
Îstîxbaratê ya sûnî
YOLOv7: Algorîtmaya Tespîtkirina Tiştê ya Herî Pêşketî?

6-ê Tîrmeha 2022-an dê di dîroka AI-ê de wekî nîgarek were destnîşan kirin ji ber ku di vê rojê de YOLOv7 hate berdan. Ji destpêka destpêkirina xwe ve, YOLOv7 di civata pêşdebiran a Computer Vision de mijara herî germ e, û ji ber sedemên rast. YOLOv7 jixwe di pîşesaziya tespîtkirina tiştan de wekî qonaxek tê hesibandin.
Demek kurt piştî Gotara YOLOv7 hate weşandin, ew wekî modela tespîtkirina îtîraza rast-a-rast-a bilez, û herî rast derket holê. Lê YOLOv7 çawa pêşbirkên xwe pêşbaz dike? Çi YOLOv7 di pêkanîna peywirên dîtina kompîturê de ewqas bikêrhatî dike?
Di vê gotarê de em ê hewl bidin ku modela YOLOv7 analîz bikin, û hewl bidin ku bersivê bibînin ka çima YOLOv7 naha dibe standard pîşesaziyê? Lê berî ku em karibin bersiva wê bidin, em ê neçar bin ku li kurte dîroka vedîtina tiştan binêrin.
Detection Object çi ye?
Vedîtina objeyê di dîtina kompîturê de şaxek e ku di wêneyek, an pelek vîdyoyê de tiştan nas dike û bi cih dike. Tespîtkirina tiştan bloka avakirina gelek sepanan e, di nav de otomobîlên xwe-ajotinê, çavdêriya çavdêrîkirin, û tewra robotîk.
Modelek tespîtkirina tiştan dikare di du kategoriyên cûda de were dabeş kirin, detektorên yek-gule, û detektorên pir-shot.
Dema Rastî Vedîtina Tiştê
Ji bo ku bi rastî fêm bikin ka YOLOv7 çawa dixebite, ji me re girîng e ku em armanca sereke ya YOLOv7 fam bikin, "Tespîtkirina Tiştên Dema Rastî”. Tespîtkirina Tişta Rastî ya Demjimêrê pêkhateyek bingehîn a dîtina komputera nûjen e. Modelên Tespîtkirina Tiştên Dema Rastî hewl didin ku di wextê rast de tiştên balkêş nas bikin û bi cih bikin. Modelên Tespîtkirina Tiştên Wexta Rastî ji bo pêşdebiran bi rastî bikêrhatî kir ku tiştên balkêş di çarçoveyek tevgerê de mîna vîdyoyek, an têketinek çavdêriya zindî bişopînin.

Modelên Tesbîtkirina Tiştên Wexta Rastî di bingeh de ji modelên vedîtina wêneya kevneşopî gavek li pêş in. Dema ku ya pêşîn ji bo şopandina tiştên di pelên vîdyoyê de tê bikar anîn, ya paşîn tiştan di nav çarçoveyek rawestayî de mîna wêneyek bi cih dike û nas dike.
Wekî encamek, modelên Tesbîtkirina Tişta Rastî ya Bi rastî ji bo analîtîkên vîdyoyê, wesayîtên xweser, hejmartina tiştan, şopandina pir-object, û hêj bêtir bikêr in.
YOLO çi ye?
YOLO an "Hûn Tenê Carekê Dinêrin” malbatek modelên tespîtkirina tiştan di dema rast de ye. Têgeha YOLO yekem car di sala 2016-an de ji hêla Joseph Redmon ve hate destnîşan kirin, û ew hema hema di cih de bû axavtina bajêr ji ber ku ew ji algorîtmayên vedîtina tiştên heyî pir bileztir û pir rasttir bû. Demek dirêj derbas nebû ku algorîtmaya YOLO di pîşesaziya dîtina komputerê de standardek bû.

Têgeha bingehîn a ku algorîtmaya YOLO pêşniyar dike ev e ku meriv torgilokek neuralî ya dawî-bi-dawî bi karanîna qutiyên sînor û îhtîmalên polê bikar bîne da ku di wextê rast de pêşbîniyan bike. YOLO ji modela vedîtina objektê ya berê cûda bû di vê wateyê de ku ew nêzîkatiyek cûda pêşniyar kir ku bi veavakirina dabeşkeran ve tespîtkirina tiştan pêk bîne.
Guhertina nêzîkbûnê xebitî ji ber ku YOLO di demek kurt de bû standarda pîşesaziyê ji ber ku valahiya performansê di navbera xwe de, û algorîtmayên din ên tespîtkirina tiştan di dema rast de girîng bûn. Lê sedem çi bû ku YOLO ewqas bikêrhatî bû?
Dema ku bi YOLO re were berhev kirin, algorîtmayên vedîtina tiştan wê hingê Tora Pêşniyara Herêmê bikar anîn da ku herêmên mumkin ên berjewendiyê kifş bikin. Pêvajoya naskirinê piştre li ser her herêmê cuda hate kirin. Wekî encamek, van modelan bi gelemperî li ser heman wêneyê gelek dubare kirin, û ji ber vê yekê nebûna rastbûnê, û dema darvekirinê bilindtir. Ji hêla din ve, algorîtmaya YOLO qatek bi tevahî ve girêdayî bikar tîne da ku pêşbîniyê bi carekê pêk bîne.
YOLO Çawa Kar dike?
Sê gav hene ku diyar dikin ka algorîtmayek YOLO çawa dixebite.
Reframing Detection Object wekî Pirsgirêkek Regresyonê ya Yekane
Ew Algorîtmaya YOLO hewl dide ku vedîtina tiştan wekî pirsgirêkek yekane ya paşvekêşanê ji nû ve binav bike, di nav de pîxelên wêneyê, îhtîmalên polê, û koordînatên qutiya sînorkirî. Ji ber vê yekê, algorîtm pêdivî ye ku tenê carekê li wêneyê mêze bike da ku tiştên armanc di wêneyan de pêşbîn bike û bibîne.
Sedemên Wêne li Cîhanê
Ji bilî vê, dema ku algorîtmaya YOLO pêşbîniyan dike, ew wêneyê gerdûnî dike sedem. Ew ji teknolojiyên bingeh-pêşniyaz, û xêzkirinê yên herêmê cûda ye ji ber ku algorîtmaya YOLO di dema perwerdehî û ceribandina li ser databasê de wêneyê bêkêmasî dibîne, û dikare agahdariya çarçovê li ser dersan, û ka ew çawa xuya dikin, kod bike.
Berî YOLO, Fast R-CNN yek ji wan algorîtmayên vedîtina tiştana herî populer bû ku nikaribû çarçoveyek mezintir di wêneyê de bibîne ji ber ku ew di wêneyekê de xêzên paşîn ên di wêneyekê de bi tiştekê şaş dikir. Dema ku bi algorîtmaya Fast R-CNN re were berhev kirin, YOLO% 50 rasttir e dema ku ew ji bo çewtiyên paşperdeya tê.
Nûnertiya Objeyan giştî dike
Di dawiyê de, algorîtmaya YOLO di heman demê de armanc dike ku nûnertiya tiştan di wêneyekê de giştî bike. Wekî encamek, dema ku algorîtmayek YOLO li ser danûstendinek bi wêneyên xwezayî ve hate xebitandin, û ji bo encaman hat ceribandin, YOLO ji modelên R-CNN-ê yên heyî ji hêla marjînalek fireh ve derket pêş. Ji ber ku YOLO pir bi gelemperî gelemperî ye, şansên têkçûna wê dema ku li ser têketinên nediyar an domên nû têne bicîh kirin kêm bûn.
YOLOv7: Çi Nû ye?
Naha ku me têgihiştinek bingehîn heye ka modelên tespîtkirina tiştan di wextê rast de çi ne, û algorîtmaya YOLO çi ye, dem e ku em li ser algorîtmaya YOLOv7 nîqaş bikin.
Optimîzekirina Pêvajoya Perwerdehiyê
Algorîtmaya YOLOv7 ne tenê hewl dide ku mîmariya modelê xweşbîn bike, lê ew di heman demê de çêtirkirina pêvajoya perwerdehiyê jî armanc dike. Mebest ew e ku modul û rêbazên xweşbîniyê bikar bîne da ku rastbûna vedîtina tiştan baştir bike, lêçûna perwerdehiyê xurt bike, di heman demê de lêçûna destwerdanê biparêze. Van modulên xweşbînkirinê dikarin wekî a bag trainable belaş hûnîn .
Tayînkirina Etîketa Rêvebir a Rêjeya Qehweyî berbi Baş
Algorîtmaya YOLOv7 plan dike ku li şûna ya konvansiyonel, Etîketek Rêvebir a Rêvebiriya Qehwet û Xweşik a nû bikar bîne. Peywira Labelê Dînamîk. Wisa ye ji ber ku bi peywirdarkirina nîşana dînamîkî re, perwerdekirina modelek bi çend qatên derketinê re dibe sedema hin pirsgirêkan, ya herî gelemperî ew e ku meriv çawa armancên dînamîkî ji bo şaxên cihêreng û encamên wan destnîşan dike.
Model Re-Parameterization
Ji nû ve-parametrîzasyona modelê di tespîtkirina tiştan de têgehek girîng e, û karanîna wê bi gelemperî di dema perwerdehiyê de bi hin pirsgirêkan re tê şopandin. Algorîtmaya YOLOv7 li ser karanîna têgeha plan dike Rêya belavkirina gradient ji bo analîzkirina polîtîkayên ji nû ve-parametrîzasyona modelê ji bo qatên cuda yên di torê de derbasdar e.
Berfirehkirin û Pîvana Têkel
Algorîtmaya YOLOv7 jî destnîşan dike rêbazên pîvandinê yên berfireh û tevlihev ji bo tespîtkirina tiştan di dema rast de pîvan û hesaban bikar bînin û bi bandor bikar bînin.

YOLOv7 : Karê Têkildar
Dema Rastî Vedîtina Tiştê
YOLO niha standarda pîşesaziyê ye, û piraniya detektorên tiştan di dema rast de algorîtmayên YOLO, û FCOS (Tişta Teşhîskirina Yek-Qonaxa Yek-Qonaxê) bi kar tînin. Detektorek tiştekê ya dema rast bi gelemperî taybetmendiyên jêrîn hene
- Mîmariya torê ya bihêztir û bileztir.
- Rêbazek yekbûna taybetmendiyê ya bi bandor.
- Rêbazek tespîtkirina tiştên rast.
- Fonksiyonek windabûna xurt.
- Rêbazek peywirdarkirina labelê ya bikêrhatî.
- Rêbazek perwerdehiya bi bandor.
Algorîtmaya YOLOv7 rêbazên fêrbûn û distilasyonê yên xwe-çavdêrkirî yên ku bi gelemperî mîqdarên mezin dane hewce nake bikar tîne. Berevajî vê, algorîtmaya YOLOv7 rêbazek çente-ji-freebies ya perwerdekirî bikar tîne.
Model Re-Parameterization
Teknolojiyên ji nû ve-parametrekirina modelê wekî teknolojiyek ensembleyê tê hesibandin ku di qonaxek navbeynkariyê de gelek modulên hesabkeriyê li hev dike. Teknîkî dikare li du kategoriyan were dabeş kirin, koma asta modelê, û ensemble-asta module.
Naha, ji bo bidestxistina modela destwerdana dawîn, teknîka reparameterîzasyona asta modelê du pratîkan bikar tîne. Pratîka yekem daneyên perwerdehiyê yên cihêreng bikar tîne da ku gelek modelên wekhev perwerde bike, û dûv re giraniya modelên perwerdekirî navîn dike. Wekî din, pratîka din di dema dubareyên cihêreng de giraniya modelan navîn dike.
Ji nû ve-parametrekirina asta modulê di van demên dawî de populerbûnek pir mezin bi dest dixe ji ber ku ew di qonaxa perwerdehiyê de modulek li şaxên modulê yên cihêreng, an şaxên cihêreng ên heman rengî vediqetîne, û dûv re di dema destwerdanê de van şaxên cihêreng di modulek wekhev de yek dike.
Lêbelê, teknîkên ji nû ve-parameterîzasyonê li ser her cûre mîmarî nayê sepandin. Sedema vê yekê ye Algorîtmaya YOLOv7 teknîkên nû-parametrekirina modela nû bikar tîne da ku stratejiyên têkildar sêwirîne ji bo mîmariyên cihêreng maqûl e.
Scaling Model
Pîvana modelê pêvajoyek bilindbûn an kêmkirina modelek heyî ye ji ber vê yekê ew di nav cîhazên hesabker ên cihêreng de cih digire. Pîvana modelê bi gelemperî gelek faktorên wekî hejmara qatan bikar tîne(kûrî), mezinahiya wêneyên têketinê(çareseriyê), hejmara pîramîdên taybetmendiyê (şanocî), û hejmara kanalan (width). Van faktoran di dabînkirina danûstendinek hevseng de ji bo parametreyên torê, leza destwerdanê, hesabkirin û rastbûna modelê de rolek girîng dilîzin.
Yek ji wan awayên ku herî zêde tê bikar anîn ev e NAS an Lêgerîna Mîmariya Torê ku bixweber bêyî qaîdeyên tevlihev li faktorên pîvandinê yên guncan ji motorên lêgerînê digere. Nerazîbûna sereke ya karanîna NAS-ê ev e ku ew ji bo lêgerîna faktorên pîvana guncan nêzîkbûnek biha ye.
Hema hema her modela ji nû ve-parametrekirina modelê faktorên pîvandina ferdî û yekta serbixwe analîz dike, û ji bilî vê yekê, tewra van faktoran bi rengek serbixwe xweştir dike. Ji ber ku mîmariya NAS bi faktorên pîvandinê yên ne-girêdayî re dixebite.
Hêjayî gotinê ye ku modelên lihevhatin-based mîna VoVNet or DenseNet dema ku kûrahiya modelan tê pîvandin firehiya têketina çend qatan biguhezîne. YOLOv7 li ser mîmarî-bingehek pevgirêdanê ya pêşniyarkirî dixebite, û ji ber vê yekê rêbazek pîvana tevlihev bikar tîne.

Nîgara ku li jor hatî destnîşan kirin hevber dike torên komkirina qata bikêrhatî ya dirêjkirî (E-ELAN) ji modelên cuda. Rêbaza E-ELAN ya pêşniyarkirî riya veguheztina gradientê ya mîmariya orîjînal diparêze, lê armanc dike ku bi karanîna tevhevkirina komê kardinalîteya taybetmendiyên lêzêde zêde bike. Pêvajo dikare taybetmendiyên ku ji hêla nexşeyên cûda ve têne fêr kirin zêde bike, û dikare karanîna hesab û pîvanan bêtir bikêrtir bike.
YOLOv7 Mîmarî
Modela YOLOv7 modelên YOLOv4, YOLO-R, û Scaled YOLOv4 wekî bingeha xwe bikar tîne. YOLOv7 encama ceribandinên ku li ser van modelan hatine kirin e ku encam çêtir bikin, û modela rasttir bikin.
Tevra Tevhevkirina Layera Berfireh an E-ELAN
E-ELAN bloka avakirina bingehîn a modela YOLOv7 e, û ew ji modelên heyî yên li ser karbidestiya torê, bi taybetî ji ELAN.
Nîqaşên sereke dema sêwirana mîmariyek bikêrhatî hejmara parameteran, dendika hesabkerî, û hêjeya hesabkirinê ne. Modelên din di heman demê de faktorên wekî bandora rêjeya kanala têketin / derketinê, şaxên di tora mîmariyê de, leza destwerdana torê, hejmara hêmanên di tensorên tora konvolutional de, û hêj bêtir dihesibînin.
Ew CSPVoNet model ne tenê pîvanên jorîn dihesibîne, lê ew di heman demê de rêça gradientê jî analîz dike da ku taybetmendiyên cihêreng fêr bibe bi çalakkirina giraniyên qatên cihêreng. Nêzîkatî dihêle ku destwerdan pir zûtir, û rast bin. Ew ELAN mîmarî armanc dike ku sêwirana torgilokek bikêrhatî ji bo kontrolkirina riya herî dirêj a gradientê kontrol bike da ku tor di fêrbûnê de, û lihevhatina bi bandortir be.
ELAN jixwe gihaştiye qonaxek bi îstîqrar, bêyî ku jimara berhevkirina blokên hesabker, û dirêjahiya riya gradient. Ger blokên hesabker bêsînor werin berhev kirin, dibe ku dewleta stabîl hilweşe, û rêjeya karanîna parametreyê dê kêm bibe. Ew Mîmariya E-ELAN-ê ya pêşniyarkirî dikare pirsgirêkê çareser bike ji ber ku ew berfirehbûn, tevlihevkirin, û kardinalîteyê bikar tîne. ku bi domdarî şiyana fêrbûna torê zêde bike dema ku riya gradientê ya orjînal bigire.
Wekî din, dema ku mîmariya E-ELAN bi ELAN re tê berhev kirin, ferqa tenê di bloka hesabkirinê de ye, dema ku mîmariya qata derbasbûnê neguherî ye.
E-ELAN pêşniyar dike ku kardinalîteya blokên hesabkirinê berfireh bike, û bi karanîna kanalê berfireh bike kombûna komê. Dê nexşeya taybetmendiyê wê hingê were hesibandin, û li gorî pîvana komê di nav koman de were tevlihev kirin, û dûv re dê bi hev re were girêdan. Hejmara kanalên di her komê de dê wekî mîmariya orjînal bimîne. Di dawiyê de, komên nexşeyên taybetmendiyê dê werin zêdekirin da ku kardinalîteyê bikin.
Scaling Model ji bo Modelên Bingeha Hevgirtinê
Pîvana modelê dibe alîkar verastkirina taybetmendiyên modelan ku di hilberîna modelan de li gorî hewcedariyên, û pîvanên cûda dibe alîkar ku leza destwerdana cihêreng bicîh bîne.

Hêjmar behsa pîvandina modelê ji bo modelên cihêreng ên lihevhatinî dike. Wekî ku hûn di jimar (a) û (b) de dikarin, firehiya derketinê ya bloka hesabkirinê bi zêdebûna pîvandina kûrahiya modelan re zêde dibe. Di encamê de, firehiya têketinê ya qatên veguheztinê zêde dibe. Ger van rêbazan li ser mîmariya li ser bingeha hevgirtinê werin bicîh kirin, pêvajoya pîvandinê bi kûrahî tête kirin, û ew di jimareya (c) de tê xuyang kirin.
Ji ber vê yekê meriv dikare were encamdan ku ne gengaz e ku ji bo modelên lihevhatî-bingehan faktorên pîvandinê serbixwe werin analîz kirin, û li şûna ku ew bi hev re bêne hesibandin an analîz kirin. Ji ber vê yekê, ji bo modelek lihevhatinê, ew guncan e ku meriv rêbaza pîvandina modela tevlihev a têkildar bikar bîne. Wekî din, dema ku faktora kûrahiyê tê pîvandin, divê kanala derketinê ya blokê jî were pîvandin.
Trainable Bag of Freebies
Çenteyek belaş têgehek e ku pêşdebiran ji bo danasînê bikar tînin komek rêbaz an teknîkên ku dikarin stratejiya perwerdehiyê an lêçûn biguhezînin di hewlekê de ji bo zêdekirina rastbûna modelê. Ji ber vê yekê ev çenteyên perwerdekirî yên belaş ên di YOLOv7 de çi ne? Ka em lê binêrin.
Têkiliya Re-Parameterized Plankirî
Algorîtmaya YOLOv7 ji bo destnîşankirina rêyên belavbûna herikîna gradient bikar tîne meriv çawa torgilokek bi îdeal bi tevhevkirina ji nû ve-parametrekirî ve tê hev kirin. Ev nêzîkatiya YOLov7 hewldanek dijber e Algorîtmaya RepConv ku her çend li ser modela VGG bi aramî pêk aniye jî, dema ku rasterast li ser modelên DenseNet û ResNet were sepandin xirab performans dike.
Ji bo naskirina girêdanên di qatek konvokî de, ya Algorîtmaya RepConv 3 × 3 pevçûn, û 1 × 1 tevlihev dike. Ger em algorîtma, performansa wê, û mîmariya wê analîz bikin, em ê bibînin ku RepConv wê hilweşîne hevgirtin li DenseNet, û mayî li ResNet.

Wêneya li jor modelek ji nû ve-parametrekirî ya plansazkirî nîşan dide. Tê dîtin ku algorîtmaya YOLov7 dît ku qatek di torê de bi girêdan an girêdanên mayînde divê di algorîtmaya RepConv de pêwendiyek nasnameyê nebe. Di encamê de, pejirandina bi RepConvN re bêyî girêdanên nasnameyê tê pejirandin.
Ji bo Alîkarî û Fîn ji bo Wendakirina Serê
Çavdêriya kûr şaxek di zanistiya kompîturê de ye ku pir caran karanîna xwe di pêvajoya perwerdehiya torên kûr de dibîne. Prensîba bingehîn a çavdêriya kûr ew e di qatên navîn ên torê de serê alîkariyek din zêde dike li gel giranên torê yên nazik ku windabûna arîkar wekî rêberê wê ye. Algorîtmaya YOLOv7 serê ku ji derana paşîn berpirsiyar e wekî serê pêşeng destnîşan dike, û serê alîkar serê ku di perwerdehiyê de dibe alîkar e.
Dûv re, YOLOv7 ji bo tayînkirina labelê rêbazek cûda bikar tîne. Bi konvansiyonel, peywira labelê ji bo afirandina etîketan bi guhdana rasterast li rastiya zemîn, û li ser bingeha rêzek rêzikan hatî bikar anîn. Lêbelê, di van salên dawî de, dabeşkirin, û kalîteya têketina pêşbîniyê rolek girîng dilîze ji bo afirandina nîşanek pêbawer. YOLOv7 etîketek nerm a tiştê çêdike bi karanîna pêşbîniyên qutiya sînor û rastiya zemîn.
Wekî din, rêbaza peywirdarkirina labelê ya nû ya algorîtmaya YOLOv7 pêşbîniyên serê pêşeng bikar tîne da ku rêber û serê alîkar jî rêve bike. Rêbaza peywirdarkirina labelê du stratejiyên pêşniyarkirî hene.
Lead Head Guided Label Assigner
Stratejî li ser bingeha encamên pêşbîniya serê pêşeng, û rastiya erdê hesaban dike, û dûv re xweşbîniyê bikar tîne da ku nîşaneyên nerm çêbike. Dûv re ev etîketên nerm hem ji bo serê pêşeng, hem jî ji bo serê alîkar wekî modela perwerdehiyê têne bikar anîn.
Stratejî li ser vê yekê dixebite ku ji ber ku serê pêşeng xwedan jêhatîbûnek hînbûnê ya mezintir e, labelên ku ew diafirîne divê nûnertir bin, û di navbera çavkanî û armancê de têkildar bin.
Berhevkarê Labelê Serê Rêvebiriya Qeht-to-Fine
Ev stratejî di heman demê de li ser bingeha encamên pêşbîniya serê pêşeng, û rastiya zemîn hesaban dike, û dûv re xweşbîniyê bikar tîne da ku etîketên nerm çêbike. Lêbelê, cûdahiyek bingehîn heye. Di vê stratejiyê de, du komên etîketên nerm hene, asta hişk, û labelê baş.
Nîşana qelew bi rihetkirina astengiyên nimûneya erênî tê çêkirin
Pêvajoya peywirdarkirinê ya ku bêtir torên wekî armancên erênî digire. Ew tête kirin ku ji ber hêza fêrbûna qels a serê alîkar ji xetereya windakirina agahdariyê dûr bixin.

Nîgara li jor di algorîtmaya YOLOv7 de karanîna çenteyek belaş a perwerdehiyê rave dike. Ew ji bo serê arîkar hişk, û ji bo serê sereke jî baş nîşan dide. Dema ku em modelek bi Serê Alîkar (b) re bi Modela Normal (a) re bidin ber hev, em ê bibînin ku şemaya di (b) de serekek alîkar heye, lê ne di (a) de ye.
Hêjmara (c) diyarkera etîketa serbixwe ya hevpar nîşan dide dema ku jimar (d) û jimar (e) bi rêzê Vebijarkera Rêvebir a Pêşewa, û Rêvebira Rêvebir a Berbiçav-biFine ku ji hêla YOLOv7 ve hatî bikar anîn temsîl dikin.
Other Trainable Bag of Freebies
Ji bilî yên ku li jor hatine behs kirin, algorîtmaya YOLOv7 çenteyên belaş ên din bikar tîne, her çend ew di destpêkê de ji hêla wan ve nehatine pêşniyar kirin. Ew hene
- Normalîzasyona Komê di Teknolojiya Conv-Bn-Çalakkirinê de: Ev stratejî ji bo girêdana qatek konvokî rasterast bi qata normalkirina hevîrê ve tê bikar anîn.
- Di YOLOR de zanîna nepenî: YOLOv7 stratejiyê bi nexşeya taybetmendiya Convolutional re dike yek.
- Modela EMA: Modela EMA wekî modela referansa paşîn di YOLOv7 de tê bikar anîn her çend karanîna wê ya bingehîn ew e ku di rêbaza mamosteyê navîn de were bikar anîn.
YOLOv7 : Ceribandin
Sêwirandina Ezmûnî
Algorîtmaya YOLOv7 bi kar tîne Data Microsoft COCO ji bo perwerdekirin û pejirandinê modela tespîtkirina objeya wan, û ne hemî van ceribandinan modelek pêş-perwerdekirî bikar tînin. Pêşdebiran databasa trênê ya 2017-an ji bo perwerdehiyê bikar anîn, û daneyên pejirandina 2017-an ji bo hilbijartina hîperparametran bikar anîn. Di dawiyê de, performansa encamên tespîtkirina tiştan YOLOv7 bi algorîtmayên hunerî yên ji bo vedîtina tiştan re têne berhev kirin.
Pêşdebiran ji bo modelek bingehîn dîzayn kirin Edge GPU (YOLOv7-piçûk), GPU normal (YOLOv7), û GPU ewr (YOLOv7-W6). Wekî din, algorîtmaya YOLOv7 di heman demê de ji bo pîvandina modelê li gorî daxwazên karûbarê cihêreng modelek bingehîn bikar tîne, û modelên cihêreng digire. Ji bo algorîtmaya YOLOv7 pîvandina stûyê li stûyê tê kirin, û pêkhateyên pêşniyarkirî têne bikar anîn da ku kûrahî & firehiya modelê zêde bikin.
Bingehên bingehîn
Algorîtmaya YOLOv7 modelên berê yên YOLO bikar tîne, û algorîtmaya tespîtkirina tiştan YOLOR wekî bingeha xwe bikar tîne.

Nîgara jorîn bingeha bingehîn a modela YOLOv7 bi modelên din ên vedîtina tiştan re berhev dike, û encam pir diyar in. Dema ku bi ya Algorîtmaya YOLOv4, YOLOv7 ne tenê 75% kêmtir pîvanan bikar tîne, lê ew di heman demê de 15% kêm hesaban jî bikar tîne, û 0.4% rastbûna wê jî zêde ye.
Berawirdkirin bi Modelên Detektorê Objektîf ên Rewşa Hunerê re

Dema ku YOLOv7 li hember modelên nûjen ên tespîtkirina tiştên hunerî yên ji bo GPU-yên mobîl û gelemperî têne berhev kirin, jimareya jorîn encaman nîşan dide. Dikare were dîtin ku rêbaza ku ji hêla algorîtmaya YOLOv7 ve hatî pêşniyar kirin xwedan xala danûstandina bilez-rastbûna çêtirîn e.
Lêkolîna Ablation: Rêbaza Pîvana Pêvek Pêşniyar

Nîgara ku li jor hatî destnîşan kirin encamên karanîna stratejiyên cihêreng ên ji bo mezinkirina modelê berhev dike. Stratejiya pîvandinê ya di modela YOLOv7 de kûrahiya bloka hesabkeriyê 1.5 qat zêde dike, û firehiyê jî 1.25 qat mezin dike.
Dema ku bi modelek ku tenê kûrahiyê mezin dike re were berhev kirin, modela YOLOv7 ji% 0.5 çêtir performans dike dema ku kêmtir parametre, û hêza hesabkirinê bikar tîne. Ji hêla din ve, dema ku bi modelên ku tenê kûrahiyê mezin dikin re were berhev kirin, rastbûna YOLOv7% 0.2 çêtir dibe, lê pêdivî ye ku hejmara pîvanan bi% 2.9 û hesabkirin% 1.2 were pîvan kirin.
Modela Re-Parametrekirî ya Plankirî ya Pêşniyarkirî
Ji bo verastkirina giştîbûna modela wê ya ji nû ve-parametrekirî ya pêşniyarkirî, ya Algorîtmaya YOLOv7 wê ji bo verastkirinê li ser modelên bingeh-mayî, û lihevkirinê bikar tîne.. Ji bo pêvajoya verastkirinê, algorîtmaya YOLOv7 bikar tîne ELAN 3-stacked ji bo modela-bingeha hevgirtî, û CSPDarknet ji bo modela-bingeha mayî.
Ji bo modela-bingeha hevgirtinê, algorîtma di ELAN-a 3-stacked de bi RepConv re 3 × 3 qatên hevedudanî diguhezîne. Nîgara jêrîn konfigurasyona berfireh a Planned RepConv, û ELAN-a 3-stacked nîşan dide.
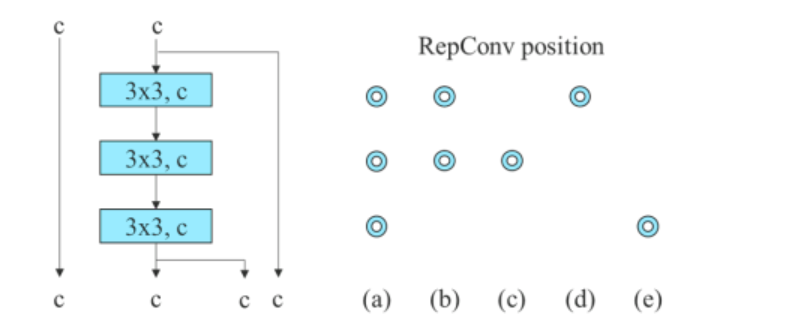
Wekî din, dema ku bi modela-bingeha mayî re mijûl dibe, algorîtmaya YOLOv7 bloka tarî ya berevajîkirî bikar tîne ji ber ku bloka tarî ya orîjînal xwedan bloka tevlihevkirina 3×3 nîne. Nîgara jêrîn mîmariya CSPDarkneta Reversed nîşan dide ku pozîsyonên 3×3 û 1×1 qata pevgirêdayî berevajî dike. 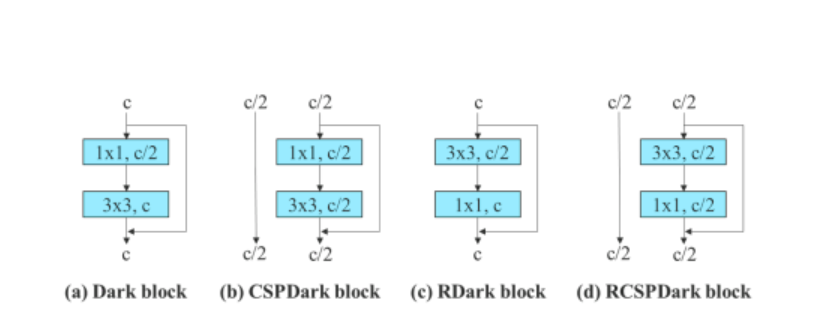
Ji bo Serê Alîkarê Wendakirina Alîkarê Pêşniyar kirin
Ji bo windabûna arîkar ji bo serê alîkar, modela YOLOv7 peywira etîketa serbixwe ya ji bo awayên serê alîkar & serê rêber berhev dike.

Di jimareya jorîn de encamên lêkolînê yên li ser serê alîkarê pêşniyarkirî hene. Tê dîtin ku performansa giştî ya modelê bi zêdebûna windabûna arîkar re zêde dibe. Digel vê yekê, peywira nîşana rêberî ya rêberî ya ku ji hêla modela YOLOv7 ve hatî pêşniyar kirin ji stratejiyên tayînkirina rêberiya serbixwe çêtir pêk tîne.
YOLOv7 Encam
Li ser bingeha ceribandinên jorîn, li vir encama performansa YOLov7-ê dema ku bi algorîtmayên din ên tespîtkirina tiştan re tê berhev kirin heye.

Hêjmara jorîn modela YOLOv7 bi algorîtmayên din ên vedîtina tiştan re berhev dike, û bi zelalî tê dîtin ku YOLOv7 ji modelên din ên tespîtkirina îtîrazê di warê Average Precision (AP) v / s midaxeleya hevîrê.
Wekî din, jimareya jêrîn performansa YOLOv7 v/s algorîtmayên din ên tespîtkirina îtîraza dema rast berhev dike. Carek din, YOLOv7 modelên din di warê performansa giştî, rastbûn, û karîgeriyê de bi ser dikeve.

Li vir hin çavdêriyên din ji encam û performansa YOLOv7 hene.
- YOLOv7-Tiny di malbata YOLO de modela herî piçûk e, bi zêdetirî 6 mîlyon parametre. YOLOv7-Tiny xwedan rastbûnek navînî 35.2%, ye û ew ji modelên YOLOv4-Tiny bi pîvanên berawirdî derdixe pêş.
- Modela YOLOv7 zêdetirî 37 mîlyon parametre hene, û ew ji modelên bi parametreyên bilindtir ên mîna YOLov4 derdixe.
- Modela YOLOv7 di navbera 5 û 160 FPS de rêjeya mAP û FPS ya herî bilind e.
Xelasî
YOLO an Hûn Tenê Carekê Dinêrin di dîtina komputera nûjen de rewşa modela vedîtina tiştên hunerî ye. Algorîtmaya YOLO bi rastbûna xwe ya bilind, û bikêrhatina xwe tê zanîn, û wekî encamek, ew di pîşesaziya tespîtkirina tiştan de di dema rast de serîlêdana berfireh dibîne. Ji ber ku yekem algorîtmaya YOLO di sala 2016-an de hate destnîşan kirin, ceribandinan hişt ku pêşdebiran bi domdarî modelê baştir bikin.
Modela YOLOv7 di malbata YOLO de pêveka herî dawî ye, û ew heya roja îro algorîtmaya YOLo ya herî hêzdar e. Di vê gotarê de, me li ser bingehên YOLOv7 axivî, û hewl da ku rave bikin ka çi YOLOv7 ew qas bi bandor dike.















