
ხელოვნური ინტელექტი
ხელოვნური ინტელექტის გამომუშავებული ენა იწყებს სამეცნიერო ლიტერატურის დაბინძურებას

მკვლევარებმა საფრანგეთიდან და რუსეთიდან გამოაქვეყნეს კვლევა, რომელიც მიუთითებს, რომ ხელოვნური ინტელექტის საფუძველზე მართული ალბათური ტექსტის გენერატორების გამოყენება, როგორიცაა GPT-3, შემოაქვს „ნაწამებულ ენას“, არარსებულ ლიტერატურაზე ციტირებს და ად-ჰოკ, არაკრედიტებული გამოსახულების ხელახლა გამოყენებას მანამდე პატივცემულ არხებში. ახალი სამეცნიერო ლიტერატურის გამოცემა.
ალბათ ყველაზე შემაშფოთებელია ის, რომ შესწავლილი ნაშრომები ასევე შეიცავს მეცნიერულად არაზუსტ ან არარეპროდუცირებად შინაარსს, რომელიც წარმოდგენილია როგორც ობიექტური და სისტემატური კვლევის შედეგი, რაც მიუთითებს იმაზე, რომ გენერაციული ენის მოდელები გამოიყენება არა მხოლოდ ნაშრომების ავტორების შეზღუდული ინგლისური უნარების გასაძლიერებლად, მაგრამ რეალურად შეასრულოს მძიმე სამუშაო (და, უცვლელად, ამის გაკეთება ცუდად).
ის მოხსენება, სახელწოდებით წამებული ფრაზები: მეცნიერებაში გაჩენილი საეჭვო წერის სტილი, შედგენილია ტულუზის უნივერსიტეტის კომპიუტერული მეცნიერების დეპარტამენტის მკვლევარებმა და Yandex-ის მკვლევარმა ალექსანდრე მაგაზინოვმა, ამჟამად თელ-ავივის უნივერსიტეტში.
კვლევა განსაკუთრებით ფოკუსირებულია Elsevier Journal-ში ხელოვნური ხელოვნური ინტელექტის მიერ გენერირებული უაზრო სამეცნიერო პუბლიკაციების ზრდაზე. მიკროპროცესორები და მიკროსისტემები.
ნებისმიერი სხვა სახელით
აუტორეგრესიული ენის მოდელები, როგორიცაა GPT-3, გაწვრთნილია მონაცემთა დიდ მოცულობაზე და შექმნილია ამ ხელშემწყობი მონაცემების პერიფრაზირებისთვის, შეჯამებისთვის, შეჯამებისა და ინტერპრეტაციისთვის, რომლებიც შეკრული გენერაციული ენის მოდელებში, რომლებსაც შეუძლიათ ბუნებრივი მეტყველებისა და წერის ნიმუშების რეპროდუცირება, ორიგინალის შენარჩუნებისას. ტრენინგის მონაცემების განზრახვა.
იმის გამო, რომ ასეთი ჩარჩოები ხშირად ისჯება მოდელის ტრენინგის ეტაპზე ორიგინალური მონაცემების პირდაპირი და „არააბსორბირებული“ რეგურგიტაციის შეთავაზებისთვის, ისინი აუცილებლად ეძებენ სინონიმებს - თუნდაც კარგად ჩამოყალიბებულ ფრაზებს.
აშკარად ხელოვნური ინტელექტის მიერ შექმნილი/დახმარებული სამეცნიერო წარდგინებები, რომლებიც აღმოჩენილია მკვლევარების მიერ, მოიცავს არაჩვეულებრივ წარუმატებელ მცდელობებს კრეატიული სინონიმების შემოქმედებითად ცნობილი ფრაზების მანქანური სწავლების სექტორში:
ღრმა ნერვული ქსელი:ღრმა ნერვული ორგანიზაცია"
ხელოვნური ნერვული ქსელიk: "(ყალბი | ყალბი) ნერვული ორგანიზაცია"
მობილური ქსელი: 'მრავალმხრივი ორგანიზაცია"
ქსელის შეტევა: 'ორგანიზაცია (ჩასაფრება | თავდასხმა)'
ქსელის კავშირი: "ორგანიზაციის ასოციაცია"
დიდი მონაცემები: '(უზარმაზარი | უზარმაზარი | უზარმაზარი | კოლოსალური) ინფორმაცია'
მონაცემთა საწყობი: "ინფორმაცია (საწყობი | სადისტრიბუციო ცენტრი)"
ხელოვნური ინტელექტი (AI): "(ყალბი | ადამიანის მიერ შექმნილი) ცნობიერება"
მაღალი ხარისხის გამოთვლა: "ელიტის ფიგურა"
ნისლი/ნისლი/ღრუბლოვანი გამოთვლა: "ნისლის ფიგურა"
გრაფიკული დამუშავების ერთეული (GPU): "დიზაინის მომზადების განყოფილება"
ცენტრალური დამუშავების ერთეული (CPU): "ფოკუსური მომზადების განყოფილება"
სამუშაო ნაკადის ძრავა: "სამუშაო პროცესის ძრავა"
სახის ამოცნობა: "სახის აღიარება"
ხმის ამოცნობა: "დისკურსის აღიარება"
საშუალო კვადრატული შეცდომა: 'საშუალო კვადრატი (შეცდომა | შეცდომა)'
ნიშნავს აბსოლუტურ შეცდომას: "საშუალო (პირდაპირი | უმაღლესი) (შეცდომა | შეცდომა)"
სიგნალი ხმაურზე: "(მოძრაობა | დროშა | ინდიკატორი | ნიშანი | სიგნალი) (ღელვა | ხმაური | ხმაური)"
გლობალური პარამეტრები: "მსოფლიო პარამეტრები"
წვდომა: "(თვითნებური | არარეგულარული) მიღების უფლება
შემთხვევითი ტყე: "(თვითნებური | არარეგულარული) (ტყე | მერქანი | აყვავებული ტერიტორია)"
შემთხვევითი მნიშვნელობა: '(თვითნებური | არარეგულარული) პატივისცემა'
ჭიანჭველების კოლონია: 'ქვედა მწერი (სახელმწიფო | პროვინცია | ტერიტორია | რეგიონი | დასახლება)'
ჭიანჭველების კოლონია: "მიწისქვეშა მცოცავი მცოცავი (შტატი | პროვინცია | ტერიტორია | რეგიონი | დასახლება)'
დარჩენილი ენერგია: "ნარჩენი სიცოცხლისუნარიანობა"
კინეტიკური ენერგია: "საავტომობილო სიცოცხლისუნარიანობა"
გულუბრყვილო ბეისი: "(საიდუმლო | უდანაშაულო | გულუბრყვილო) ბეისი"
პირადი ციფრული ასისტენტი (PDA): "ინდივიდუალური კომპიუტერიზებული თანამშრომელი"
2021 წლის მაისში მკვლევარებმა გამოიკითხეს ზომები აკადემიური საძიებო სისტემა ეძებს ამ ტიპის დაზიანებულ, ავტომატიზირებულ ენას, ზრუნავს ისეთი ლეგიტიმური ფრაზების გამორიცხვაზე, როგორიცაა „უზარმაზარი ინფორმაცია“ (რაც სწორი ფრაზაა და არა „დიდი მონაცემების“ წარუმატებელი სინონიმი). ამ დროს მათ დააფიქსირეს მიკროპროცესორები და მიკროსისტემები ჰქონდა არასწორად დამუშავებული პერიფრაზირების შემთხვევების ყველაზე მეტი შემთხვევა.
ამ დროისთვის ჯერ კიდევ შესაძლებელია ვიღებ (არქივის სურათი, 15/07/2021) არაერთი სამეცნიერო ნაშრომი უაზრო ფრაზისთვის „ღრმა ნერვული ორგანიზაცია“ (ანუ „ღრმა ნეირონული ქსელი“) და სხვა ზემოაღნიშნულ ჩამონათვალში მსგავს დარტყმებს იძლევა.
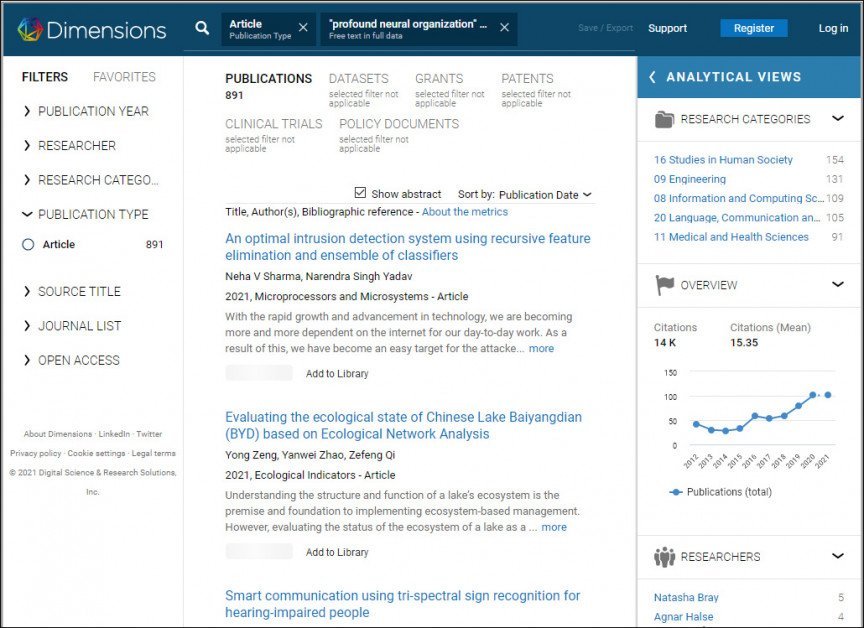
ძიების შედეგები 'ღრმა ნერვული ორგანიზაცია' ('ღრმა ნერვული ქსელი') Dimensions-ზე. წყარო: https://app.dimensions.ai/
ის მიკროპროცესორები ჟურნალი დაარსდა 1976 წელს და ეწოდა მიკროპროცესორები და მიკროსისტემები ორი წლის შემდეგ.
უაზრო ენის ზრდა
მკვლევარებმა შეისწავლეს პერიოდი 2018 წლის თებერვლიდან 2021 წლის ივნისამდე და დააფიქსირეს წარდგენის მოცულობის მკვეთრი ზრდა ბოლო ორი წლის განმავლობაში და განსაკუთრებით ბოლო 6-8 თვის განმავლობაში:
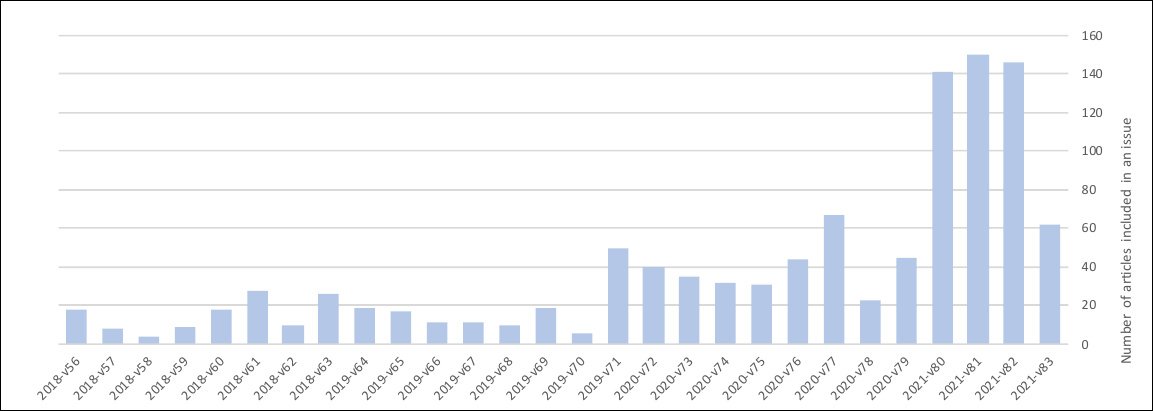
კორელაცია თუ მიზეზობრიობა? Microprocessors and Microsystems-ის ჟურნალში წარდგენის ზრდა, როგორც ჩანს, ემთხვევა „უაზრო“ ტექსტისა და სინონიმების ზრდას აშკარად პატივცემულ წინადადებებში. წყარო: https://arxiv.org/pdf/2107.06751.pdf
თანამშრომლების მიერ შეგროვებული საბოლოო მონაცემთა ნაკრები შეიცავს 1,078 სრულმეტრაჟიან სტატიას, რომლებიც მიღებულ იქნა ტულუზის უნივერსიტეტის Elsevier გამოწერით.
ჩინური სამეცნიერო ნაშრომების სარედაქციო ზედამხედველობის შემცირება
ნაშრომი აღნიშნავს, რომ დროშით მონიშნული წინადადებების სარედაქციო შეფასებისთვის გამოყოფილი დრო რადიკალურად მცირდება 2021 წელს და დაეცემა 40 დღემდე; თანატოლთა მიმოხილვის სტანდარტული დროის ექვსჯერ შემცირება, რაც აშკარაა 2021 წლის თებერვლიდან.
დროშით მონიშნული ნაშრომების უდიდესი რაოდენობა წარმოიშვა მატერიკული ჩინეთის კუთვნილი ავტორებისგან: 404 ნაშრომიდან მიღებული 30 დღეზე ნაკლები ხნის განმავლობაში, 97.5% ჩინეთთან არის დაკავშირებული. პირიქით, იმ შემთხვევებში, როდესაც სარედაქციო პროცესი აღემატებოდა 40 დღეს (615 ნაშრომი), ჩინეთთან დაკავშირებული წარდგინებები წარმოადგენდა ამ კატეგორიის მხოლოდ 9.5%-ს - ათჯერადი დისბალანსი.
მოხსენება მიაწერს დროშით მონიშნული ნაშრომების შეღწევას სარედაქციო პროცესში ხარვეზებს და რესურსების შესაძლო ნაკლებობას წინადადებების მზარდი რაოდენობის ფონზე.
მკვლევარები ვარაუდობენ, რომ GPT-ის სტილის გენერაციული მოდელები და მსგავსი ტიპის ენის გენერირების ჩარჩოები გამოყენებული იქნა დროშით მონიშნულ ნაშრომებში ტექსტის დიდი ნაწილის შესაქმნელად; თუმცა, გზა, რომლითაც გენერაციული მოდელი აბსტრაქტებს თავის წყაროებს, ამის დამტკიცებას ართულებს და მთავარი მტკიცებულება მდგომარეობს ცუდი და არასაჭირო სინონიმების საღი აზრის შეფასებაში და წარდგენის ლოგიკური თანმიმდევრულობის საფუძვლიან გამოკვლევაში.
მკვლევარები ასევე აკვირდებიან, რომ გენერაციულ ენობრივ მოდელებს, რომლებიც მათი აზრით, ხელს უწყობენ სისულელეების ამ ნაკადს, შეუძლიათ არა მხოლოდ შექმნან პრობლემური ტექსტები, არამედ ამოიცნონ ისინი და სისტემატურად მონიშნონ ისინი, ისევე, როგორც თავად მკვლევარებმა განახორციელეს. ხელით. ნამუშევარი დეტალურად აღწერს ამგვარ იმპლემენტაციას GPT-2-ის გამოყენებით და გთავაზობთ ჩარჩოს მომავალი სისტემებისთვის პრობლემური სამეცნიერო წარდგენის იდენტიფიცირებისთვის.
„დაბინძურებული“ წარდგენის სიხშირე გაცილებით მაღალია Elsevier-ის ჟურნალში (72.1%) სხვა შესწავლილ ჟურნალებთან შედარებით (მაქსიმუმ 13.6%).
არა მხოლოდ სემანტიკა
მკვლევარები ხაზს უსვამენ, რომ მრავალი ჟურნალი იყენებს არა მხოლოდ არასწორ ენას, არამედ შეიცავს მეცნიერულად არაზუსტ განცხადებებს, რაც მიუთითებს იმაზე, რომ გენერაციული ენის მოდელები გამოიყენება არა მხოლოდ მეცნიერთა შეზღუდული ენობრივი უნარების გასაუმჯობესებლად, არამედ რეალურად გამოიყენება ნაშრომში არსებული რამდენიმე ძირითადი თეორემისა და მონაცემის ფორმულირებისთვის.
სხვა შემთხვევებში, მკვლევარები ასახელებენ აბსტრაქტული (და უმაღლესი) წინა ნაშრომის ეფექტურ „რესინთეზს“ ან „დატრიალებას“, რათა დააკმაყოფილონ „გამოქვეყნება ან დაღუპვა“ აკადემიური კვლევის კულტურების ზეწოლა და, შესაძლოა, გააუმჯობესონ ეროვნული რეიტინგები გლობალურ წინასწარ გამორჩეულობა ხელოვნური ინტელექტის კვლევაში, დიდი მოცულობის წყალობით.

უაზრო შინაარსი წარდგენილ ნაშრომში. ამ შემთხვევაში, მკვლევარებმა დაადგინეს, რომ ტექსტი მომდინარეობს, ad hoc, ა EDN სტატია, საიდანაც თანმხლები ილუსტრაცია ასევე გატაცებულია ატრიბუტის გარეშე. ორიგინალური შინაარსის ხელახლა დაწერა იმდენად ექსტრემალურია, რომ მას უაზროდ აქცევს.
Elsevier-ის რამდენიმე წარმოდგენილი ნაშრომის გაანალიზებისას, მკვლევარებმა იპოვეს წინადადებები, რომელთა მნიშვნელობის დადგენა ვერ მოხერხდა; ცნობები არარსებულ ლიტერატურაზე; მითითებები ცვლადებსა და თეორემებზე ფორმულებში, რომლებიც რეალურად არ ჩანდნენ დამხმარე მასალაში (ვარაუდობენ ენაზე დაფუძნებულ აბსტრაქციას, ან 'ჰალუცინაციააშკარად ფაქტობრივი მონაცემები); და სურათების ხელახალი გამოყენება მათი წყაროების აღიარების გარეშე (რასაც მკვლევარები აკრიტიკებენ არა საავტორო უფლებების თვალსაზრისით, არამედ როგორც არაადეკვატური სამეცნიერო სიმკაცრის მაჩვენებელი).
ციტირების წარუმატებლობა
სამეცნიერო ნაშრომში არგუმენტების მხარდასაჭერად გამიზნული ციტატები, დროშის მქონე ბევრ მაგალითში აღმოჩნდა, რომ „ან გატეხილი იყო ან მიგვიყვანდა დაუკავშირებელ პუბლიკაციებამდე“.
გარდა ამისა, მითითებები "დაკავშირებულ ნაშრომზე" აშკარად ხშირად მოიცავს ავტორებს, რომლებიც მკვლევარების აზრით, "ჰალუცინირებული" იყვნენ GPT-ის სტილის სისტემით.
მოხეტიალე ყურადღება
უახლესი ენობრივი მოდელების კიდევ ერთი ნაკლი, როგორიცაა GPT-3, არის მათი ტენდენცია, დაკარგონ ყურადღება ხანგრძლივი დისკურსის დროს. მკვლევარებმა დაადგინეს, რომ დროშით მონიშნული ნაშრომები ხშირად ასახავს თემას ნაშრომის დასაწყისში, რომელიც რეალურად არასოდეს დაბრუნდება მას შემდეგ, რაც იგი პირველად იქნება გაშუქებული წინასწარ ჩანაწერებში ან სხვაგან.
ისინი ასევე ვარაუდობენ, რომ ზოგიერთი ყველაზე ცუდი მაგალითი წარმოიქმნება წყაროს ტექსტის მრავალჯერადი მოგზაურობის დროს მთარგმნელობითი ძრავების სერიის მეშვეობით, თითოეული მათგანი კიდევ უფრო ამახინჯებს მნიშვნელობას.
წყაროები და მიზეზები
მცდელობისას გაარკვიონ რა დგას ამ ფენომენის მიღმა, ნაშრომის ავტორები გვთავაზობენ რამდენიმე შესაძლებლობას: რომ შინაარსი ქაღალდის ქარხნები გამოიყენება როგორც წყარო, უზუსტობების დანერგვა ძალიან ადრეულ პროცესში, რაც აუცილებლად გამოიწვევს შემდგომ უზუსტობებს; რომ სტატიების დაწნვის ხელსაწყოები, როგორიცაა Spinbot, გამოიყენება პლაგიატის დასაფარად; და რომ რეგულარულად გამოქვეყნებაზე დიდი ზეწოლა აიძულებს მკვლევარებს, რომლებსაც არ აქვთ რესურსები, გამოიყენონ GPT-3-ის სტილის სისტემები ახალი აკადემიური ნაშრომების გასაზრდელად ან მთლიანად შესაქმნელად.
მკვლევარები ასრულებენ მოწოდებით მოქმედებისკენ უფრო მეტი ზედამხედველობისა და გაუმჯობესებული სტანდარტების აკადემიური გამოცემის სფეროში, რომელიც აშკარად ამტკიცებს, რომ ხდება საკვები საკუთარი საგნისთვის - მანქანათმცოდნეობის სისტემები. ისინი ასევე სთხოვენ Elsevier-ს და სხვა გამომცემლებს დანერგონ უფრო მკაცრი სკრინინგის და განხილვის პროცედურები და ფართოდ აკრიტიკებენ ამ კუთხით მიმდინარე სტანდარტებსა და პრაქტიკას, რაც ვარაუდობს, რომ "სინთეტიკური ტექსტებით მოტყუება საფრთხეს უქმნის სამეცნიერო ლიტერატურის მთლიანობას.'















