້ວຍ lip synch a ຜົນຜະລິດຂອງຂະບວນການ; ແລະໃນເດືອນພຶດສະພາຂອງປີ 2021 AI startup FlawlessAI ໄດ້ເປີດເຜີຍເຕັກໂນໂລຊີ lip-sync TrueSync ຂອງຕົນ, ຢ່າງກວ້າງຂວາງ. ໄດ້ຮັບ ໃນຫນັງສືພິມເປັນຕົວເປີດໃຊ້ຂອງການປັບປຸງເຕັກໂນໂລຊີການຂະຫນານສໍາລັບການອອກຮູບເງົາທີ່ສໍາຄັນໃນທົ່ວພາສາ.
ແລະ, ແນ່ນອນ, ການພັດທະນາຢ່າງຕໍ່ເນື່ອງຂອງ repositories open source deepfake ສະຫນອງສາຂາອື່ນຂອງການຄົ້ນຄວ້າທີ່ປະກອບສ່ວນໂດຍຜູ້ໃຊ້ຢ່າງຫ້າວຫັນໃນຂອບເຂດຂອງການສັງເຄາະຮູບພາບໃບຫນ້ານີ້.















