
Artificial Intelligence
Google sér fyrir sér GPT-3-líkt fyrirspurnakerfi, án leitarniðurstaðna

Ný grein frá fjórum rannsakendum Google leggur til „sérfræðinga“ kerfi sem getur svarað spurningum notenda á opinberan hátt án þess að setja fram lista yfir mögulegar leitarniðurstöður, svipað og spurninga- og svörunarhugmyndin sem hefur vakið athygli almennings með tilkomu GPT-3 undanfarið. ári.
The pappír, rétt Endurhugsa leit: Gera sérfræðinga úr Dilettantum, bendir til þess að núverandi staðall um að kynna notanda lista yfir leitarniðurstöður sem svar við fyrirspurn sé „vitræn byrði“ og leggur til úrbætur á getu náttúrulegs málvinnslukerfis (NLP) til að veita opinbert og endanlegt svar .
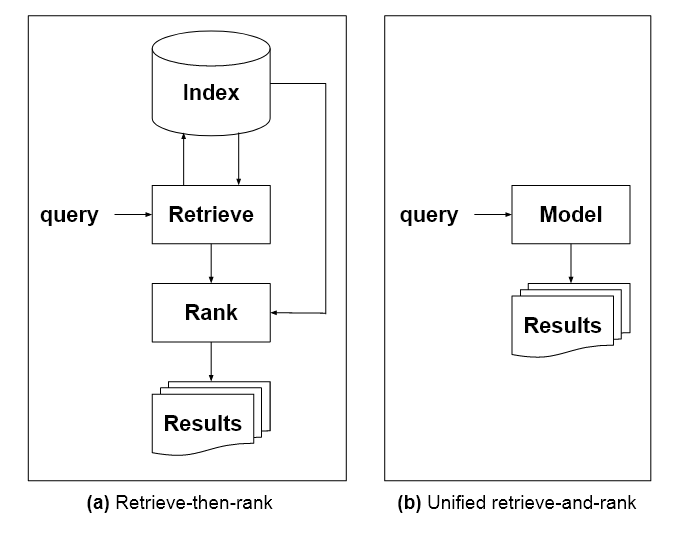
Samkvæmt fyrirhuguðu líkani um „sérfræðing“, véfrétt yfir lén, verða þúsundir mögulegra leitarniðurstöðuheimilda settar inn í tungumálalíkan í stað þess að vera beinlínis aðgengilegt sem könnunarúrræði fyrir notendur til að meta og fletta sjálfir. Heimild: https://arxiv.org/pdf/2105.02274.pdf
Blaðið, undir forystu Donald Metzler hjá Google Research, leggur til úrbætur á þeirri tegund véfréttaviðbragða sem hægt er að fá í gegnum djúpt nám eins og GPT-3. Helstu úrbætur sem gert er ráð fyrir eru a) að líkanið væri fær um að vitna nákvæmlega í heimildirnar sem upplýstu svarið og b) að líkanið yrði komið í veg fyrir að 'ofskynja' svörum eða að finna upp heimildarefni sem ekki er til, sem er nú vandamál með slíkum arkitektúr.
Þjálfun og getu á mörgum lénum
Auk þess yrði fyrirhugað tungumálalíkan, sem í greininni er lýst sem „Eitt líkan fyrir öll upplýsingaöflunarverkefni“, þjálfað á ýmsum sviðum, þar á meðal myndir og texta. Það þyrfti líka skilning á uppruna þekkingar, sem vantar í arkitektúr í GPT-3 stíl.
„Til að skipta út vísitölum fyrir eitt, sameinað líkan verður að vera mögulegt fyrir líkanið sjálft að hafa þekkingu á alheimi skjalaauðkenna, á sama hátt og hefðbundnar vísitölur gera. Ein leið til að ná þessu er að hverfa frá hefðbundnum LM og í átt að corpuslíkönum sem í sameiningu mynda hugtaks-hugtak, hugtak-skjal og skjala-skjal sambönd.

Á myndinni hér að ofan, úr blaðinu, eru þrjár aðferðir til að bregðast við fyrirspurn notenda: til vinstri, tungumálalíkönin sem felast í reiknirit leitarniðurstöðum Google hafa valið og forgangsraðað „besta svarinu“, en hafa skilið það eftir sem efstu niðurstöðu margra. Center, samtalssvar í GPT-3 stíl, sem talar með yfirvaldi, en réttlætir ekki fullyrðingar sínar eða vitnar í heimildir. Rétt, fyrirhugað sérfræðikerfi fellur „bestu svörun“ úr röðuðum leitarniðurstöðum beint inn í kennslufræðilegt svar, með tilvitnunum í fræðilegum stíl neðanmálsgreinar (ekki sýndar á upprunalegu myndinni) sem gefa til kynna heimildirnar sem upplýsa svarið.
Fjarlægir eitraðar og ónákvæmar niðurstöður
Rannsakendur taka fram að kraftmikið og stöðugt uppfært eðli leitarvísitalna er áskorun til að endurtaka algjörlega í vélanámslíkani af þessu tagi. Til dæmis, þar sem einu sinni traustur heimildarmaður hefur verið þjálfaður beint í skilning líkansins á heiminum, getur það verið erfiðara að fjarlægja áhrif þess (til dæmis eftir að það hefur verið ófrægt) en bara að fjarlægja vefslóð úr SERP, þar sem gagnahugtök geta orðið óhlutbundin og víða við aðlögun í þjálfun.
Þar að auki þyrfti að þjálfa slíkt líkan stöðugt til að veita sömu svörun við nýjum greinum og ritum eins og nú er veitt af stöðugri köngulóarheimild Google. Í raun þýðir þetta stöðuga og sjálfvirka útsetningu, öfugt við núverandi fyrirkomulag, þar sem smávægilegar breytingar eru gerðar á þyngd og stillingum leitarreikniritsins í frjálsu formi, en reikniritið sjálft er venjulega aðeins uppfært sjaldan.
Árásarfletir fyrir miðlæga sérfræðing véfrétt
Miðstýrt líkan sem stöðugt tileinkar sér og alhæfir ný gögn gæti umbreytt árásaryfirborðinu fyrir leitarfyrirspurnir.
Eins og er getur árásarmaður fengið ávinning með því að ná háum röðun fyrir lén eða síður sem annað hvort innihalda rangar upplýsingar eða illgjarn kóða. Í skjóli ógegnsærri véfrétta „sérfræðings“ minnkar tækifærið til að beina notendum yfir á árásarlén til muna, en möguleikinn á að sprauta inn eitruðum gagnaárásum er stóraukin.
Þetta er vegna þess að fyrirhugað kerfi útilokar ekki leitarröðunaralgrímið, heldur felur það fyrir notandanum, gerir í raun sjálfvirkan forgang efstu niðurstaðna og gerir hana (eða þær) í kennslufræðilegri yfirlýsingu. Illgjarnir notendur hafa lengi getað skipulagt árásir á Google leitarreikniritið, til selja falsa vörur, beinir notendur á lén sem dreifa spilliforritum, eða í þeim tilgangi pólitísk meðferð, meðal margra annarra notkunartilvika.
Ekki AGI
Rannsakendur leggja áherslu á að ólíklegt væri að slíkt kerfi uppfylli skilyrði sem gervigreind (AGI) og setja möguleika á alhliða viðbragðssérfræðingi í samhengi við náttúrulega málvinnslu, háð öllum þeim áskorunum sem slík líkön standa frammi fyrir nú.
Í ritgerðinni eru fimm kröfur um „hágæða“ svar:
1: Yfirvald
Eins og með núverandi röðunaralgrím, virðist 'yfirvald' vera dregið af tilvitnunum frá hágæða lénum sem eru talin opinber í sjálfu sér. Rannsakendur athuga:
„Svör ættu að búa til efni með því að sækja frá mjög viðurkenndum heimildum. Þetta er önnur ástæða fyrir því að það er svo mikilvægt að koma á skýrari tengingum milli raða hugtaka og lýsigagna skjala. Ef öll skjölin í málheildinni eru merkt með heimildarstig, ætti að taka tillit til þess stigs þegar líkanið er þjálfað, svarað eða hvort tveggja.'
Þó að rannsakendur gefi ekki til kynna að hefðbundnar SERP niðurstöður yrðu ófáanlegar ef sérfræðingur af þessu tagi reyndist árangursríkur og vinsæll, sýnir allt blaðið hið hefðbundna röðunarkerfi og leitarniðurstöðulista, í ljósi áratuga. gamalt og úrelt upplýsingaöflunarkerfi.
„Sú staðreynd að röðun er mikilvægur þáttur í þessari hugmyndafræði er einkenni endurheimtarkerfisins sem gefur notendum úrval mögulegra svara, sem veldur frekar verulegu vitrænni álagi á notandann. Löngunin til að skila svörum í stað niðurraðaðra lista yfir niðurstöður var einn af hvatningarþáttum fyrir þróun spurningasvarskerfis. '
2: Gagnsæi
Rannsakendur segja:
„Þegar mögulegt er ætti að gera honum aðgengilegt uppruna þeirra upplýsinga sem verið er að kynna notandanum. Er þetta aðaluppspretta upplýsinga? Ef ekki, hver er frumheimildin?'
3: Meðhöndlun hlutdrægni
Ritgerðin bendir á að fyrirfram þjálfuð tungumálalíkön séu ekki hönnuð til að leggja mat á reynslusannleika, heldur til að alhæfa og forgangsraða ríkjandi stefnum í gögnunum. Það viðurkennir að þessi tilskipun opni líkanið fyrir árás (eins og átti sér stað með Microsoft óviljandi kynþáttafordómar árið 2016), og að aukakerfi þurfi til að verjast slíkum hlutdrægum viðbrögðum kerfisins.
4: Virkja fjölbreytt sjónarmið
Ritgerðin leggur einnig til aðferðir til að tryggja fjölmörg sjónarmið:
„Búin svör ættu að tákna margvísleg sjónarmið en ættu ekki að vera skautandi. Til dæmis, fyrir fyrirspurnir um umdeilt efni, ætti að fara yfir báðar hliðar efnisins á sanngjarnan og yfirvegaðan hátt. Þetta hefur augljóslega náin tengsl við líkan hlutdrægni.'
5: Aðgengilegt tungumál
Auk þess að veita nákvæmar þýðingar í tilfellum þar sem talið er að hið opinbera svar er á öðru tungumáli, leggur blaðið til að innbyggð svör ættu að vera „skrifuð á eins látlausan hátt og mögulegt er“.















