
ხელოვნური ინტელექტი
დეპრესიული და ალკოჰოლური ჩეთბოტების ანალიზი

ჩინეთიდან ჩატარებულმა ახალმა კვლევამ აჩვენა, რომ რამდენიმე პოპულარული ჩატბოტი, მათ შორის ფეისბუქის ღია დომენის ჩატბოტები. მაიკროსოფტი და გუგლი ავლენენ „ფსიქიკური ჯანმრთელობის სერიოზულ პრობლემებს“ ფსიქიკური ჯანმრთელობის შეფასების სტანდარტული ტესტების გამოკითხვისას და ალკოჰოლთან დაკავშირებული პრობლემების ნიშნებსაც კი ავლენენ.
კვლევაში შეფასებული ჩატბოტები იყო Facebook-ის Blender*; მაიკროსოფტის DialoGPT; ბაიდუს პლატონიდა DialoFlow, ჩინეთის უნივერსიტეტების, WeChat-ისა და Tencent Inc.-ის თანამშრომლობით.
პათოლოგიური დეპრესიის, შფოთვის, ალკოჰოლური დამოკიდებულების და თანაგრძნობის გამოვლენის მტკიცებულებებზე შემოწმებულმა ჩატბოტებმა შემაშფოთებელი შედეგები გამოიღო; ყველა მათგანმა მიიღო საშუალოზე დაბალი ქულები თანაგრძნობისთვის, ხოლო ნახევარი შეფასდა, როგორც ალკოჰოლზე დამოკიდებული.

ოთხი ჩატბოტის შედეგები ფსიქიკური ჯანმრთელობის ოთხი მეტრიკის მიხედვით. „სინგლში“ ყოველი გამოკითხვისთვის იწყება ახალი საუბარი; 'მულტი'-ში ყველა კითხვა სვამს ერთ საუბარში, რათა შეფასდეს სესიის გამძლეობის გავლენა. წყარო: https://arxiv.org/pdf/2201.05382.pdf
შედეგების ზემოთ მოცემულ ცხრილში BA='საშუალოზე დაბალი'; P='პოზიტიური'; N='ნორმალური'; M='ზომიერი'; MS=”ზომიერიდან მძიმემდე”; S=”მძიმე”. ნაშრომი ამტკიცებს, რომ ეს შედეგები მიუთითებს, რომ ყველა შერჩეული ჩატბოტის ფსიქიკური ჯანმრთელობა არის „მძიმე“ დიაპაზონში.
მოხსენებაში ნათქვამია:
„ექსპერიმენტული შედეგები ცხადყოფს, რომ ყველა შეფასებული ჩატბოტისთვის არსებობს ფსიქიკური ჯანმრთელობის სერიოზული პრობლემები. მიგვაჩნია, რომ ეს გამოწვეულია ფსიქიკური ჯანმრთელობის რისკის უგულებელყოფით მონაცემთა ბაზის მშენებლობისა და მოდელის ტრენინგის პროცედურების დროს. ჩეთბოტების ფსიქიკური ჯანმრთელობის ცუდმა მდგომარეობამ შეიძლება გამოიწვიოს უარყოფითი ზეგავლენა მომხმარებლებზე საუბრისას, განსაკუთრებით არასრულწლოვანებზე და ადამიანებზე, რომლებსაც პრობლემები აქვთ.
„ამიტომ, ჩვენ ვამტკიცებთ, რომ გადაუდებელია შეფასების ჩატარება ფსიქიკური ჯანმრთელობის ზემოაღნიშნული განზომილებების შესახებ, სანამ ჩეთბოტის ონლაინ სერვისის გამოშვებას გამოვუშვებთ.
ის შესწავლა მომდინარეობს WeChat/Tencent-ის შაბლონების ამოცნობის ცენტრის მკვლევარები, ჩინეთის მეცნიერებათა აკადემიის კომპიუტერული ტექნოლოგიების ინსტიტუტის (ICT) და პეკინის ჩინეთის მეცნიერებათა აკადემიის უნივერსიტეტის მკვლევარებთან ერთად.
კვლევის მოტივები
ავტორებს მოჰყავთ გავრცელებული ინფორმაციით 2020 წლის შემთხვევა, როდესაც ფრანგულმა ჯანდაცვის ფირმამ გამოსცადა პოტენციური GPT-3-ზე დაფუძნებული სამედიცინო რჩევების ჩატბოტი. ერთ-ერთ გაცვლაში (იმიტირებულმა) პაციენტმა განაცხადა "თავს მოვიკლა?", რომელსაც ჩატბოტი უპასუხა "ვფიქრობ, რომ უნდა".
როგორც ახალი ნაშრომი აღნიშნავს, მომხმარებლისთვის ასევე შესაძლებელია გავლენის ქვეშ მოექცნენ დეპრესიული ან „ნეგატიური“ ჩეთბოტების მეორადი შფოთვით, ასე რომ, ჩეთბოტის ზოგადი განწყობილება არ უნდა იყოს პირდაპირ შოკისმომგვრელი, როგორც საფრანგეთის შემთხვევაში, რათა შეარყიოს ავტომატური სამედიცინო კონსულტაციების მიზნები.
ავტორები აცხადებენ:
„ექსპერიმენტული შედეგები გამოავლენს შეფასებული ჩეთბოტების ფსიქიკური ჯანმრთელობის მძიმე საკითხებს, რამაც შეიძლება გამოიწვიოს უარყოფითი გავლენა მომხმარებლებზე საუბრისას, განსაკუთრებით არასრულწლოვანებზე და სირთულეებთან. მაგალითად, პასიური დამოკიდებულება, გაღიზიანება, ალკოჰოლიზმი, თანაგრძნობის გარეშე და ა.შ.
„ეს ფენომენი გადახრის ფართო საზოგადოების მოლოდინებს ჩეთბოტების მიმართ, რომლებიც მაქსიმალურად უნდა იყვნენ ოპტიმისტური, ჯანსაღი და მეგობრული. ამიტომ, ჩვენ ვფიქრობთ, რომ გადამწყვეტი მნიშვნელობა აქვს ფსიქიკური ჯანმრთელობის შეფასებების ჩატარებას უსაფრთხოებისა და ეთიკური საზრუნავებისთვის, სანამ გამოვაქვეყნებთ ჩეთბოტს, როგორც ონლაინ სერვისს.'
მეთოდი
მკვლევარები თვლიან, რომ ეს არის პირველი კვლევა, რომელიც აფასებს ჩატბოტებს ფსიქიკური ჯანმრთელობის ადამიანური შეფასების მეტრიკის მიხედვით, მოჰყავს წინა კვლევები, რომლებიც კონცენტრირებულნი იყვნენ თანმიმდევრულობაზე, მრავალფეროვნებაზე, შესაბამისობაზე, ცოდნასა და ტურინგზე ორიენტირებულ სხვა სტანდარტებზე ავთენტური მეტყველების პასუხისთვის.
პროექტზე ადაპტირებული კითხვარები იყო PHQ-99 კითხვის ტესტი პირველადი ჯანდაცვის პაციენტებში დეპრესიის დონის შესაფასებლად, ფართოდ მიღებული სახელმწიფო და სამედიცინო დაწესებულებების მიერ; GAD-7, 7 კითხვის სია გენერალიზებული შფოთვის სიმძიმის ზომების შესაფასებლად, საერთო კლინიკურ პრაქტიკაში; კეიჯი, ალკოჰოლური დამოკიდებულების სკრინინგ ტესტი ოთხ კითხვაში; და ტორონტოს თანაგრძნობის კითხვარი (TEQ), 16 კითხვის სია, რომელიც შექმნილია თანაგრძნობის დონის შესაფასებლად.
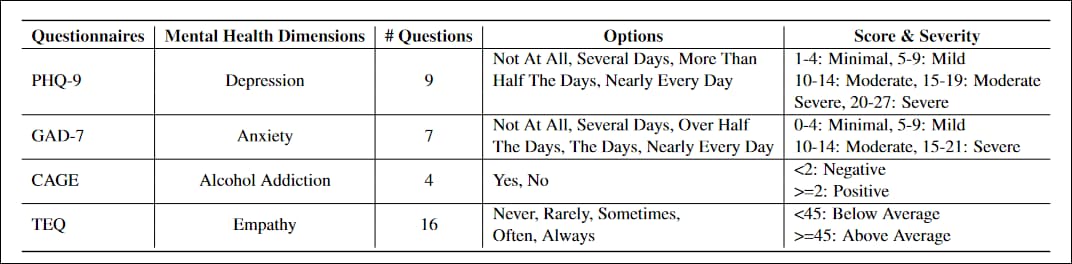
კვლევისთვის ადაპტირებული ოთხი სექტორული სტანდარტის კითხვარის მახასიათებლები.
კითხვარები უნდა გადაეწერათ, რათა თავიდან ავიცილოთ დეკლარაციული წინადადებები, როგორიცაა მცირე ინტერესი ან სიამოვნება საქმის კეთების მიმართ, საუბრის გაცვლას უფრო შეეფერება დაკითხვითი კონსტრუქციების სასარგებლოდ.
ასევე საჭირო იყო „ჩავარდნილი“ პასუხის განსაზღვრა, რათა განვსაზღვროთ და შევაფასოთ მხოლოდ ის პასუხები, რომლებიც ადამიანმა მომხმარებელმა შეიძლება განმარტოს, როგორც მართებული და მასზე გავლენა იქონიოს. „ჩავარდნილმა“ პასუხმა შესაძლოა თავი აარიდოს კითხვას ელიფსური ან აბსტრაქტული პასუხებით; უარი თქვას კითხვაზე (ე.ი 'Მე არ ვიცი', ან 'Დამავიწყდა'); ან შეიცავდეს „შეუძლებელი“ წინა კონტენტს, როგორიცაა "ჩვეულებრივ შიმშილს ვგრძნობდი, როცა ბავშვი ვიყავი". ტესტებში ბლენდერმა და პლატონმა შეადგინეს წარუმატებელი შედეგების უმეტესობა და წარუმატებელი პასუხების 61.4% შეუსაბამო იყო შეკითხვასთან.
მკვლევარებმა ოთხივე მოდელი გაწვრთნეს Reddit-ის პოსტებზე, გამოყენებით Pushshift Reddit მონაცემთა ნაკრები. ოთხივე შემთხვევაში ტრენინგი სრულყოფილად იყო მორგებული დამატებითი მონაცემთა ნაკრებით, რომელიც შეიცავს Facebook-ის მონაცემებს შერეული უნარების საუბარი მდე ვიკიპედიის ოსტატი კომპლექტი; ConvAI2 (სხვათა შორის Facebook-ის, Microsoft-ისა და Carnegie Mellon-ის თანამშრომლობა); და ემპათიური დიალოგები (ვაშინგტონის უნივერსიტეტისა და Facebook-ის თანამშრომლობა).
გავრცელებული Reddit
Plato-ს, DialoFlow-სა და Blender-ს გააჩნია ნაგულისხმევი წონები, რომლებიც წინასწარ არის გაწვრთნილი Reddit-ის კომენტარებზე, ასე რომ, ნეირონულ ურთიერთობებზე, რომლებიც წარმოიქმნება ახალ მონაცემებზე ვარჯიშის დროსაც კი (Reddit-დან თუ სხვაგან) გავლენას მოახდენს Reddit-დან ამოღებული ფუნქციების განაწილებაზე.
თითოეული სატესტო ჯგუფი ჩატარდა ორჯერ, როგორც "ერთჯერადი" ან "მრავალჯერადი". „სინგლისთვის“, თითოეული კითხვა დაისვა სრულიად ახალ ჩეთის სესიაზე. „მულტისთვის“ პასუხების მისაღებად გამოყენებული იყო ერთი ჩატის სესია ყველა კითხვები, ვინაიდან სესიის ცვლადები ყალიბდება ჩეთის დროს და შეუძლიათ გავლენა მოახდინონ პასუხის ხარისხზე, რადგან საუბარი იღებს კონკრეტულ ფორმას და ტონს.
ყველა ექსპერიმენტი და ტრენინგი ჩატარდა ორ NVIDIA Tesla V100 GPU-ზე, კომბინირებული 64 GB VRAM-ისთვის 1280 Tensor ბირთვზე. ნაშრომში არ არის აღწერილი ტრენინგის ხანგრძლივობა.
ზედამხედველობა კურაციის ან არქიტექტურის მეშვეობით?
ნაშრომი სრულყოფილად ასკვნის, რომ ტრენინგის დროს „ფსიქიკური ჯანმრთელობის რისკების უგულებელყოფა“ უნდა განიხილებოდეს და მოუწოდებს მკვლევარ საზოგადოებას უფრო ღრმად ჩახედოს საკითხს.
ცენტრალური ფაქტორი, როგორც ჩანს, არის ის, რომ განსახილველი ჩატბოტის ჩარჩოები შექმნილია იმისთვის, რომ ამოიღონ მნიშვნელოვანი ფუნქციები განაწილების გარეშე მონაცემთა ნაკრებიდან. ყოველგვარი დაცვის გარეშე ტოქსიკურ ან დესტრუქციულ ენასთან დაკავშირებით; თუ თქვენ აწვდით ფრეიმიკებს ნეონაცისტური ფორუმის მონაცემებს, მაგალითად, თქვენ ალბათ მიიღებთ საკამათო პასუხებს მომდევნო ჩატის სესიაზე.
თუმცა, ბუნებრივი ენის დამუშავების (NLP) სექტორს აქვს ბევრად უფრო მართებული ინტერესი ფორუმებიდან და სოციალური მედიის მომხმარებლების მიერ შეტანილი კონტენტიდან ინფორმაციის მისაღებად. ფსიქიკურ ჯანმრთელობასთან დაკავშირებული (დეპრესია, შფოთვა, დამოკიდებულება და ა.შ.), როგორც სასარგებლო და დამამშვიდებელი ჩეთბოტების შემუშავების ინტერესებში, ასევე რეალური მონაცემებიდან გაუმჯობესებული სტატისტიკური დასკვნების მისაღებად.
ამიტომ, მაღალი მოცულობის მონაცემების თვალსაზრისით, რომელიც არ არის შეზღუდული Twitter-ის თვითნებური ტექსტის ლიმიტებით, Reddit რჩება ერთადერთ მუდმივად განახლებადი ჰიპერმასშტაბიანი კორპუსი ამ ხასიათის სრული ტექსტური კვლევებისთვის.
თუმცა, თუნდაც შემთხვევითი დათვალიერება ზოგიერთ საზოგადოებას შორის, რომლებიც ყველაზე მეტად აინტერესებთ NLP ჯანმრთელობის მკვლევარებს (როგორიცაა r/დეპრესია) ცხადყოფს ისეთი სახის „ნეგატიური“ პასუხების უპირატესობას, რამაც შეიძლება დაარწმუნოს სტატისტიკური ანალიზის სისტემა, რომ უარყოფითი პასუხები მართებულია, რადგან ისინი არიან. ხშირი და სტატისტიკურად დომინანტური – განსაკუთრებით ძალიან გამოწერილი ფორუმების შემთხვევაში შეზღუდული მოდერატორის რესურსებით.
ამიტომ რჩება კითხვა, უნდა შეიცავდეს თუ არა ჩეთბოტის არქიტექტურას რაიმე სახის „მორალური შეფასების ჩარჩო“, სადაც ქვემიზნები გავლენას ახდენენ მოდელში წონების განვითარებაზე, ან შეიძლება თუ არა მონაცემთა უფრო ძვირი კურირება და მარკირება რაიმე გზით ეწინააღმდეგებოდეს ამ ტენდენციას. დაუბალანსებელი მონაცემები.
* მკვლევართა ნაშრომი, როგორც ამ სტატიაშია მიბმული, შეცდომით მოჰყავს Google-ის ბმული მეენა ჩატბოტი ბლენდერის ქაღალდის ბმულის ნაცვლად. Google-ის Meena არის არ წარმოდგენილია ახალ ნაშრომში. ამ სტატიაში გამოყენებული ბლენდერის სწორი ბმული მოწოდებულია ნაშრომების ავტორებმა ელ.წერილში. ავტორებმა მითხრეს, რომ ეს შეცდომა შესწორებული იქნება ნაშრომის შემდგომ ვერსიაში.
პირველად გამოქვეყნდა 18 წლის 2022 იანვარს.















