
ხელოვნური ინტელექტი
AI-ზე ორიენტირებული მიკერძოების შემოწმება ახალი ამბების სტატიებისთვის, ხელმისაწვდომია პითონში

მკვლევარები კანადაში, ინდოეთში, ჩინეთში და ავსტრალიაში თანამშრომლობდნენ, რათა შეექმნათ თავისუფლად ხელმისაწვდომი Python პაკეტი, რომელიც შეიძლება ეფექტურად იქნას გამოყენებული ახალი ამბების ასლში „არასამართლიანი ენის“ დასადგენად და ჩანაცვლებისთვის.
სისტემა, სახელწოდებით დბიასი, იყენებს მანქანათმცოდნეობის სხვადასხვა ტექნოლოგიებსა და მონაცემთა ბაზებს სამეტაპიანი წრიული სამუშაო ნაკადის შესაქმნელად, რომელსაც შეუძლია დახვეწოს მიკერძოებული ტექსტი სანამ არ დააბრუნებს მიუკერძოებელ, ან თუნდაც უფრო ნეიტრალურ ვერსიას.

ჩატვირთული ენა ახალი ამბების ფრაგმენტში, რომელიც იდენტიფიცირებულია, როგორც "მიკერძოებული", Dbias-ის მიერ გარდაიქმნება ნაკლებად გამაღიზიანებელ ვერსიად. წყარო: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
სისტემა წარმოადგენს მრავალჯერად გამოყენებადი და თვითკმარი მილსადენს, რომელიც შეიძლება იყოს დაინსტალირებული Pip-ის საშუალებით Hugging Face-დან და ინტეგრირებულია არსებულ პროექტებში, როგორც დამატებითი ეტაპი, დანამატი ან დანამატი.
აპრილში მსგავსი ფუნქციონირება განხორციელდა Google Docs-ში კრიტიკის ქვეშ მოექცა, განსაკუთრებით მისი რედაქტირების ნაკლებობის გამო. მეორეს მხრივ, Dbias შეიძლება იყოს უფრო შერჩევითი ტრენინგი ახალი ამბების ნებისმიერ კორპუსზე, რომელიც მოისურვებს საბოლოო მომხმარებელს, შეინარჩუნებს უნარს შეიმუშაოს შეკვეთილი სამართლიანობის სახელმძღვანელო მითითებები.
კრიტიკული განსხვავება ისაა, რომ Dbias მილსადენის მიზანია ავტომატურად გარდაქმნას "დატვირთული ენა" (სიტყვები, რომლებიც ამატებენ კრიტიკულ ფენას ფაქტობრივ კომუნიკაციას) ნეიტრალურ ან პროზაულ ენად, ვიდრე მომხმარებლის მუდმივი სწავლებისთვის. არსებითად, საბოლოო მომხმარებელი განსაზღვრავს ეთიკურ ფილტრებს და შესაბამისად მოამზადებს სისტემას; Google Docs-ის მიდგომით, სისტემა – სავარაუდოდ – ასწავლის მომხმარებელს ცალმხრივად.
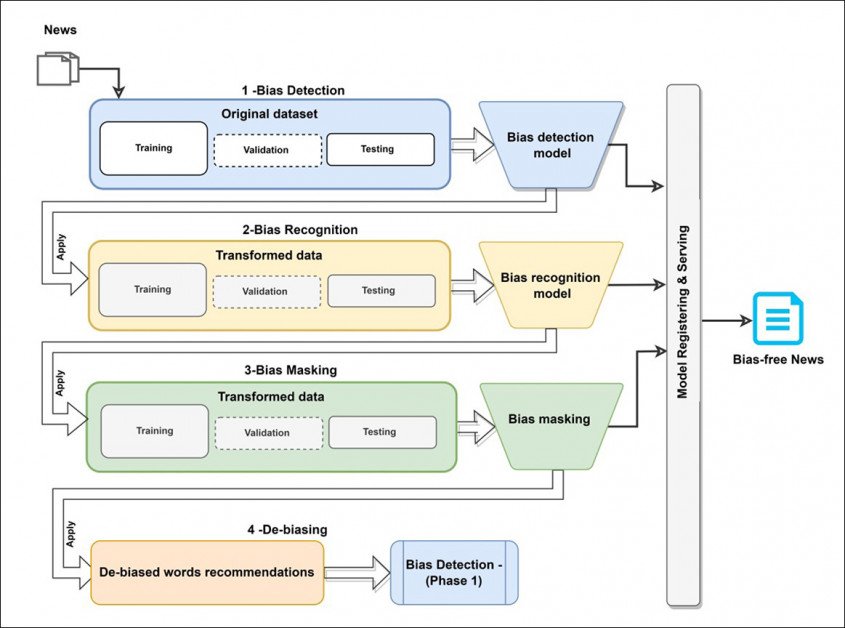
კონცეპტუალური არქიტექტურა Dbias სამუშაო ნაკადისთვის.
მკვლევარების აზრით, Dbias არის პირველი ნამდვილად კონფიგურირებადი მიკერძოების გამოვლენის პაკეტი, განსხვავებით თაროზე მომზადებული ასამბლეის პროექტებისგან, რომლებიც ახასიათებს ბუნებრივი ენის დამუშავების ამ ქვესექტორს დღემდე.
ის ახალი ქაღალდი სახელდება მიდგომა ახალი ამბების სტატიებში სამართლიანობის უზრუნველსაყოფადდა მოდის ტორონტოს უნივერსიტეტის, ტორონტოს მეტროპოლიტენის უნივერსიტეტის, ბანგალორის გარემოსდაცვითი რესურსების მენეჯმენტის, ჩინეთის მეცნიერებათა DeepBlue აკადემიისა და სიდნეის უნივერსიტეტის კონტრიბუტორებისგან.
მეთოდი
პირველი მოდული დბიასში არის მიკერძოების გამოვლენა, რომელიც იყენებს DistilBERT პაკეტი – ძალიან ოპტიმიზირებული ვერსია Google-ის საკმაოდ მანქანური ინტენსიურობით ბერტი. პროექტისთვის, DistilBERT კარგად იყო მორგებული მედია მიკერძოების ანოტაციაზე (MBIC) მონაცემთა ბაზა.

MBIC შედგება ახალი ამბების სტატიებისგან სხვადასხვა მედია წყაროებიდან, მათ შორის Huffington Post, USA Today და MSNBC. მკვლევარებმა გამოიყენეს მონაცემთა ნაკრების გაფართოებული ვერსია.
მიუხედავად იმისა, რომ თავდაპირველი მონაცემები ანოტაციას ახდენდნენ crowdsourced მუშაკების მიერ (მეთოდი, რომელიც ცეცხლი გაუჩნდა 2021 წლის ბოლოს), ახალი ნაშრომის მკვლევარებმა შეძლეს დაედგინათ მონაცემთა ნაკრების მიკერძოების დამატებითი არალეგირებული შემთხვევები და ხელით დაურთოთ ისინი. მიკერძოების გამოვლენილი შემთხვევები, რომლებიც დაკავშირებულია რასასთან, განათლებასთან, ეთნიკურ კუთვნილებასთან, ენასთან, რელიგიასთან და სქესთან.
შემდეგი მოდული, მიკერძოების აღიარება, იყენებს სახელის სახელის აღიარება (NER) მიკერძოებული სიტყვების გამოყოფა შეყვანის ტექსტიდან. ნაშრომში ნათქვამია:
მაგალითად, ახალი ამბები „არ იყიდო ფსევდომეცნიერული აჟიოტაჟი ტორნადოსა და კლიმატის ცვლილების შესახებ“ კლასიფიცირებულია, როგორც მიკერძოებული წინა მიკერძოების გამოვლენის მოდულის მიერ და მიკერძოებული ამოცნობის მოდული ახლა შეუძლია განსაზღვროს ტერმინი „ფსევდომეცნიერული აჟიოტაჟი“ როგორც მიკერძოებული სიტყვა“.
NER არ არის სპეციალურად შექმნილი ამ ამოცანისთვის, მაგრამ გამოყენებულია ადრე მიკერძოების იდენტიფიკაციისთვის, განსაკუთრებით ა 2021 პროექტი დიდი ბრიტანეთის დურჰამის უნივერსიტეტიდან.
ამ ეტაპისთვის მკვლევარებმა გამოიყენეს რობერტა კომბინირებული SpaCy English Transformer NER მილსადენთან.

შემდეგი ეტაპი, მიკერძოების ნიღაბი, მოიცავს იდენტიფიცირებული მიკერძოებული სიტყვების ახალ მრავალ ნიღბს, რომელიც მოქმედებს თანმიმდევრულად მრავალი გამოვლენილი მიკერძოებული სიტყვის შემთხვევაში.

დბიასის მესამე ეტაპზე დატვირთული ენა იცვლება პრაგმატული ენით. გაითვალისწინეთ, რომ „პირისპირება“ და „გამოყენება“ ერთსა და იმავე მოქმედებას უტოლდება, თუმცა პირველი დამცინავად ითვლება.
საჭიროებისამებრ, ამ ეტაპის გამოხმაურება კვლავ გაიგზავნება მილსადენის დასაწყისში შემდგომი შეფასებისთვის, სანამ არ იქნება გენერირებული რამდენიმე შესაფერისი ალტერნატიული ფრაზები ან სიტყვა. ეს ეტაპი იყენებს ნიღბიანი ენის მოდელირებას (სახლიდან) მიერ დადგენილი ხაზების გასწვრივ 2021 წლის თანამშრომლობა Facebook Research-ის ხელმძღვანელობით.
ჩვეულებრივ, MLM დავალება შემთხვევით ნიღბავს სიტყვების 15%-ს, მაგრამ Dbias-ის სამუშაო პროცესი ეუბნება პროცესს, რომ იდენტიფიცირებული მიკერძოებული სიტყვები მიიღოს შეყვანად.
არქიტექტურა დანერგილი და გაწვრთნილი იქნა Google Colab Pro-ზე NVIDIA P100-ზე 24 GB VRAM-ით 16 პარტიული ზომით, მხოლოდ ორი ეტიკეტის გამოყენებით (მიკერძოებული მდე მიუკერძოებელი).
ტესტები
მკვლევარებმა შეამოწმეს Dbias ხუთი შესადარებელი მიდგომის წინააღმდეგ: LG-TFIDF ერთად ლოგისტიკური რეგრესია მდე TfidfVetorizer (TFIDF) სიტყვების ჩასმა; LG-ELMO; MLP-ELMO (მიწოდების ხელოვნური ნერვული ქსელი, რომელიც შეიცავს ELMO ჩაშენებებს); BERT; და რობერტა.
ტესტებისთვის გამოყენებული მეტრიკა იყო სიზუსტე (ACC), სიზუსტე (PREC), გახსენება (Rec) და F1 ქულა. ვინაიდან მკვლევარებმა არ იცოდნენ რაიმე არსებული სისტემის შესახებ, რომელსაც შეეძლო სამივე ამოცანის შესრულება ერთ მილსადენში, კონკურენტი ჩარჩოებისთვის დისპენსირება გაკეთდა მხოლოდ Dbias-ის ძირითადი ამოცანების შეფასებით - მიკერძოების გამოვლენა და აღიარება.

შედეგები Dbias-ის ცდებიდან.
Dbias-მა მოახერხა ყველა კონკურენტული ჩარჩოს შედეგების გადალახვა, მათ შორის უფრო მძიმე დამუშავების კვალი.
ნაშრომში ნათქვამია:
შედეგი ასევე აჩვენებს, რომ ღრმა ნერვულ ჩანერგვას, ზოგადად, შეუძლია აღემატებოდეს ტრადიციული ჩაშენების მეთოდებს (მაგ., TFIDF) მიკერძოების კლასიფიკაციის ამოცანაში. ამას ადასტურებს ღრმა ნერვული ქსელის ჩაშენების (ანუ ELMO) უკეთესი შესრულება TFIDF ვექტორიზაციასთან შედარებით LG-თან გამოყენებისას.
ეს ალბათ იმიტომ ხდება, რომ ღრმა ნერვულ ჩანერგვას უკეთ შეუძლია ტექსტის სიტყვების კონტექსტი სხვადასხვა კონტექსტში აღბეჭდოს. ღრმა ნერვული ჩანერგვა და ღრმა ნერვული მეთოდები (MLP, BERT, RoBERTa) ასევე უკეთესად მუშაობს, ვიდრე ტრადიციული ML მეთოდი (LG).'
მკვლევარები ასევე აღნიშნავენ, რომ ტრანსფორმატორზე დაფუძნებული მეთოდები აჯობებს კონკურენტ მეთოდებს მიკერძოების გამოვლენაში.
დამატებითი ტესტი მოიცავდა შედარებას Dbias-სა და SpaCy Core Web-ის სხვადასხვა გემოს შორის, მათ შორის core-sm (პატარა), core-md (საშუალო) და core-lg (დიდი). დბიასმა ასევე შეძლო გამგეობის ლიდერობა ამ ტესტებში:

მკვლევარები ასკვნიან, რომ მიკერძოების ამოცნობის ამოცანები ზოგადად აჩვენებენ უკეთეს სიზუსტეს უფრო დიდ და ძვირადღირებულ მოდელებში, მათი ვარაუდით, პარამეტრების და მონაცემთა წერტილების გაზრდილი რაოდენობის გამო. ისინი ასევე აკვირდებიან, რომ ამ სფეროში მომავალი მუშაობის ეფექტურობა დამოკიდებული იქნება უფრო დიდ ძალისხმევაზე მაღალი ხარისხის მონაცემთა ნაკრების ანოტაციისთვის.
ტყე და ხეები
ვიმედოვნებთ, რომ მიკერძოების ამოცნობის ამგვარი წვრილმარცვლოვანი პროექტი საბოლოოდ ჩაერთვება მიკერძოების ძიების ჩარჩოებში, რომლებსაც შეუძლიათ ნაკლებად მიოპიური ხედვა და გაითვალისწინონ, რომ რომელიმე კონკრეტული ამბის გაშუქების არჩევა თავისთავად არის მიკერძოების აქტი, რომელიც პოტენციურად არის. განპირობებულია არა მხოლოდ მოხსენებული ნახვის სტატისტიკით.
პირველად გამოქვეყნდა 14 წლის 2022 ივლისს.















